
Rumah >Peranti teknologi >AI >Tingkatkan prestasi AI hujung ke hujung melalui gabungan operator tersuai
Tingkatkan prestasi AI hujung ke hujung melalui gabungan operator tersuai

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-06 15:52:081298semak imbas
Pengoptimuman graf memainkan peranan penting dalam mengurangkan masa dan sumber yang digunakan oleh latihan dan inferens model AI. Fungsi penting pengoptimuman graf adalah untuk menggabungkan operator yang boleh digabungkan dalam model, dengan itu meningkatkan kecekapan pengkomputeran dengan mengurangkan penggunaan memori dan pemindahan data dalam memori berkelajuan rendah. Walau bagaimanapun, adalah sangat sukar untuk melaksanakan penyelesaian bahagian belakang yang boleh menyediakan pelbagai gabungan operator, menghasilkan gabungan operator yang sangat terhad yang boleh digunakan oleh model AI pada perkakasan sebenar.
Perpustakaan Inti Tersusun (CK) bertujuan untuk menyediakan satu set penyelesaian bahagian belakang untuk gabungan operator pada GPU AMD. CK menggunakan bahasa pengaturcaraan tujuan umum HIP C++ dan sumber terbuka sepenuhnya. Konsep reka bentuknya termasuk:
- Prestasi tinggi & produktiviti tinggi: Teras CK ialah satu set modul asas yang direka dengan teliti, sangat dioptimumkan dan boleh diguna semula. Semua operator dalam perpustakaan CK dilaksanakan dengan menggabungkan modul asas ini. Menggunakan semula modul asas ini sangat memendekkan kitaran pembangunan algoritma bahagian belakang sambil memastikan prestasi tinggi.
- Mahir dalam masalah AI semasa dan cepat menyesuaikan diri dengan masalah AI masa hadapan: CK menyasarkan untuk menyediakan satu set lengkap penyelesaian bahagian belakang pengendali AI, yang membolehkan gabungan operator yang kompleks keseluruhan bahagian belakang yang akan dilaksanakan menggunakan CK tanpa bergantung pada perpustakaan pengendali luaran. Modul asas boleh guna semula CK mencukupi untuk melaksanakan pelbagai pengendali dan gabungannya diperlukan oleh model AI biasa (penglihatan mesin, pemprosesan bahasa semula jadi, dsb.). Apabila model AI yang baru muncul memerlukan pengendali baharu, CK juga akan menyediakan modul asas yang diperlukan.
- Alat yang ringkas tetapi berkuasa untuk pakar sistem AI: CK Semua pengendali dilaksanakan menggunakan templat HIP C++. Pakar sistem AI boleh menyesuaikan sifat pengendali ini melalui templat instantiasi, seperti jenis data, jenis operasi meta, format storan tensor, dsb. Ini biasanya hanya memerlukan beberapa baris kod.
- Antara muka HIP C++ yang mesra: Pembangun algoritma HPC telah mendorong sempadan pecutan pengkomputeran AI. Konsep reka bentuk penting CK adalah untuk memudahkan pembangun algoritma HPC menyumbang kepada pecutan AI. Oleh itu, semua modul teras CK dilaksanakan dalam HIP C++ dan bukannya Perwakilan Pertengahan (IR). Pembangun algoritma HPC menulis algoritma secara langsung dalam format C++ yang biasa mereka gunakan, tanpa perlu menulis Pas Pengkompil untuk algoritma tertentu, seperti halnya dengan perpustakaan pengendali berasaskan IR. Melakukannya boleh meningkatkan kelajuan lelaran algoritma.
- Kemudahalihan: Pengoptimuman graf hari ini menggunakan CK sebagai bahagian belakang akan dapat dialihkan ke semua GPU AMD akan datang, dan akhirnya akan dialihkan ke CPU AMD [2].
- Kod sumber CK: https://github.com/ROCmSoftwarePlatform/composable_kernel
Konsep Teras
CK memperkenalkan dua konsep untuk meningkatkan produktiviti pembangun bahagian belakang:
1 Pengenalan Pecah Tanah "Transformasi Koordinat Tensor" Mengurangkan kerumitan penulisan pengendali AI. Penyelidikan ini mempelopori takrifan set modul asas Transformasi Koordinat Tensor yang boleh diguna semula dan menggunakannya untuk menyatakan semula pengendali AI yang kompleks (seperti konvolusi, pengurangan normalisasi kumpulan, Depth2Space, dll.) dengan cara yang teliti secara matematik ke dalam AI yang paling asas operator (GEMM, pengurangan 2D, pemindahan tensor, dll.). Teknologi ini membolehkan algoritma yang ditulis untuk pengendali AI asas digunakan secara langsung pada semua pengendali AI kompleks yang sepadan tanpa perlu menulis semula algoritma.
2. Paradigma pengaturcaraan berasaskan jubin: Membangunkan algoritma hujung belakang untuk gabungan operator boleh dilihat sebagai mula-mula membuka setiap operator pra-gabungan (operator bebas) kepada banyak "Kepingan kecil" operasi data, dan kemudian gabungkan operasi "kepingan kecil" ini ke dalam operator bercantum. Setiap operasi "blok kecil" itu sepadan dengan pengendali bebas asal, tetapi data yang dikendalikan hanyalah sebahagian (jubin) daripada tensor asal, jadi operasi "blok kecil" sedemikian dipanggil Operator Tensor Jubin. Pustaka CK mengandungi satu set pelaksanaan Operator Tensor Jubin yang sangat dioptimumkan, dan semua pengendali bebas AI dan operator gabungan dalam CK dilaksanakan menggunakan mereka. Pada masa ini, Operator Tensor Jubin ini termasuk GEMM Jubin, Pengurangan Jubin dan Pemindahan Tensor Jubin. Setiap Operator Tensor Jubin mempunyai pelaksanaan untuk blok benang GPU, meledingkan dan benang.
Transformasi Koordinat Tensor dan Operator Tensor Jubin bersama-sama membentuk modul asas boleh guna semula CK.
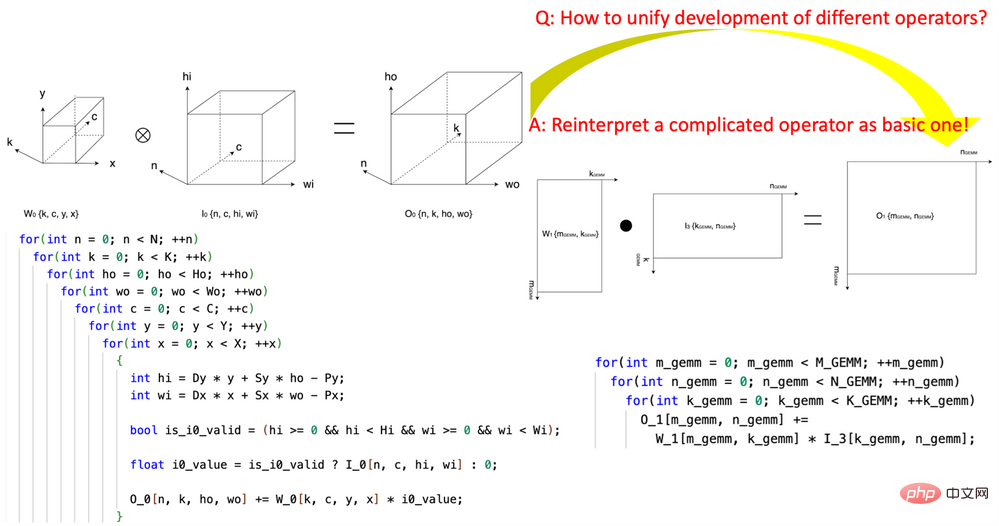
Rajah 1, menggunakan modul asas Transformasi Koordinat Tensor CK untuk menyatakan pengendali konvolusi ke dalam pengendali GEMM
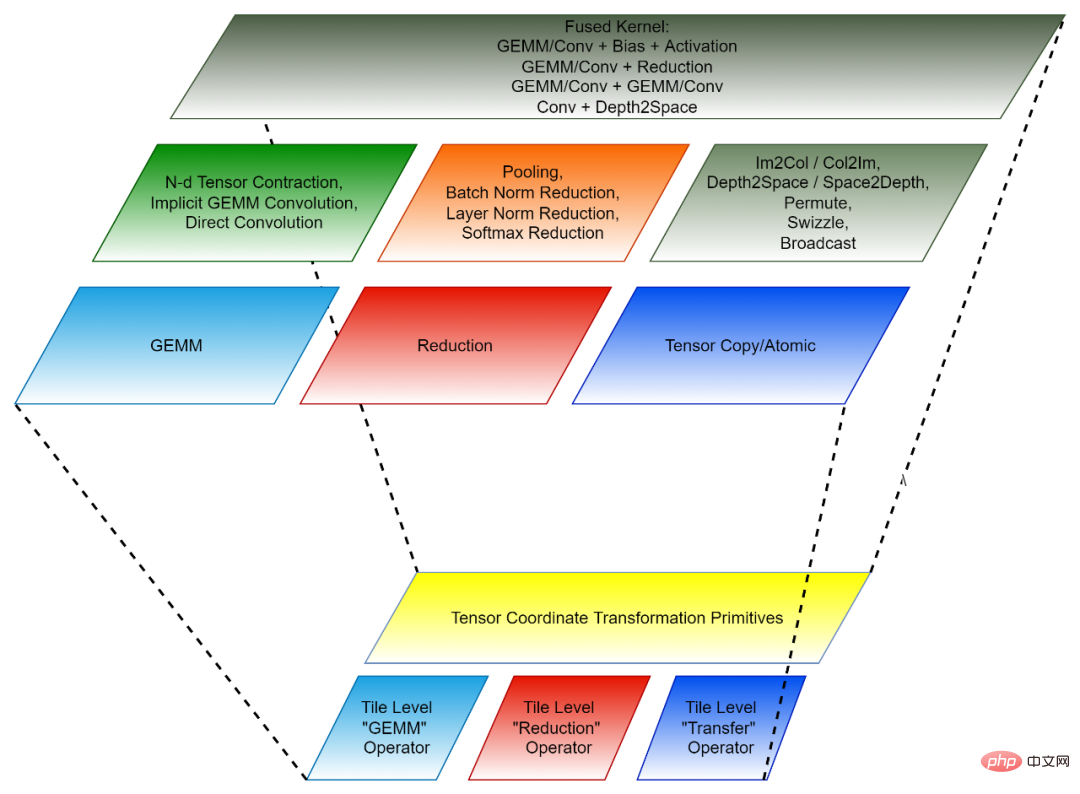
Rajah 2, komposisi CK (bawah: modul asas boleh guna semula; atas: operator bebas dan operator gabungan)
Struktur kod
Struktur perpustakaan CK dibahagikan kepada empat lapisan, dari bawah ke atas: Operator Jubin Templat, Kernel dan Invoker Templat, Inti Instanti dan Invoker dan API Pelanggan [3]. Setiap lapisan sepadan dengan pembangun yang berbeza.
- Pakar sistem AI: "Saya memerlukan penyelesaian bahagian belakang yang menyediakan pengendali bebas dan bersatu berprestasi tinggi yang boleh saya gunakan secara langsung." API Klien dan Kernel dan Invoker Instantiated yang digunakan dalam contoh ini [4] menyediakan objek pra-instantiated dan compiled untuk memenuhi keperluan pembangun jenis ini.
- Pakar sistem AI: "Saya melakukan kerja pengoptimuman graf terkini untuk rangka kerja AI sumber terbuka. Saya memerlukan kernel berprestasi tinggi yang boleh menyediakan semua operator gabungan diperlukan untuk pengoptimuman graf Pada masa yang sama, saya juga perlu menyesuaikan kernel ini, jadi penyelesaian kotak hitam seperti "ambil atau tinggalkan" tidak dapat memenuhi keperluan saya. Lapisan Kernel dan Invoker Templat memenuhi jenis pembangun ini. Contohnya, dalam contoh [5] ini, pembangun boleh menggunakan lapisan Kernel dan Invoker Templated untuk membuat instantiat kernel FP16 GEMM + Tambah + Tambah + FastGeLU yang diperlukan.
- Pakar algoritma HPC: “Pasukan saya membangunkan algoritma back-end berprestasi tinggi untuk model AI yang sentiasa berulang dalam syarikat Kami mempunyai pakar algoritma HPC dalam pasukan. tetapi kami masih berharap untuk menggunakan kompleks Menggunakan dan menambah baik kod sumber yang sangat dioptimumkan yang disediakan oleh vendor perkakasan meningkatkan produktiviti kami dan membolehkan kod kami dialihkan ke seni bina perkakasan masa hadapan Kami berharap dapat melakukan ini tanpa perlu berkongsi kod kami dengan vendor perkakasan. " Lapisan Operator Jubin Templat boleh membantu pembangun jenis ini. Contohnya, dalam kod [6] ini, pembangun menggunakan Operator Jubin Templat untuk melaksanakan saluran paip pengoptimuman GEMM.
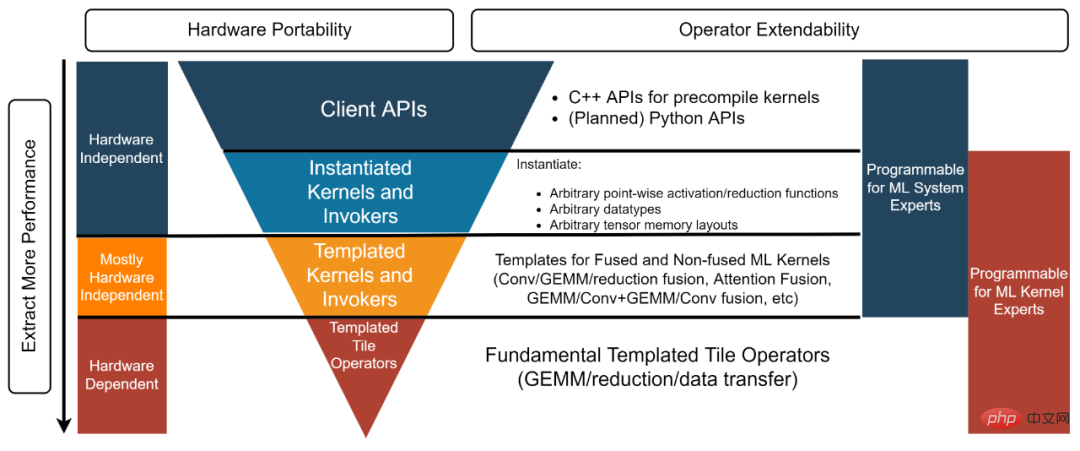
Rajah 3, struktur empat lapisan perpustakaan CK
Inferens model hujung ke hujung berdasarkan AITemplate + CK
AITemplate Meta [7] (AIT) ialah sistem inferens AI yang menyatukan GPU AMD dan Nvidia. AITemplate menggunakan CK sebagai bahagian belakangnya pada GPU AMD, menggunakan lapisan Kernel dan Invoker Templated CK.
AITemplate + CK mencapai prestasi inferens terkini pada berbilang model AI penting pada AMD Instinct™ MI250. Takrifan pengendali gabungan yang paling maju dalam CK didorong oleh visi pasukan AITemplate. Banyak algoritma pengendali gabungan juga direka bentuk bersama oleh pasukan CK dan AITemplate.
Artikel ini membandingkan prestasi beberapa model hujung ke hujung pada AMD Instinct MI250 dan produk yang serupa [8]. Semua data prestasi model AMD Instinct MI250 AI dalam artikel ini diperoleh menggunakan AITemplate[9] + CK[10].
Eksperimen
ResNet-50
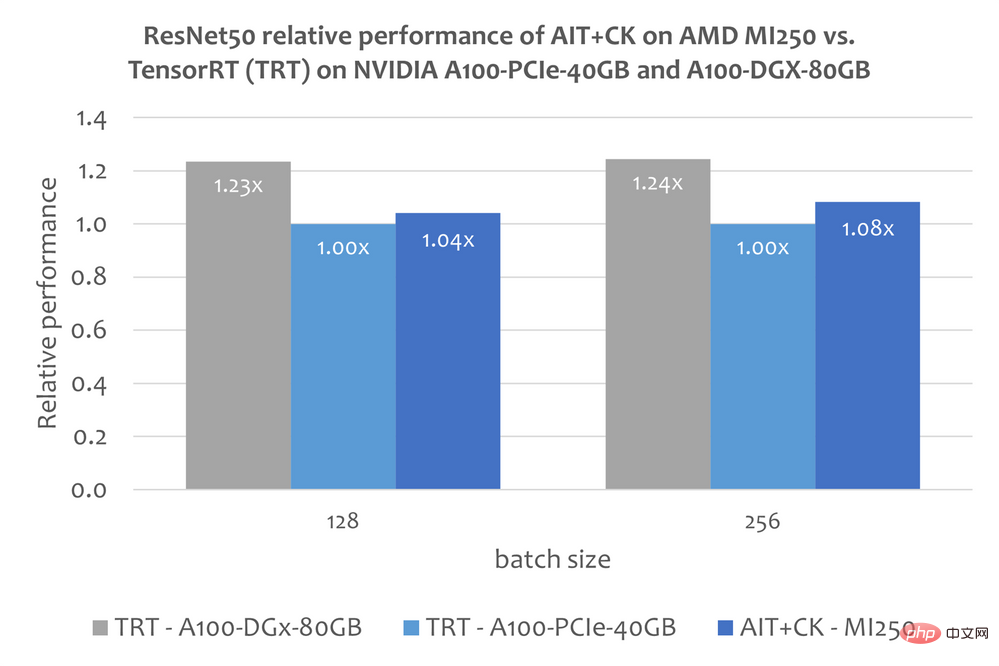
Imej di bawah menunjukkan AIT pada AMD Instinct MI250 + Perbandingan prestasi CK dengan TensorRT v8.5.0.12 [11] (TRT) pada A100-PCIe-40GB dan A100-DGX-80GB. Keputusan menunjukkan bahawa AIT + CK pada AMD Instinct MI250 mencapai pecutan 1.08x berbanding TRT pada A100-PCIe-40GB.
BERT
Templat operator gabungan GEMM + Softmax + GEMM Berkelompok berdasarkan pelaksanaan CK, yang boleh menghapuskan sepenuhnya pemindahan hasil perantaraan antara Unit Pengiraan GPU (Unit Pengiraan) dan HBM. Dengan menggunakan templat operator gabungan ini, banyak masalah dalam lapisan perhatian yang asalnya terikat lebar jalur telah menjadi kesesakan pengiraan (terikat pengiraan), yang boleh menggunakan kuasa pengkomputeran GPU dengan lebih baik. Pelaksanaan CK ini sangat diilhamkan oleh FlashAttention [12] dan mengurangkan lebih banyak pengendalian data daripada pelaksanaan FlashAttention yang asal.
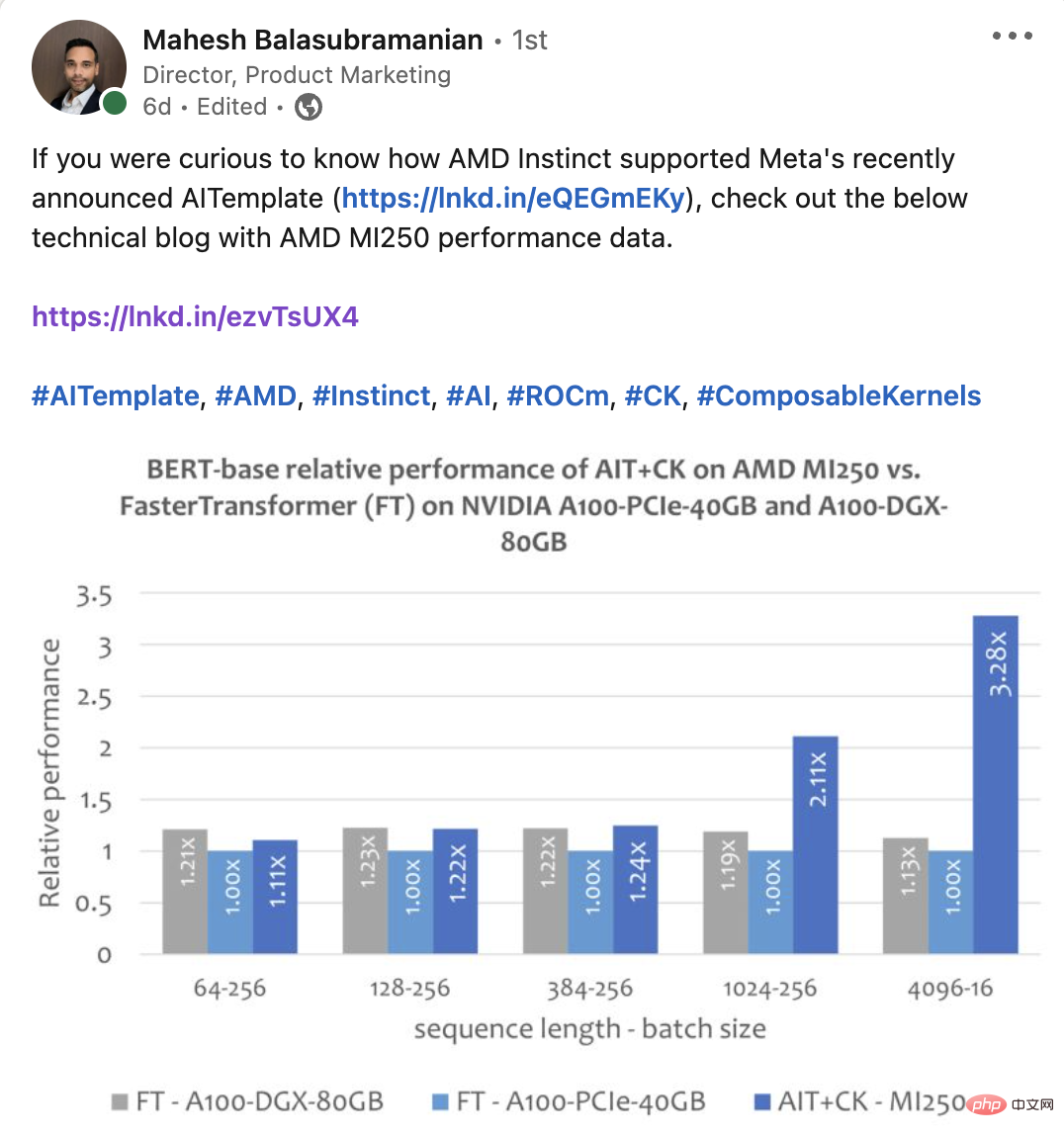
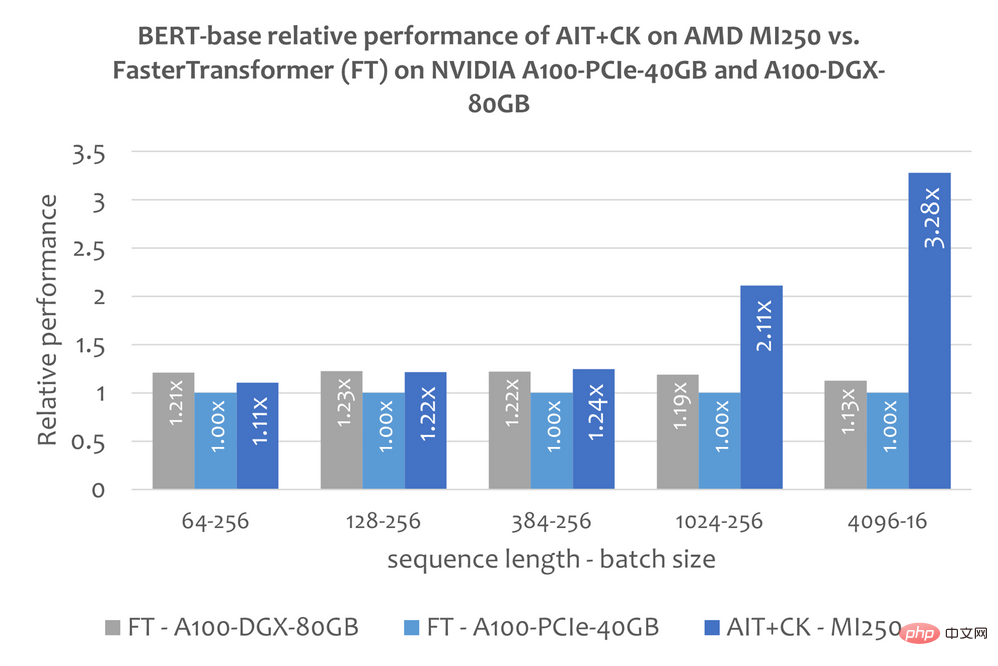
Gambar di bawah menunjukkan AIT + CK pada AMD Instinct MI250 dengan pembetulan pepijat FasterTransformer v5.1.1 pada A100-PCIe-40GB dan A100-DGX-80GB [13] (FT) Perbandingan prestasi daripada model Bert Base (tanpa sarung). FT akan melimpahkan memori GPU pada Batch 32 pada A100-PCIe-40GB dan A100-DGX-80GB apabila Jujukan ialah 4096. Oleh itu, apabila Jujukan ialah 4096, artikel ini hanya menunjukkan keputusan Kumpulan 16. Keputusan menunjukkan bahawa AIT + CK pada AMD Instinct MI250 mencapai pecutan 3.28x FT berbanding FT pada A100-PCIe-40GB, dan kelajuan 2.91x FT berbanding dengan A100-DGX-80GB.
Vision Transformer (VIT)
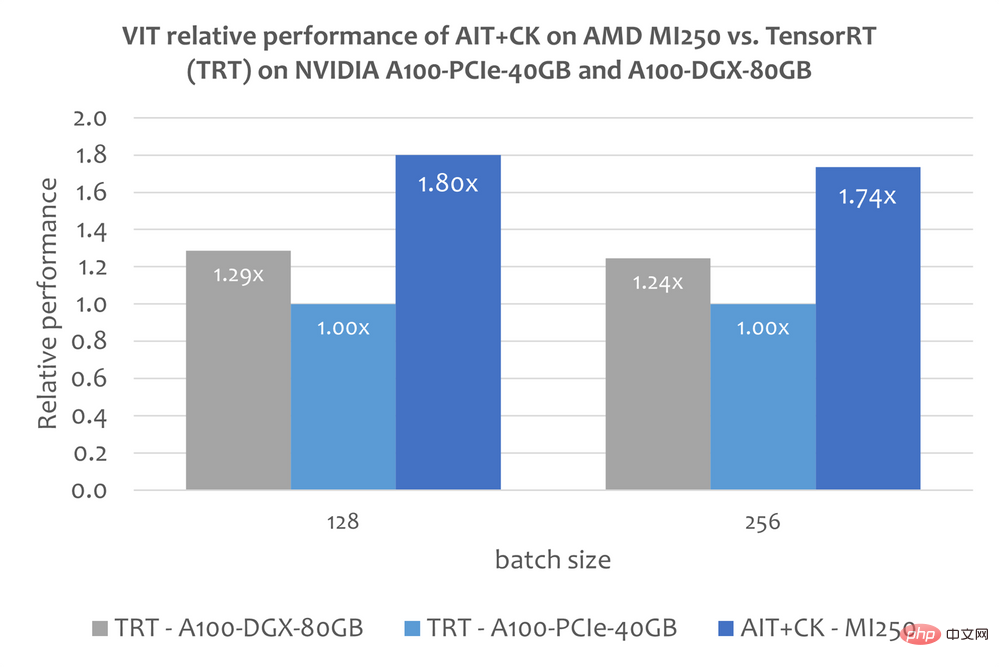
Imej di bawah menunjukkan AMD Perbandingan Prestasi Naluri AIT + CK pada MI250 dengan Vision Transformer Base (imej 224x224) TensorRT v8.5.0.12 (TRT) pada A100-PCIe-40GB dan A100-DGX-80GB. Keputusan menunjukkan bahawa AIT + CK pada AMD Instinct MI250 mencapai kelajuan 1.8x berbanding TRT pada A100-PCIe-40GB, dan kelajuan 1.4x berbanding TRT pada A100-DGX-80GB.
Resapan Stabil
Resapan Stabil hujung-ke-hujung
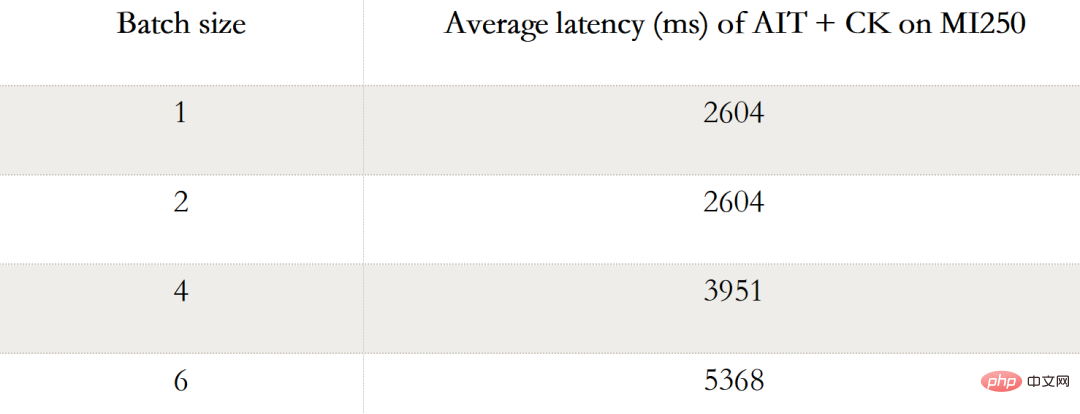
Jadual berikut menunjukkan data prestasi AIT + CK Stable Diffusion hujung ke hujung (Batch 1, 2, 4, 6) pada AMD Instinct MI250. Apabila Batch ialah 1, hanya satu GCD digunakan pada MI250, manakala dalam Batch 2, 4 dan 6, kedua-dua GCD digunakan.
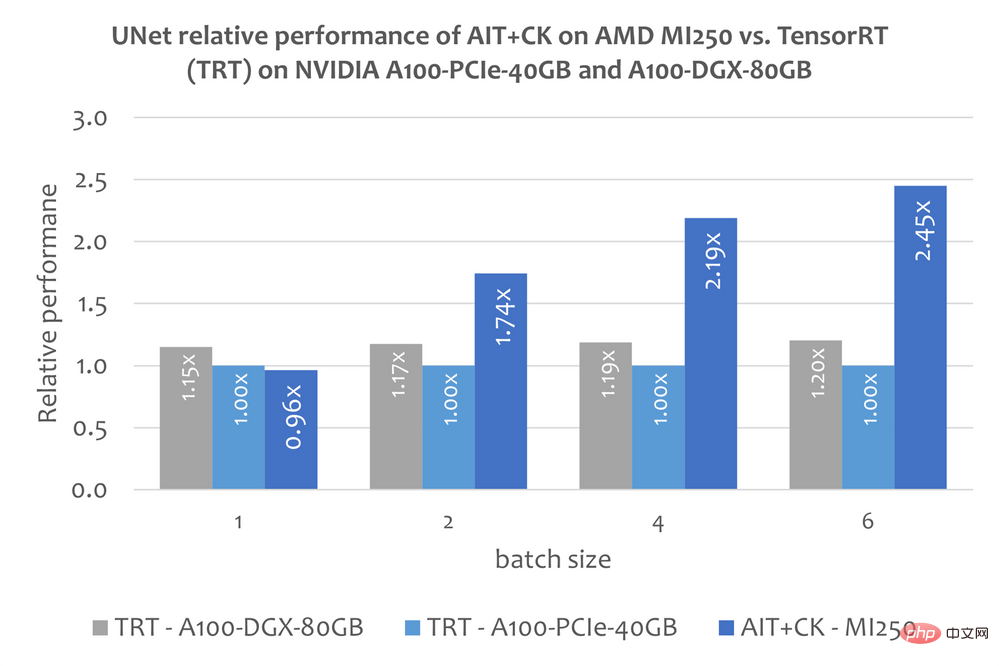
UNet dalam Stable Diffusion
Walau bagaimanapun, artikel ini belum lagi mengenai penggunaan TensorRT untuk menjalankan Stable Penyebaran maklumat awam hujung ke hujung tentang model akhir. Tetapi artikel ini "Jadikan resapan stabil 25% lebih pantas menggunakan TensorRT" [14] menerangkan cara menggunakan TensorRT untuk mempercepatkan model UNet dalam Resapan Stabil. UNet ialah bahagian Resapan Stabil yang paling penting dan memakan masa, jadi prestasi UNet secara kasar menggambarkan prestasi Resapan Stabil.
Imej di bawah menunjukkan AIT+CK pada AMD Instinct MI250 lwn. UNet untuk TensorRT v8.5.0.12 (TRT) pada A100-PCIe-40GB dan A100-DGX-80GB Perbandingan prestasi . Keputusan menunjukkan bahawa AIT + CK pada AMD Instinct MI250 mencapai kelajuan 2.45x berbanding TRT pada A100-PCIe-40GB, dan kelajuan 2.03x berbanding TRT pada A100-DGX-80GB.
Maklumat lanjut
halaman web ROCm: AMD ROCm™ Open Software Platform |. AMD
Portal Maklumat ROCm: Dokumentasi AMD - Portal
AMD Instinct Accelerators: AMD Instinct™ Accelerators
Hab Infinity AMD: Hab AMD Infinity | Liu ialah Jurutera Pembangunan Perisian PMTS di AMD Jing Zhang ialah Jurutera Pembangunan Perisian SMTS di AMD Penyiaran mereka adalah pendapat mereka sendiri dan mungkin tidak mewakili kedudukan, strategi atau pendapat AMD , AMD tidak bertanggungjawab ke atas kandungan tapak terpaut tersebut dan tiada pengendorsan yang tersirat 2.CK untuk CPU sedang dalam fasa pembangunan awal. 3.C++ API buat masa ini, API Python sedang dalam perancangan. 4.Contoh CK "API Pelanggan" untuk GEMM + Tambah + Tambah + Pengendali gabungan FastGeLU. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
8.MI200-71: Ujian Dijalankan oleh AMD MLSE 10.23.22 menggunakan AITemplate https://github.com/ROCmSoftwarePlatform/AITemplate, commit f940d9b) + Composable Kernel https://github.com/ROCmSoftwarePlatform/composable_kernel, commit 40942b9) dengan ROCm™5.3 berjalan pada pelayan 2x7 AMD 1EPYC6-Core3EEPYC 4x AMD Instinct MI250 OAM (128 GB HBM2e) GPU 560W dengan teknologi AMD Infinity Fabric™ lwn. TensorRT v8.5.0.12 dan FasterTransformer (v5.1.1 pembetulan pepijat) dengan CUDA® 11.8 berjalan pada pelayan 2x AMD EPYC 7742 Processor 64 dengan 4x Nvidia A100-PCIe-40GB (250W) GPU dan TensorRT v8.5.0.12 dan FasterTransformer (v5.1.1 pembetulan pepijat) dengan CUDA® 11.8 berjalan pada pelayan 2xAMD EPYC 7742 64-Core Processor dengan 8x4 NVIDIA A1000GB (SXM NVIDIA A1000GB ) GPU. Pengeluar pelayan mungkin berbeza konfigurasi, menghasilkan hasil yang berbeza. Prestasi mungkin berbeza-beza berdasarkan faktor termasuk penggunaan pemacu dan pengoptimuman terkini.
9.https://github.com/ROCmSoftwarePlatform/AITemplate/tree/f940d9b7ac8b976fba127e2c269>
10.https://github.com/ROCmSoftwarePlatform/composable_kernel/tree/40942b909801dd721769834fc61ad201b5795...
Repositori 11.TensorRT GitHub. https://github.com/NVIDIA/TensorRT12.FlashAttention: Perhatian Tepat Cepat dan Cekap Memori dengan Kesedaran IO . https://arxiv.org/abs/2205.14135
13.Repositori GitHub FasterTransformer. https://github.com/NVIDIA/FasterTransformer
14.Menjadikan resapan stabil 25% lebih pantas menggunakan TensorRT. https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/
15 .Sepanjang masa mereka dalam AMD
Atas ialah kandungan terperinci Tingkatkan prestasi AI hujung ke hujung melalui gabungan operator tersuai. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI