
Rumah >Peranti teknologi >AI >Meta mengeluarkan sumber terbuka model besar pelbagai guna untuk membantu bergerak selangkah lebih dekat kepada penyatuan visual
Meta mengeluarkan sumber terbuka model besar pelbagai guna untuk membantu bergerak selangkah lebih dekat kepada penyatuan visual

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-07 15:49:181264semak imbas
Selepas sumber terbuka model SAM yang "membahagikan segala-galanya", Meta semakin jauh menuju ke "model asas visual".
Kali ini, mereka menggunakan sumber terbuka satu set model yang dipanggil DINOv2. Model ini boleh menghasilkan perwakilan visual berprestasi tinggi yang boleh digunakan untuk tugas hiliran seperti pengelasan, pembahagian, pengambilan imej dan anggaran kedalaman tanpa penalaan halus.
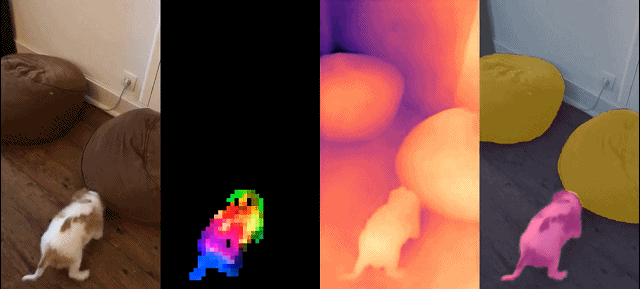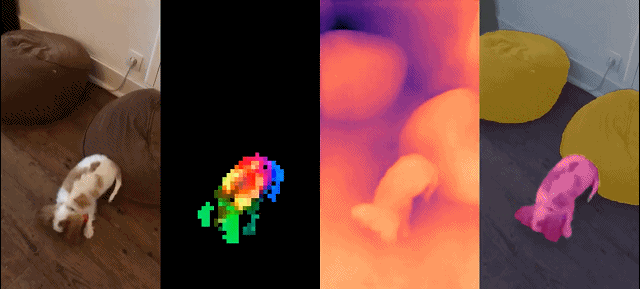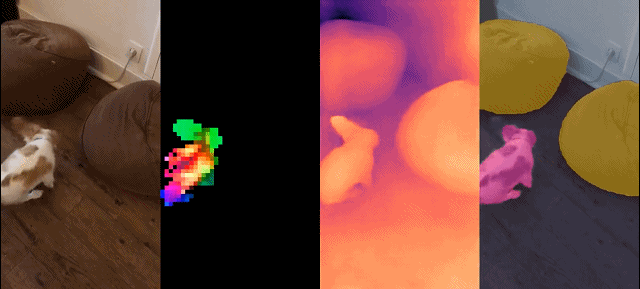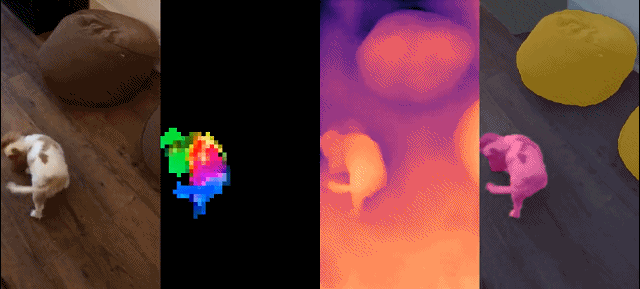
Set model ini mempunyai ciri-ciri berikut:
- Latihan menggunakan pendekatan penyeliaan sendiri tanpa memerlukan sejumlah besar data berlabel
- boleh digunakan sebagai tulang belakang hampir semua CV; tugasan, tiada penalaan halus diperlukan, Seperti klasifikasi imej, pembahagian, pengambilan imej dan anggaran kedalaman; memahami maklumat tempatan dengan lebih baik; CLIP dan OpenCLIP pada pelbagai tugas.
- Pautan kertas: https://arxiv.org/pdf/2304.07193.pdf
Pautan projek: https://dinov2.metademolab.com/
- Gambaran Keseluruhan Kertas Pembelajaran perwakilan pra-latihan neutral tugasan telah menjadi standard dalam pemprosesan bahasa semula jadi. Anda boleh menggunakan ciri ini "seadanya" (tiada penalaan halus diperlukan), dan ciri tersebut menunjukkan prestasi yang lebih baik pada tugas hiliran berbanding model khusus tugas. Kejayaan ini disebabkan oleh pra-latihan pada sejumlah besar teks mentah menggunakan objektif tambahan, seperti pemodelan bahasa atau vektor perkataan, yang tidak memerlukan pengawasan.
- Memandangkan anjakan paradigma ini berlaku dalam bidang NLP, diharapkan model "asas" yang serupa akan muncul dalam penglihatan komputer. Model ini harus menjana ciri visual yang berfungsi "di luar kotak" pada sebarang tugas, sama ada pada tahap imej (cth. klasifikasi imej) atau tahap piksel (cth. segmentasi).
Alternatif kepada pra-latihan berpandukan teks ialah pembelajaran penyeliaan kendiri, di mana ciri dipelajari daripada imej sahaja. Kaedah ini secara konsepnya lebih dekat dengan tugas bahagian hadapan seperti pemodelan bahasa, dan boleh menangkap maklumat pada tahap imej dan piksel. Walau bagaimanapun, walaupun potensi mereka untuk mempelajari ciri umum, kebanyakan penambahbaikan dalam pembelajaran penyeliaan kendiri telah dicapai dalam konteks pra-latihan pada dataset kecil yang diperhalusi ImageNet1k. Terdapat beberapa usaha oleh sesetengah penyelidik untuk melanjutkan kaedah ini melangkaui ImageNet-1k, tetapi mereka memfokuskan pada set data tidak ditapis, yang sering mengakibatkan kemerosotan yang ketara dalam kualiti prestasi. Ini disebabkan oleh kekurangan kawalan ke atas kualiti dan kepelbagaian data, yang penting untuk menghasilkan keputusan yang baik.
Dalam kerja ini, penyelidik meneroka sama ada pembelajaran penyeliaan kendiri adalah mungkin untuk mempelajari ciri visual umum jika dilatih terlebih dahulu pada sejumlah besar data yang diperhalusi. Mereka menyemak semula kaedah diskriminatif yang diselia sendiri yang mempelajari ciri pada tahap imej dan tampung, seperti iBOT, dan mempertimbangkan semula beberapa pilihan reka bentuk mereka di bawah set data yang lebih besar. Kebanyakan sumbangan teknikal kami disesuaikan untuk menstabilkan dan mempercepatkan pembelajaran diskriminatif penyeliaan kendiri apabila menskalakan model dan saiz data. Penambahbaikan ini menjadikan kaedah mereka lebih kurang 2x lebih pantas dan memerlukan 1/3 kurang memori daripada kaedah diskriminatif seliaan sendiri yang serupa, membolehkan mereka memanfaatkan latihan yang lebih panjang dan saiz kelompok yang lebih besar.
Mengenai data pra-latihan, mereka membina saluran paip automatik untuk menapis dan mengimbangi semula set data daripada koleksi besar imej yang tidak ditapis. Ini diilhamkan oleh saluran paip yang digunakan dalam NLP, di mana persamaan data digunakan dan bukannya metadata luaran, dan anotasi manual tidak diperlukan. Kesukaran utama semasa memproses imej adalah untuk mengimbangi semula konsep dan mengelakkan pemasangan berlebihan dalam beberapa mod dominan. Dalam kerja ini, kaedah pengelompokan naif dapat menyelesaikan masalah ini dengan baik, dan penyelidik mengumpul korpus kecil tetapi pelbagai yang terdiri daripada imej 142M untuk mengesahkan kaedah mereka.
Akhir sekali, penyelidik menyediakan pelbagai model penglihatan pra-latihan, dipanggil DINOv2, dilatih pada data mereka menggunakan seni bina Transformer visual (ViT) yang berbeza. Mereka mengeluarkan semua model dan kod untuk melatih semula DINOv2 pada sebarang data. Apabila dilanjutkan, mereka mengesahkan kualiti DINOv2 pada pelbagai penanda aras penglihatan komputer pada tahap imej dan piksel, seperti yang ditunjukkan dalam Rajah 2. Kami menyimpulkan bahawa pra-latihan yang diselia sendiri sahaja adalah calon yang baik untuk mempelajari ciri-ciri beku yang boleh dipindah milik, setanding dengan model penyeliaan lemah yang tersedia secara awam terbaik.
Pemprosesan Data
Penyelidik mengumpulkan LVD mereka yang diperhalusi dengan mendapatkan semula imej daripada sejumlah besar data tidak ditapis yang hampir dengan data dalam berbilang set data yang diperhalusi -142M. Dalam kertas kerja mereka, mereka menerangkan komponen utama dalam saluran paip data, termasuk sumber data yang dipilih susun/tidak ditapis, langkah penyahduplikasi imej dan sistem perolehan semula. Keseluruhan saluran paip tidak memerlukan sebarang metadata atau teks dan memproses imej secara langsung, seperti yang ditunjukkan dalam Rajah 3. Pembaca dirujuk kepada Lampiran A untuk butiran lanjut mengenai metodologi model.
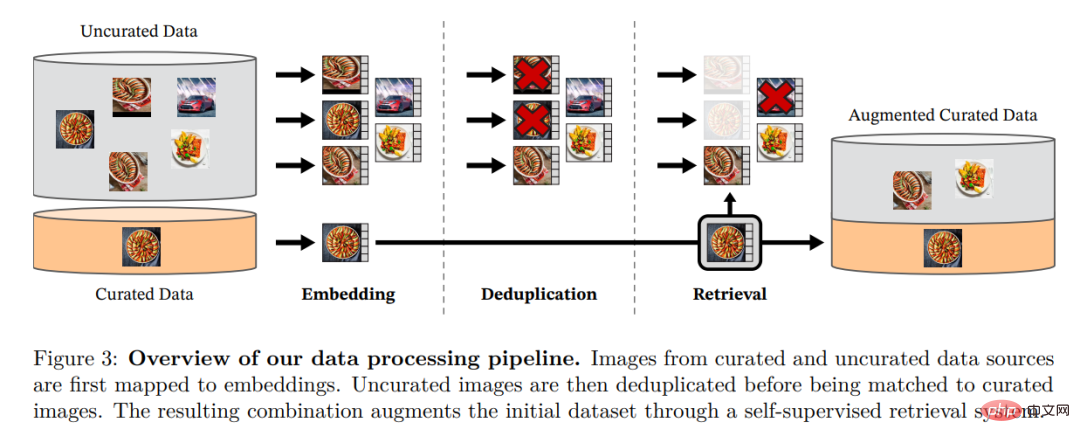
Rajah 3: Gambaran keseluruhan saluran paip untuk pemprosesan data. Imej daripada sumber data yang diperhalusi dan tidak diperhalusi pertama kali dipetakan kepada pembenaman. Imej yang tidak diperhalusi kemudiannya dinyahduplikasi sebelum dipadankan dengan imej standard. Gabungan yang terhasil memperkayakan lagi set data awal melalui sistem perolehan yang diselia sendiri.
Pralatihan penyeliaan diri yang diskriminatif
Para penyelidik mempelajari ciri-ciri mereka melalui pendekatan penyeliaan kendiri yang diskriminatif yang boleh dilihat gabungan kerugian DINO dan iBOT, berpusat di sekitar SwAV. Mereka juga menambah penyelaras untuk menyebarkan ciri dan fasa latihan resolusi tinggi ringkas.
Pelaksanaan yang cekap
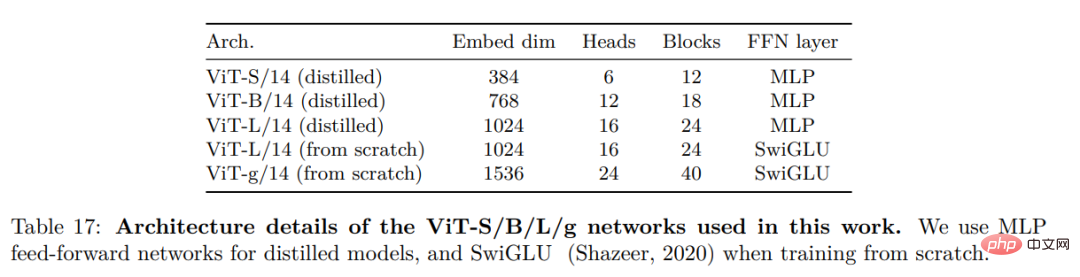
Mereka mempertimbangkan beberapa penambahbaikan untuk melatih model pada skala yang lebih besar. Model ini dilatih pada GPU A100 menggunakan PyTorch 2.0, dan kod itu juga boleh digunakan dengan model terlatih untuk pengekstrakan ciri. Butiran model adalah di Lampiran Jadual 17. Pada perkakasan yang sama, kod DINOv2 hanya menggunakan 1/3 daripada memori dan berjalan 2 kali lebih pantas daripada pelaksanaan iBOT.
Hasil eksperimen
Dalam bahagian ini, penyelidik akan memperkenalkan model baharu dalam banyak pemahaman imej Penilaian empirikal ke atas tugasan. Mereka menilai perwakilan imej global dan tempatan, termasuk pengecaman peringkat kategori dan contoh, pembahagian semantik, ramalan kedalaman monokular dan pengecaman tindakan.
Klasifikasi ImageNet
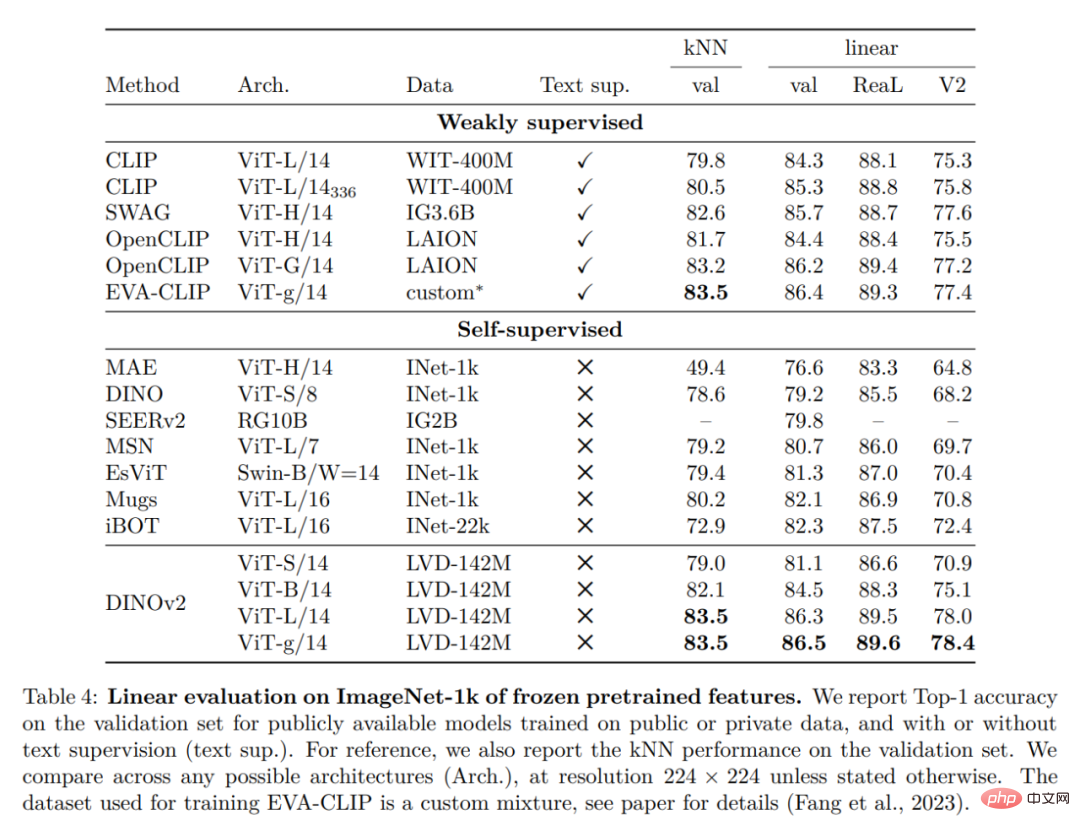
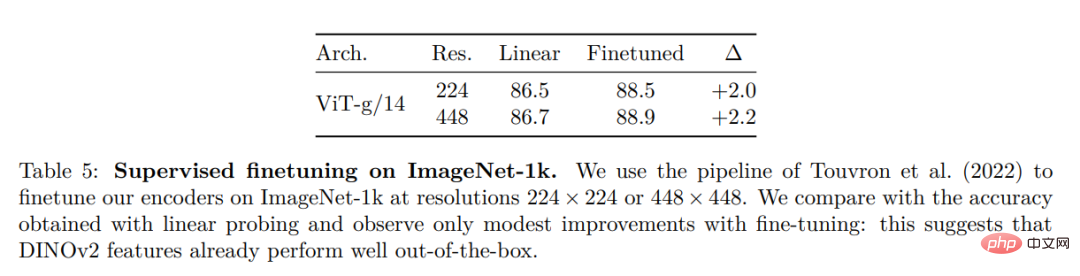
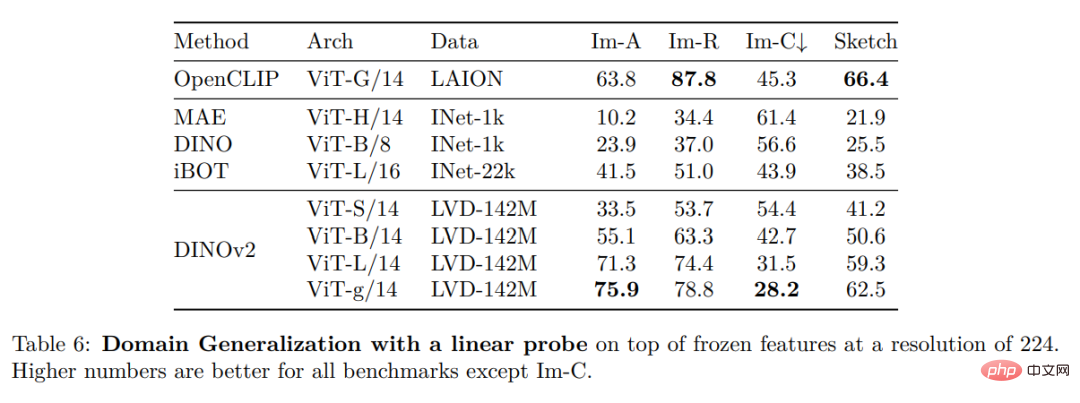
Tanda Aras Klasifikasi Imej dan Video Lain
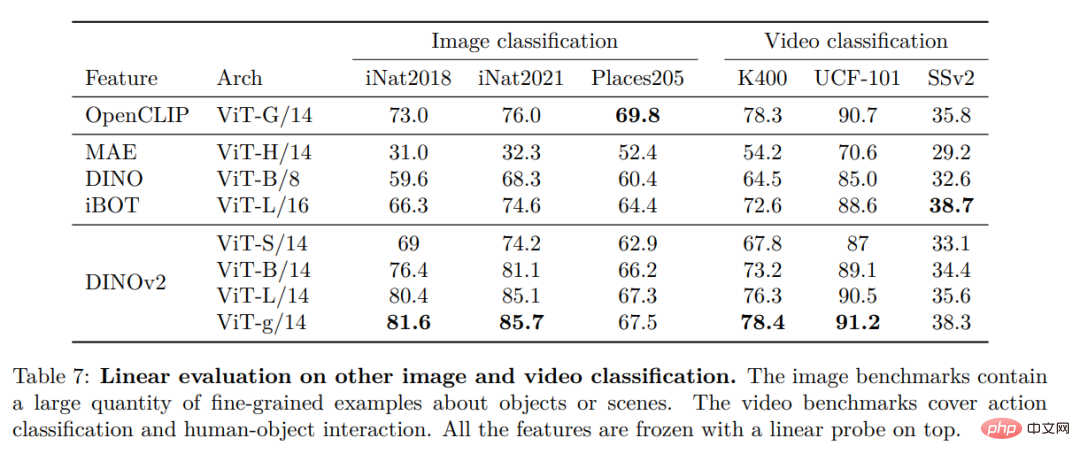
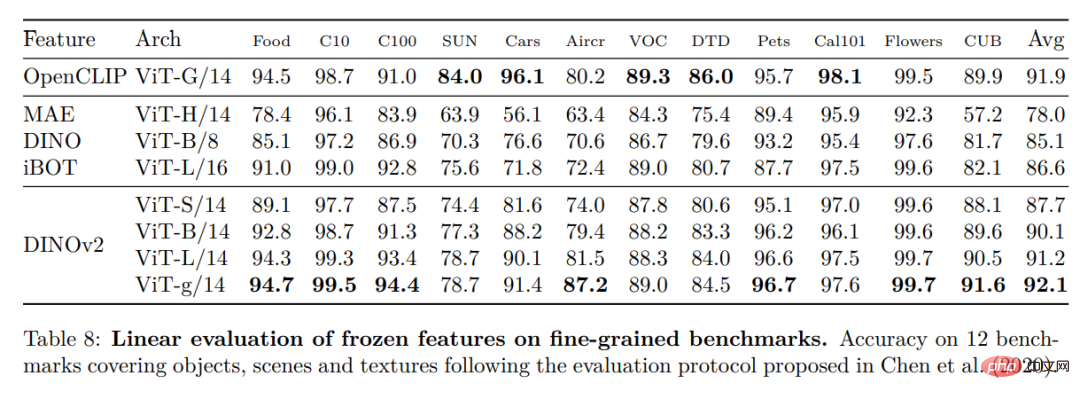
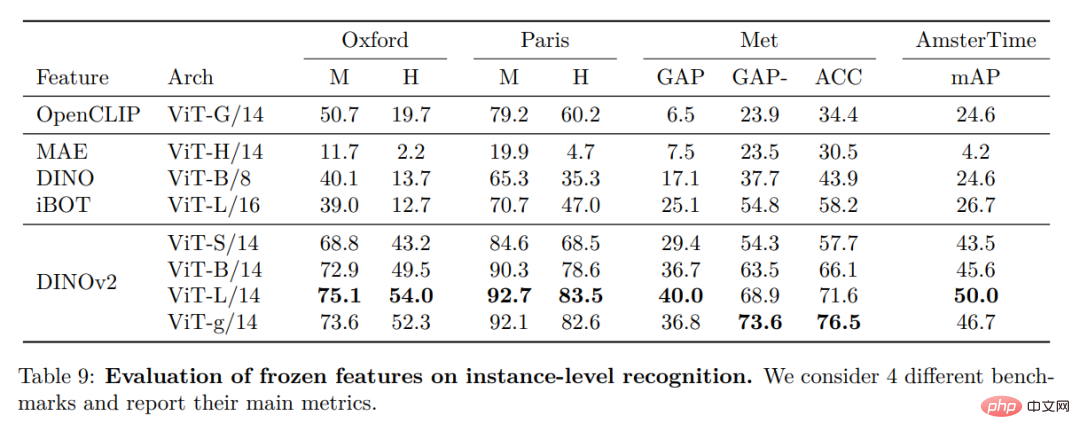
Pengenalan contoh
Tugas pengecaman padat
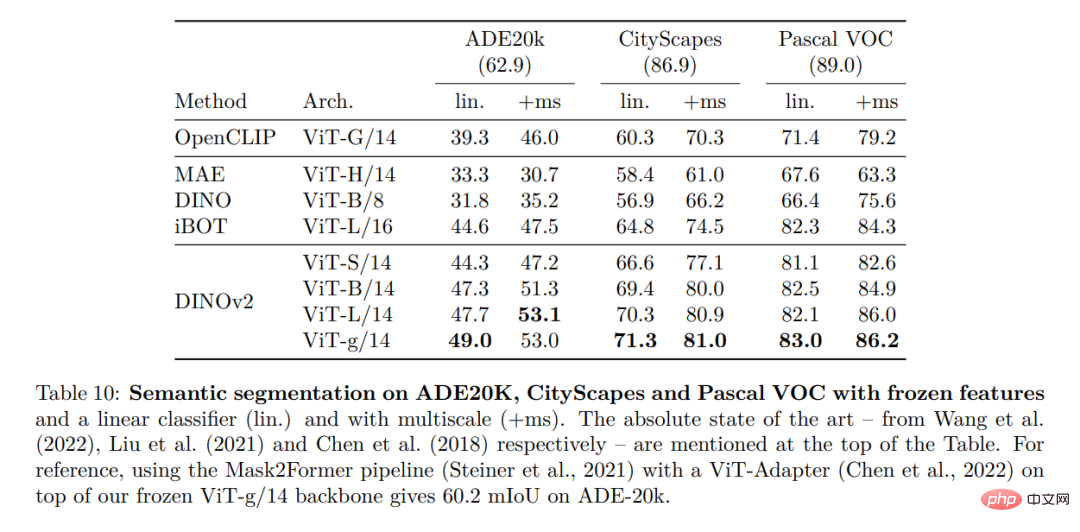
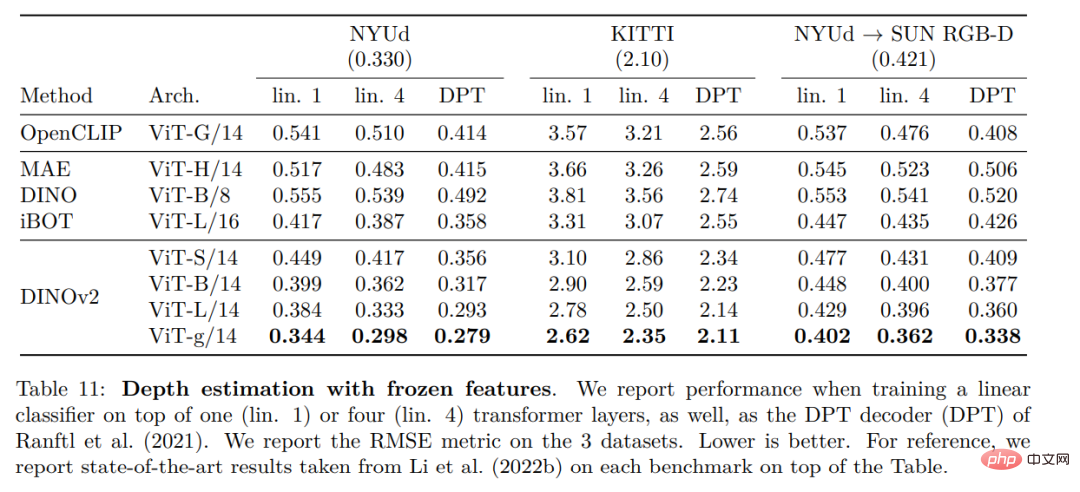
Hasil kualitatif



Atas ialah kandungan terperinci Meta mengeluarkan sumber terbuka model besar pelbagai guna untuk membantu bergerak selangkah lebih dekat kepada penyatuan visual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI