
Rumah >Peranti teknologi >AI >Institut Penyelidikan Otak Digital Shanghai mengeluarkan DB1, model membuat keputusan berbilang modal besar pertama di China, yang boleh mencapai keputusan pantas untuk masalah ultra-kompleks
Institut Penyelidikan Otak Digital Shanghai mengeluarkan DB1, model membuat keputusan berbilang modal besar pertama di China, yang boleh mencapai keputusan pantas untuk masalah ultra-kompleks

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-04 09:58:061662semak imbas
Baru-baru ini, Institut Penyelidikan Otak Digital Shanghai (selepas ini dirujuk sebagai "Institut Penyelidikan Otak Digital") melancarkan model membuat keputusan berbilang modal otak digital berskala besar pertama (dirujuk sebagai DB1), memenuhi keperluan domestik. jurang dalam hal ini dan seterusnya mengesahkan Potensi model pra-latihan dalam teks, teks imej, pembelajaran pengukuhan membuat keputusan dan pengoptimuman operasi membuat keputusan. Pada masa ini, kami telah membuka sumber kod DB1 pada Github, pautan projek: https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1.
Sebelum ini, Institut Sains Matematik mencadangkan MADT (https://arxiv.org/abs/2112.02845)/MAT (https://arxiv.org/abs/2205.14953) dan model Badan kecerdasan pelbagai kecerdasan lain, melalui pemodelan jujukan dalam beberapa model luar talian yang besar, menggunakan model Transformer telah mencapai hasil yang luar biasa pada beberapa tugas tunggal/berbilang ejen, dan penyelidikan serta penerokaan ke arah ini diteruskan.
Dalam beberapa tahun kebelakangan ini, dengan peningkatan model pra-latihan yang besar, akademia dan industri terus membuat kemajuan baharu dalam parameter model pra-latihan dan tugasan pelbagai mod . Institut Penyelidikan Digital, yang memberi tumpuan kepada penyelidikan perisikan membuat keputusan, secara inovatif cuba menyalin kejayaan model pra-latihan kepada tugas membuat keputusan dan mencapai kejayaan.
Model besar membuat keputusan berbilang mod DB1
Sebelum ini, DeepMind melancarkan Gato, yang menyatukan tugas membuat keputusan ejen tunggal, perbualan pelbagai pusingan dan gambar- tugas penjanaan teks menjadi satu Berdasarkan masalah autoregresif Transformer, ia telah mencapai prestasi yang baik pada 604 tugasan yang berbeza, menunjukkan bahawa beberapa masalah membuat keputusan pembelajaran pengukuhan mudah boleh diselesaikan melalui ramalan jujukan Ini mengesahkan hala tuju penyelidikan Institut Matematik dalam arah model membuat keputusan yang besar.
Kali ini, DB1 yang dilancarkan oleh Institut Penyelidikan Matematik terutamanya menghasilkan semula dan mengesahkan Gato, dan cuba menjalankannya dari aspek struktur rangkaian dan jumlah parameter, jenis tugas dan bilangan tugasan. Cuba untuk menjadi sedekat mungkin dengan Gato dari segi parameter. Secara umumnya, Institut Penyelidikan Berangka menggunakan struktur yang serupa dengan Gato (bilangan Blok Penyahkod yang sama, saiz lapisan tersembunyi, dll.), tetapi dalam FeedForwardNetwork, kerana fungsi pengaktifan GeGLU akan memperkenalkan tambahan 1/3 daripada bilangan parameter , Institut Sains Matematik mahu Jumlah parameter hampir dengan Gato, dan keadaan lapisan tersembunyi 4 * n_embed dimensi diubah menjadi 2 * n_embed ciri dimensi melalui fungsi pengaktifan GeGLU. Jika tidak, kami berkongsi parameter pembenaman pada sisi pengekodan input dan output dengan pelaksanaan Gato. Berbeza daripada Gato, kami menggunakan penyelesaian PostNorm dalam memilih normalisasi lapisan, dan kami menggunakan pengiraan ketepatan campuran dalam Perhatian untuk meningkatkan kestabilan berangka.
-
-
Jenis tugas dan bilangan tugas: Bilangan tugas percubaan dalam DB1 mencapai 870, iaitu 44.04% lebih tinggi daripada Gato dan >=50 % lebih tinggi daripada Gato Prestasi pakar meningkat sebanyak 2.23%. Dari segi jenis tugas tertentu, DB1 kebanyakannya mewarisi tugas membuat keputusan, imej dan teks Gato, dan bilangan pelbagai tugasan pada asasnya tetap sama. Tetapi dari segi tugas membuat keputusan, DB1 juga telah memperkenalkan lebih daripada 200 tugasan senario kehidupan sebenar, iaitu Masalah Jurujual Perjalanan (TSP) skala 100 dan 200 nod Tugas jenis ini memilih 100-200 lokasi geografi secara rawak nod di semua bandar utama di China representasi) penyelesaian. - Dapat dilihat bahawa prestasi keseluruhan DB1 telah mencapai tahap yang sama dengan Gato, dan telah mula berkembang ke arah badan domain permintaan yang lebih dekat dengan perniagaan sebenar dan boleh diselesaikan dengan baik Masalah NP-hard TSP belum pernah diterokai ke arah ini sebelum ini oleh Gato.
Perbandingan penunjuk DB1 (kanan) dan GATO (kiri)

Pengagihan prestasi pelbagai tugas DB1 pada persekitaran simulasi pembelajaran pengukuhan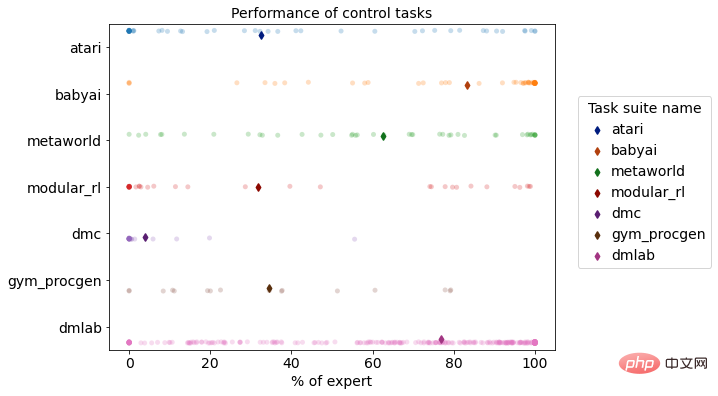
Berbanding dengan algoritma membuat keputusan tradisional, DB1 mempunyai prestasi yang baik dalam keupayaan merentas tugas membuat keputusan dan keupayaan migrasi pantas. Dari segi keupayaan membuat keputusan silang tugas dan kuantiti parameter, ia telah mencapai lonjakan daripada berpuluh juta parameter untuk satu tugas kompleks kepada berbilion parameter untuk pelbagai tugas yang kompleks, dan terus berkembang, serta mempunyai keupayaan untuk menyelesaikannya. masalah dalam persekitaran perniagaan yang kompleks. Keupayaan yang mencukupi untuk menyelesaikan masalah praktikal. Dari segi keupayaan penghijrahan, DB1 telah melengkapkan lonjakan daripada ramalan pintar kepada membuat keputusan yang bijak, dan daripada ejen tunggal kepada berbilang ejen, menebus kelemahan kaedah tradisional dalam migrasi silang tugas, yang memungkinkan untuk membina model besar dalam perusahaan.
Tidak dapat dinafikan bahawa DB1 juga menghadapi banyak kesukaran dalam proses pembangunan Institut Sains Matematik telah melakukan banyak percubaan untuk menyediakan industri dengan latihan model berskala besar dan pelbagai. storan data latihan tugasan Sediakan beberapa laluan penyelesaian standard. Memandangkan parameter model telah mencapai 1 bilion parameter dan skala tugas adalah besar, dan ia perlu dilatih pada lebih daripada 100T (300B+ Token) data pakar, rangka kerja latihan pembelajaran pengukuhan dalam biasa tidak lagi dapat memenuhi keperluan latihan pantas dalam keadaan ini. Untuk tujuan ini, di satu pihak, untuk latihan teragih, Institut Penyelidikan Matematik mempertimbangkan sepenuhnya struktur pengkomputeran pembelajaran tetulang, pengoptimuman operasi dan latihan model besar Dalam persekitaran mesin tunggal dan berbilang kad dan berbilang mesin dan berbilang kad, ia menggunakan sumber perkakasan dengan sebaik mungkin dan bijak mereka bentuk modul Mekanisme komunikasi antara kedua-dua model memaksimumkan kecekapan latihan model dan memendekkan masa latihan 870 tugasan kepada satu minggu. Sebaliknya, untuk pensampelan rawak teragih, pengindeksan, penyimpanan, pemuatan dan prapemprosesan data yang diperlukan dalam proses latihan juga telah menjadi kesesakan yang sepadan Institut Penyelidikan Matematik menggunakan mod pemuatan tertunda apabila memuatkan set data untuk menyelesaikan masalah had memori dan memaksimumkan Gunakan sepenuhnya memori yang tersedia. Di samping itu, selepas prapemprosesan data yang dimuatkan, data yang diproses akan dicache pada cakera keras, supaya data praproses boleh dimuatkan terus kemudian, mengurangkan masa dan kos sumber yang disebabkan oleh prapemprosesan berulang.
Pada masa ini, syarikat dan institusi penyelidikan antarabangsa dan domestik terkemuka seperti OpenAI, Google, Meta, Huawei, Baidu dan DAMO Academy telah menjalankan penyelidikan ke atas model besar berbilang modal dan Terdapat beberapa percubaan pengkomersilan, termasuk mengaplikasikannya dalam produknya sendiri atau menyediakan API model dan penyelesaian industri yang berkaitan. Sebaliknya, Institut Sains Matematik lebih menumpukan pada isu membuat keputusan dan menyokong percubaan aplikasi dalam tugasan membuat keputusan AI permainan, pengoptimuman penyelidikan operasi tugas penyelesaian TSP, tugas kawalan membuat keputusan robot, tugas menyelesaikan pengoptimuman kotak hitam dan berbilang- tugasan dialog bulat.
Prestasi Tugas
Pengoptimuman Penyelidikan Operasi: Penyelesaian Masalah TSP
Mengambil Masalah TSP bahagian Cina dengan bandar sebagai nod
Demonstrasi video tugasan pembelajaran pengukuhan
Model DB1 siap 870 Selepas pembelajaran luar talian tugasan membuat keputusan yang berbeza, keputusan penilaian menunjukkan bahawa 76.67% daripada tugasan mencapai atau melebihi 50% tahap pakar. Berikut ialah demonstrasi kesan daripada beberapa tugasan.
- Senario permainan video: DB1 boleh menerima input imej 2D/3D, dan boleh melengkapkan permainan piksel 2D seperti Atari dan Procgen, dan untuk DMLab DB1 sedemikian juga menunjukkan prestasi yang baik pada tugas input imej 3D yang serupa dengan dunia sebenar.

Atari Breakout

DMLab Teroka Lokasi Objek

Procgen DogBall
- Senario kawalan berterusan: Dalam tugas kawalan berterusan dalam bidang robotik, DB1 juga boleh memodelkan output dasar tindakan berterusan dan menyelesaikannya dengan baik pada tugas simulasi.

Metaworld PlateSlide

ModularRL Cheetah
文本 - 图像任务
- 文本生成:给出主务本描述
- 输入提示:makmal otak digital ialah sebuah syarikat berasaskan shanghai
-
生成结果:makmal otak digital ialah syarikat berasaskan shanghai dan kami sedang mencari syarikat orang yang berkemahiran tinggi dan berpengalaman untuk menyertai pasukan kami di shanghai, china.
kami adalah makmal otak digital dan kami sedang mencari orang yang berkemahiran tinggi dan berpengalaman untuk menyertai pasukan kami di shanghai, china.
ini adalah peluang untuk bekerja untuk sebuah syarikat yang terkenal dan sedang berkembang yang sedang melalui fasa pertumbuhan yang pantas dan mempunyai kesan dalam pasaran.
Ini adalah jawatan tetap sepenuh masa.
Kami sedang mencari jurutera perisian yang berkemahiran tinggi, bermotivasi dan berpengalaman yang boleh memimpin pasukan 5-10 dalam persekitaran yang sangat kompetitif
虽然当前多模态决策预训练模型作住 DB1仍存在一定局限性,诸如:跨域任务采样权重敏感、跨域知识迁移困难、长序列建模困难、专家数据强依赖等。虽然存在众多挆我我,中文我,住我我,住我我了态决策大模型是实现决策智能体从游戏走向更广泛场景,从虚拟走向现实,在现实开放动态环境中进行自主感觉与决策,最终实现更加通用人工智能的是他们最终实现更加通用人工智能的最终实现更加通用人工智能的最终实现更加通用人工智能的最与能的厳中。来,数研院将持续迭代数字大脑决策大模型,通过更大参数量,更有效的娏刁行,接入和支持更多任务,结合离线 / 线训练与微调,实现跨域、跨模态、跨模态、跨他们加,最终在现实应用场景下提供更通用、更高效、更低成本的决策智能决策解决方案。
Atas ialah kandungan terperinci Institut Penyelidikan Otak Digital Shanghai mengeluarkan DB1, model membuat keputusan berbilang modal besar pertama di China, yang boleh mencapai keputusan pantas untuk masalah ultra-kompleks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI