
Rumah >Peranti teknologi >AI >Penyelidikan HKUST & MSRA: Mengenai penukaran imej-ke-imej, Finetuning adalah semua yang anda perlukan
Penyelidikan HKUST & MSRA: Mengenai penukaran imej-ke-imej, Finetuning adalah semua yang anda perlukan

- 王林ke hadapan
- 2023-05-04 23:10:061012semak imbas

Banyak projek pengeluaran kandungan memerlukan penukaran lakaran mudah kepada gambar realistik, yang melibatkan terjemahan imej-ke-imej, yang menggunakan pembelajaran model generatif mendalam Taburan bersyarat imej semula jadi yang diberikan input.
Konsep asas penukaran imej-ke-imej ialah menggunakan rangkaian neural yang telah terlatih untuk menangkap manifold imej semula jadi. Transformasi imej adalah serupa dengan merentasi manifold dan mencari titik semantik input yang boleh dilaksanakan. Sistem pra-melatih rangkaian sintetik menggunakan banyak imej untuk memberikan output yang boleh dipercayai daripada sebarang pensampelan ruang terpendamnya. Melalui rangkaian sintetik yang telah terlatih, latihan hiliran menyesuaikan input pengguna kepada perwakilan terpendam model.
Selama bertahun-tahun kami telah melihat banyak kaedah khusus tugasan mencapai tahap SOTA, tetapi penyelesaian semasa bergelut untuk mencipta imej kesetiaan tinggi untuk kegunaan dunia nyata.

Dalam kertas kerja baru-baru ini, penyelidik dari Universiti Sains dan Teknologi Hong Kong dan Microsoft Research Asia percaya bahawa untuk penukaran imej kepada imej, pra-latihan adalah Apa yang anda perlukan. . Kaedah sebelumnya memerlukan reka bentuk seni bina khusus dan melatih model transformasi tunggal dari awal, menjadikannya sukar untuk menjana adegan kompleks dengan kualiti tinggi, terutamanya apabila data latihan berpasangan tidak mencukupi.
Oleh itu, kami menganggap setiap masalah terjemahan imej-ke-imej sebagai tugas hiliran dan memperkenalkan rangka kerja umum ringkas yang menggunakan model resapan terlatih untuk menyesuaikan diri dengan pelbagai terjemahan imej-ke-imej. Mereka memanggil model terjemahan imej-ke-imej yang dicadangkan sebagai PITI (terjemahan imej-ke-imej berasaskan pralatihan). Di samping itu, penyelidik juga mencadangkan untuk menggunakan latihan lawan untuk meningkatkan sintesis tekstur dalam latihan model resapan, dan menggabungkannya dengan pensampelan berpandu ternormal untuk meningkatkan kualiti penjanaan.
Akhir sekali, penyelidik menjalankan perbandingan empirikal yang meluas mengenai pelbagai tugasan pada penanda aras yang mencabar seperti ADE20K, COCO-Stuff dan DIODE, menunjukkan bahawa imej yang disintesis PITI memaparkan realisme dan kesetiaan Perbelanjaan yang tidak pernah berlaku sebelum ini.

- Pautan kertas: https://arxiv.org/pdf/2205.12952.pdf
- Laman utama projek: https://tengfei-wang .github.io/PITI/index.html
GAN sudah mati, model resapan masih hidup
Pengarang tidak menggunakan GAN yang berprestasi terbaik dalam bidang tertentu, tetapi menggunakan model penyebaran , mensintesis pelbagai jenis imej. Kedua, ia harus menjana imej daripada dua jenis kod terpendam: satu yang menerangkan semantik visual dan satu yang menyesuaikan untuk turun naik imej. Semantik, terpendam dimensi rendah adalah penting untuk tugas hiliran. Jika tidak, adalah mustahil untuk mengubah input modal menjadi ruang terpendam yang kompleks. Memandangkan ini, mereka menggunakan GLIDE, model dipacu data yang boleh menjana imej yang berbeza, sebagai penjanaan terlatih sebelum ini. Memandangkan GLIDE menggunakan teks terpendam, ia membenarkan ruang terpendam semantik.
Kaedah resapan dan berasaskan skor menunjukkan kualiti penjanaan merentas penanda aras. Pada ImageNet bersyarat kelas, model ini bersaing dengan kaedah berasaskan GAN dari segi kualiti visual dan kepelbagaian pensampelan. Baru-baru ini, model penyebaran yang dilatih dengan gandingan imej teks berskala besar telah menunjukkan keupayaan yang mengejutkan. Model resapan yang terlatih boleh menyediakan sebelum generatif umum untuk sintesis.
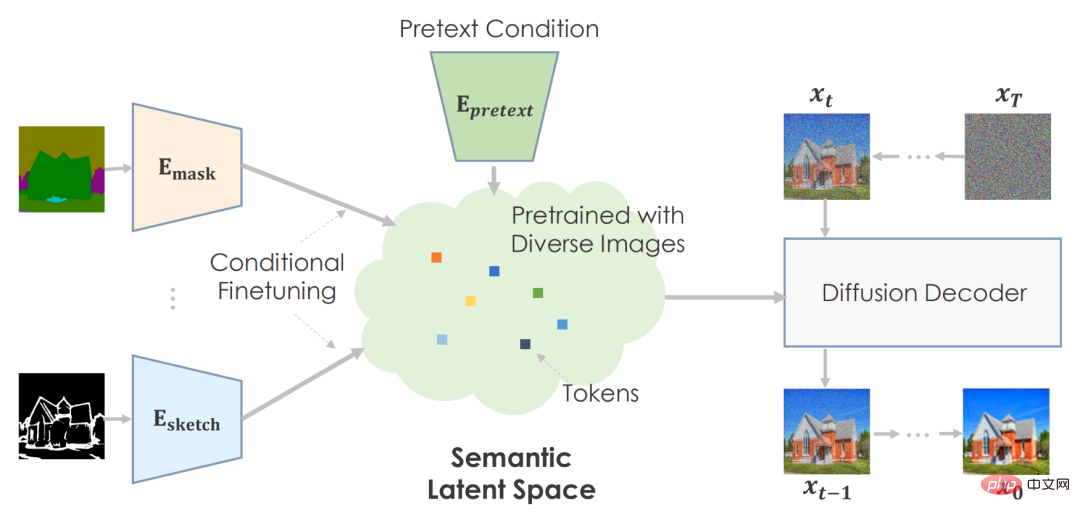
Kerangka
Pengarang boleh menggunakan tugas dalih untuk pra-latihan pada jumlah data yang besar dan membangunkan ruang terpendam yang sangat bermakna untuk meramalkan statistik imej.
Untuk tugasan hiliran, mereka memperhalusi ruang semantik secara bersyarat untuk memetakan persekitaran khusus tugasan. Mesin ini mencipta visual yang boleh dipercayai berdasarkan maklumat yang telah dilatih.
Pengarang mengesyorkan menggunakan input semantik untuk pra-melatih model resapan. Mereka menggunakan model GLIDE berhawa dingin dan terlatih imej. Rangkaian Transformer mengekod input teks dan mengeluarkan token untuk model resapan. Seperti yang dirancang, adalah wajar untuk teks dibenamkan dalam ruang.

Gambar di atas adalah hasil kerja penulis. Model terlatih meningkatkan kualiti dan kepelbagaian imej berbanding teknik dari awal. Memandangkan set data COCO mempunyai banyak kategori dan gabungan, pendekatan asas tidak dapat memberikan hasil yang cantik dengan seni bina yang menarik. Kaedah mereka boleh mencipta butiran yang kaya dengan semantik yang tepat untuk adegan yang sukar. Gambar menggambarkan kepelbagaian pendekatan mereka.
Eksperimen dan Impak
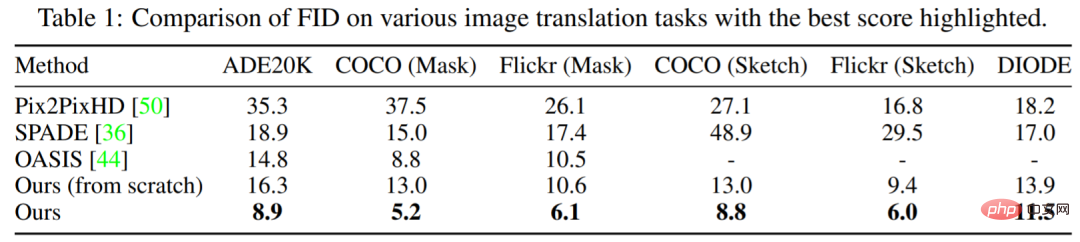
Jadual 1 menunjukkan bahawa prestasi kaedah yang dicadangkan dalam kajian ini sentiasa lebih baik daripada model lain. Berbanding dengan OASIS terkemuka, PITI mencapai peningkatan ketara dalam FID dalam sintesis topeng-ke-imej. Tambahan pula, kaedah ini juga menunjukkan prestasi yang baik dalam tugasan sintesis lakaran-ke-imej dan geometri-ke-imej.
Rajah 3 menunjukkan hasil visualisasi kajian ini pada tugasan yang berbeza. Eksperimen menunjukkan bahawa berbanding dengan kaedah latihan dari awal, model pra-latihan meningkatkan kualiti dan kepelbagaian imej yang dihasilkan dengan ketara. Kaedah yang digunakan dalam kajian ini boleh menghasilkan butiran yang jelas dan semantik yang betul walaupun untuk tugas penjanaan yang mencabar.

Penyelidikan itu turut menjalankan kajian pengguna tentang sintesis topeng-ke-imej pada COCO-Stuff di Amazon Mechanical Turk, dengan 3000 keputusan daripada 20 tiket peserta. Peserta diberi dua imej pada satu masa dan diminta mengundi yang mana satu lebih realistik. Seperti yang ditunjukkan dalam Jadual 2, kaedah yang dicadangkan mengatasi model dari awal dan garis dasar lain secara besar-besaran.

Sintesis imej bersyarat menghasilkan gambar berkualiti tinggi yang memenuhi syarat tertentu. Bidang penglihatan komputer dan grafik menggunakannya untuk mencipta dan memanipulasi maklumat. Pra-latihan berskala besar meningkatkan klasifikasi imej, pengecaman objek dan pembahagian semantik. Apa yang tidak diketahui ialah sama ada pralatihan berskala besar bermanfaat untuk tugas penjanaan umum.
Penggunaan tenaga dan pelepasan karbon adalah isu utama dalam pra-latihan imej. Pra-latihan memerlukan tenaga, tetapi hanya diperlukan sekali sahaja. Penalaan halus bersyarat membolehkan tugas hiliran menggunakan model pra-latihan yang sama. Pralatihan membolehkan model generatif dilatih dengan kurang data latihan, meningkatkan sintesis imej apabila data terhad disebabkan isu privasi atau kos anotasi yang mahal.
Atas ialah kandungan terperinci Penyelidikan HKUST & MSRA: Mengenai penukaran imej-ke-imej, Finetuning adalah semua yang anda perlukan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI