
Rumah >Peranti teknologi >AI >Bagaimana untuk menggunakan pembelajaran pengukuhan untuk meningkatkan pengekalan pengguna Kuaishou?
Bagaimana untuk menggunakan pembelajaran pengukuhan untuk meningkatkan pengekalan pengguna Kuaishou?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-07 18:31:082364semak imbas
Matlamat teras sistem pengesyoran video pendek adalah untuk memacu pertumbuhan DAU dengan meningkatkan pengekalan pengguna. Oleh itu, pengekalan ialah salah satu petunjuk pengoptimuman perniagaan teras bagi setiap APP. Walau bagaimanapun, pengekalan ialah maklum balas jangka panjang selepas berbilang interaksi antara pengguna dan sistem, dan sukar untuk menguraikannya menjadi satu item atau senarai tunggal Oleh itu, sukar untuk model tradisional dari segi titik dan senarai untuk secara langsung mengoptimumkan pengekalan.
Kaedah pembelajaran pengukuhan (RL) mengoptimumkan ganjaran jangka panjang dengan berinteraksi dengan persekitaran, dan sesuai untuk mengoptimumkan pengekalan pengguna secara langsung. Kerja ini memodelkan masalah pengoptimuman pengekalan sebagai proses keputusan Markov (MDP) dengan butiran permintaan ufuk tak terhingga Setiap kali pengguna meminta sistem pengesyoran untuk memutuskan tindakan, ia digunakan untuk mengagregatkan berbilang anggaran maklum balas jangka pendek yang berbeza (Tempoh tontonan. suka, ikut, komen, tweet semula, dsb.) pemarkahan model ranking. Matlamat kerja ini adalah untuk mempelajari dasar, meminimumkan selang masa terkumpul antara berbilang sesi pengguna, meningkatkan kekerapan pembukaan apl dan dengan itu meningkatkan pengekalan pengguna.
Walau bagaimanapun, disebabkan oleh ciri isyarat yang dikekalkan, aplikasi langsung algoritma RL sedia ada mempunyai cabaran berikut: 1) Ketidakpastian: isyarat yang dikekalkan bukan sahaja ditentukan oleh algoritma pengesyoran , tetapi juga diganggu oleh banyak faktor luaran; 2) Bias: Isyarat pengekalan mempunyai penyimpangan dalam tempoh masa yang berbeza dan kumpulan pengguna aktif yang berbeza 3) Ketidakstabilan: Tidak seperti persekitaran permainan yang mengembalikan ganjaran serta-merta, isyarat pengekalan biasanya kembali dalam beberapa jam hari, yang akan menyebabkan algoritma RL pergi dalam talian Masalah ketidakstabilan latihan.
Kerja ini mencadangkan algoritma Pembelajaran Pengukuhan untuk Pengekalan Pengguna (RLUR) untuk menyelesaikan cabaran di atas dan mengoptimumkan pengekalan secara langsung. Melalui pengesahan luar talian dan dalam talian, algoritma RLUR boleh meningkatkan indeks pengekalan sekunder dengan ketara berbanding garis dasar Negara Seni. Algoritma RLUR telah dilaksanakan sepenuhnya dalam Apl Kuaishou, dan boleh terus mencapai pengekalan sekunder yang ketara dan hasil DAU Ini adalah kali pertama dalam industri bahawa teknologi RL telah digunakan untuk meningkatkan pengekalan pengguna dalam persekitaran pengeluaran sebenar. Kerja ini telah diterima ke dalam Laluan Industri WWW 2023.

Pengarang: Cai Qingpeng, Liu Shuchang, Wang Xueliang, Zuo Tianyou, Xie Wentao, Yang Bin, Zheng Dong, Jiang Peng
Alamat kertas: https://arxiv.org/pdf/2302.01724.pdf
Pemodelan Masalah
Seperti yang ditunjukkan dalam Rajah 1(a), kerja ini memodelkan masalah pengoptimuman pengekalan sebagai Proses Keputusan Markov berasaskan permintaan ufuk tak terhingga, di mana sistem pengesyoran adalah ejen, pengguna ialah persekitaran. Setiap kali pengguna membuka Apl, sesi baharu i dibuka. Seperti yang ditunjukkan dalam Rajah 1(b), setiap kali pengguna meminta  sistem pengesyoran menentukan vektor parameter
sistem pengesyoran menentukan vektor parameter  berdasarkan status pengguna
berdasarkan status pengguna  , manakala n Model kedudukan yang menganggarkan penunjuk jangka pendek yang berbeza (masa tontonan, suka, perhatian, dll.) menjaringkan setiap video calon j
, manakala n Model kedudukan yang menganggarkan penunjuk jangka pendek yang berbeza (masa tontonan, suka, perhatian, dll.) menjaringkan setiap video calon j  . Kemudian fungsi pengisihan memasukkan tindakan dan vektor pemarkahan setiap video untuk mendapatkan skor akhir setiap video, dan memilih 6 video yang mendapat markah tertinggi untuk dipaparkan kepada pengguna. Pengguna mengembalikan maklum balas segera
. Kemudian fungsi pengisihan memasukkan tindakan dan vektor pemarkahan setiap video untuk mendapatkan skor akhir setiap video, dan memilih 6 video yang mendapat markah tertinggi untuk dipaparkan kepada pengguna. Pengguna mengembalikan maklum balas segera 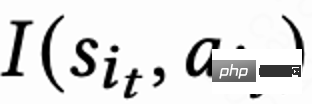 . Apabila pengguna meninggalkan Apl, sesi ini tamat Pada kali seterusnya pengguna membuka Apl, sesi i+1 dibuka Selang masa antara akhir sesi sebelumnya dan permulaan sesi seterusnya dipanggil masa kembali (. Masa kembali),
. Apabila pengguna meninggalkan Apl, sesi ini tamat Pada kali seterusnya pengguna membuka Apl, sesi i+1 dibuka Selang masa antara akhir sesi sebelumnya dan permulaan sesi seterusnya dipanggil masa kembali (. Masa kembali),  . Matlamat penyelidikan ini adalah untuk melatih strategi yang meminimumkan jumlah masa panggil balik untuk berbilang sesi.
. Matlamat penyelidikan ini adalah untuk melatih strategi yang meminimumkan jumlah masa panggil balik untuk berbilang sesi.
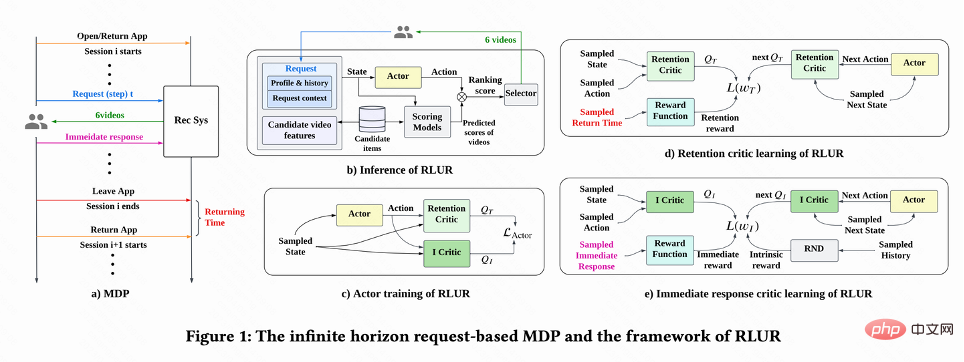
Algoritma RLUR
Kerja ini mula-mula membincangkan cara menganggarkan masa lawatan balik kumulatif, dan kemudian mencadangkan kaedah untuk menyelesaikan beberapa cabaran utama bagi isyarat yang dikekalkan. Kaedah ini diringkaskan ke dalam algoritma Pembelajaran Pengukuhan untuk Pengekalan Pengguna, disingkatkan sebagai RLUR.
Anggaran masa lawatan balik
Seperti yang ditunjukkan dalam Rajah 1(d), memandangkan tindakan itu berterusan, Kerja ini menggunakan kaedah pembelajaran perbezaan temporal (TD) algoritma DDPG untuk menganggarkan masa lawatan balik.
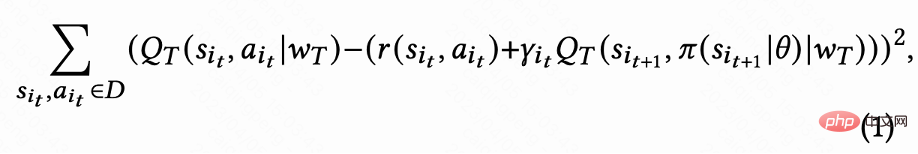
Memandangkan setiap sesi hanya mempunyai ganjaran masa lawatan balik untuk permintaan terakhir, dan ganjaran perantaraan ialah 0, pengarang menetapkan faktor diskaun  Nilai permintaan terakhir dalam setiap sesi ialah
Nilai permintaan terakhir dalam setiap sesi ialah 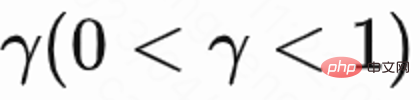 , dan nilai permintaan lain ialah 1. Tetapan ini boleh mengelakkan pereputan eksponen masa lawatan balik. Dan secara teori boleh dibuktikan bahawa apabila kerugian (1) ialah 0, Q sebenarnya menganggarkan masa pulangan kumulatif berbilang sesi,
, dan nilai permintaan lain ialah 1. Tetapan ini boleh mengelakkan pereputan eksponen masa lawatan balik. Dan secara teori boleh dibuktikan bahawa apabila kerugian (1) ialah 0, Q sebenarnya menganggarkan masa pulangan kumulatif berbilang sesi, 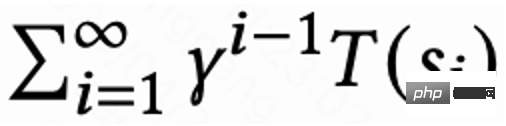 .
.
Menyelesaikan masalah kelewatan ganjaran
Memandangkan masa lawatan balik hanya berlaku pada akhir setiap sesi , yang akan membawa masalah kecekapan pembelajaran yang rendah. Oleh itu, pengarang menggunakan ganjaran heuristik untuk meningkatkan pembelajaran dasar. Memandangkan maklum balas jangka pendek berkaitan secara positif dengan pengekalan, pengarang menggunakan maklum balas jangka pendek sebagai ganjaran heuristik pertama. Dan penulis menggunakan rangkaian Penyulingan Rangkaian Rawak (RND) untuk mengira ganjaran intrinsik setiap sampel sebagai ganjaran heuristik kedua. Secara khusus, rangkaian RND menggunakan dua struktur rangkaian yang sama Satu rangkaian dimulakan secara rawak kepada tetap, dan rangkaian lain sesuai dengan rangkaian tetap, dan kerugian pemasangan digunakan sebagai ganjaran intrinsik. Seperti yang ditunjukkan dalam Rajah 1(e), untuk mengurangkan gangguan ganjaran heuristik pada ganjaran pengekalan, kerja ini mempelajari rangkaian pengkritik yang berasingan untuk menganggarkan jumlah maklum balas jangka pendek dan ganjaran intrinsik. Iaitu 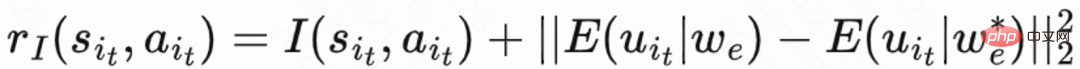 .
.
Menyelesaikan isu ketidakpastian
Disebabkan oleh masa lawatan balik, ia telah disyorkan oleh banyak faktor dan ketidakpastian yang tinggi, yang akan menjejaskan kesan pembelajaran. Kerja ini mencadangkan kaedah regularisasi untuk mengurangkan varians: mula-mula menganggarkan model klasifikasi  untuk menganggarkan kebarangkalian masa lawatan balik, iaitu sama ada anggaran masa lawatan balik adalah lebih pendek daripada
untuk menganggarkan kebarangkalian masa lawatan balik, iaitu sama ada anggaran masa lawatan balik adalah lebih pendek daripada  ; Kemudian gunakan ketaksamaan Markov untuk mendapatkan batas bawah masa lawatan balik,
; Kemudian gunakan ketaksamaan Markov untuk mendapatkan batas bawah masa lawatan balik, 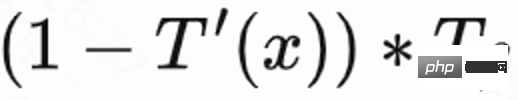 Akhir sekali, gunakan masa lawatan balik sebenar/anggaran masa lawatan balik yang terikat lebih rendah sebagai lawatan balik yang ditetapkan pahala.
Akhir sekali, gunakan masa lawatan balik sebenar/anggaran masa lawatan balik yang terikat lebih rendah sebagai lawatan balik yang ditetapkan pahala.
Menyelesaikan masalah sisihan
Disebabkan perbezaan besar dalam tabiat tingkah laku kumpulan aktif yang berbeza, pengguna sangat aktif Kadar pengekalan adalah tinggi dan bilangan sampel latihan adalah jauh lebih besar daripada pengguna aktif rendah, yang akan menyebabkan pembelajaran model didominasi oleh pengguna aktif tinggi. Untuk menyelesaikan masalah ini, kerja ini mempelajari 2 strategi bebas untuk kumpulan yang berbeza dengan aktiviti tinggi dan aktiviti rendah, dan menggunakan aliran data yang berbeza untuk latihan The Actor meminimumkan masa lawatan balik sambil memaksimumkan ganjaran tambahan. Seperti yang ditunjukkan dalam Rajah 1(c), mengambil kumpulan aktiviti tinggi sebagai contoh, kerugian Pelakon ialah:
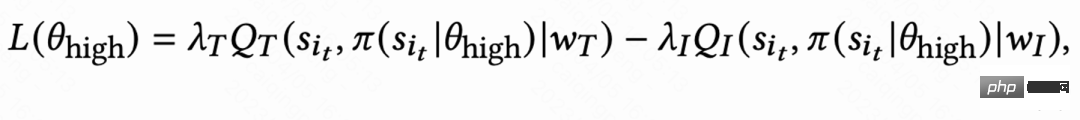
Menyelesaikan masalah ketidakstabilan
Disebabkan kelewatan isyarat dalam lawatan balas masa, Biasanya kembali dalam masa beberapa jam hingga beberapa hari, yang boleh menyebabkan ketidakstabilan dalam latihan dalam talian RL. Walau bagaimanapun, secara langsung menggunakan kaedah pengklonan tingkah laku sedia ada sama ada akan mengehadkan kelajuan pembelajaran atau gagal menjamin pembelajaran yang stabil. Oleh itu, kerja ini mencadangkan kaedah regularisasi lembut baharu, iaitu, mendarabkan kehilangan aktor dengan pekali regularisasi lembut:
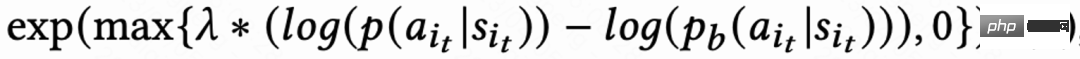
Kaedah penyusunan semula ini pada asasnya adalah kesan brek: jika strategi pembelajaran semasa dan strategi sampel menyimpang dengan ketara, kerugian akan menjadi lebih kecil dan pembelajaran akan cenderung stabil jika kelajuan pembelajaran cenderung stabil, kerugian akan berlaku; semula- Semakin besar anda, semakin cepat anda belajar. Apabila  , bermakna tiada sekatan terhadap proses pembelajaran.
, bermakna tiada sekatan terhadap proses pembelajaran.
Percubaan luar talian
Kerja ini menggabungkan RLUR dan algoritma pembelajaran pengukuhan TD3 Terkini, serta kaedah pengoptimuman kotak hitam Kaedah Cross Entropy ( CEM) dalam Set data awam KuaiRand digunakan untuk perbandingan. Kerja ini mula-mula membina simulator pengekalan berdasarkan set data KuaiRand: termasuk tiga modul: maklum balas segera pengguna, pengguna meninggalkan sesi dan lawatan balik pengguna ke apl, dan kemudian menggunakan kaedah penilaian simulator pengekalan ini.
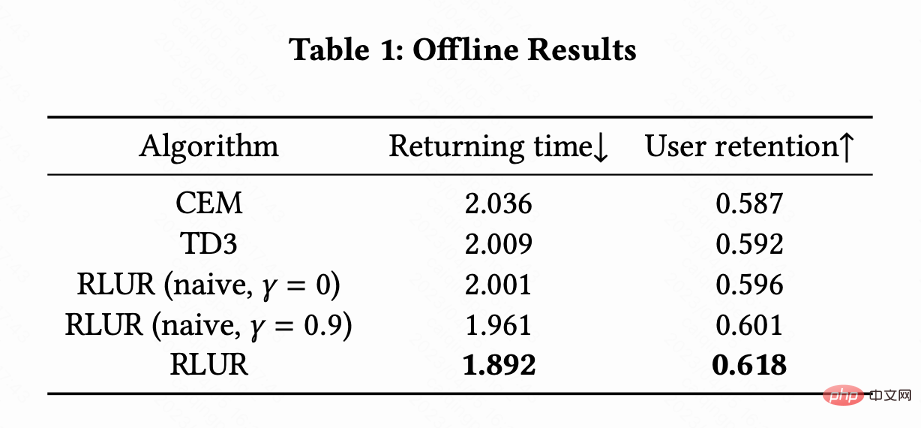
Jadual 1 menggambarkan bahawa RLUR jauh lebih baik daripada CEM dan TD3 dalam masa lawatan balik dan penunjuk pengekalan sekunder. Kajian ini menjalankan eksperimen ablasi untuk membandingkan RLUR dengan hanya bahagian pembelajaran pengekalan (RLUR (naif)), yang boleh menggambarkan keberkesanan pendekatan kajian ini untuk menyelesaikan cabaran pengekalan. Dan melalui perbandingan  dan
dan  , ditunjukkan bahawa algoritma meminimumkan masa pulangan berbilang sesi adalah lebih baik daripada meminimumkan masa pulangan satu sesi .
, ditunjukkan bahawa algoritma meminimumkan masa pulangan berbilang sesi adalah lebih baik daripada meminimumkan masa pulangan satu sesi .
Percubaan dalam talian
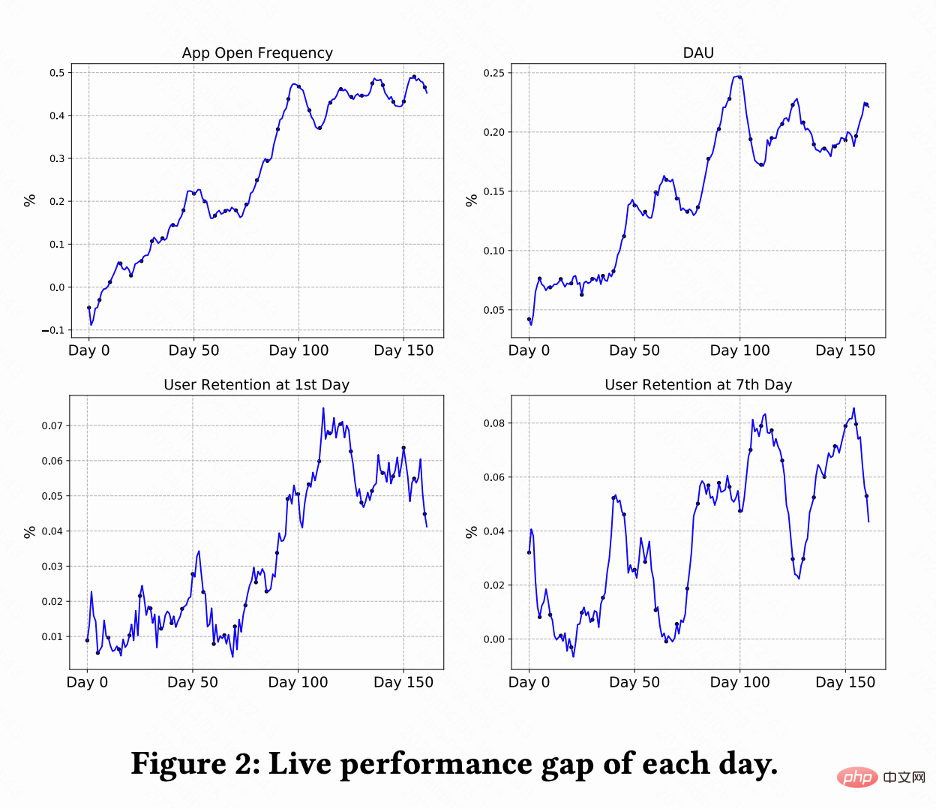
Kerja ini menjalankan ujian A/B pada sistem pengesyoran video pendek Kuaishou untuk membandingkan RLUR dan CEM kaedah . Rajah 2 menunjukkan peratusan peningkatan kekerapan pembukaan apl, DAU, pengekalan pertama dan pengekalan ke-7 masing-masing berbanding RLUR dan CEM. Ia boleh didapati bahawa kekerapan pembukaan apl meningkat secara beransur-ansur dan malah menumpu dari 0 hingga 100 hari. Dan ia juga memacu peningkatan pengekalan kedua, pengekalan ke-7 dan penunjuk DAU (0.1% DAU dan 0.01% peningkatan dalam pengekalan kedua dianggap signifikan secara statistik).
Ringkasan dan kerja akan datang
Kertas kerja ini mengkaji cara meningkatkan pengekalan pengguna sistem pengesyoran melalui teknologi RL Kerja ini memodelkan pengoptimuman pengekalan sebagai Marko dengan butiran permintaan ufuk tak terhingga Kerja ini mencadangkan algoritma RLUR untuk mengoptimumkan pengekalan secara langsung dan menangani beberapa cabaran utama isyarat pengekalan dengan berkesan. Algoritma RLUR telah dilaksanakan sepenuhnya dalam Apl Kuaishou dan boleh mencapai pengekalan sekunder yang ketara dan hasil DAU. Mengenai kerja masa depan, cara menggunakan pembelajaran pengukuhan luar talian, Pengubah Keputusan dan kaedah lain untuk meningkatkan pengekalan pengguna dengan lebih berkesan adalah arah yang menjanjikan.
Atas ialah kandungan terperinci Bagaimana untuk menggunakan pembelajaran pengukuhan untuk meningkatkan pengekalan pengguna Kuaishou?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI