
Rumah >Peranti teknologi >AI >A100 melaksanakan kaedah pembinaan semula 3D tanpa lilitan 3D, dan hanya mengambil masa 70ms untuk setiap pembinaan semula bingkai
A100 melaksanakan kaedah pembinaan semula 3D tanpa lilitan 3D, dan hanya mengambil masa 70ms untuk setiap pembinaan semula bingkai

- PHPzke hadapan
- 2023-05-07 10:43:081826semak imbas
Membina semula adegan dalaman 3D daripada imej pose biasanya dibahagikan kepada dua peringkat: anggaran kedalaman imej, diikuti dengan penggabungan kedalaman dan pembinaan semula permukaan. Baru-baru ini, beberapa kajian telah mencadangkan pelbagai kaedah yang melakukan pembinaan semula secara langsung dalam ruang ciri volumetrik 3D akhir. Walaupun kaedah ini telah mencapai hasil pembinaan semula yang mengagumkan, kaedah ini bergantung pada lapisan konvolusi 3D yang mahal, mengehadkan penggunaannya dalam persekitaran terhad sumber.
Kini, penyelidik dari institusi seperti Niantic dan UCL cuba menggunakan semula kaedah tradisional dan menumpukan pada ramalan kedalaman berbilang paparan berkualiti tinggi, akhirnya menggunakan mudah dan luar biasa. kaedah gabungan kedalaman rak Pembinaan semula 3D yang sangat tepat.

- Alamat kertas: https://nianticlabs.github .io/simplerecon/resources/SimpleRecon.pdf
- Alamat GitHub: https://github.com/nianticlabs/simplerecon
- Halaman utama kertas: https://nianticlabs.github.io/simplerecon/
Penyelidikan ini menggunakan imej berkuasa pertama A CNN 2D direka bentuk dengan teliti berdasarkan eksperimen serta kuantiti ciri imbasan satah dan kehilangan geometri. Kaedah yang dicadangkan SimpleRecon mencapai keputusan yang mendahului dengan ketara dalam anggaran kedalaman dan membolehkan pembinaan semula memori rendah masa nyata dalam talian.
Seperti yang ditunjukkan dalam rajah di bawah, kelajuan pembinaan semula SimpleRecon adalah sangat pantas, hanya mengambil kira-kira 70ms setiap bingkai.
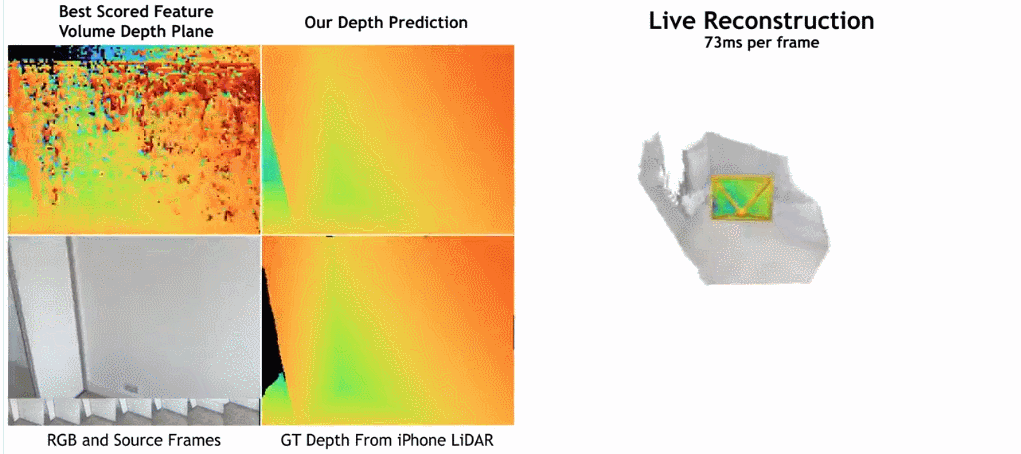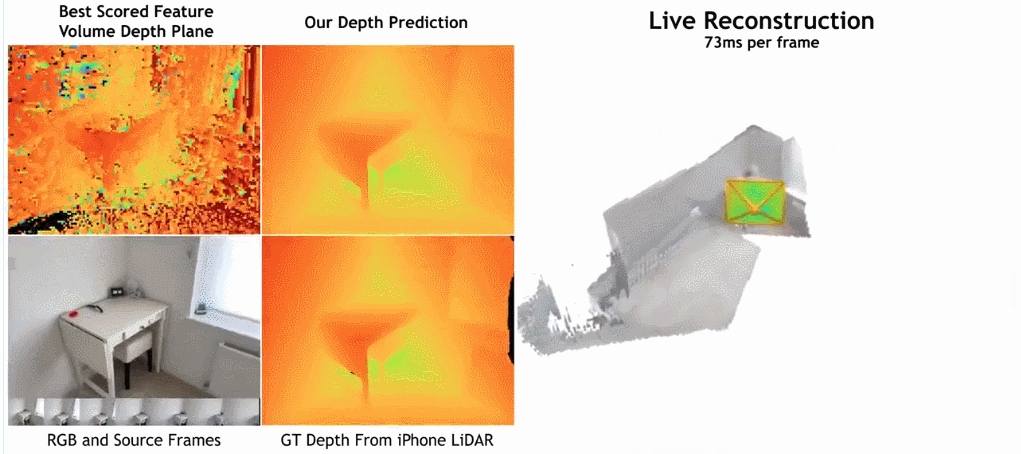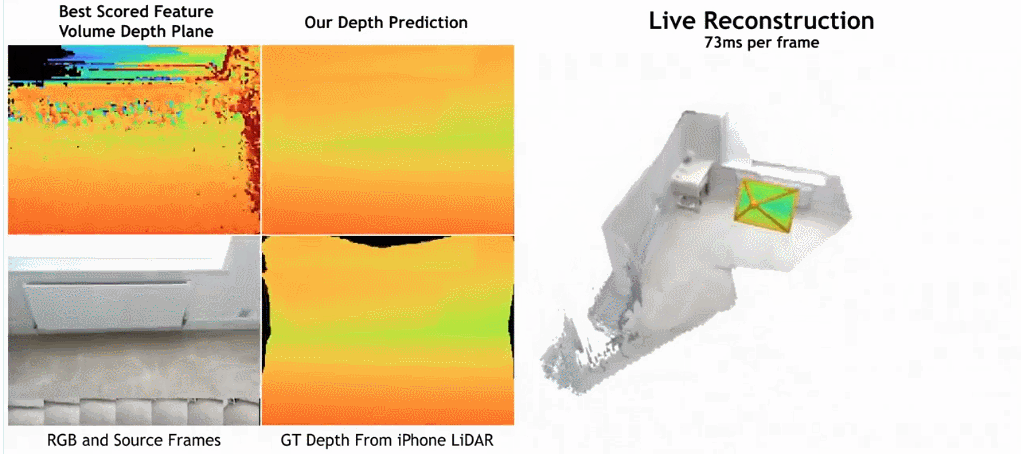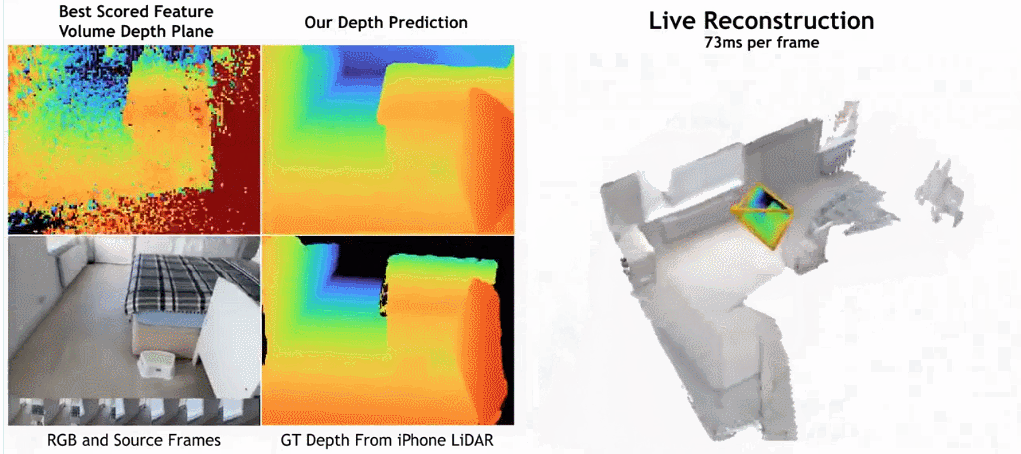
Hasil perbandingan antara SimpleRecon dan kaedah lain adalah seperti berikut:


Kaedah
Model anggaran kedalaman terletak di persimpangan anggaran kedalaman monokular dan pengimbasan planar MVS ramalan encoder-decoder Architecture, seperti yang ditunjukkan dalam Rajah 2. Pengekod imej mengekstrak ciri padanan daripada rujukan dan imej sumber sebagai input kepada volum kos. Rangkaian penyahkod pengekod konvolusi 2D digunakan untuk memproses output volum kos, yang ditambah dengan ciri peringkat imej yang diekstrak oleh pengekod imej terlatih yang berasingan.
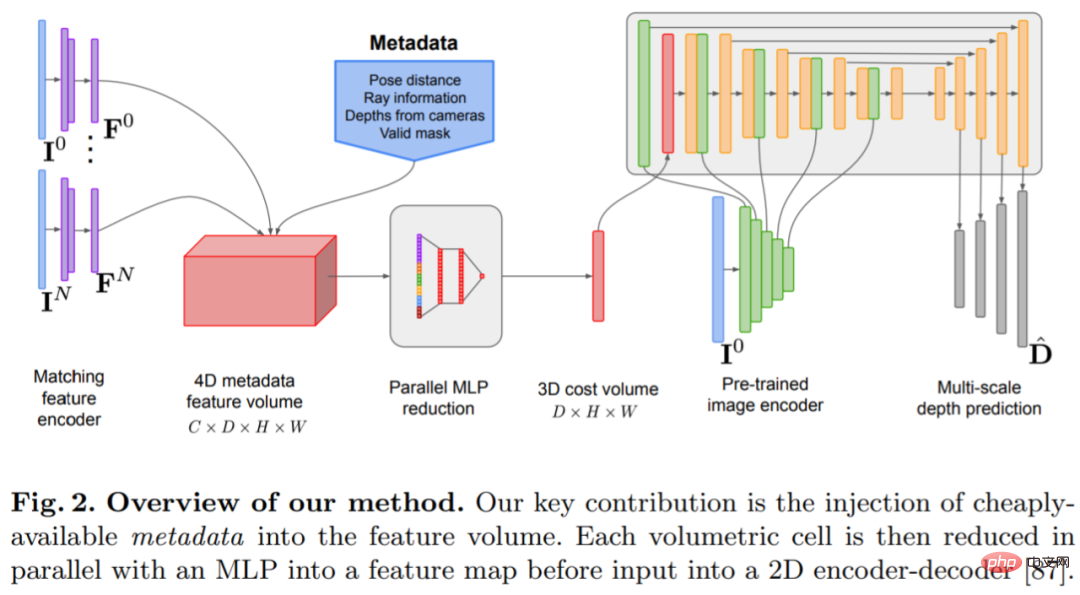
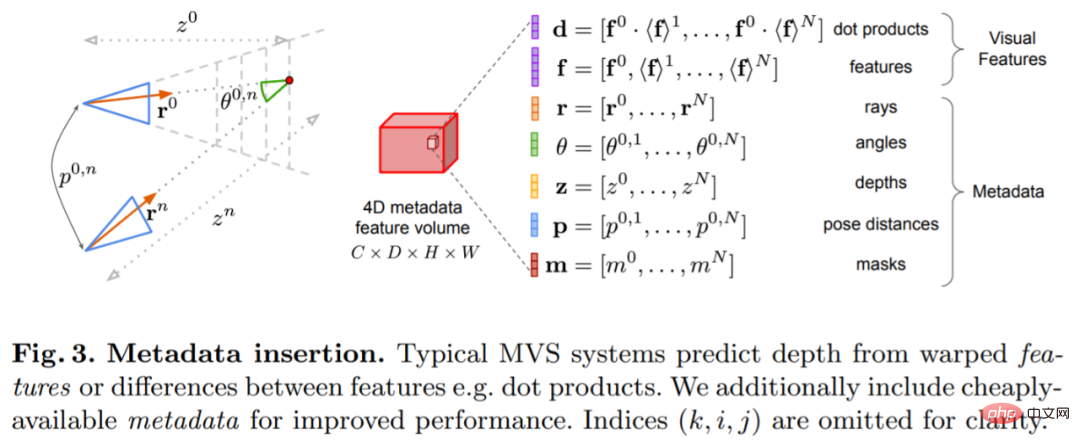
Kunci kepada penyelidikan ini adalah untuk menyuntik metadata sedia ada ke dalam volum kos bersama-sama ciri imej dalam biasa untuk membenarkan akses rangkaian kepada maklumat yang berguna, seperti sebagai geometri dan maklumat pose kamera relatif. Rajah 3 menunjukkan pembinaan isipadu ciri secara terperinci. Dengan menyepadukan maklumat yang belum diterokai sebelum ini, model kami mampu mengatasi dengan ketara kaedah sebelumnya dalam ramalan mendalam tanpa volum kos 4D yang mahal, gabungan temporal yang kompleks dan proses Gaussian.
Kajian ini dilaksanakan menggunakan PyTorch dan menggunakan EfficientNetV2 S sebagai tulang belakang, yang mempunyai penyahkod serupa dengan UNet++. Selain itu, mereka juga menggunakan ResNet18 2 blok pertama telah digunakan untuk pengekstrakan ciri yang sepadan, pengoptimumnya ialah AdamW, dan ia mengambil masa 36 jam untuk disiapkan pada dua 40GB A100 GPU.
Reka bentuk seni bina rangkaian
Rangkaian dilaksanakan berdasarkan seni bina pengekod-penyahkod konvolusi 2D. Apabila membina rangkaian sedemikian, penyelidikan mendapati bahawa terdapat beberapa pilihan reka bentuk penting yang boleh meningkatkan ketepatan ramalan kedalaman dengan ketara, terutamanya termasuk:
Panduan volum kos asas: Walaupun temporal berasaskan RNN kaedah gabungan sering digunakan, tetapi ia meningkatkan kerumitan sistem dengan ketara. Sebaliknya, kajian menjadikan gabungan volum kos semudah mungkin dan mendapati bahawa hanya menambah kos pemadanan produk titik antara paparan rujukan dan setiap paparan sumber boleh memberikan hasil yang berdaya saing dengan anggaran kedalaman SOTA.
Pengekod imej dan pengekod padanan ciri: Kajian terdahulu telah menunjukkan bahawa pengekod imej adalah sangat penting untuk anggaran kedalaman, kedua-dua dalam anggaran monokular dan berbilang paparan. Contohnya, DeepVideoMVS menggunakan MnasNet sebagai pengekod imej, yang mempunyai kependaman yang agak rendah. Kajian mengesyorkan menggunakan pengekod EfficientNetv2 S yang kecil tetapi lebih berkuasa, yang meningkatkan ketepatan anggaran kedalaman dengan ketara, walaupun ini melibatkan kos peningkatan bilangan parameter dan pengurangan 10% dalam kelajuan pelaksanaan.
Menggabungkan ciri imej berskala ke dalam pengekod volum kos: Dalam stereo kedalaman dan stereo berbilang paparan berasaskan CNN, ciri imej biasanya digabungkan dengan output volum kos pada satu skala. Baru-baru ini, DeepVideoMVS mencadangkan untuk mencantumkan ciri imej dalam pada pelbagai skala, menambah sambungan langkau antara pengekod imej dan pengekod volum kos pada semua resolusi. Ini berguna untuk rangkaian gabungan berasaskan LSTM, dan kajian mendapati ia juga penting untuk seni binanya.
Eksperimen
Kajian ini melatih dan menilai kaedah yang dicadangkan pada dataset pembinaan semula pemandangan 3D ScanNetv2. Jadual 1 di bawah menggunakan metrik yang dicadangkan oleh Eigen et al (2014) untuk menilai prestasi ramalan kedalaman beberapa model rangkaian.
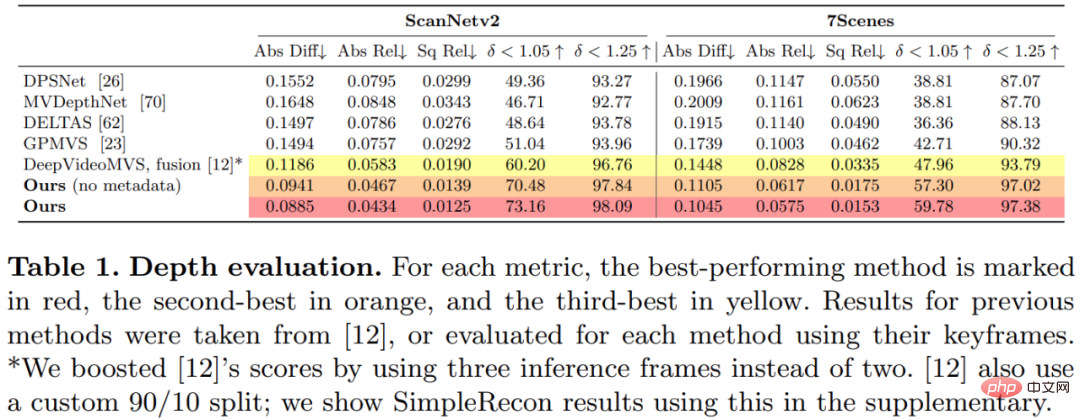
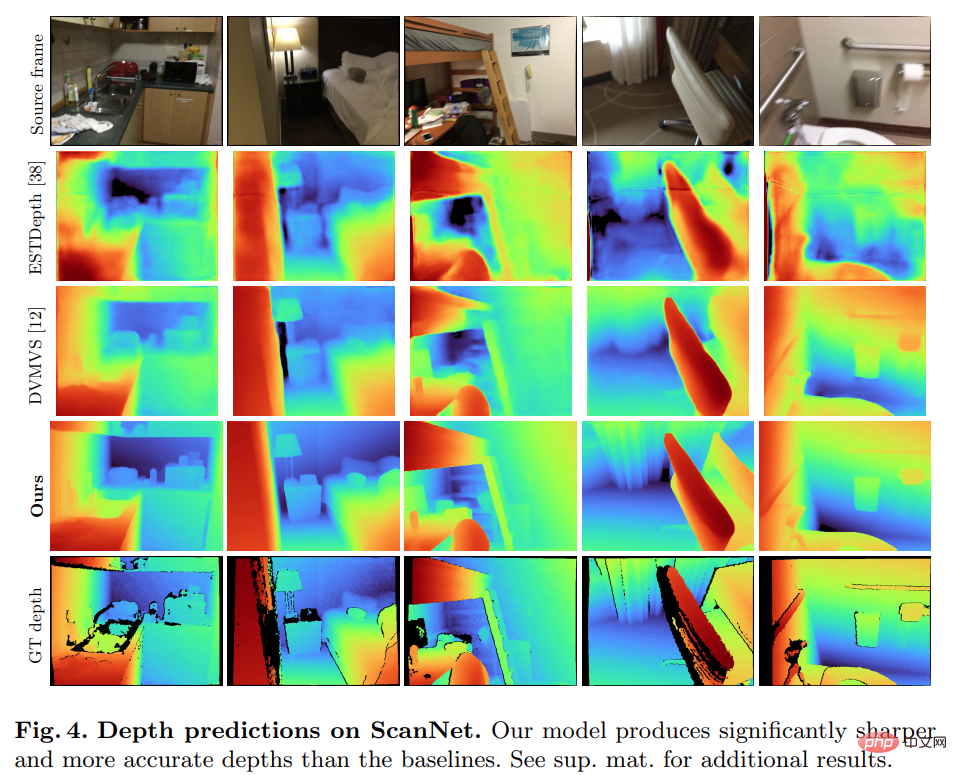
Anehnya, model yang dicadangkan dalam kajian ini tidak menggunakan lilitan 3D tetapi mengatasi semua model garis dasar dalam petunjuk ramalan mendalam. Tambahan pula, model garis dasar yang tidak menggunakan pengekodan metadata juga berprestasi lebih baik daripada kaedah sebelumnya, menunjukkan bahawa rangkaian 2D yang direka bentuk dan terlatih adalah mencukupi untuk anggaran kedalaman berkualiti tinggi. Rajah 4 dan 5 di bawah menunjukkan keputusan kualitatif untuk kedalaman dan normal.

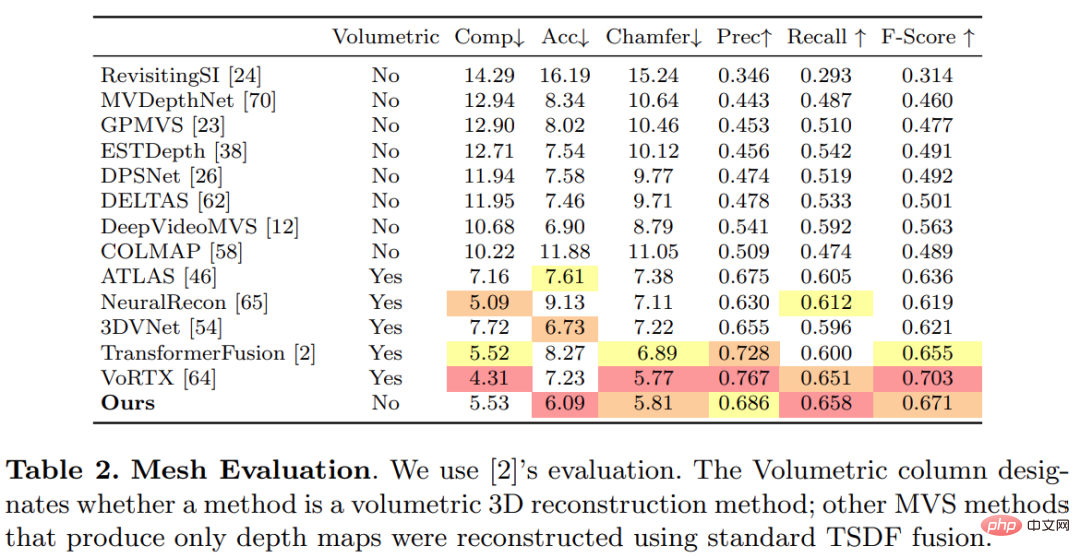
Kajian ini menggunakan protokol standard yang ditubuhkan oleh TransformerFusion untuk penilaian pembinaan semula 3D, dan hasilnya ditunjukkan dalam Jadual 2 di bawah.
Untuk aplikasi pembinaan semula 3D dalam talian dan interaktif, mengurangkan kependaman sensor adalah penting. Jadual 3 di bawah menunjukkan masa pengiraan ensemble bagi setiap bingkai bagi setiap model yang diberi bingkai RGB baharu.

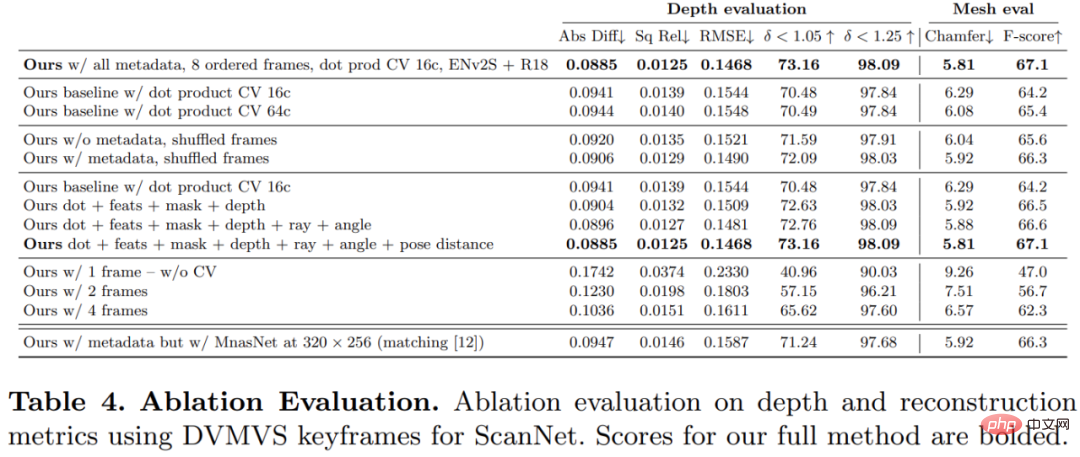
Untuk mengesahkan keberkesanan setiap komponen dalam kaedah yang dicadangkan dalam kajian ini, penyelidik menjalankan eksperimen ablasi, dan hasilnya ditunjukkan dalam Jadual 4 di bawah.
Pembaca yang berminat boleh membaca teks asal kertas kerja untuk mengetahui lebih lanjut butiran penyelidikan.
Atas ialah kandungan terperinci A100 melaksanakan kaedah pembinaan semula 3D tanpa lilitan 3D, dan hanya mengambil masa 70ms untuk setiap pembinaan semula bingkai. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI