
Rumah >Peranti teknologi >AI >Ciri pembalikan menjadikan model id semula berubah daripada 88.54% kepada 0.15%
Ciri pembalikan menjadikan model id semula berubah daripada 88.54% kepada 0.15%

- 王林ke hadapan
- 2023-05-04 15:52:061160semak imbas
Versi pertama artikel ini ditulis pada Mei 2018, dan baru-baru ini diterbitkan pada Disember 2022. Saya telah menerima banyak sokongan dan pemahaman daripada bos saya sejak empat tahun lalu.
(Saya juga berharap pengalaman ini dapat memberi sedikit semangat kepada pelajar yang menghantar kertas kerja. Jika anda menulis kertas dengan baik, anda pasti menang. Jangan mudah putus asa!)
Versi awal arXiv ialah: Serangan Pertanyaan melalui Ciri Arah Bertentangan: Ke Arah Pengambilan Imej Teguh

pautan kertas: https://link.springer.com/article/10.1007/s11263-022-01737-y
Pautan sandaran kertas: https://zdzheng .xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
Kod: https://github.com/layumi/ U_turn
Pengarang: Zhedong Zheng, Liang Zheng, Yi Yang dan Fei Wu
Berbanding sebelum ini versi,
- Kami membuat beberapa pelarasan pada formula; telah ditambah Serangan Kueri Berskala/serangan kotak hitam/pertahanan dari tiga sudut yang berbeza
- Tambah kaedah dan perbandingan baharu pada Food256, Market-1501, CUB; , Oxford, Paris dan set data lain Cara baharu untuk menggambarkan.
- Menyerang struktur PCB di reid dan WiderResNet di Cifar10.
- Kes sebenar
- Dalam penggunaan sebenar. Sebagai contoh, katakan kita ingin menyerang sistem pengambilan imej Google atau Baidu untuk membuat berita besar (kabus). Kami boleh memuat turun imej anjing, mengira ciri melalui model imagenet (atau model lain, sebaik-baiknya model yang hampir dengan sistem perolehan semula), dan mengira bunyi lawan ditambah dengan memutarkan ciri (kaedah dalam artikel ini). Kembali kepada anjing. Kemudian gunakan fungsi carian imej untuk anjing selepas serangan Anda dapat melihat bahawa sistem Baidu dan Google tidak dapat mengembalikan kandungan yang berkaitan dengan anjing. Walaupun kita manusia masih boleh mengenali bahawa ini adalah imej anjing.
Apa
1. Niat asal artikel ini sebenarnya sangat mudah Model reid atau model perolehan landskap yang sedia ada telah mencapai kadar ingatan Recall-1 yang lebih banyak daripada 95%. Jadi bolehkah kita mereka bentuk cara untuk menyerang model perolehan semula? Di satu pihak, mari kita terokai latar belakang model REID Sebaliknya, serangan itu adalah untuk pertahanan yang lebih baik.
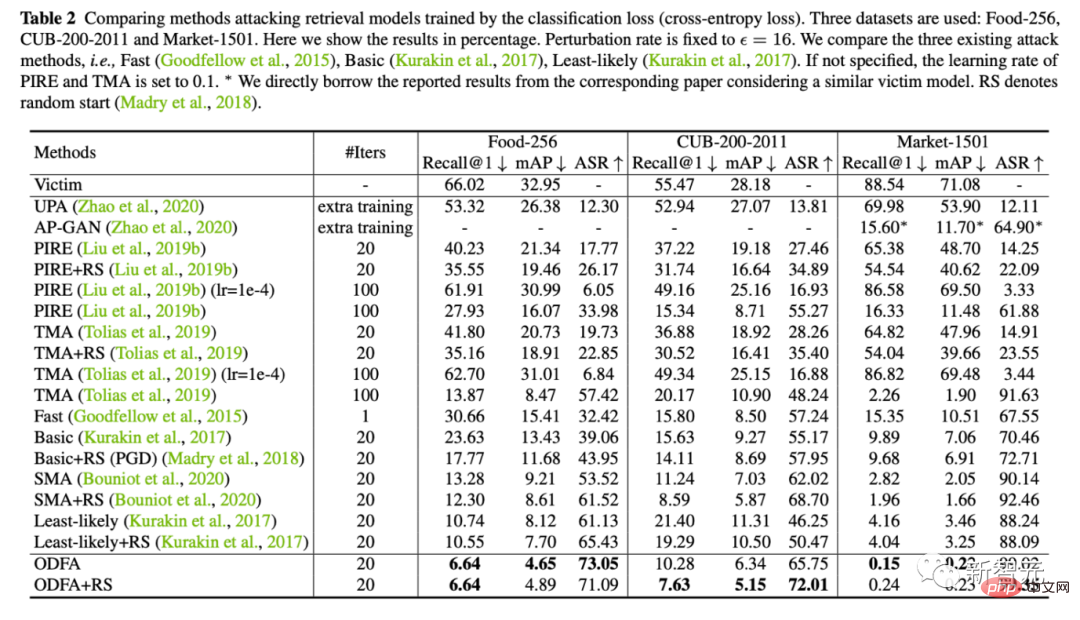
2 Perbezaan antara model perolehan dan model pengelasan tradisional ialah model perolehan menggunakan ciri yang diekstrak untuk membandingkan hasil (isihan), yang agak berbeza daripada model pengelasan tradisional . , seperti yang ditunjukkan dalam jadual di bawah.3. Satu lagi ciri masalah perolehan ialah set terbuka, yang bermaksud bahawa kategori semasa ujian selalunya sama seperti yang dilihat semasa latihan. Jika anda sudah biasa dengan set data anak, di bawah tetapan pengambilan, terdapat lebih daripada 100 jenis burung dalam set latihan semasa latihan, dan lebih daripada 100 jenis burung dalam set ujian Kedua-dua 100 jenis ini tidak mempunyai pertindihan jenis. Pemadanan dan kedudukan bergantung semata-mata pada ciri visual yang diekstrak. Oleh itu, beberapa kaedah serangan klasifikasi tidak sesuai untuk menyerang model perolehan semula, kerana kecerunan berdasarkan ramalan kategori semasa serangan sering tidak tepat.
1. Idea semula jadi ialah ciri serangan. Jadi bagaimana untuk menyerang ciri? Berdasarkan pemerhatian kami sebelum ini mengenai kehilangan entropi silang, (sila rujuk artikel kehilangan softmax margin besar). Selalunya apabila kita menggunakan kehilangan klasifikasi, ciri f akan mempunyai taburan jejari. Ini kerana persamaan kos dikira antara ciri dan berat W lapisan pengelasan terakhir semasa pembelajaran. Seperti yang ditunjukkan dalam rajah di bawah, selepas kita mempelajari model, sampel kategori yang sama akan diedarkan berhampiran W kategori tersebut, supaya f*W boleh mencapai nilai maksimum. Bagaimana
2 Jadi kami mencadangkan kaedah yang sangat mudah, iaitu mengubah ciri. Seperti yang ditunjukkan dalam rajah di bawah, sebenarnya terdapat dua kaedah serangan klasifikasi biasa yang juga boleh divisualisasikan bersama. Contohnya (a), ini adalah untuk menindas kategori dengan kebarangkalian pengelasan tertinggi (seperti Kecerunan Pantas), dengan memberikan -Wmaks, jadi terdapat arah perambatan kecerunan merah di sepanjang Wmaks songsang sebagai (b), terdapat satu lagi; cara untuk menyekat kategori yang paling tidak berkemungkinan. Ciri kategori yang mungkin ditarik ke atas (seperti Paling tidak berkemungkinan), jadi kecerunan merah berada di sepanjang Wmin.
3. Kedua-dua kaedah serangan klasifikasi ini sudah tentu sangat langsung dan berkesan dalam masalah klasifikasi tradisional. Walau bagaimanapun, oleh kerana set ujian dalam masalah perolehan adalah semua kategori ghaib (spesies burung ghaib), taburan f semula jadi tidak sesuai dengan Wmax atau Wmin Oleh itu, strategi kami adalah sangat mudah gerakkan f ke -f, seperti yang ditunjukkan dalam Rajah (c).
Dengan cara ini, dalam peringkat pemadanan ciri, keputusan dengan kedudukan tinggi, idealnya, akan disenaraikan paling rendah apabila dikira sebagai persamaan cos dengan -f, dari hampir 1 hingga hampir -1.
Mencapai kesan pengisihan pengambilan semula serangan kami.
4. Dalam masalah mendapatkan semula, kami juga sering menggunakan berbilang skala untuk penambahan pertanyaan, jadi kami juga mengkaji cara mengekalkan kesan serangan dalam kes ini. (Kesukaran utama ialah operasi ubah saiz mungkin melicinkan beberapa kegelisahan kecil tetapi kritikal.)
Malah, kaedah kami untuk menanganinya juga sangat mudah seperti ensemble model, kita gabungkan berbilang Hanya buat purata ensemble bagi kecerunan lawan skala.
Eksperimen
1 Di bawah tiga set data dan tiga penunjuk, kami menetapkan amplitud jitter, iaitu epsilon pada abscissa, dan membandingkan keputusan di bawah amplitud jitter yang sama Satu kaedah boleh membuat model retrieval membuat lebih banyak kesilapan. Kaedah kami ialah garisan kuning semuanya di bahagian bawah, bermakna kesan serangan adalah lebih baik.
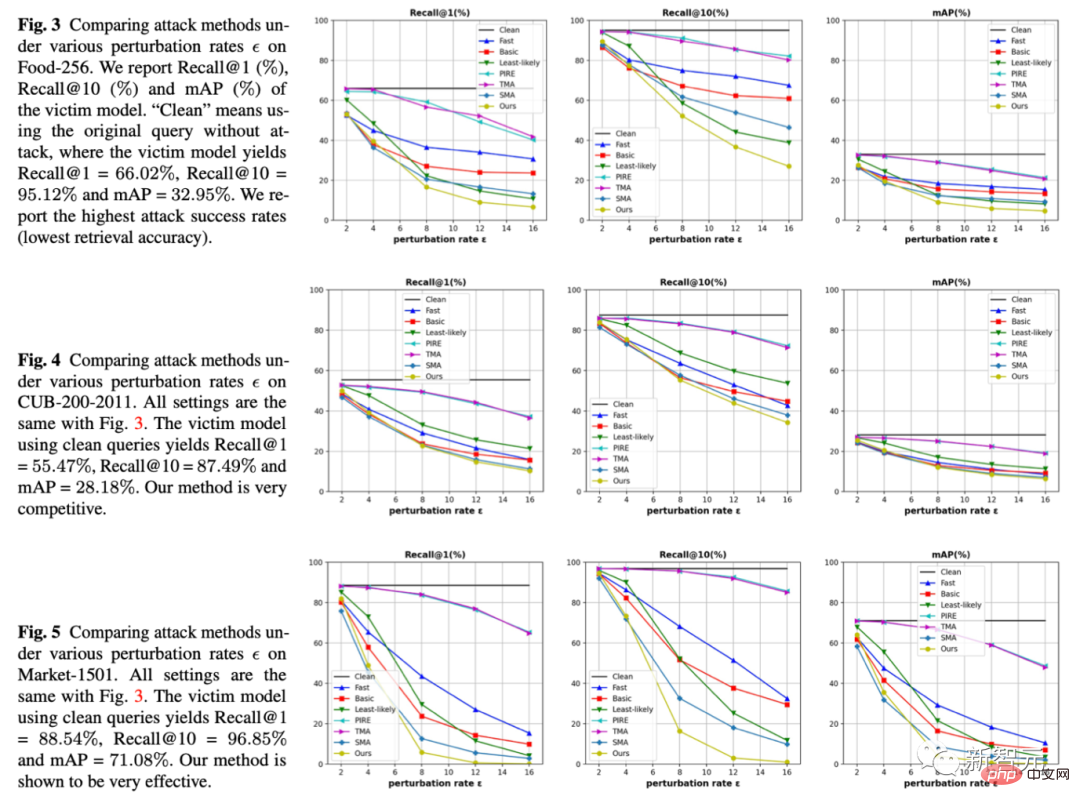
2 Pada masa yang sama, kami juga menyediakan hasil percubaan kuantitatif pada 5 set data (Makanan, CUB, Pasar, Oxford, Paris)<.>
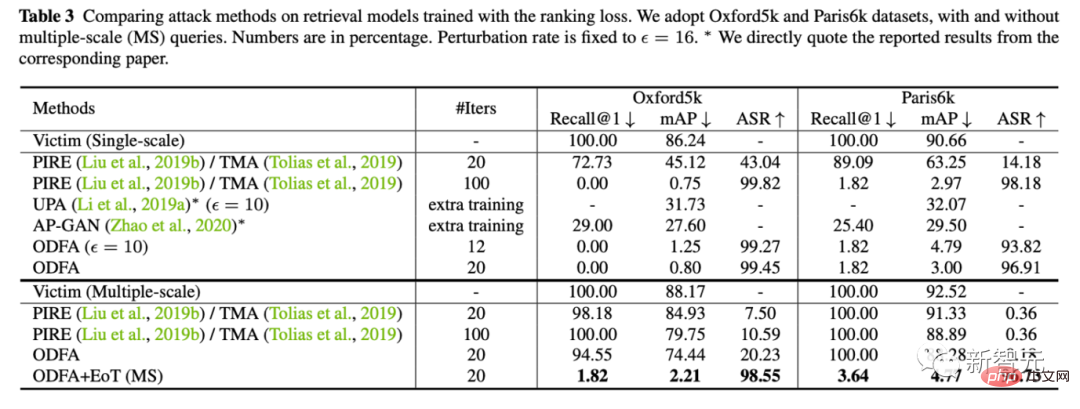
3 Untuk menunjukkan mekanisme model, kami juga cuba menyerang model klasifikasi Cifar10.
Anda dapat melihat bahawa strategi kami untuk menukar lapisan terakhir ciri juga mempunyai kuasa penindasan yang kuat terhadap 5 teratas. Untuk top-1, memandangkan tiada kategori calon ditarik ke atas, ia akan menjadi lebih rendah sedikit daripada kemungkinan kecil, tetapi ia hampir sama.
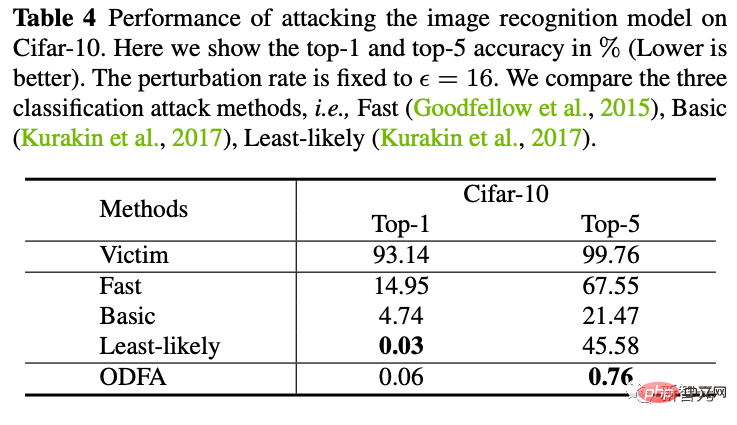
4. Serangan kotak hitam
Kami juga cuba menggunakan sampel serangan yang dihasilkan oleh ResNet50 untuk menyerang Model DenseNet kotak hitam (parameter model ini tidak tersedia kepada kami). Didapati bahawa keupayaan serangan migrasi yang lebih baik juga boleh dicapai.
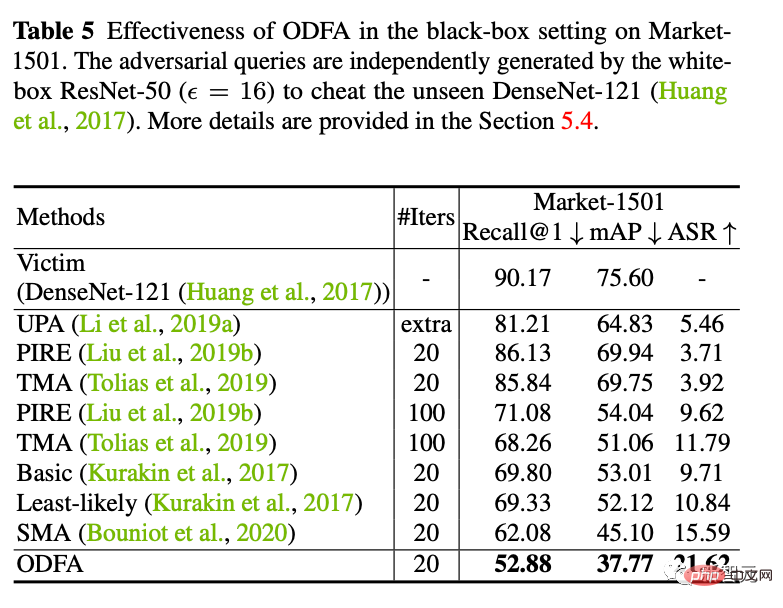
5
Kami menggunakan latihan lawan dalam talian untuk melatih model pertahanan. Kami mendapati bahawa ia masih tidak berkesan apabila menerima serangan kotak putih baharu, tetapi ia lebih stabil dalam kegelisahan kecil (menurunkan kurang mata) daripada model tanpa pertahanan sepenuhnya.
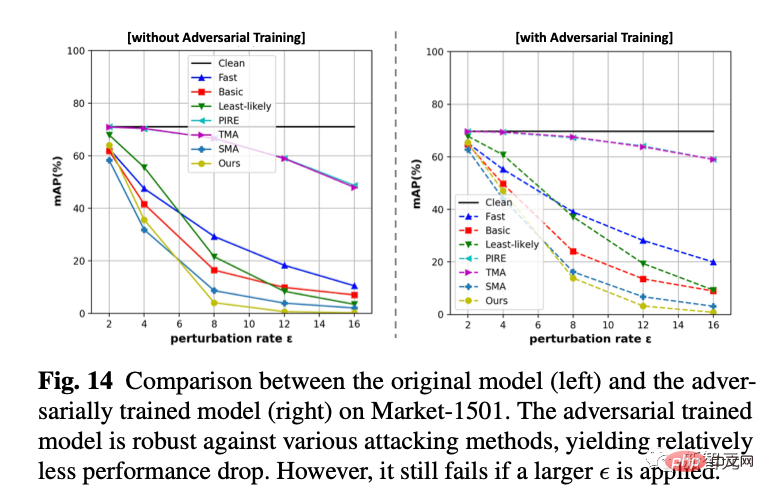
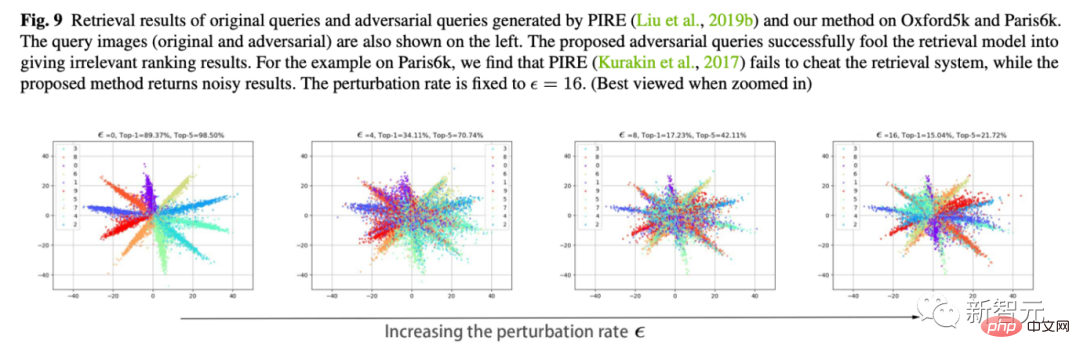
6. Visualisasi pergerakan ciri
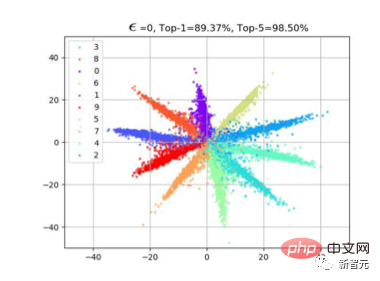
Ini juga percubaan kegemaran saya. Kami menggunakan Cifar10 untuk menukar dimensi lapisan pengelasan terakhir kepada 2 untuk merancang perubahan dalam ciri lapisan pengelasan.
Seperti yang ditunjukkan dalam rajah di bawah, apabila epsilon amplitud jitter meningkat, kita dapat melihat bahawa ciri-ciri sampel perlahan-lahan "berpusing". Sebagai contoh, kebanyakan ciri oren telah berpindah ke bahagian yang bertentangan.
Atas ialah kandungan terperinci Ciri pembalikan menjadikan model id semula berubah daripada 88.54% kepada 0.15%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI