
Rumah >Peranti teknologi >AI >Beberapa petua untuk mengelakkan perangkap apabila menggunakan ChatGLM
Beberapa petua untuk mengelakkan perangkap apabila menggunakan ChatGLM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-02 13:58:062221semak imbas
Saya berkata semalam bahawa saya menggunakan satu set ChatGLM selepas pulang dari Karnival Teknologi Data, dan merancang untuk mengkaji penggunaan model bahasa yang besar untuk melatih pangkalan pengetahuan operasi dan penyelenggaraan pangkalan data Ramai rakan tidak mempercayainya, mengatakan bahawa anda sudah tua, Lao Bai, dan anda masih boleh melakukannya. Adakah anda akan bermain-main dengan perkara ini sendiri? Bagi melenyapkan keraguan rakan-rakan ini, saya akan berkongsi dengan anda proses melontarkan ChatGLM pada dua hari lepas hari ini, dan juga berkongsi beberapa petua untuk mengelakkan perangkap untuk rakan-rakan yang berminat untuk melontarkan ChatGLM.
ChatGLM-6B dibangunkan berdasarkan model bahasa GLM yang dilatih bersama oleh Makmal KEG Universiti Tsinghua dan Zhipu AI pada tahun 2023. Ia adalah model bahasa besar yang menyediakan Balasan dan sokongan yang sesuai. Jawapan di atas dijawab oleh ChatGLM sendiri GLM-6B ialah model pra-latihan parameter sumber terbuka 6.2 bilion, yang dicirikan dengan dapat dijalankan secara tempatan dalam persekitaran perkakasan yang agak kecil. Ciri ini membolehkan aplikasi berdasarkan model bahasa besar memasuki beribu-ribu isi rumah. Tujuan makmal KEG adalah untuk membolehkan model GLM-130B yang lebih besar (130 bilion parameter, bersamaan dengan GPT-3.5) dilatih dalam persekitaran yang rendah dengan RTX 3090 8 hala.
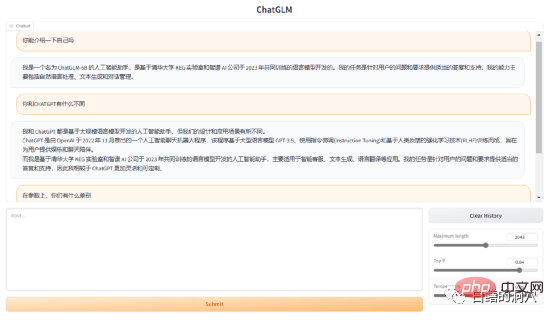
Jika matlamat ini benar-benar dapat dicapai, pastinya ia akan menjadi berita baik bagi mereka yang ingin membuat beberapa aplikasi berdasarkan model bahasa yang besar. Model FP16 ChatGLP-6B semasa adalah lebih kurang 13G, dan model terkuantiti INT-4 adalah kurang daripada 4GB Ia boleh dijalankan pada RTX 3060TI dengan memori video 6GB.
Saya tidak tahu banyak tentang situasi ini sebelum penggunaan, jadi saya membeli 12GB RTX 3060 yang tidak tinggi atau rendah, jadi selepas melengkapkan pemasangan dan penggunaan, saya masih tidak dapat menjalankan model FP16. Jika saya lebih tahu untuk melakukan ujian dan pengesahan di rumah, saya baru sahaja membeli 3060TI yang lebih murah. Jika anda ingin menjalankan model FP16 tanpa kerugian, anda mesti mendapatkan 3090 dengan memori video 24GB.
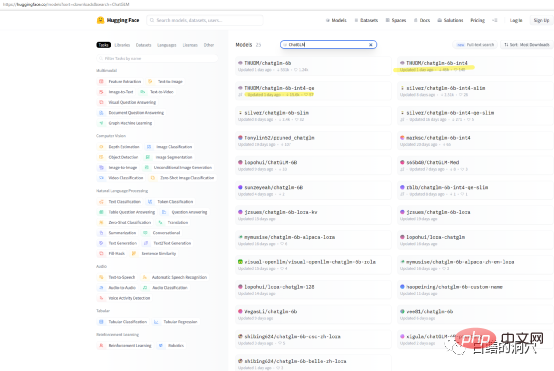
Jika anda hanya mahu menguji keupayaan ChatGLP-6B pada mesin anda sendiri, maka anda mungkin tidak perlu memuat turun THUDM/ChatGLM secara langsung - Model 6B, terdapat beberapa model kuantitatif berpakej tersedia untuk dimuat turun pada muka peluk. Kelajuan muat turun model sangat perlahan, anda boleh memuat turun model kuantitatif int4 secara terus.
Saya menyelesaikan pemasangan ini pada PC 8 teras I7 dengan kad grafik RTX 3060 memori video 12G Oleh kerana komputer ini adalah komputer kerja saya, saya memasang ChatGLM pada subnet WSL. Memasang ChatGLM pada subsistem WINDOWS WSL adalah lebih rumit daripada memasangnya terus dalam persekitaran LINUX. Perangkap terbesar ialah pemasangan pemacu kad grafik. Apabila menggunakan ChatGLM secara langsung pada Linux, anda perlu memasang pemacu NVIDIA secara langsung dan mengaktifkan pemacu kad rangkaian melalui modprobe. Memasang pada WSL agak berbeza.
ChatGLM boleh dimuat turun di github, dan terdapat beberapa dokumen ringkas di tapak web, malah termasuk dokumen untuk menggunakan ChatGLM pada WINDOWS WSL. Walau bagaimanapun, jika anda seorang pemula dalam bidang ini dan menggunakan sepenuhnya mengikut dokumen ini, anda akan menghadapi banyak masalah.
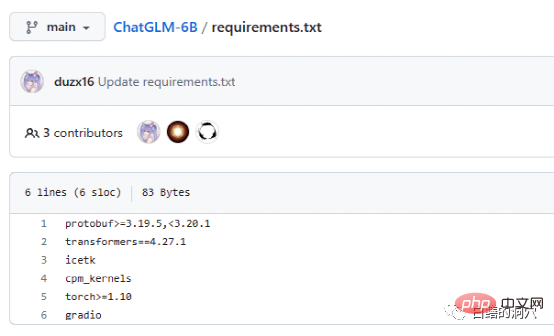
Dokumen Requriements.txt menyenaraikan senarai dan nombor versi komponen sumber terbuka utama yang digunakan oleh ChatGLM Teras ialah pengubah, yang memerlukan versi 4.27. 1. Sebenarnya, syaratnya tidak begitu ketat. Tidak ada masalah besar jika ia lebih rendah sedikit, tetapi lebih baik menggunakan versi yang sama untuk alasan keselamatan. Icetk adalah untuk pemprosesan token, cpm_kernels ialah panggilan teras bagi model pemprosesan Cina dan cuda, dan protobuf adalah untuk penyimpanan data berstruktur. Gradio ialah rangka kerja untuk menjana aplikasi AI dengan cepat menggunakan Python. Saya tidak memerlukan sebarang pengenalan kepada Torch.
ChatGLM boleh digunakan dalam persekitaran tanpa GPU, menggunakan CPU dan 32GB memori fizikal untuk dijalankan, tetapi kelajuan larian adalah sangat perlahan dan hanya boleh digunakan untuk pengesahan demonstrasi. Jika anda ingin bermain ChatGLM, sebaiknya lengkapkan diri anda dengan GPU.
Perangkap terbesar dalam memasang ChatGLM pada WSL ialah pemacu kad grafik sungguh mengelirukan. Sebenarnya, penggunaan perisian tidak menyusahkan, tetapi pemacu kad grafik sangat rumit.
Oleh kerana ia digunakan pada subsistem WSL, LINUX hanyalah sistem emulasi, bukan LINUX yang lengkap Oleh itu, pemacu grafik NVIDIA hanya perlu dipasang pada WINDOWS dan tidak perlu diaktifkan dalam WSL. Walau bagaimanapun, CUDA TOOLS masih perlu dipasang dalam persekitaran maya LINUX WSL. Pemacu NVIDIA pada WINDOWS mesti memasang pemacu terkini dari tapak web rasmi, dan tidak boleh menggunakan pemacu keserasian yang disertakan dengan WIN10/11 Oleh itu, jangan tinggalkan memuat turun pemacu terkini dari tapak web rasmi dan memasangnya.
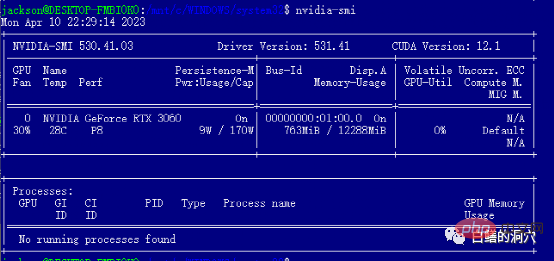
Selepas memasang pemacu WIN, anda boleh memasang alat cuda terus dalam WSL Selepas pemasangan selesai, jalankan nvidia-smi dan jika anda dapat melihat perkara di atas antara muka , maka tahniah, anda telah berjaya mengelakkan lubang pertama. Malah, anda akan menghadapi beberapa masalah apabila memasang alat cuda. Iaitu, sistem anda mesti mempunyai versi gcc, gcc-dev, make dan alat berkaitan kompilasi lain yang dipasang Jika komponen ini tiada, pemasangan alat cuda akan gagal.
Sebenarnya, ia mengelakkan perangkap pemandu NVIDIA, dan pemasangan seterusnya adalah masih sangat lancar. Dari segi pemilihan sistem, saya masih mengesyorkan memilih Ubuntu yang serasi dengan Debian Versi baharu kebolehan Ubuntu adalah sangat pintar dan boleh membantu anda menyelesaikan isu keserasian versi sejumlah besar perisian dan merealisasikan penurunan taraf versi automatik bagi sesetengah perisian.
Proses pemasangan berikut boleh diselesaikan dengan lancar mengikut panduan pemasangan Perlu diingat bahawa kerja menggantikan sumber pemasangan dalam /etc/apt/sources.list sebaiknya diselesaikan mengikut panduan satu tangan, kelajuan pemasangan akan Ia adalah lebih cepat, dan sebaliknya, ia juga mengelakkan masalah keserasian versi perisian. Sudah tentu, tidak menggantikannya tidak semestinya akan menjejaskan proses pemasangan seterusnya.
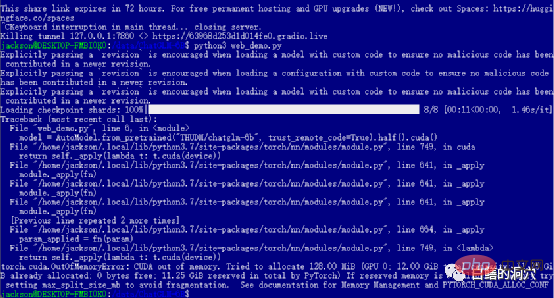
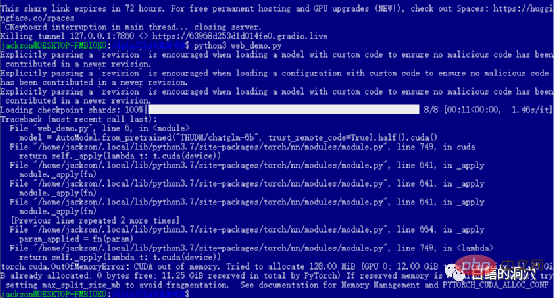
Jika anda berjaya melepasi tahap sebelumnya, maka anda telah memasuki langkah terakhir dan memulakan web_demo . Melaksanakan python3 web_demo.py boleh memulakan contoh perbualan WEB. Pada masa ini, jika anda seorang yang miskin dan hanya mempunyai 3060 dengan memori video 12GB, maka anda pasti akan melihat ralat di atas Walaupun anda menetapkan PYTORCH_CUDA_ALLOC_CONF kepada minimum 21, anda tidak boleh mengelakkan ralat ini. Pada masa ini anda tidak boleh malas, anda mesti menulis semula skrip python.
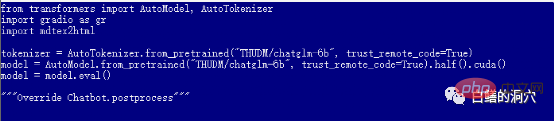
Web_demo.py lalai menggunakan model pra-latihan FP16 dengan lebih daripada 13GB pasti tidak akan dimuatkan ke dalam 12GB memori sedia ada , jadi anda perlu membuat sedikit pelarasan pada kod ini.

Anda boleh menukar kepada kuantiti(4) untuk memuatkan model kuantisasi INT4, atau tukar kepada kuantisasi(8) untuk memuatkan model kuantisasi INT8. Dengan cara ini, memori kad grafik anda akan mencukupi, dan ia boleh menyokong anda melakukan pelbagai perbualan.
Perlu diambil perhatian bahawa muat turun model tidak benar-benar bermula sehingga web_demo.py dimulakan, jadi ia akan mengambil masa yang lama untuk memuat turun model 13GB Anda boleh melakukan kerja ini di tengah-tengah malam, atau Anda boleh terus menggunakan alat muat turun seperti Thunder untuk memuat turun model daripada berpeluk muka terlebih dahulu. Jika anda tidak tahu apa-apa tentang model dan tidak begitu mahir dalam memasang model yang dimuat turun, anda juga boleh mengubah suai nama model dalam kod, THUDM/chatglm-6b-int4, dan memuat turun terus model terkuantiti INT4 dengan kurang daripada 4GB daripada Internet. Ini akan Ia lebih pantas, tetapi kad grafik anda yang rosak tidak dapat menjalankan model FP16.
Pada ketika ini, anda boleh bercakap dengan ChatGLM melalui halaman web, tetapi ini hanyalah permulaan masalah. Hanya apabila anda boleh melatih model anda yang diperhalusi barulah perjalanan anda ke ChatGLM benar-benar bermula. Bermain perkara seperti ini masih memerlukan banyak tenaga dan wang, jadi berhati-hati apabila memasuki perangkap.
Akhirnya, saya sangat berterima kasih kepada rakan-rakan saya di Makmal KEG Universiti Tsinghua Hasil kerja mereka membolehkan lebih ramai orang menggunakan model bahasa yang besar pada kos yang rendah.
Atas ialah kandungan terperinci Beberapa petua untuk mengelakkan perangkap apabila menggunakan ChatGLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI