
Rumah >Java >javaTutorial >Cara menggunakan perangkak Java untuk merangkak imej dalam kelompok
Cara menggunakan perangkak Java untuk merangkak imej dalam kelompok

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-03 20:04:051968semak imbas
Idea Merangkak
Pemerolehan imej jenis ini pada asasnya ialah muat turun fail (HttpClient). Tetapi kerana ia bukan hanya untuk mendapatkan gambar, terdapat juga proses penghuraian halaman (Jsoup).
Jsoup: menghuraikan halaman html dan dapatkan pautan ke imej.
HttpClient: Minta pautan imej dan simpan imej secara setempat.
Langkah khusus
Mula-mula masukkan halaman utama untuk analisis, terdapat terutamanya kategori berikut (bukan semua kategori di sini, tetapi ini sudah mencukupi, ini hanya teknik pembelajaran.) , Matlamat kami adalah untuk mendapatkan gambar di bawah setiap kategori.
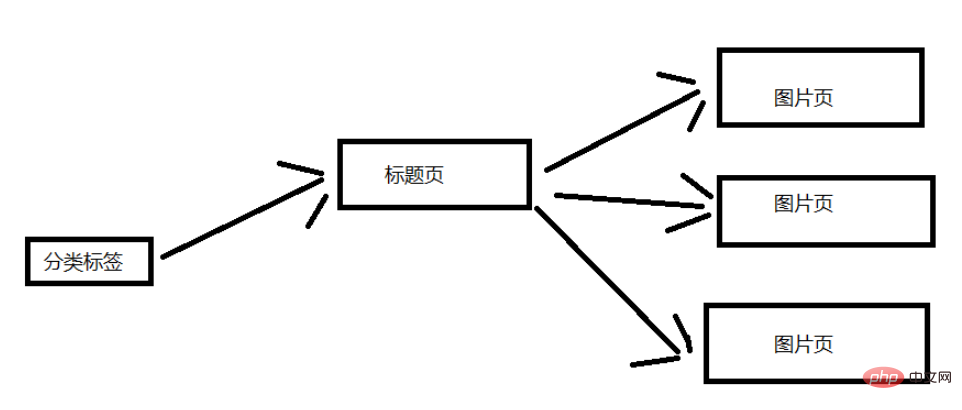
Mari kita analisa struktur tapak web saya akan ringkaskan di sini. Gambar di bawah ialah struktur umum Di sini, label klasifikasi dipilih untuk penjelasan. Halaman tab kategori mengandungi berbilang halaman tajuk, dan setiap halaman tajuk mengandungi berbilang halaman imej. (sepadan dengan berpuluh-puluh gambar pada halaman tajuk)
Kod khusus
Import koordinat pakej balang bergantung projek atau muat turun terus balang yang sepadan pakej. Mengimport projek juga boleh.
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>Kelas gambar dan kelas alat HeaderUtil
Kelas entiti: Merangkum sifat menjadi objek, yang menjadikannya lebih mudah untuk dipanggil.
package com.picture;
public class Picture {
private String title;
private String url;
public Picture(String title, String url) {
this.title = title;
this.url = url;
}
public String getTitle() {
return this.title;
}
public String getUrl() {
return this.url;
}
}Kategori Alat: Sentiasa menukar UA (Saya tidak tahu sama ada ia berguna, tetapi saya menggunakan IP saya sendiri, jadi ia mungkin tidak berguna)
package com.picture;
public class HeaderUtil {
public static String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
}Kategori Muat Turun
Multi-threading benar-benar terlalu pantas Di samping itu, saya hanya mempunyai satu IP dan tiada IP proksi boleh digunakan (saya tidak tahu sangat mengenainya). IP.
package com.picture;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private String referer;
private CloseableHttpClient httpClient;
private Picture picture;
private String filePath;
public SinglePictureDownloader(Picture picture, String referer, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.picture = picture;
this.referer = referer;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(picture.getUrl());
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", HeaderUtil.headers[rand.nextInt(HeaderUtil.headers.length)]);
get.setHeader("referer", referer);
System.out.println(referer);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, picture.getTitle());
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}Ini ialah kelas alat untuk mendapatkan sambungan HttpClient untuk mengelakkan penggunaan prestasi untuk membuat sambungan yang kerap. (Tetapi kerana saya menggunakan satu utas untuk merangkak di sini, ia tidak begitu berguna. Saya hanya boleh menggunakan satu sambungan HttpClient untuk merangkak. Ini kerana saya menggunakan beberapa utas untuk merangkak pada mulanya. Tetapi selepas pada dasarnya mendapat beberapa gambar, ia telah diharamkan, jadi ia telah ditukar kepada perangkak satu benang, jadi kumpulan sambungan kekal )
package com.m3u8;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}Kelas yang paling penting: kelas halaman parsing PictureSpider
package com.picture;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.m3u8.HttpClientUtil;
/**
* 首先从顶部分类标题开始,依次爬取每一个标题(小分页),每一个标题(大分页。)
* */
public class PictureSpider {
private CloseableHttpClient httpClient;
private String referer;
private String rootPath;
private String filePath;
public PictureSpider() {
httpClient = HttpClientUtil.getHttpClient();
}
/**
* 开始爬虫爬取!
*
* 从爬虫队列的第一条开始,依次爬取每一条url。
*
* 分页爬取:爬10页
* 每个url属于一个分类,每个分类一个文件夹
* */
public void start(List<String> urlList) {
urlList.stream().forEach(url->{
this.referer = url;
String dirName = url.substring(22, url.length()-1); //根据标题名字去创建目录
//创建分类目录
File path = new File("D:/DragonFile/DBC/mzt/", dirName); //硬编码路径,需要用户自己指定一个
if (!path.exists()) {
path.mkdir();
rootPath = path.toString();
}
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}
});
}
/**
* 标题分页获取链接
* */
public void page(String url) {
System.out.println("url:" + url);
String html = this.getHtml(url); //获取页面数据
Map<String, String> picMap = this.extractTitleUrl(html); //抽取图片的url
if (picMap == null) {
return ;
}
//获取标题对应的图片页面数据
this.getPictureHtml(picMap);
}
private String getHtml(String url) {
String html = null;
HttpGet get = new HttpGet(url);
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
get.setHeader("referer", url);
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
HttpEntity entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTf-8"); //关闭实体?
}
}
else {
System.out.println(statusCode);
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
private Map<String, String> extractTitleUrl(String html) {
if (html == null) {
return null;
}
Document doc = Jsoup.parse(html, "UTF-8");
Elements pictures = doc.select("ul#pins > li");
//不知为何,无法直接获取 a[0],我不太懂这方面的知识。
//那我就多处理一步,这里先放下。
Elements pictureA = pictures.stream()
.map(pic->pic.getElementsByTag("a").first())
.collect(Collectors.toCollection(Elements::new));
return pictureA.stream().collect(Collectors.toMap(
pic->pic.getElementsByTag("img").first().attr("alt"),
pic->pic.attr("href")));
}
/**
* 进入每一个标题的链接,再次分页获取图片的链接
* */
private void getPictureHtml(Map<String, String> picMap) {
//进入标题页,在标题页中再次分页下载。
picMap.forEach((title, url)->{
//分页下载一个系列的图片,每个系列一个文件夹。
File dir = new File(rootPath, title.trim());
if (!dir.exists()) {
dir.mkdir();
filePath = dir.toString(); //这个 filePath 是每一个系列图片的文件夹
}
for (int i = 1; i <= 60; i++) {
String html = this.getHtml(url + "/" + i);
if (html == null) {
//每个系列的图片一般没有那么多,
//如果返回的页面数据为 null,那就退出这个系列的下载。
return ;
}
Picture picture = this.extractPictureUrl(html);
System.out.println("开始下载");
//多线程实在是太快了(快并不是好事,我改成单线程爬取吧)
SinglePictureDownloader downloader = new SinglePictureDownloader(picture, referer, filePath);
downloader.download();
try {
Thread.sleep(1500); //不要爬的太快了,这里只是学习爬虫的知识。不要扰乱别人的正常服务。
System.out.println("爬取完一张图片,休息1.5秒。");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* 获取每一页图片的标题和链接
* */
private Picture extractPictureUrl(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
//获取标题作为文件名
String title = doc.getElementsByTag("h3")
.first()
.text();
//获取图片的链接(img 标签的 src 属性)
String url = doc.getElementsByAttributeValue("class", "main-image")
.first()
.getElementsByTag("img")
.attr("src");
//获取图片的文件扩展名
title = title + url.substring(url.lastIndexOf("."));
return new Picture(title, url);
}
} BootStrap kelas permulaan
Terdapat baris gilir crawler di sini, tetapi akhirnya saya tidak merangkak pun yang pertama Ini kerana saya membuat pengiraan yang salah dan meremehkannya dengan dua urutan magnitud. Walau bagaimanapun, fungsi program adalah betul.
package com.picture;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 爬虫启动类
* */
public class BootStrap {
public static void main(String[] args) {
//反爬措施:UA、refer 简单绕过就行了。
//refer https://www.mzitu.com
//使用数组做一个爬虫队列
String[] urls = new String[] {
"https://www.mzitu.com/xinggan/",
"https://www.mzitu.com/zipai/"
};
// 添加初始队列,启动爬虫
List<String> urlList = new ArrayList<>(Arrays.asList(urls));
PictureSpider spider = new PictureSpider();
spider.start(urlList);
}
}Hasil merangkak

Nota
Terdapat ralat pengiraan di sini , kodnya adalah seperti berikut:
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}Nilai i terlalu besar kerana saya membuat kesilapan dalam pengiraan saya. Jika dimuat turun mengikut situasi ini, sejumlah 4 * 10 * (30-5) * 60 = 64800 gambar akan dimuat turun. (Setiap halaman mengandungi 30 halaman tajuk, dan kira-kira 5 adalah iklan.) Saya fikir hanya terdapat beberapa ratus gambar pada mulanya! Ini adalah anggaran, tetapi volum muat turun sebenar tidak akan jauh berbeza daripada ini (tiada susunan perbezaan magnitud). Jadi saya memuat turun seketika dan mendapati hanya gambar dalam barisan pertama yang dimuat turun. Sudah tentu, sebagai program pembelajaran crawler, ia masih sangat layak.
Program ini hanya untuk pembelajaran Saya menetapkan selang muat turun setiap gambar kepada 1.5 saat, dan ia adalah program satu benang, jadi kelajuannya akan menjadi sangat perlahan. Tetapi itu tidak mengapa, selagi program berfungsi dengan betul, tiada siapa yang akan benar-benar menunggu sehingga imej dimuat turun.
Ia akan mengambil masa yang lama: 64800*1.5s = 97200s = 27j Ini hanya anggaran kasar dan tidak mengambil kira masa berjalan program yang lain, tetapi masa lain pada dasarnya boleh diabaikan.
Atas ialah kandungan terperinci Cara menggunakan perangkak Java untuk merangkak imej dalam kelompok. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Mengapakah \'Tidak boleh mengeluarkan pernyataan manipulasi data dengan executeQuery()\' Berlaku Ralat?
- Bagaimanakah Regex Boleh Mengeluarkan Komen Berbilang Talian Gaya C dengan Berkesan daripada Kod?
- Warisan Java: Mengapa Pewarisan Tunggal dan Pelaksanaan Pelbagai Antara Muka?
- Bagaimana untuk Menyambung ke Pangkalan Data Oracle Menggunakan Nama Perkhidmatan di Java?
- Apakah Perbezaan Antara `` dan `` pada Musim Bunga 3?