
Rumah >Peranti teknologi >AI >Aplikasi inferens sebab dalam insentif paparan mikro dan senario penawaran dan permintaan
Aplikasi inferens sebab dalam insentif paparan mikro dan senario penawaran dan permintaan

- PHPzke hadapan
- 2023-05-04 20:40:051578semak imbas

1. Inferens sebab dan algoritma insentif
1. Latar belakang perniagaan dan pemodelan perniagaan
Pertama sekali, mari kita perkenalkan secara ringkas latar belakang perniagaan insentif sampul merah Tencent Weishi. Sama seperti produk dan senario lain, dalam belanjawan tertentu, kami mengeluarkan beberapa insentif tunai kepada pengguna Tencent Weishi, dengan harapan dapat memaksimumkan pengekalan dan masa penggunaan pada hari berikutnya pengguna pada hari yang sama melalui insentif tunai. Bentuk utama insentif tunai adalah untuk mengeluarkan sampul surat merah tunai dengan jumlah yang tidak ditentukan dan jumlah yang tidak ditentukan kepada pengguna pada selang masa yang tidak tetap. Tiga "ketidakpastian" yang disebutkan di atas akhirnya ditentukan oleh algoritma. Tiga "ketidakpastian" ini juga dipanggil tiga elemen strategi insentif sampul merah.
Seterusnya, mari kita bincangkan tentang bentuk abstrak strategi insentif tunai yang berbeza. Yang pertama menyatakan strategi dalam bentuk urutan sampul merah, seperti menomborkan urutan sampul merah, dan kemudian menomborkan setiap rawatan secara bebas dalam bentuk satu-panas. Kelebihannya ialah ia boleh menggambarkan lebih banyak butiran, seperti jumlah antara setiap sampul merah dan strategi terperinci lain, serta kesan yang sepadan. Walau bagaimanapun, ini pasti memerlukan lebih banyak pembolehubah untuk mewakili strategi Ruang penerokaan strategi adalah sangat besar Selain itu, lebih banyak pengiraan akan diperlukan apabila meneroka dan memilih strategi. Bentuk kedua, yang menggunakan vektor tiga elemen untuk mewakili strategi, adalah lebih fleksibel dan lebih cekap dalam penerokaan, tetapi ia mengabaikan beberapa butiran. Cara ketiga adalah lebih matematik, iaitu, jujukan sampul merah secara langsung menjadi fungsi tentang masa t, dan parameter dalam fungsi boleh membentuk vektor untuk mewakili strategi. Pemodelan masalah penyebab dan perwakilan strategi sangat menentukan ketepatan dan kecekapan anggaran kesan sebab akibat.
Dengan mengandaikan bahawa kami mempunyai abstraksi strategi dan perwakilan vektor yang baik, perkara seterusnya yang perlu dilakukan ialah memilih rangka kerja algoritma. Terdapat tiga rangka kerja di sini. Rangka kerja pertama agak matang dalam industri, yang menggunakan inferens sebab-akibat digabungkan dengan pengoptimuman kekangan berbilang objektif untuk memperuntukkan dan mengoptimumkan strategi. Dalam rangka kerja ini, inferens sebab bertanggungjawab terutamanya untuk menganggar penunjuk pengguna teras yang sepadan dengan strategi yang berbeza, yang kami panggil pengekalan pengguna dan penambahbaikan tempoh. Selepas anggaran, kami menggunakan pengoptimuman kekangan berbilang objektif untuk melaksanakan peruntukan strategi belanjawan luar talian untuk memenuhi kekangan belanjawan. Jenis kedua ialah pembelajaran peneguhan luar talian digabungkan dengan kaedah pengoptimuman kekangan berbilang objektif. Saya secara peribadi berpendapat kaedah ini lebih menjanjikan kerana dua sebab utama. Sebab pertama ialah dalam senario aplikasi sebenar, terdapat banyak strategi, dan pembelajaran pengukuhan itu sendiri boleh meneroka ruang strategi dengan cekap Pada masa yang sama, kerana strategi kami bergantung, pembelajaran pengukuhan boleh memodelkan pergantungan antara strategi bahawa intipati kimia kuat luar talian sebenarnya adalah masalah anggaran counterfaktual, yang dengan sendirinya mempunyai sifat sebab akibat yang kuat. Malangnya, kami telah mencuba pembelajaran pengukuhan luar talian dalam senario kami, tetapi kesan dalam taliannya tidak mencapai kesan yang diingini. Sebabnya, di satu pihak, masalah kaedah kami, dan sebaliknya, ia terutamanya terhad oleh data. Untuk melatih model pembelajaran peneguhan luar talian yang baik, pengagihan strategi dalam data perlu cukup luas, atau pengagihan strategi cukup seragam. Dalam erti kata lain, sama ada kami menggunakan data rawak atau data pemerhatian, kami berharap untuk meneroka sebanyak mungkin strategi sedemikian, dan pengedaran akan menjadi sekata, supaya kami dapat mengurangkan bilangan varians yang dianggarkan. Rangka kerja algoritma terakhir agak matang dalam senario pengiklanan Kami menggunakan pembelajaran pengukuhan dalam talian untuk mengawal trafik dan belanjawan. Kelebihan kaedah ini ialah ia boleh bertindak balas terhadap kecemasan dalam talian dengan cara yang tepat pada masanya dan pantas, dan pada masa yang sama, ia boleh mengawal belanjawan dengan lebih tepat. Selepas pengenalan sebab dan akibat, penunjuk yang kami gunakan untuk pemilihan atau kawalan trafik bukan lagi penunjuk ECPM Ia mungkin penambahbaikan dalam pengekalan dan tempoh yang kami anggarkan sekarang. Selepas beberapa siri percubaan praktikal, akhirnya kami memilih rangka kerja algoritma yang pertama, iaitu inferens kausal yang digabungkan dengan pengoptimuman kekangan berbilang objektif, kerana ia lebih stabil dan boleh dikawal, dan ia juga kurang bergantung pada kejuruteraan dalam talian.
Jalur Paip rangka kerja algoritma pertama ditunjukkan dalam rajah di bawah. Mula-mula, ciri pengguna dikira di luar talian, dan kemudian model kausal digunakan untuk menganggarkan penambahbaikan penunjuk teras pengguna di bawah strategi yang berbeza, iaitu apa yang dipanggil peningkatan. Berdasarkan anggaran peningkatan, kami menggunakan pengoptimuman berbilang objektif untuk menyelesaikan dan menetapkan strategi optimum. Untuk mempercepatkan pengiraan keseluruhan proses, kami akan mengelompokkan orang ramai terlebih dahulu semasa menstruktur, yang bermakna kami percaya bahawa orang dalam kelompok ini mempunyai sebab dan akibat yang sama, dan dengan itu, kami menetapkan strategi yang sama kepada orang dalam kelompok yang sama.

2. Hipotesis strategi dan rajah sebab
Berdasarkan perbincangan di atas, mari fokus kepada cara mengabstraksikan strategi. Mula-mula mari kita lihat bagaimana kita mengabstrakkan rajah kausal. Sebab dan akibat yang perlu dimodelkan dalam senario insentif sampul merah ditunjukkan dalam berbilang hari dan berbilang sampul merah. Oleh kerana sampul merah sebelumnya pasti akan mempengaruhi sama ada untuk menerima sampul merah seterusnya, ia pada asasnya adalah masalah Kesan Rawatan Berubah-Masa, disarikan ke dalam rajah kausa siri masa seperti yang ditunjukkan di sebelah kanan.
Mengambil berbilang sampul merah dalam satu hari sebagai contoh, semua subskrip T mewakili nombor siri sampul merah itu. T pada masa ini mewakili vektor yang terdiri daripada jumlah sampul merah semasa dan selang masa sejak sampul merah terakhir dikeluarkan. Y ialah masa penggunaan semasa pengguna selepas sampul merah dikeluarkan dan peningkatan pengekalan pada hari berikutnya. X ialah pembolehubah mengelirukan yang diperhatikan sehingga saat semasa, seperti gelagat tontonan pengguna atau atribut demografi, dsb. Sudah tentu, terdapat banyak pembolehubah mengelirukan yang tidak diperhatikan, diwakili oleh U, seperti pengguna yang tinggal sekali-sekala atau berhenti sekali-sekala. Pembolehubah pengeliru yang tidak diperhatikan adalah minda pengguna, yang terutamanya merangkumi penilaian nilai pengguna terhadap jumlah insentif sampul merah. Minda yang dipanggil ini sukar untuk diwakili melalui beberapa statistik atau ciri statistik dalam sistem.
Adalah sangat rumit untuk memodelkan strategi sampul merah dalam bentuk siri masa, jadi kami telah membuat beberapa pemudahan yang munasabah. Sebagai contoh, anggap bahawa U hanya mempengaruhi T, X dan Y pada saat semasa, dan ia hanya mempengaruhi U pada saat seterusnya, iaitu minda pengguna. Maksudnya, ia hanya akan menjejaskan masa depan Y dengan menjejaskan penilaian nilai atau mentaliti detik seterusnya. Tetapi walaupun selepas beberapa siri pemudahan, kita akan mendapati bahawa keseluruhan rajah sebab akibat siri masa masih sangat padat, menjadikannya sukar untuk membuat anggaran yang munasabah. Dan apabila menggunakan kaedah G untuk menyelesaikan Kesan Trend Berbeza-beza, sejumlah besar data diperlukan untuk latihan Namun, pada hakikatnya, data yang kami perolehi sangat jarang, jadi sukar untuk mencapai kesan yang baik dalam talian. Jadi pada akhirnya kami membuat banyak penyederhanaan dan mendapat struktur garpu (Fork) seperti gambar di sebelah kanan bawah. Kami membuat pengagregatan semua strategi sampul merah untuk hari itu, yang merupakan vektor yang terdiri daripada tiga elemen strategi (jumlah insentif sampul merah, jumlah masa dan jumlah bilangan), yang diwakili oleh T. X ialah pembolehubah yang mengelirukan pada masa T-1, iaitu gelagat sejarah dan atribut demografi pengguna pada hari itu. Y mewakili masa penggunaan pengguna pada hari tersebut, iaitu pengekalan pengguna atau penunjuk masa penggunaan untuk hari berikutnya. Walaupun kaedah ini seolah-olah mengabaikan banyak butiran, seperti interaksi antara sampul merah. Tetapi dari perspektif makro, strategi ini lebih stabil dan kesannya boleh diukur dengan lebih baik.

3. Perwakilan strategi dan model kausal
Berdasarkan perbincangan di atas, langkah seterusnya ialah isu teras iaitu cara menyatakan strategi (rawatan). Sebelum ini kami cuba menggunakan One-Hot untuk menomborkan vektor tiga elemen secara bebas, dan untuk memisahkan tiga elemen dan menggunakan fungsi masa untuk membina rawatan berbilang pembolehubah. Dua strategi pertama lebih mudah difahami, dan kaedah terakhir akan diperkenalkan seterusnya. Tengok gambar di atas. Kami membina fungsi sinus bagi tiga elemen berkenaan dengan t masing-masing, iaitu, diberi masa T, kami boleh memperoleh jumlah, selang masa dan nombor masing-masing. Kami menggunakan parameter yang sepadan dengan fungsi ini sebagai elemen vektor baharu, serupa dengan perwakilan tiga elemen strategi. Tujuan kami menggunakan fungsi untuk menyatakan strategi adalah untuk mengekalkan lebih banyak butiran, kerana dua kaedah pertama hanya boleh mengetahui jumlah purata sampul merah dan selang pengedaran melalui gabungan strategi, dan menggunakan fungsi mungkin mewakilinya dengan lebih terperinci. Walau bagaimanapun, kaedah ini mungkin memperkenalkan lebih banyak pembolehubah dan menjadikan pengiraan lebih rumit.
Selepas mempunyai perwakilan strategi, anda boleh memilih model penyebab untuk menganggarkan kesan penyebab. Dalam bentuk One-Hot yang mewakili tiga elemen T, kami menggunakan model x-Learner untuk memodelkan setiap strategi, dan menggunakan strategi dengan jumlah amaun terkecil sebagai strategi asas untuk mengira dan menilai kesan rawatan semua strategi. Dalam kes ini, anda mungkin merasakan kecekapannya sangat rendah dan model tidak mempunyai generalisasi. Oleh itu, kami seterusnya mengguna pakai strategi ketiga yang baru disebutkan, iaitu menggunakan vektor unsur fungsi sinusoidal untuk membentuk rawatan. Satu model DML seterusnya digunakan untuk menganggar prestasi semua strategi berbanding dengan strategi garis dasar. Di samping itu, kami juga membuat DML pengoptimuman, dengan mengandaikan bahawa y ialah pemberat linear bagi pembolehubah pembancuh dan kesan penyebab, iaitu, y adalah sama dengan kesan rawatan ditambah pembolehubah pengacau. Dengan cara ini, istilah persilangan dan istilah peringkat tinggi antara elemen vektor dibina secara buatan. Ia bersamaan dengan membina fungsi inti polinomial untuk memperkenalkan fungsi tak linear. Atas dasar ini, DML telah bertambah baik berbanding dengan strategi garis dasar. Daripada analisis rajah di bawah, kita boleh mendapati bahawa model DML kos wang yang lebih rendah dan meningkatkan ROI, yang bermaksud bahawa kita boleh menggunakan sumber dengan lebih cekap.
Terdahulu, kami membincangkan beberapa abstraksi kaedah dan pemilihan model semasa proses amalan, kami juga akan menemui beberapa isu berorientasikan perniagaan, seperti Apa yang harus saya lakukan tentang rawatan apabila melakukan One-Hot? Pada masa ini, kami melaksanakan strategi pengembangan kelompok demi kelompok. Mula-mula, buat strategi benih melalui tiga elemen strategi, dan kemudian saring dan simpan benih berkualiti tinggi secara manual, dan kemudian kembangkannya. Selepas pengembangan, kami akan melancarkan strategi baharu dalam kelompok berdasarkan tempoh masa, seperti dua minggu pertama pelancaran dan memastikan saiz trafik rawak setiap strategi adalah konsisten atau setanding. Dalam proses ini, impak faktor masa sememangnya akan diabaikan, dan strategi yang kurang berkesan akan diganti secara berterusan, seterusnya memperkaya koleksi strategi. Di samping itu, faktor masa pasti akan mempengaruhi sama ada strategi trafik rawak adalah setanding. Oleh itu, kami membina kaedah yang serupa dengan putaran hirisan masa untuk memastikan hirisan masa yang diliputi adalah konsisten, dengan itu menghapuskan kesan faktor masa ke atas strategi, supaya trafik rawak yang diperoleh boleh digunakan untuk melatih model.
Dan bagaimana untuk menjana strategi baharu? Kaedah mudah ialah menggunakan carian gred, atau algoritma genetik Ini adalah algoritma umum yang lebih biasa untuk carian. Di samping itu, kita boleh menggabungkan pemangkasan manual, seperti memotong beberapa jenis urutan sampul merah yang tidak diingini. Kaedah lain ialah menggunakan BanditNet, iaitu kaedah pembelajaran pengukuhan luar talian untuk mengira strategi yang tidak kelihatan, iaitu, menganggarkan kesan kontrafaktual, dan kemudian menggunakan nilai anggaran untuk membuat pemilihan strategi. Sudah tentu, kita akhirnya perlu menggunakan trafik rawak dalam talian untuk mengesahkannya. Sebabnya ialah varians kaedah pembelajaran pengukuhan luar talian ini mungkin sangat besar.

4. Isu strategik dan lelaran
Selain masalah yang dinyatakan di atas, kami juga akan menghadapi beberapa masalah berorientasikan perniagaan. Soalan pertama ialah apakah kitaran kemas kini dasar pengguna? Adakah lebih baik jika semua dasar pengguna dikemas kini dengan kerap? Dalam hal ini, pengalaman praktikal kami berbeza dari orang ke orang. Sebagai contoh, strategi untuk pengguna frekuensi tinggi harus berubah dengan lebih perlahan. Di satu pihak, ini kerana pengguna frekuensi tinggi sudah biasa dengan format kami, termasuk jumlah insentif Jika jumlah sampul merah berubah secara drastik, ia pasti akan menjejaskan penunjuk yang sepadan. Oleh itu, kami sebenarnya mengekalkan strategi kemas kini mingguan untuk pengguna frekuensi tinggi, mengemas kini sekali seminggu tetapi untuk pengguna baharu, kitaran kemas kini adalah lebih pendek. Sebabnya ialah kami tahu sangat sedikit tentang pengguna baharu, dan kami mahu dapat meneroka strategi yang sesuai dengan lebih cepat dan bertindak balas dengan cepat untuk membuat perubahan strategi berdasarkan interaksi pengguna. Memandangkan tingkah laku pengguna baharu juga sangat jarang, dalam kes ini, kami akan menggunakan tahap harian untuk mengemas kini pengguna baharu atau beberapa pengguna frekuensi rendah. Selain itu, kami juga perlu memantau kestabilan strategi untuk mengelakkan kesan bunyi ciri Paip yang kami bina ditunjukkan di sebelah kanan. Di sini kami akan memantau sama ada kesan rawatan adalah stabil, dan kami juga akan memantau strategi akhir yang ditetapkan oleh pengguna setiap hari, seperti perbezaan antara strategi hari ini dan strategi semalam, termasuk jumlah dan nombor. Kami juga akan mengambil gambar biasa strategi dalam talian, terutamanya untuk penyahpepijatan dan main balik pantas untuk memastikan kestabilan strategi. Selain itu, kami juga akan menjalankan percubaan pada trafik kecil dan memantau kestabilannya Hanya percubaan trafik kecil yang memenuhi keperluan kestabilan akan digunakan untuk menggantikan strategi sedia ada.
Soalan kedua ialah sama ada dasar untuk pengguna baharu dan sesetengah pengguna istimewa adalah bebas? Jawapannya ya. Contohnya, untuk pengguna baharu, kami akan memberikannya insentif yang kuat dahulu, dan kemudian keamatan insentif akan mereput dari semasa ke semasa. Selepas pengguna memasuki kitaran hayat biasa, kami akan melaksanakan strategi insentif tetap untuknya. Pada masa yang sama, untuk kumpulan sensitif khas, akan ada dasar sekatan ke atas jumlah mereka. Untuk ini, kami juga akan melatih model bebas untuk menyesuaikan diri dengan kumpulan orang ini.
Soalan ketiga yang mungkin anda tanyakan ialah, sejauh manakah pentingnya inferens sebab dalam keseluruhan rangka kerja algoritma? Dari perspektif teori, kami percaya bahawa inferens kausal adalah teras kerana ia membawa faedah yang besar dalam algoritma insentif. Berbanding dengan model regresi dan klasifikasi, inferens sebab adalah konsisten dengan matlamat perniagaan dan sememangnya berorientasikan ROI, jadi ia akan membawa matlamat pengoptimuman mengenai jumlah peningkatan. Walau bagaimanapun, kami ingin mengingatkan semua orang bahawa apabila kami memperuntukkan belanjawan, kami tidak boleh memilih strategi optimum untuk setiap pengguna, dan kesan sebab akibatnya agak kecil berbanding individu. Apabila kami memperuntukkan belanjawan, kemungkinan besar beberapa perbezaan dalam kesan penyebab pengguna akan dihapuskan. Pada masa ini, pengoptimuman terhad kami akan mempengaruhi kesan strategi. Oleh itu, semasa melakukan pengelompokan, kami juga mencuba lebih banyak kaedah pengelompokan, seperti kaedah SCCL pengelompokan mendalam untuk mendapatkan hasil pengelompokan yang lebih baik. Kami juga telah menjalankan beberapa lelaran model penyebab dalam, seperti BNN atau Dragonnet, dsb.
Kami mendapati bahawa semasa latihan, penunjuk luar talian model sebab dalam memang telah bertambah baik dengan ketara, tetapi kesan dalam taliannya tidak cukup stabil terdapat nilai yang hilang. Pada masa yang sama, kami juga mendapati bahawa kaedah perancangan ciri sangat mempengaruhi kestabilan model dalam talian pembelajaran mendalam, jadi pada akhirnya kami akan cenderung menggunakan kaedah DML secara stabil.
Itu sahaja untuk perkongsian dalam senario insentif Seterusnya, saya ingin meminta dua pelajar lain daripada pasukan kami untuk berkongsi dengan anda beberapa amalan dalam pembekalan dan senario pengoptimuman permintaan dan penerokaan teori.

2. Inferens sebab dan pelarasan penawaran dan permintaan
1 Latar belakang perniagaan dan pemodelan perniagaan
Seterusnya. Izinkan saya memperkenalkan latar belakang perniagaan Tencent Weishi dari segi penawaran dan permintaan. Sebagai platform video pendek, Weishi mempunyai banyak kategori video yang berbeza. Untuk kumpulan pengguna yang kadangkala mempunyai minat tontonan yang berbeza, kami perlu memperuntukkan perkadaran pendedahan atau perkadaran inventori dengan sewajarnya bagi setiap kategori mengikut ciri pengguna yang berbeza Matlamatnya adalah untuk meningkatkan pengalaman pengguna dan masa tontonan pengguna, antaranya pengalaman pengguna boleh diukur berdasarkan penunjuk kadar leret pantas 3 saat, dan masa tontonan diukur terutamanya berdasarkan jumlah masa main balik. Bagaimana untuk melaraskan nisbah pendedahan atau nisbah inventori bagi kategori video? Kaedah utama yang kami anggap ialah menambah atau mengurangkan beberapa kategori mengikut perkadaran. Nisbah kenaikan atau penurunan ialah nilai pratetap.
Seterusnya kita perlu menggunakan algoritma untuk menyelesaikan cara memutuskan kategori mana yang hendak dinaikkan dan kategori mana yang perlu dikurangkan, supaya dapat memaksimumkan pengalaman pengguna dan masa tontonan, dan pada masa yang sama, kita perlu memenuhi Contohnya, terdapat beberapa kekangan yang mengehadkan jumlah pendedahan. Tempat ini meringkaskan tiga idea pemodelan utama. Pertama ialah idea yang lebih mudah, iaitu, kami secara langsung menganggap kenaikan dan penurunan sebagai pembolehubah rawatan 0 dan 1, kami menganggarkan kesan penyebabnya, dan kemudian menjalankan pengoptimuman kekangan berbilang objektif untuk Mendapatkan strategi terakhir. Idea kedua ialah memodelkan rawatan dengan lebih tepat. Kami menganggap rawatan sebagai pembolehubah berterusan Contohnya, nisbah pendedahan kategori ialah pembolehubah yang berubah secara berterusan antara 0 dan 1. Kemudian muatkan keluk kesan sebab akibat yang sepadan atau fungsi kesan sebab, dan kemudian lakukan pengoptimuman kekangan berbilang objektif, dan akhirnya dapatkan strategi akhir. Dapat diambil perhatian bahawa kedua-dua kaedah yang disebutkan tadi adalah kaedah dua peringkat. Idea ketiga, kami membawa kekangan ke dalam anggaran kesan sebab untuk mendapatkan strategi optimum yang memenuhi kekangan. Ini juga kandungan kajian yang saya harap dapat dikongsikan bersama anda nanti.
Pertama sekali, mari fokus pada dua idea pemodelan yang pertama. Terdapat beberapa perkara pemodelan yang perlu diberi perhatian. Perkara pertama ialah untuk memastikan ketepatan anggaran kesan sebab, kita perlu membahagikan populasi dan menganggar kesan sebab akibat rawatan binari atau rawatan berterusan ke atas setiap populasi. Sebentar tadi, Cikgu Zheng turut menyebut kaedah mengklasifikasikan orang, seperti menggunakan kmeans clustering atau beberapa deep clustering. Perkara kedua ialah cara menilai kesan model pada data eksperimen bukan rawak. Sebagai contoh, kita perlu menilai kesan model di luar talian tanpa melakukan ujian AB. Mengenai isu ini, anda boleh merujuk kepada beberapa penunjuk yang disebut dalam kertas yang diindeks di atas pada PPT untuk penilaian luar talian. Perkara ketiga yang perlu diperhatikan ialah kita harus mempertimbangkan korelasi dan pengaruh bersama antara kategori sebanyak mungkin, seperti beberapa masalah kesesakan antara kategori yang serupa, dsb. Jika faktor-faktor ini boleh dimasukkan dalam anggaran kesan penyebab, keputusan yang lebih baik harus dicapai.

2 Strategi pelarasan perkadaran pendedahan kategori kumpulan tunggal
<.>Seterusnya kami akan mengembangkan idea pemodelan ini secara terperinci. Pertama sekali, kaedah pemodelan pertama adalah untuk mentakrifkan rawatan 0 dan 1, yang digunakan untuk mewakili cara menambah atau mengurangkan kedua-dua jenis campur tangan ini Anda boleh merujuk kepada rajah sebab dan akibat ringkas di sebelah kiri . Di sini x mewakili beberapa ciri pengguna, seperti gelagat operasi sejarah, serta atribut pengguna lain, dsb. y ialah sasaran yang kami ambil berat, iaitu kadar pecutan 3 saat atau jumlah masa main balik. Di samping itu, adalah perlu juga untuk memberi perhatian kepada beberapa pembolehubah mengelirukan yang tidak diperhatikan, seperti pengguna yang tidak sengaja, meleret dan keluar dengan pantas, dan pengguna yang sama sebenarnya boleh digunakan oleh berbilang orang, yang juga merupakan masalah berbilang identiti pengguna. Di samping itu, lelaran berterusan dan kemas kini strategi pengesyoran juga akan memberi kesan kepada data pemerhatian, dan penghijrahan minat pengguna juga berada di luar pemerhatian. Pembolehubah mengelirukan yang tidak diperhatikan ini boleh menjejaskan anggaran kesan sebab akibat pada tahap tertentu.
Untuk kaedah pemodelan sebegitu, kaedah anggaran kesan sebab akibat biasa boleh diselesaikan. Sebagai contoh, anda boleh mempertimbangkan T-Learner atau X-Learner, atau DML, yang boleh menganggarkan kesan penyebab. Sudah tentu, kaedah pemodelan mudah ini juga mempunyai beberapa masalah Sebagai contoh, jika kita menggunakan rawatan binari untuk model, ia akan menjadi terlalu mudah. Di samping itu, di bawah kaedah ini, setiap kategori dianggap secara berasingan, dan korelasi antara kategori tidak dipertimbangkan. Masalah terakhir ialah kami tidak mengambil kira faktor khusus seperti susunan pendedahan dan kualiti kandungan dalam keseluruhan soalan.
Seterusnya, mari perkenalkan idea pemodelan kedua. Kami mempertimbangkan semua kategori sebagai contoh, kami mempunyai kategori video k, dan biarkan rawatan menjadi vektor penyebab dimensi k. Setiap kedudukan vektor mewakili kategori, seperti rancangan pelbagai filem dan televisyen atau acara MOBA, dsb. 0 dan 1 masih mewakili peningkatan atau penurunan. Pada masa ini, anggaran kesan sebab rawatan dalam vektor berbilang dimensi boleh diselesaikan dengan algoritma DML. Kami biasanya menganggap vektor rawatan, yang semuanya 0, sebagai kawalan. Walaupun kaedah ini menyelesaikan masalah bahawa setiap kategori tidak dianggap secara berasingan, ia masih mempunyai beberapa masalah yang berpotensi. Yang pertama ialah masalah letupan dimensi yang disebabkan oleh terlalu banyak kategori Apabila dimensi meningkat, kerana terdapat dua situasi 0 dan 1 pada setiap kedudukan, bilangan pilih atur dan kombinasi yang berpotensi akan meningkat secara eksponen, yang akan menjejaskan sebab dan akibat. . Ketepatan anggaran kesan mewujudkan gangguan. Di samping itu, faktor seperti susunan pendedahan dan kandungan yang dinyatakan sebelum ini tidak diambil kira.

Selepas berkongsi idea pemodelan rawatan pembolehubah binari, seterusnya kita boleh menggunakan rawatan Menjalankan pemodelan yang lebih terperinci yang lebih sesuai dengan ciri-ciri tersendiri. Kami mendapati bahawa nisbah pendedahan itu sendiri adalah pembolehubah berterusan, jadi adalah lebih munasabah untuk kami menggunakan rawatan berterusan untuk pemodelan. Di bawah idea pemodelan ini, kita perlu membahagikan orang ramai terlebih dahulu. Untuk setiap kumpulan orang, kami memodelkan setiap kategori secara berasingan untuk mendapatkan lengkung kesan sebab bagi satu kumpulan*kategori tunggal. Seperti yang ditunjukkan dalam gambar di sebelah kiri, lengkung kesan sebab-akibat mewakili kesan perkadaran kategori yang berbeza pada matlamat yang kita pentingkan. Untuk menganggarkan lengkung kesan sebab, saya berkongsi dua algoritma yang boleh dilaksanakan, satu ialah DR-Net dan satu lagi ialah VC-Net Kedua-dua algoritma tergolong dalam kategori pembelajaran mendalam. Struktur model adalah seperti yang ditunjukkan dalam gambar di sebelah kanan.
Perkenalkan DR-Net dahulu. Input x model akan mula-mula melalui beberapa lapisan yang disambungkan sepenuhnya untuk mendapatkan perwakilan tersirat yang dipanggil z. DR-Net menggunakan strategi pendiskretan, yang menyebarkan rawatan berterusan kepada berbilang blok, dan kemudian setiap blok melatih sub-rangkaian untuk meramalkan pembolehubah sasaran. Memandangkan DR-Net menggunakan strategi pendiskretan, lengkung kesan sebab akibat akhir yang diperolehinya tidak berterusan sepenuhnya, tetapi apabila pendiskritan menjadi lebih nipis, anggaran akhir akan lebih hampir kepada lengkung berterusan. Sudah tentu, apabila segmentasi ideal menjadi lebih nipis, ia akan membawa lebih banyak parameter dan risiko yang lebih tinggi untuk overfitting.
Seterusnya saya akan berkongsi tentang VC-Net. VC-Net menambah baik kekurangan DR-Net pada tahap tertentu. Pertama sekali, input model VC-Net masih X, yang juga merupakan ciri pengguna. Ia juga mula-mula memperoleh perwakilan tersirat Z selepas beberapa lapisan bersambung sepenuhnya. Tetapi pada Z, modul untuk meramal Skor Kecenderungan akan disambungkan terlebih dahulu. Di bawah keadaan Rawatan berterusan, Kecenderungan ialah ketumpatan kebarangkalian Rawatan t di bawah keadaan X tertentu, yang juga π diwakili pada rajah. Seterusnya, mari kita lihat struktur rangkaian selepas Z. Berbeza daripada operasi pendiskretan DR-Net, VC-Net menggunakan struktur rangkaian pekali boleh ubah, iaitu setiap parameter model selepas Z ialah parameter tentang fungsi t. Pengarang literatur yang kami nyatakan di sini menggunakan kaedah fungsi asas untuk menyatakan setiap fungsi sebagai gabungan linear fungsi asas, yang juga ditulis sebagai θ(t). Dengan cara ini, anggaran fungsi menjadi anggaran parameter gabungan linear fungsi asas. Jadi dengan cara ini, pengoptimuman parameter model tidak menjadi masalah, dan lengkung kesan sebab yang diperolehi oleh VC-Net juga merupakan lengkung berterusan. Mengenai fungsi objektif yang akan diselesaikan oleh VC-Net terdiri daripada beberapa bahagian. Di satu pihak, ia terdiri daripada kehilangan kuasa dua ramalan akhir pada sasaran, iaitu μ dalam rajah. Sebaliknya, ia juga terdiri daripada kehilangan logaritma ketumpatan kebarangkalian kecenderungan. Sebagai tambahan kepada dua bahagian ini, pengarang juga menambah istilah penalti yang dipanggil regularisasi disasarkan pada fungsi objektif, supaya sifat anggaran teguh berganda boleh diperolehi. Untuk butiran khusus, rakan-rakan yang berminat boleh merujuk kepada dua kertas asal yang diindeks di atas untuk butiran lanjut.

Akhirnya, mari kita buka jalan untuk satu kajian yang akan kami kongsikan anda tidak lama lagi. Kami mendapati bahawa bahagian pendedahan bagi setiap kategori video ialah vektor berterusan berbilang dimensi. Sebab mengapa ia berbilang dimensi ialah kami mempunyai berbilang kategori video dan setiap dimensi mewakili kategori video. Sebab utama mengapa ia berterusan ialah bahagian pendedahan setiap kategori video adalah berterusan, dan nilainya adalah antara 0 dan 1. Pada masa yang sama, terdapat kekangan semula jadi, iaitu jumlah nisbah pendedahan semua kategori video kami mestilah sama dengan 1. Jadi kita boleh mempertimbangkan vektor berterusan berbilang dimensi sebagai rawatan.
Vektor yang ditunjukkan di sebelah kanan ialah contoh perkara ini. Matlamat kami adalah untuk mencari nisbah pendedahan optimum untuk memaksimumkan jumlah masa bermain kami. Dalam rangka kerja kausal tradisional, adalah sukar bagi algoritma untuk menyelesaikan masalah berbilang dimensi yang berterusan dan tidak terkekang. Seterusnya, kami berkongsi penyelidikan kami mengenai isu sedemikian.

3 Perkongsian Model Penyebab Pelbagai Pembolehubah Berterusan Terkekang
MDPP Forest Kerja ini merupakan kaedah penerokaan dan penyelesaian inovatif kepada masalah yang dilakukan oleh pasukan ketika mengkaji isu penawaran dan permintaan. Pasukan kami mendapati pada masa itu bahawa apabila berhadapan dengan masalah bagaimana memperuntukkan nisbah pendedahan kategori video terbaik untuk setiap pengguna, kaedah biasa lain yang sedia ada tidak dapat mencapai hasil yang lebih sesuai dengan jangkaan. Oleh itu, selepas tempoh percubaan dan penambahbaikan, kaedah yang direka oleh pasukan kami boleh mencapai hasil yang baik di luar talian, dan kemudian bekerjasama dengan pengesyoran, dan akhirnya mencapai faedah strategik tertentu. Kami kemudiannya menyusun karya ini ke dalam kertas kerja, yang cukup bertuah kerana diterbitkan pada KDD 2022.

1. Latar Belakang dan Cabaran
Pertama, perkenalkan latar belakang masalah. Dari segi isu penawaran dan permintaan, kami membahagikan video pendek kepada kategori berbeza berdasarkan kandungan, seperti sains popular, filem dan televisyen, makanan luar, dsb. Nisbah pendedahan kategori video merujuk kepada perkadaran video dalam kategori berbeza ini kepada semua video yang ditonton oleh pengguna. Pengguna mempunyai pilihan yang sangat berbeza untuk kategori yang berbeza, dan platform selalunya perlu menentukan nisbah pendedahan optimum untuk setiap kategori berdasarkan kes demi kes. Dalam peringkat penyusunan semula, pengesyoran pelbagai jenis video dikawal. Cabaran besar bagi syarikat ialah cara memperuntukkan nisbah terbaik pendedahan video untuk memaksimumkan masa setiap pengguna di platform.

Kesukaran utama masalah sedemikian terletak pada tiga perkara berikut. Yang pertama ialah dalam sistem pengesyoran video pendek, video yang dilihat oleh setiap pengguna mempunyai perkaitan yang sangat kuat dengan ciri-cirinya sendiri. Ini adalah bias terpilih. Oleh itu, kita perlu menggunakan algoritma yang berkaitan dengan inferens sebab untuk menghapuskan berat sebelah. Yang kedua ialah nisbah pendedahan kategori video ialah rawatan berterusan, berbilang dimensi dan terkekang. Pada masa ini tiada kaedah yang sangat matang untuk masalah yang kompleks seperti ini dalam bidang inferens sebab dan pengoptimuman dasar. Yang ketiga ialah dalam data luar talian, kita tidak boleh mengetahui secara priori nisbah pendedahan optimum sebenar setiap orang, jadi sukar untuk menilai kaedah ini. Dalam persekitaran sebenar, ia hanyalah subpautan dalam pengesyoran. Keputusan percubaan akhir tidak dapat menilai ketepatan kaedah ini untuk matlamat pengiraannya sendiri. Oleh itu, sukar untuk kita menilai dengan tepat masalah senario ini. Kami akan memperkenalkan cara kami menjalankan penilaian kesan kemudian.

2 Definisi Masalah
Kami. Pertama, abstrak data ke dalam gambar rajah sebab dalam statistik. Antaranya, vektor. Y ialah masa tontonan pengguna, yang merupakan tindak balas kepada matlamat tugasan. Matlamat pemodelan kami adalah untuk memberikan nisbah pendedahan kategori video optimum berdimensi tinggi di bawah ciri pengguna khusus X, supaya dapat memaksimumkan jangkaan masa tontonan pengguna. Masalah ini nampaknya hanya diwakili oleh rajah ternari sebab, tetapi terdapat masalah besar, yang dinyatakan sebelum ini ialah nisbah pendedahan berbilang kategori, yang diambil kira mengikut pendedahan kategori dengan nilai berterusan dan jumlah vektor ialah 1. Masalah ini lebih rumit.

3 Pengenalan kaedah——Titik Keutamaan Maksimum (MDP2) Hutan
Sehubungan itu, kaedah kami juga berdasarkan hutan keputusan sebab musabab (causal forest). Pokok keputusan penyebab umum hanya boleh menyelesaikan masalah rawatan dengan nilai diskret satu dimensi. Dengan menambah baik pengiraan fungsi kriteria pemisahan perantaraan, kami menambah beberapa maklumat berterusan dimensi tinggi semasa pemisahan, supaya ia dapat menyelesaikan masalah nilai berterusan dimensi tinggi dan rawatan yang terhad.

① Pengenalan kepada kaedah - masalah berterusan
Pertama, kami selesaikan masalah rawatan berterusan. Seperti yang ditunjukkan dalam rajah, kesan T pada Y ialah lengkung selanjar. Mari kita anggap bahawa ini adalah lengkung yang meningkat secara monoton. Untuk semua nilai Rawatan dalam data, kami merentasinya dan mengira min Y bagi sampel kiri dan kanan untuk mencari titik dengan perbezaan terbesar antara min Y di sebelah kiri dan min Y di sebelah kanan, iaitu, titik dengan purata faedah penyebab terbesar. Kami memanggil titik ini sebagai Titik Perbezaan Maksimum, yang merupakan titik paling cekap pada ruang Rawatan berterusan, yang bermaksud Rawatan boleh mengubah Y dengan ketara. Titik Perbezaan Maksimum ialah titik yang kita mahu dapatkan dalam satu dimensi.
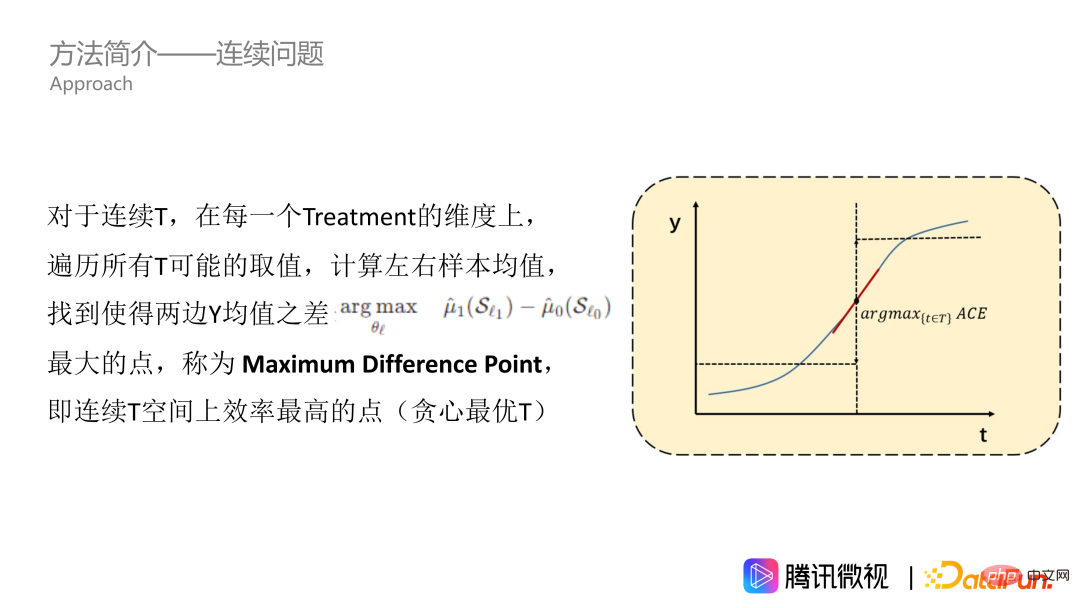
Walau bagaimanapun, kaedah yang kami sebutkan tadi hanya sesuai untuk lengkung yang meningkat secara monoton. Tetapi sebenarnya, kebanyakan masalah tidak begitu baik, terutamanya isu nisbah pendedahan. Mengenai isu ini, lengkung kesan secara amnya berbentuk gunung, iaitu, ia meningkat dahulu dan kemudian menurun. Mengesyorkan lebih banyak video yang disukai pengguna boleh meningkatkan masa tontonan pengguna Walau bagaimanapun, jika jenis ini disyorkan terlalu banyak, keseluruhan pengesyoran video akan menjadi sangat membosankan dan ia juga akan menyesakkan ruang pendedahan jenis video yang disukai pengguna lain. Jadi lengkung biasanya berbentuk gunung, tetapi ia mungkin juga dalam bentuk lain. Untuk menyesuaikan diri dengan lengkung-T dalam sebarang bentuk, kita perlu melakukan operasi kamiran, iaitu, untuk mencari selang julat nilai untuk pengumpulan. Pada lengkung terkumpul, kami juga mengira nilai min di sebelah kiri dan kanan, serta titik di mana perbezaan antara nilai min pada kedua-dua belah adalah yang terbesar, seperti bintang berbucu lima dalam gambar itu. Titik ini boleh dipanggil titik perbezaan maksimum keutamaan, iaitu MDPP kami.

② Pengenalan kepada kaedah - masalah dimensi tinggi
Kami memperkenalkan cara menyelesaikan masalah berterusan di atas, tetapi lengkung yang disebutkan tadi hanyalah satu dimensi dan sepadan dengan satu kategori video. Seterusnya, kami menggunakan idea traversal dimensi heuristik untuk menyelesaikan masalah pelbagai dimensi. Apabila mengira skor pengelasan, kami menggunakan idea heuristik untuk mengisih dimensi K secara rawak dan mengira pengagregatan penunjuk D dalam setiap dimensi, iaitu, melakukan operasi penjumlahan. Dapatkan D* sebagai entropi maklumat berdimensi tinggi, dan kemudian pertimbangkan kekangannya ialah jumlah semua MDPP ialah 1. Di sini kita perlu mempertimbangkan dua situasi berikut Satu ialah jika jumlah MDPP tidak mencapai 1 selepas dimensi K dilalui. Sebagai tindak balas kepada situasi ini, kami akan menambah jumlah semua MDPP dan menormalkannya kepada 1. Kes kedua ialah jika kita hanya merentasi dimensi K', yang lebih kecil daripada dimensi K, jumlah MDPP telah mencapai 1. Untuk ini, kami akan menghentikan traversal dan menetapkan MDPP kepada baki "jumlah sumber", iaitu 1 tolak jumlah nilai MDPP yang dikira sebelum ini, supaya kekangan boleh diambil kira.

Selain itu, kami juga akan memperkenalkan hutan pada struktur pokok di atas, kerana ia terutamanya Terdapat dua makna utama. Yang pertama ialah idea ensembel beg tradisional kami, yang boleh menggunakan berbilang pelajar untuk meningkatkan keteguhan model. Yang kedua ialah dalam traversal dimensi, hanya dimensi K’ akan dikira setiap kali nod dipecah, dan beberapa dimensi tidak disertakan. Agar setiap dimensi mempunyai peluang yang sama untuk mengambil bahagian dalam perpecahan, kita perlu membina berbilang pokok.

③ Pengenalan kepada kaedah - pecutan algoritma
Terdapat masalah lain Memandangkan algoritma mengandungi tiga peringkat traversal, semua model pokok memerlukan traversal nilai eigen, serta traversal dimensi tambahan dan traversal carian MDPP. Traversal tiga lapisan sedemikian menjadikan kecekapan sangat rendah. Oleh itu, kami menggunakan kaedah graf kuantil berwajaran untuk traversal nilai eigen dan traversal MDPP, dan hanya mengira hasil yang sepadan pada titik kuantil, yang boleh mengurangkan kerumitan algoritma dengan banyak. Pada masa yang sama, kami juga mendapati titik kuantil ini sebagai titik sempadan "julat nilai terkumpul", yang boleh mengurangkan jumlah pengiraan dan penyimpanan. Dengan mengandaikan terdapat q kuantil, kita hanya perlu mengira q kali untuk mendapatkan bilangan sampel dan nilai min y dalam setiap selang kuantil Dengan cara ini, setiap kali kita mengira perbezaan d antara min pada kedua-dua belah, kita sahaja perlu membahagikan nilai q ke kiri Untuk dua bahagian di sebelah kanan, hanya lakukan jumlah wajaran nilai purata dalam setiap selang. Kita tidak perlu lagi mengira semula min semua sampel di sebelah kiri dan kanan titik kuantil. Mari kita masuk ke bahagian percubaan.

4. Reka bentuk eksperimen
① Reka bentuk eksperimen-Metrik
Penilaian eksperimen kami pada asasnya ialah Penilaian strategi masalah, jadi kami memperkenalkan penunjuk yang berkaitan dengan penilaian strategi. Yang pertama ialah Penyesalan Utama, yang mengukur jurang antara pulangan strategi keseluruhan dan pulangan optimum teori. Satu lagi ialah Ralat Petak Rawatan Utama, yang digunakan untuk mengukur jurang antara nilai anggaran dan nilai optimum bagi setiap dimensi Rawatan di bawah Rawatan berbilang dimensi. Untuk kedua-dua penunjuk, lebih kecil lebih baik. Walau bagaimanapun, masalah terbesar yang disebabkan oleh menetapkan kedua-dua penunjuk penilaian ini ialah bagaimana untuk menentukan nilai optimum.

② Reka bentuk eksperimen - kaedah perbandingan
Perkenalkan kaedah perbandingan kami. Pertama, terdapat dua kaedah yang biasa digunakan dalam inferens sebab, satu ialah DML dengan teori statistik lengkap, dan satu lagi ialah model rangkaian DR-Net dan VC-Net. Kaedah ini hanya boleh menangani masalah satu dimensi, tetapi untuk masalah dalam artikel ini, kami telah membuat beberapa pelarasan untuk menangani masalah berbilang dimensi, iaitu, mula-mula mengira nilai mutlak setiap dimensi dan kemudian melakukan normalisasi. Terdapat juga kaedah pengoptimuman dasar dalam dua kertas berikut, yang kami panggil OPE dan OCMD. Kedua-dua artikel ini menyatakan bahawa kaedah mereka sesuai untuk masalah pelbagai dimensi, tetapi mereka juga menunjukkan bahawa apabila terdapat terlalu banyak dimensi, adalah sukar untuk kaedah ini berkesan.

③ Set data simulasi reka bentuk eksperimen
Untuk membandingkan kesan model secara ringkas dan langsung, kami mensimulasikan masalah dunia sebenar dan menjana versi ringkas set data simulasi. Ruang ciri x mewakili 6 dimensi ciri pengguna dan 2 ciri tingkah laku. Untuk sampel dengan ciri yang berbeza, kami mula-mula menganggap strategi optimumnya. Seperti yang ditunjukkan dalam rajah, sebagai contoh, pengguna yang berumur kurang daripada 45 tahun, mempunyai tahap pendidikan lebih daripada 2, dan mempunyai ciri tingkah laku lebih daripada 0.5 adalah yang terbaik dalam 6 kategori video. Dengan bantuan formula di sebelah kiri, mula-mula menjana strategi pendedahan untuk pengguna secara rawak, dan kemudian mengira jurang antara strategi pendedahan dan strategi optimum sebenar, serta tempoh pengguna simulasi. Jika strategi lebih dekat dengan strategi optimum pengguna, tempoh y pengguna akan lebih lama. Dengan cara ini kami menjana set data sedemikian. Kelebihan set data simulasi ini ialah kami secara langsung menganggap nilai optimum, yang sangat mudah untuk penilaian yang lain ialah datanya agak mudah, yang memudahkan kami menganalisis keputusan algoritma.

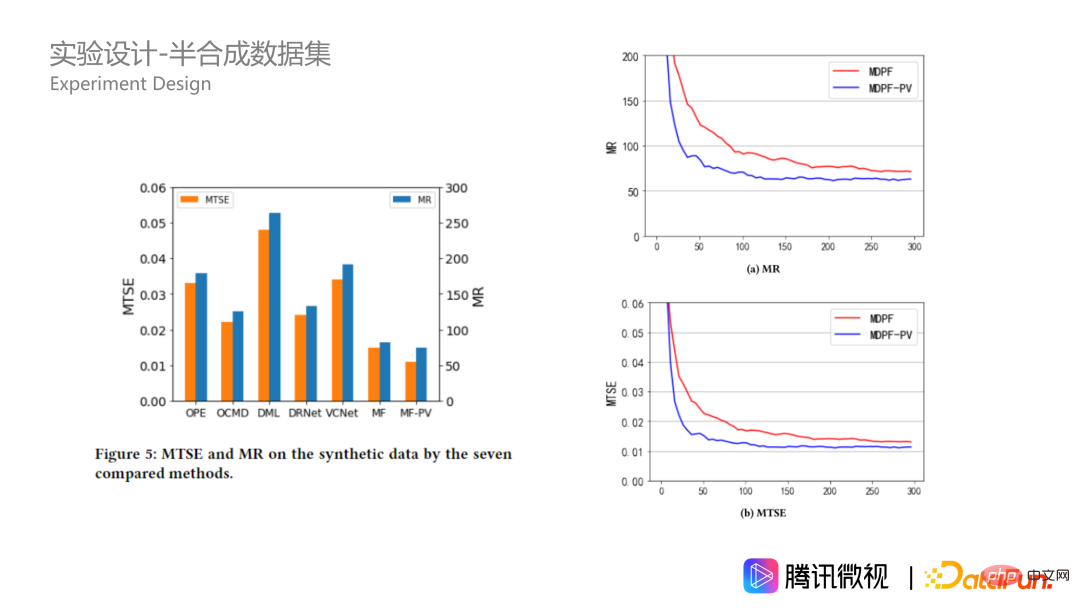
Mari kita lihat hasil percubaan pada set data simulasi baru disebut Bagi jenis populasi tersebut, pelbagai kaedah disediakan untuk mengira nilai min rawatan yang sepadan. Baris pertama adalah teori optimum, baris kedua ialah hutan MDPP kami, dan baris ketiga berdasarkan hutan MDPP dan menambah beberapa istilah penalti pada kriteria pemisahan. Ia dapat dilihat bahawa jurang antara kaedah kami dan teori optimum akan menjadi sangat kecil. Beberapa kaedah lain tidak terlalu melampau, tetapi agak sekata. Di samping itu, dari angka MR dan MTSE di sebelah kanan, kedua-dua kaedah kami juga mempunyai kelebihan yang sangat jelas.

④ Reka bentuk eksperimen - set data separa sintetik
Selain set data simulasi, kami juga membina data separa sintetik berdasarkan perniagaan sebenar data. Data datang daripada platform Tencent Weishi. Xi mewakili ciri 20 dimensi pengguna, rawatan ti mewakili nisbah pendedahan kategori video berbilang dimensi yang membentuk vektor 10 dimensi, dan yi(ti) mewakili masa penggunaan pengguna ke-i. Satu ciri senario sebenar ialah kami tidak dapat mengetahui nisbah pendedahan video optimum sebenar pengguna. Oleh itu, kami membina fungsi mengikut peraturan pusat kluster dan menjana y maya untuk menggantikan y sebenar, supaya y sampel mempunyai keteraturan yang lebih baik. Saya tidak akan menerangkan secara terperinci tentang formula khusus di sini. Pelajar yang berminat boleh membaca teks asal. Mengapa ini boleh berlaku? Kerana kunci kepada algoritma kami ialah ia mesti dapat menyelesaikan beberapa kesan yang mengelirukan antara x dan t, iaitu, pengguna dalam talian dipengaruhi oleh strategi berat sebelah. Untuk menilai kesan strategi, kami hanya menyimpan x dan t dan menukar y untuk menilai masalah dengan lebih baik.

Pada data separa sintetik, algoritma kami juga menunjukkan prestasi yang lebih baik dan lebih baik daripada The kelebihan pada set data simulasi akan menjadi lebih besar. Ini menunjukkan bahawa algoritma hutan MDPP kami lebih stabil apabila data adalah kompleks. Di samping itu, mari kita lihat hiperparameter pada data sintetik, iaitu saiz hutan. Dalam gambar di sebelah kanan bawah, kita dapat melihat bahawa apabila saiz hutan meningkat, penunjuk berkumpul dengan lebih baik di bawah dua kriteria pembelahan yang akan sentiasa lebih baik, dan ia mencapai lebih baik apabila terdapat 100 pokok kesan optimum dicapai dengan 250 pokok, dan kemudian akan ada beberapa overfitting.
4 Sesi Soal Jawab
S: Mengapa merentasi Bolehkah normalisasi berfungsi apabila pendedahan melebihi 1?
J: Pemahaman saya begini, kerana apa yang kami lakukan adalah pengoptimuman kekangan perkadaran pendedahan Dalam proses ini, kami adalah nilai relatif. Dalam proses merentasi, kami sedang mencari titik perpecahan yang optimum, dan mencari kategori mana yang harus diberi keutamaan untuk mendapatkan lebih banyak pendedahan. Dalam proses ini, selagi kita boleh memastikan bahawa ia berskala secara proporsional, tidak mengapa.
Saya mempunyai pandangan yang sama, cuma skalakan secara berkadaran. Oleh kerana 1 adalah kekangan yang kuat, nilai yang kita kira pada mulanya pastinya bukan tepat 1, tetapi akan menjadi lebih rendah atau lebih tinggi. Jika terdapat lebih banyak lagi, tidak ada cara untuk memenuhi syarat unik kekangan yang kuat, dan adalah lebih wajar untuk menggunakan pemikiran yang normal. Kerana kami menganggap hubungan saiz relatif antara setiap kategori. Saya fikir hubungan saiz relatif adalah lebih penting, dan bukannya persoalan nilai mutlak.
Atas ialah kandungan terperinci Aplikasi inferens sebab dalam insentif paparan mikro dan senario penawaran dan permintaan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI