
Rumah >Peranti teknologi >AI >Mengapa DeepMind tidak hadir dalam jamuan GPT? Ternyata saya sedang mengajar robot kecil bermain bola sepak.
Mengapa DeepMind tidak hadir dalam jamuan GPT? Ternyata saya sedang mengajar robot kecil bermain bola sepak.

- 王林ke hadapan
- 2023-05-04 22:31:051258semak imbas
Pada pandangan ramai sarjana, kecerdasan yang terkandung adalah hala tuju yang sangat menjanjikan ke arah AGI, dan kejayaan ChatGPT juga tidak dapat dipisahkan daripada teknologi RLHF berdasarkan pembelajaran pengukuhan. DeepMind vs OpenAI, siapa yang boleh mencapai AGI dahulu jawapannya nampaknya masih belum didedahkan.
Kami tahu bahawa mencipta kecerdasan yang terkandung umum (iaitu, ejen yang bertindak dalam dunia fizikal dengan cara yang tangkas, cekap dan memahami seperti haiwan atau manusia) adalah kunci kepada penyelidik AI dan satu matlamat jangka panjang ahli robotik. Dari segi masa, penciptaan ejen yang diwujudkan pintar dengan keupayaan pergerakan yang kompleks berlaku sejak beberapa tahun lalu, baik dalam simulasi mahupun dalam dunia nyata.
Kemajuan telah meningkat dengan ketara dalam beberapa tahun kebelakangan ini, dengan kaedah berasaskan pembelajaran memainkan peranan utama. Sebagai contoh, pembelajaran peneguhan mendalam telah terbukti dapat menyelesaikan masalah kawalan pergerakan kompleks watak simulasi, termasuk kawalan seluruh badan yang didorong oleh persepsi atau tingkah laku berbilang ejen yang kompleks. Pada masa yang sama, pembelajaran peneguhan mendalam semakin digunakan dalam robot fizikal. Khususnya, robot berkaki empat berkualiti tinggi yang digunakan secara meluas telah menjadi sasaran demonstrasi untuk pembelajaran menjana pelbagai tingkah laku lokomotor yang mantap.
Walau bagaimanapun, pergerakan dalam persekitaran statik hanyalah satu bahagian daripada banyak cara haiwan dan manusia menggunakan badan mereka untuk berinteraksi dengan dunia, dan modaliti pergerakan ini telah digunakan dalam banyak kerja belajar. kawalan seluruh badan dan manipulasi pergerakan telah disahkan, terutamanya untuk robot berkaki empat. Contoh pergerakan yang berkaitan termasuk memanjat, kemahiran bola sepak seperti menggelecek atau menangkap bola, dan gerakan mudah menggunakan kaki.
Antaranya, untuk bola sepak, ia menunjukkan banyak ciri kecerdasan sensorimotor manusia. Kerumitan bola sepak memerlukan pelbagai pergerakan yang sangat tangkas dan dinamik, termasuk berlari, berpusing, mengelak, menendang, melepasi, jatuh dan bangun, dsb. Tindakan ini perlu digabungkan dalam pelbagai cara. Pemain perlu meramal bola, rakan sepasukan dan pemain lawan, dan menyesuaikan tindakan mereka mengikut persekitaran permainan. Kepelbagaian cabaran ini telah diiktiraf dalam komuniti robotik dan AI, dan RoboCup dilahirkan.
Walau bagaimanapun, perlu diingatkan bahawa ketangkasan, fleksibiliti dan reaksi pantas yang diperlukan untuk bermain bola sepak dengan baik, serta peralihan yang lancar antara elemen ini, adalah sangat mencabar dan memakan masa untuk reka bentuk manual robot. Baru-baru ini, kertas kerja baharu daripada DeepMind (kini digabungkan dengan pasukan Google Brain untuk membentuk Google DeepMind) meneroka penggunaan pembelajaran pengukuhan mendalam untuk mempelajari kemahiran bola sepak tangkas untuk robot dwipedal.

Alamat kertas: https://arxiv.org/pdf/2304.13653 .pdf
Laman utama projek: https://sites.google.com/view/op3-soccer
Dalam makalah ini, penyelidik mengkaji kawalan seluruh badan dan interaksi objek robot humanoid kecil dalam persekitaran berbilang ejen dinamik. Mereka menganggap subset masalah bola sepak keseluruhan, melatih robot humanoid kecil kos rendah dengan 20 sendi boleh dikawal untuk bermain permainan bola sepak 1 v1 dan memerhati ciri proprioception dan keadaan permainan. Dengan pengawal terbina dalam, robot bergerak perlahan dan janggal. Walau bagaimanapun, penyelidik menggunakan pembelajaran pengukuhan yang mendalam untuk mensintesis kemahiran motor penyesuaian konteks yang dinamik dan tangkas (seperti berjalan, berlari, berpusing, dan menendang bola dan bangun semula selepas jatuh) yang digabungkan ejen secara semula jadi dan lancar menjadi panjang yang kompleks. -perilaku jangka.
Dalam eksperimen, ejen belajar meramal pergerakan bola, meletakkannya, menyekat serangan dan menggunakan bola yang melantun. Ejen mencapai tingkah laku ini dalam persekitaran berbilang ejen berkat gabungan penggunaan semula kemahiran, latihan hujung ke hujung dan ganjaran mudah. Para penyelidik melatih ejen dalam simulasi dan memindahkan mereka ke robot fizikal, menunjukkan bahawa pemindahan simulasi kepada sebenar adalah mungkin walaupun untuk robot kos rendah.
Biar data bercakap sendiri Kelajuan berjalan robot meningkat sebanyak 156%, masa untuk bangun dikurangkan sebanyak 63%, dan kelajuan menendang bola juga meningkat sebanyak. 24% berbanding garis dasar.
Sebelum masuk ke dalam tafsiran teknikal, mari kita lihat beberapa sorotan robot dalam perlawanan bola sepak 1v1. Contohnya, menembak:


Tendangan penalti:

Pusing, menggelecek dan tendang sekali gus

Menyekat:

Tetapan percubaan
Jika anda mahu robot belajar bermain bola sepak, anda memerlukan beberapa tetapan asas terlebih dahulu.
Dari segi persekitaran, DeepMind mula-mula mensimulasikan dan melatih ejen dalam persekitaran bola sepak tersuai, dan kemudian memindahkan strategi ke persekitaran sebenar yang sepadan, seperti yang ditunjukkan dalam Rajah 1. Persekitaran terdiri daripada padang bola sepak sepanjang 5 m dan lebar 4 m, dengan dua gol, setiap satu dengan lebar pembukaan 0.8 m. Dalam kedua-dua persekitaran simulasi dan sebenar, gelanggang dibatasi oleh tanjakan untuk memastikan bola dalam batas. Gelanggang sebenar ditutup dengan jubin getah untuk mengurangkan risiko merosakkan robot daripada terjatuh dan meningkatkan geseran di atas tanah.
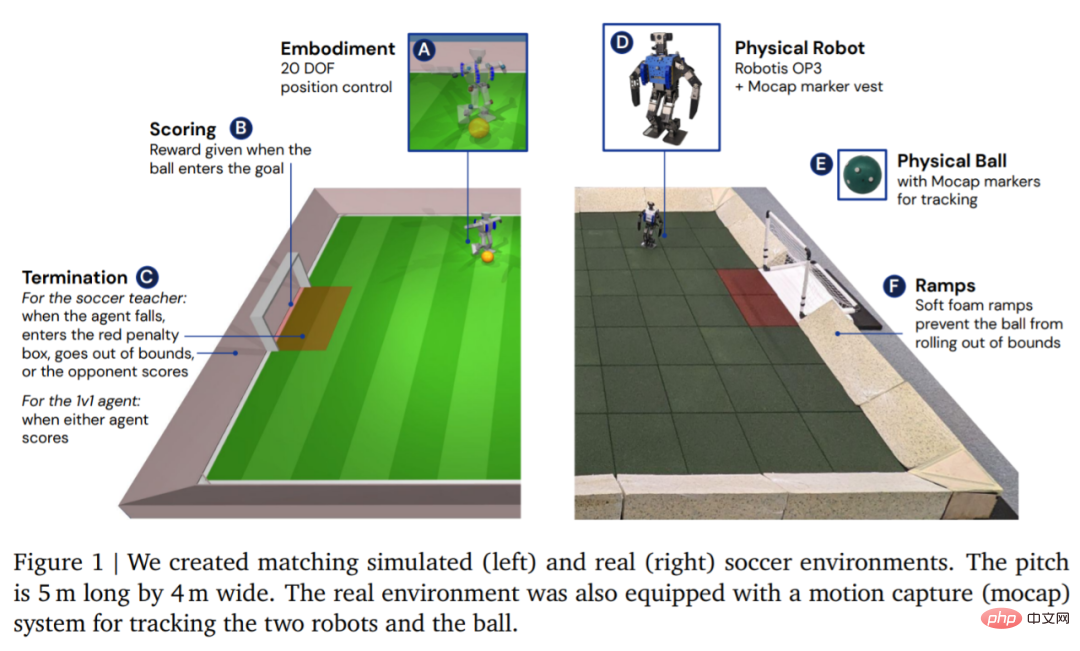
Selepas persekitaran disediakan, langkah seterusnya ialah menyediakan perkakasan dan tangkapan gerakan. DeepMind menggunakan robot Robotis OP3, yang berketinggian 51 cm dan berat 3.5 kg serta digerakkan oleh 20 motor servo. Robot tidak mempunyai GPU atau pemecut khusus lain, jadi semua pengiraan rangkaian saraf dijalankan pada CPU. Di bahagian kepala robot adalah kamera web Logitech C920, yang boleh menyediakan aliran video RGB secara pilihan pada 30 bingkai sesaat.

Kaedah
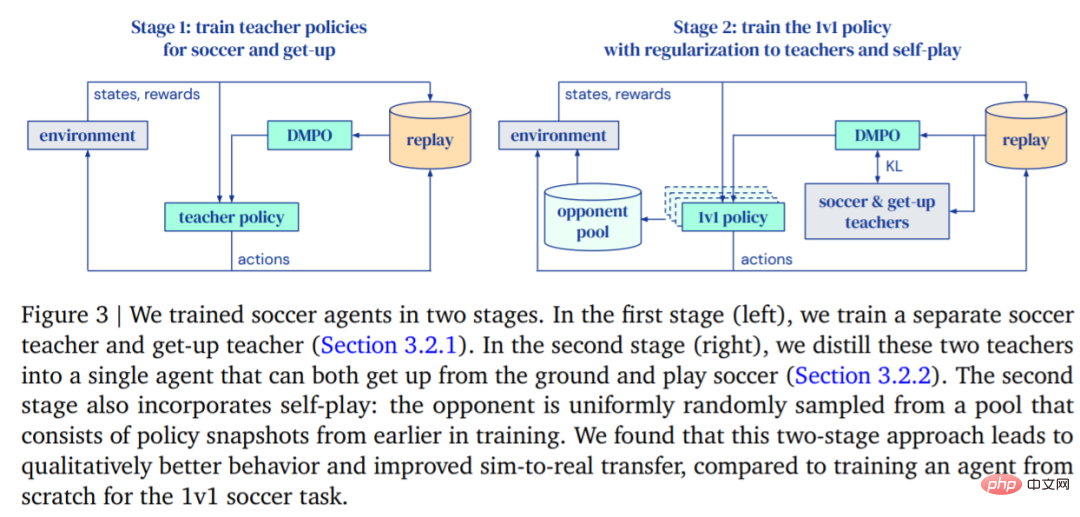
Matlamat DeepMind adalah untuk melatih orang yang boleh berjalan, menendang bola, bangun, pertahankan dan fahami Cara menjaringkan ejen dan kemudian memindahkan fungsi ini kepada robot sebenar. DeepMind membahagikan latihan kepada dua peringkat, seperti yang ditunjukkan dalam Rajah 3.
- Pada peringkat pertama, DeepMind melatih strategi guru untuk dua kemahiran khusus, termasuk membangkitkan ejen dari padang dan menjaringkan gol.
- Dalam fasa kedua, strategi guru dari fasa pertama digunakan untuk mengawal selia ejen manakala ejen belajar untuk melawan lawan yang semakin kuat dengan berkesan.
Latihan
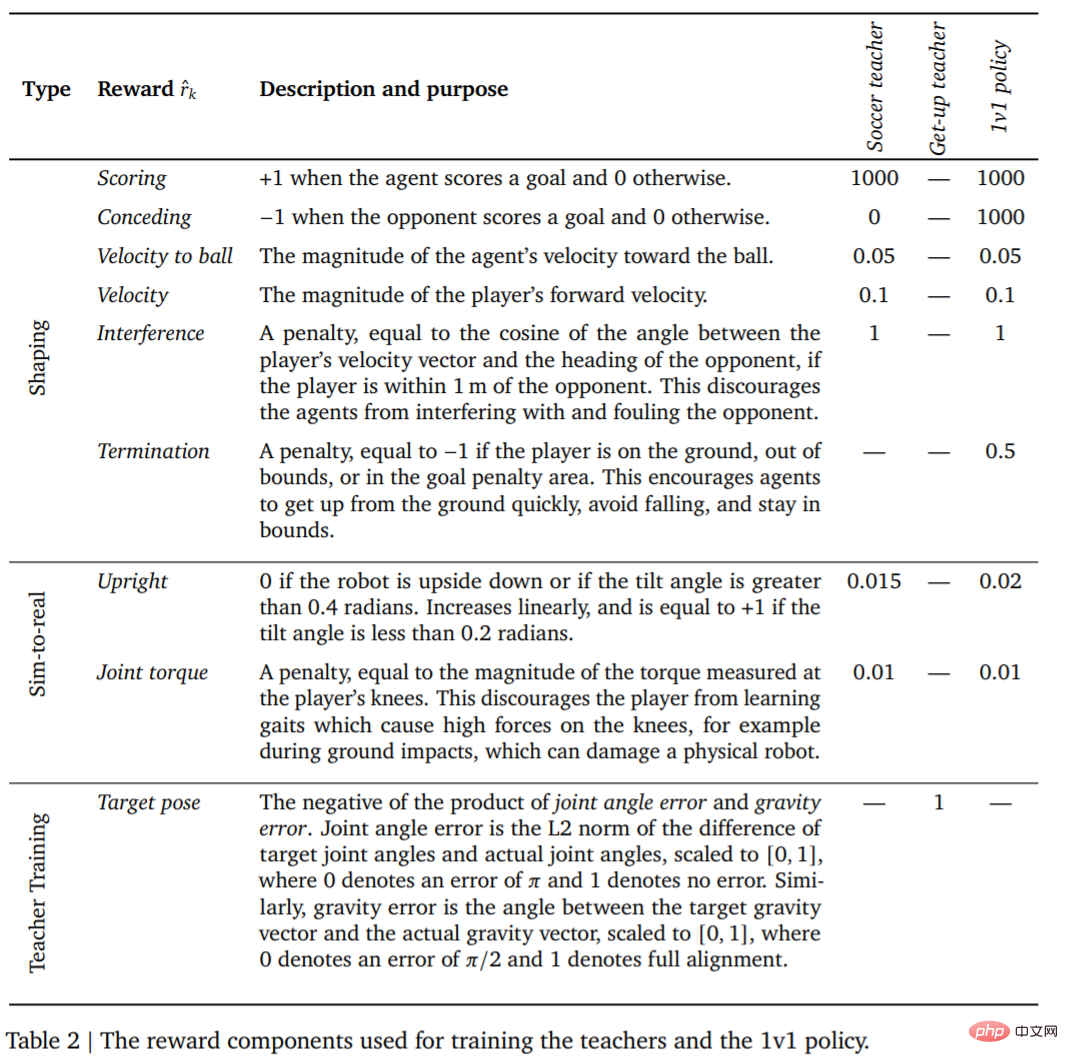
Pertama ialah latihan guru. Guru perlu menerima sebanyak mungkin latihan menjaringkan gol. Pusingan ini (Episod) tamat apabila ejen jatuh, keluar dari sempadan, memasuki kawasan larangan (ditandakan dengan warna merah dalam Rajah 1), atau apabila lawan menjaringkan gol. Pada permulaan setiap pusingan, ejen, pihak lain, dan bola dimulakan ke kedudukan rawak dan arah di gelanggang. Kedua-dua pihak dimulakan kepada pendirian lalai. Lawan dimulakan dengan dasar yang tidak terlatih, jadi ejen belajar untuk mengelakkan lawan pada peringkat ini, tetapi tiada interaksi kompleks lagi berlaku. Di samping itu, ganjaran dan pemberatnya untuk setiap peringkat latihan ditunjukkan dalam Jadual 2.
Ejen kemudian bersaing dengan lawan yang semakin berkuasa sambil mengawal tingkah lakunya mengikut dasar guru. Dengan cara ini, ejen boleh menguasai satu siri kemahiran bola sepak: berjalan, menendang, bangun, menjaringkan gol dan bertahan. Apabila ejen keluar dari sempadan atau berada di dalam kotak gol, ia menerima penalti tetap pada setiap langkah.
Selepas ejen dilatih, langkah seterusnya ialah memindahkan strategi sepakan terlatih kepada robot sebenar dengan sampel sifar. Untuk meningkatkan kadar kejayaan pemindahan sifar pukulan, DeepMind mengurangkan jurang antara ejen simulasi dan robot sebenar melalui pengenalan sistem yang mudah, meningkatkan keteguhan strategi melalui rawak domain dan gangguan semasa latihan, dan termasuk membentuk strategi ganjaran untuk mendapatkan keputusan yang berbeza. Tingkah laku yang terlalu mungkin membahayakan robot.
Eksperimen
Pertandingan 1v1: Ejen bola sepak boleh mengendalikan pelbagai tingkah laku yang timbul, termasuk kemahiran motor yang fleksibel seperti bangun dari tanah, cepat pulih daripada terjatuh, dan berlari dan berpusing. Semasa permainan, ejen beralih antara semua kemahiran ini dengan cara yang lancar.

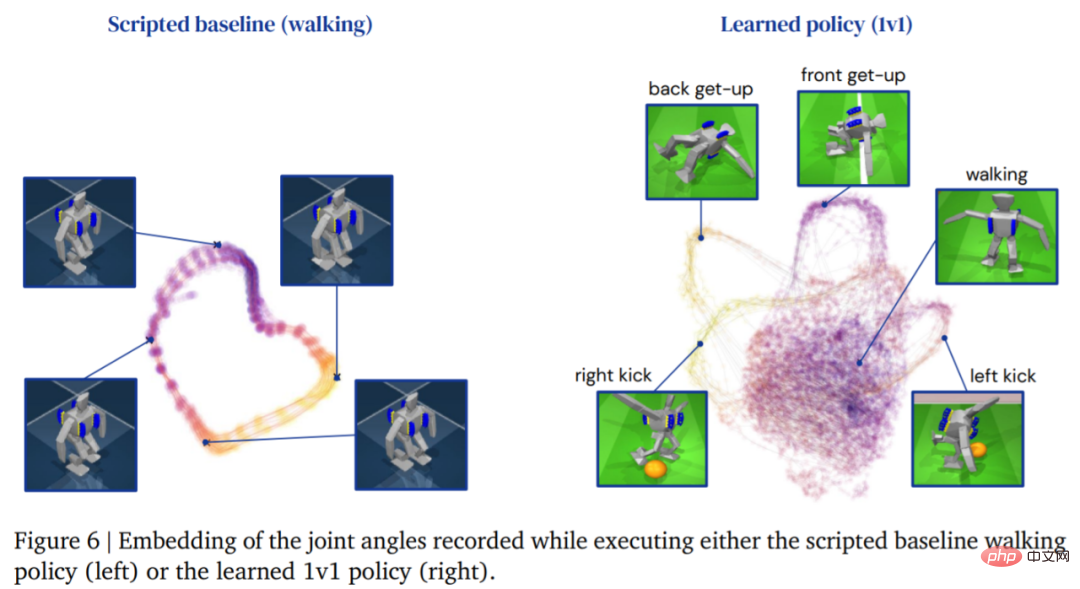
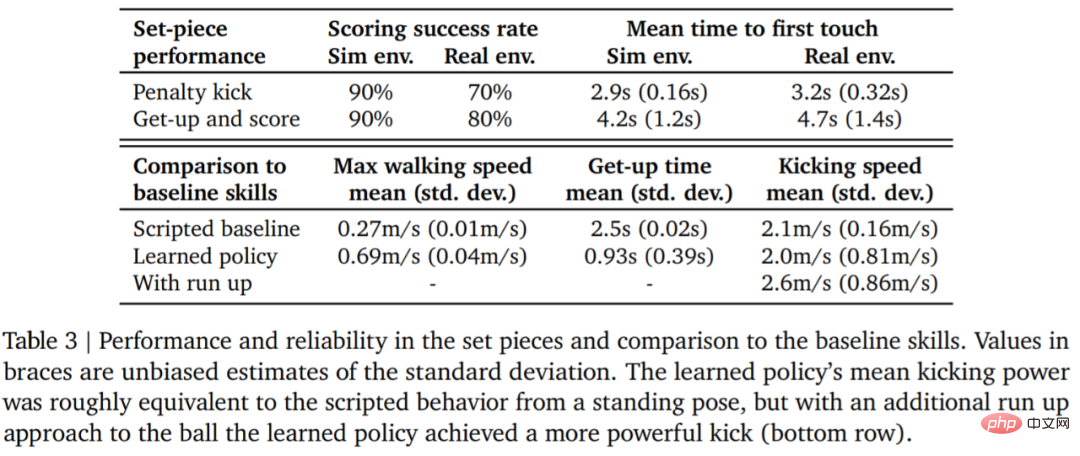
Jadual 3 di bawah menunjukkan keputusan analisis kuantitatif. Dapat dilihat daripada keputusan bahawa strategi pembelajaran pengukuhan menunjukkan prestasi yang lebih baik daripada kemahiran khusus yang direka bentuk buatan, dengan ejen berjalan 156% lebih pantas dan mengambil masa 63% lebih sedikit untuk bangun.
Rajah berikut menunjukkan trajektori berjalan bagi ejen. Sebaliknya, struktur trajektori ejen yang dihasilkan oleh strategi pembelajaran Lebih Kaya:
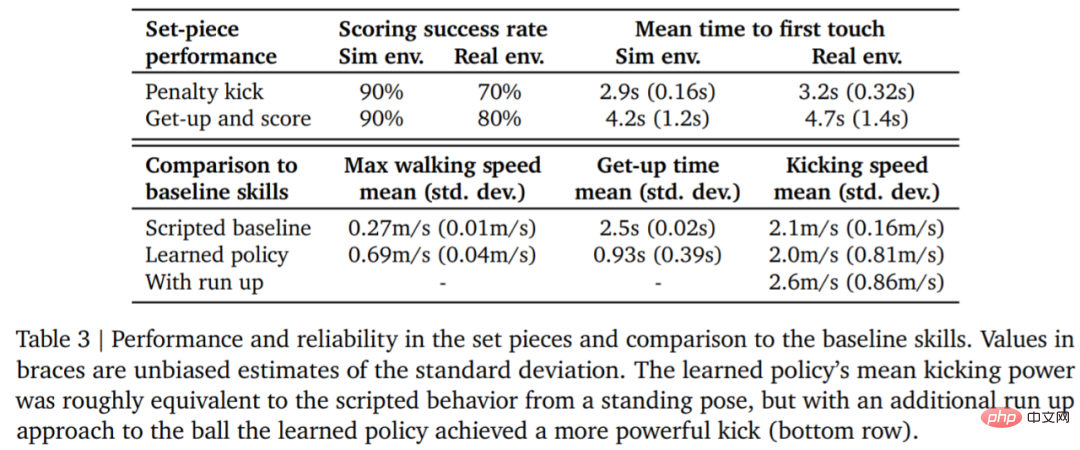
Untuk menilai kebolehpercayaan strategi pembelajaran, DeepMind merancang sepakan penalti dan berlepas kepingan set tembakan, dan Dilaksanakan dalam persekitaran simulasi dan sebenar. Konfigurasi awal ditunjukkan dalam Rajah 7.
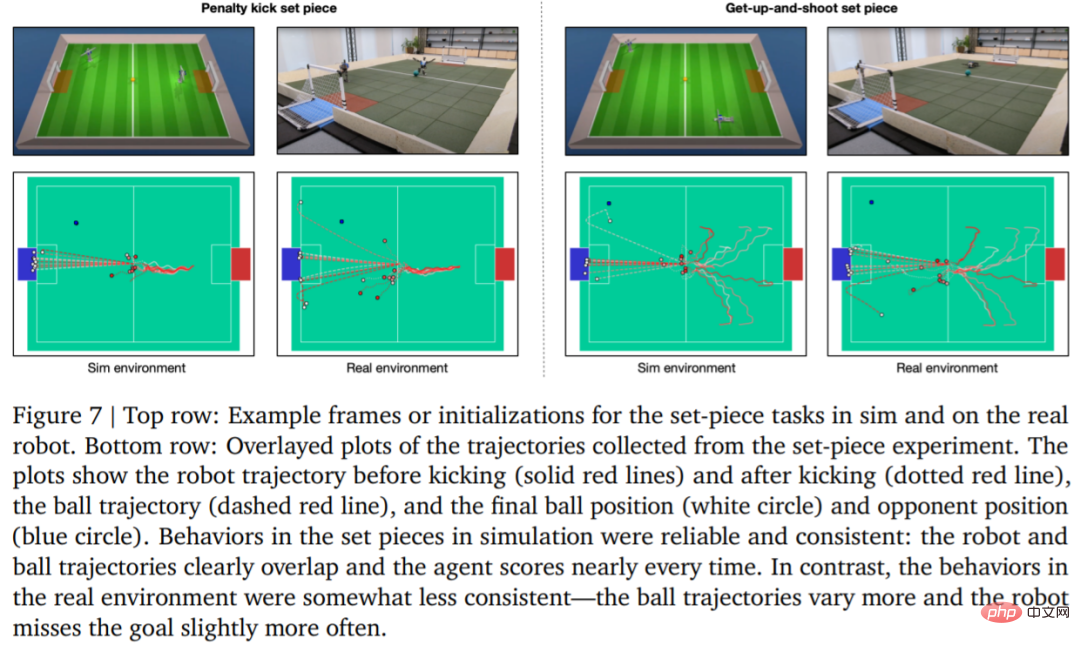
Dalam persekitaran sebenar, robot itu menjaringkan 7 daripada 10 kali (70%) dalam tugasan sepakan penalti. Pukul 8 daripada 10 kali (80%) pada misi pelancaran. Dalam eksperimen simulasi, markah ejen dalam kedua-dua tugas ini adalah lebih konsisten, yang menunjukkan bahawa strategi latihan ejen dipindahkan ke persekitaran sebenar (termasuk robot sebenar, bola, permukaan lantai, dsb.), prestasinya merosot sedikit, dan perbezaan tingkah laku telah meningkat, tetapi robot masih boleh bangun, menendang bola dan menjaringkan gol dengan pasti. Keputusan ditunjukkan dalam Rajah 7 dan Jadual 3.
Atas ialah kandungan terperinci Mengapa DeepMind tidak hadir dalam jamuan GPT? Ternyata saya sedang mengajar robot kecil bermain bola sepak.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI