
Rumah >Peranti teknologi >AI >Pembelajaran mesin graf ada di mana-mana, menggunakan Transformer untuk mengurangkan pengehadan GNN
Pembelajaran mesin graf ada di mana-mana, menggunakan Transformer untuk mengurangkan pengehadan GNN

- WBOYke hadapan
- 2023-05-02 10:07:061216semak imbas
Dalam kehidupan kita hari ini, contoh graf termasuk rangkaian sosial, seperti Twitter, Mastodon, dan mana-mana rangkaian petikan yang memautkan kertas dan pengarang, molekul, graf pengetahuan, seperti gambar rajah UML, ensiklopedia dan apa-apa sahaja dengan hiperpautan Laman web , ayat yang diwakili sebagai pokok sintaksis, dan mana-mana grid 3D, dsb., boleh dikatakan bahawa graf ada di mana-mana.
Baru-baru ini, saintis penyelidikan Hugging Face Clémentine Fourrier memperkenalkan pembelajaran mesin graf yang ada di mana-mana hari ini dalam artikel "Pengenalan kepada Pembelajaran Mesin Graf". Apakah grafik? Mengapa menggunakan graf? Cara terbaik untuk mewakili graf? Bagaimanakah orang belajar daripada graf? Clémentine Fourrier menegaskan bahawa graf ialah perihalan item yang dikaitkan dengan hubungan Antaranya, daripada kaedah pra-neural kepada graf rangkaian saraf masih biasa digunakan kaedah pembelajaran pada graf.
Selain itu, beberapa penyelidik baru-baru ini mula mempertimbangkan untuk menggunakan Transformers pada graf Transformer mempunyai kebolehskalaan yang baik dan boleh mengurangkan beberapa batasan GNN, dan prospeknya sangat menjanjikan.
1 Graf ialah perihalan item yang dipautkan oleh perhubungan
Pada asasnya, graf ialah perihalan item yang dipautkan oleh perhubungan. Item graf (atau rangkaian) dipanggil nod (atau bucu) dan disambungkan dengan tepi (atau pautan). Sebagai contoh, dalam rangkaian sosial, nod ialah pengguna dan tepi ialah sambungan antara pengguna dalam molekul, nod ialah atom dan tepi ialah ikatan molekulnya.
- Graf dengan nod ditaip atau tepi ditaip dipanggil graf heterogen Contohnya, item dalam rangkaian petikan boleh menjadi kertas atau pengarang, dengan nod ditaip, Semasa hubungan masuk Graf XML mempunyai tepi yang ditaip; ia tidak boleh diwakili semata-mata oleh topologinya, tetapi maklumat tambahan diperlukan
- Graf juga boleh diarahkan (cth. rangkaian pengikut, A mengikuti B tidak bermakna B mengikuti A) atau tidak berarah (contohnya, hubungan antara molekul dan atom adalah dua arah). Tepi boleh menyambungkan nod yang berbeza atau nod kepada dirinya sendiri (tepi diri), tetapi tidak semua nod perlu disambungkan
Seperti yang anda lihat, menggunakan data mesti mempertimbangkannya terlebih dahulu Perwakilan optimum, termasuk homogen/heterogen, terarah/tidak terarah, dsb.
Pada peringkat graf, tugas utama termasuk yang berikut:
- Penjanaan graf untuk penemuan ubat bagi menjana molekul rasional baharu
- Evolusi graf, iaitu diberi graf untuk meramalkan bagaimana ia akan berkembang dari semasa ke semasa, boleh digunakan dalam fizik untuk meramalkan evolusi sesuatu sistem
- Ramalan peringkat graf, pengelasan atau tugas regresi daripada graf, seperti meramalkan ketoksikan molekul
Lapisan nod biasanya ramalan atribut nod, contohnya penggunaan Alphafold ramalan atribut nod untuk diramal Ia adalah masalah biokimia yang sukar untuk meramalkan bagaimana molekul akan terlipat dalam ruang 3D memandangkan koordinat 3D atom dalam rajah keseluruhan molekul.
Ramalan tepi termasuk ramalan atribut tepi dan ramalan kelebihan tiada. Ramalan atribut tepi membantu meramalkan kesan sampingan ubat, memandangkan kesan sampingan yang buruk daripada sepasang ramalan kelebihan yang hilang digunakan dalam sistem pengesyoran untuk meramalkan sama ada dua nod dalam graf adalah berkaitan.
Di peringkat subgraf, pengesanan komuniti atau ramalan atribut subgraf boleh dilakukan. Rangkaian sosial boleh menggunakan pengesanan komuniti untuk menentukan cara orang disambungkan. Ramalan atribut subgraf sering digunakan dalam sistem jadual perjalanan, seperti Peta Google, yang boleh digunakan untuk meramalkan anggaran masa ketibaan.
Apabila meramalkan evolusi graf tertentu, segala-galanya dalam persediaan transformasi, termasuk latihan, pengesahan dan ujian, boleh dilakukan pada graf yang sama. Tetapi mencipta set data latihan, penilaian atau ujian daripada graf tunggal bukanlah mudah, dan banyak kerja dilakukan menggunakan graf yang berbeza (pembahagian latihan/penilaian/ujian yang berasingan), yang dipanggil tetapan induksi.
Terdapat dua cara biasa untuk mewakili pemprosesan dan operasi graf, sama ada sebagai set semua tepinya (mungkin ditambah dengan set semua nodnya), atau sebagai set semua matriks bersebelahan nodnya antara. Antaranya, matriks bersebelahan ialah matriks segi empat sama (saiz nod × saiz nod) yang menunjukkan nod yang disambungkan terus ke nod lain. Ambil perhatian bahawa mempunyai matriks bersebelahan yang jarang menjadikan pengiraan lebih sukar kerana kebanyakan graf tidak bersambung padat.
Graf sangat berbeza daripada objek biasa yang digunakan dalam ML, disebabkan topologinya yang lebih kompleks daripada "jujukan" (seperti teks dan audio) atau "grid tersusun" (seperti imej dan video): walaupun seseorang boleh Ia diwakili sebagai senarai atau matriks, tetapi perwakilan ini tidak boleh dianggap sebagai objek tertib. Iaitu, jika anda berebut perkataan dalam ayat, anda mencipta ayat baharu, dan jika anda mengacak imej dan menyusun semula lajurnya, anda mencipta imej baharu.
Kapsyen: Logo Hugging Face dan logo Hugging Face yang terganggu adalah imej baharu yang berbeza sama sekali
Tetapi ini tidak berlaku dengan graf: jika kita mengocok senarai tepi atau lajur matriks bersebelahan graf, ia masih graf yang sama.
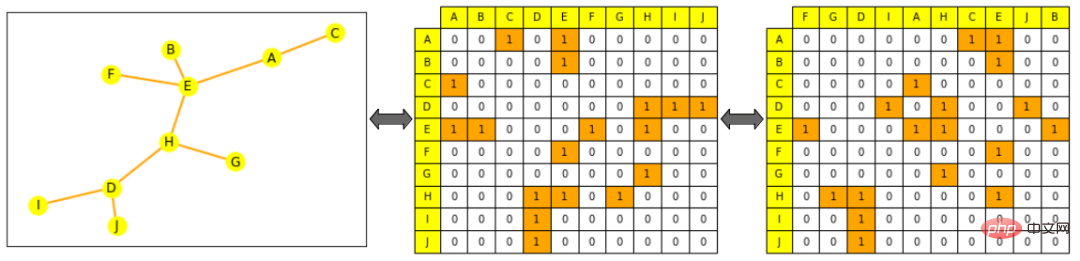
Nota gambar: Di sebelah kiri ialah gambar kecil, kuning mewakili nod, oren mewakili tepi; , lajur dan Baris disusun mengikut susunan abjad nod: baris untuk nod A (baris pertama) boleh dilihat disambungkan kepada E dan C; gambar di sebelah kanan mempunyai matriks bersebelahan (lajur tidak lagi mengikut abjad dipesan), yang masih merupakan perwakilan graf yang sah, Iaitu, A masih disambungkan kepada E dan C
2 Perwakilan grafik melalui ML
Proses konvensional memproses graf menggunakan pembelajaran mesin, Ia bermula dengan menjana perwakilan yang bermakna untuk projek, di mana nod, tepi atau graf lengkap bergantung pada keperluan tugas tertentu, dan kemudian melatih peramal untuk tugas sasaran. Seperti corak lain, anda boleh mengekang perwakilan matematik sesuatu objek supaya ia hampir secara matematik dengan objek yang serupa. Tetapi dalam hal ini, persamaan adalah sukar untuk ditakrifkan dengan ketat dalam graf ML: sebagai contoh, adakah dua nod lebih serupa apabila mereka mempunyai label yang sama atau jiran yang sama?
Seperti yang ditunjukkan di bawah, artikel ini memfokuskan pada penjanaan perwakilan nod Sebaik sahaja terdapat perwakilan peringkat nod, adalah mungkin untuk mendapatkan maklumat tahap tepi atau graf. Untuk maklumat peringkat tepi, anda boleh menyambungkan pasangan nod atau melakukan pendaraban titik untuk maklumat peringkat graf, anda boleh melakukan pengumpulan global pada tensor bercantum yang diwakili oleh semua peringkat nod, termasuk purata, penjumlahan, dsb. Walau bagaimanapun, ia masih melicinkan dan kehilangan maklumat tentang keseluruhan graf - koleksi hierarki rekursif mungkin lebih masuk akal, atau menambah nod tiruan yang disambungkan kepada semua nod lain dalam graf dan mewakilinya sebagai keseluruhan graf ekspres.
Pendekatan pra-neural
Hanya gunakan ciri kejuruteraan
Sebelum rangkaian saraf, graf dan item minatnya boleh diwakili sebagai gabungan ciri dalam cara khusus tugas. Hari ini, ciri ini masih digunakan dalam penambahan data dan pembelajaran separa penyeliaan, dan walaupun kaedah penjanaan ciri yang lebih canggih wujud, adalah penting untuk mencari cara terbaik untuk menyalurkan ciri ini kepada rangkaian bergantung pada tugas.
Ciri peringkat nod boleh memberikan maklumat tentang kepentingan serta maklumat berasaskan struktur dan menggabungkannya.
Kepusatan nod boleh digunakan untuk mengukur kepentingan nod dalam graf, dikira secara rekursif dengan menjumlahkan kepusatan jiran setiap nod sehingga penumpuan, atau dengan metrik jarak terpendek antara nod Untuk mengira secara rekursif, darjah nod ialah bilangan jiran langsung yang ada; untuk memberi Cipta semua garis percikan dengan bilangan nod bersambung tertentu.
Rajah Nota: 2 hingga 5 lakaran kecil nod
Ciri aras tepi ditambah dengan maklumat yang lebih terperinci tentang ketersambungan nod, termasuk jarak terpendek antara dua nod, jiran sepunya mereka, dan indeks Katz, yang merujuk kepada laluan panjang tertentu yang boleh dilalui antara dua nod - yang boleh dikira secara langsung daripada matriks bersebelahan).
Ciri aras graf mengandungi maklumat peringkat tinggi tentang persamaan dan keistimewaan graf, di mana pengiraan subgraf, walaupun secara pengiraan mahal, memberikan maklumat tentang bentuk subgraf. Kaedah teras mengukur persamaan antara graf melalui kaedah "beg-nod" yang berbeza (serupa dengan beg-of-words).
Kaedah berasaskan berjalan
Kaedah berasaskan berjalan menggunakan kebarangkalian melawati nod j dari nod i secara rawak untuk mentakrifkan persamaan mengukur, Kaedah ini menggabungkan maklumat tempatan dan global. Sebagai contoh, Node2Vec sebelum ini mensimulasikan jalan rawak antara nod graf, menggunakan langkau-gram untuk memproses jalan ini sama seperti kita melakukan perkataan dalam ayat untuk mengira benam.
Kaedah ini juga boleh digunakan untuk mempercepatkan pengiraan kaedah PageRank, yang memberikan setiap nod skor kepentingan berdasarkan sambungannya kepada nod lain, mis Kekerapan capaian. Walau bagaimanapun, kaedah di atas juga mempunyai had tertentu mereka tidak boleh mendapatkan pembenaman nod baharu, tidak dapat menangkap persamaan struktur antara nod dengan baik dan tidak boleh menggunakan ciri tambahan.
3 Bagaimanakah graf rangkaian saraf memproses graf?
Rangkaian saraf boleh membuat generalisasi kepada data yang tidak kelihatan. Memandangkan kekangan perwakilan yang dinyatakan sebelum ini, bagaimanakah rangkaian saraf yang baik harus mengendalikan graf?
Dua kaedah ditunjukkan di bawah:
- tidak berubah kepada penggantian:
- Persamaan: f(P(G))=f(G)f(P(G))=f(G), dengan f ialah rangkaian, P ialah fungsi pilih atur, dan G ialah graf
- Penjelasan: Selepas melalui rangkaian, perwakilan dan susunan graf hendaklah sama
- ialah permutasi setara
Persamaan: P(f(G))=f(P(G))P(f(G))=f(P(G)), di mana f ialah rangkaian, P ialah fungsi pilih atur dan G ialah graf
-
Penjelasan: mengubahsuai nod sebelum menghantarnya ke rangkaian hendaklah bersamaan dengan mengubahsuai nodnya perwakilan
Rangkaian neural biasa bukanlah invarian pilih atur, seperti RNN atau CNN, jadi seni bina baharu - rangkaian neural graf - telah diperkenalkan (asalnya sebagai keadaan- mesin berasaskan).
GNN terdiri daripada lapisan berturut-turut. Lapisan GNN mewakili nod sebagai gabungan perwakilan jirannya dan dirinya sendiri daripada lapisan sebelumnya (mesej passing), selalunya dengan pengaktifan ditambah untuk menambah beberapa bukan linear. Berbanding dengan model lain, CNN boleh dianggap sebagai GNN dengan saiz jiran tetap (melalui tetingkap gelongsor) dan pesanan (kesetaraan bukan pilih atur manakala Transformer tanpa pembenaman kedudukan boleh dianggap sebagai GNN pada graf input yang disambungkan sepenuhnya).
Pengagregatan dan pemesejan
Terdapat banyak kaedah untuk mengagregatkan maklumat daripada jiran nod, seperti kaedah penjumlahan, purata dan pengagregatan serupa yang mempunyai telah digunakan sebelum ini Rangkaian, Belajar untuk menimbang jiran yang berbeza berdasarkan kepentingan mereka (seperti Transformer); 🎜>
- Rangkaian Isomorfisme Graf, agregat perwakilan dengan menggunakan MLP pada jumlah perwakilan jiran nod.
- Pilih pengagregatan: Beberapa teknik pengagregatan (terutamanya set purata/maksimum) mengalami kegagalan apabila mencipta perwakilan halus yang membezakan antara perwakilan jiran nod berbeza bagi nod yang serupa Situasi; contohnya, melalui set min, jiran dengan 4 nod diwakili sebagai 1, 1, -1, -1, dengan purata 0, tidak berbeza dengan jiran dengan hanya 3 nod diwakili sebagai -1, 0, 1 .
Isu bentuk GNN dan terlalu licin
Pada setiap lapisan baharu, perwakilan nod merangkumi lebih banyak nod. Nod melepasi tahap pertama, agregasi jiran terdekatnya. Melalui lapisan kedua, ia masih merupakan agregasi jiran terdekatnya, tetapi kini perwakilannya juga termasuk jiran mereka sendiri (dari lapisan pertama). Selepas n peringkat, perwakilan semua nod menjadi set semua jirannya pada jarak n, dan oleh itu agregat graf penuh jika diameternya kurang daripada n.
Jika terdapat terlalu banyak lapisan rangkaian, terdapat risiko setiap nod menjadi agregat graf lengkap (dan perwakilan nod menumpu kepada perwakilan yang sama untuk semua nod), yang dipanggil overshooting Masalah pelicinan, boleh diselesaikan dengan:
- Menskalakan GNN kepada bilangan lapisan yang cukup kecil sehingga setiap nod tidak dianggarkan sebagai keseluruhan rangkaian (mula-mula menganalisis Diameter dan bentuk graf)
- Tingkatkan kerumitan lapisan
- Tambah lapisan bukan pemesejan untuk mengendalikan mesej (cth. MLP mudah)
- Tambah sambungan langkau
Masalah terlalu lancar ialah kawasan penyelidikan penting dalam graf ML kerana ia menghalang GNN daripada meningkat , sama seperti Transformer telah ditunjukkan dalam model lain.
Graph Transformers
Transformer tanpa lapisan pengekodan kedudukan adalah permutasi invarian, dan Transformer juga mempunyai kebolehskalaan yang baik, jadi penyelidikan Orang ramai baru-baru ini mula mempertimbangkan menggunakan Transformer pada graf. Kebanyakan kaedah menumpukan pada mencari ciri terbaik dan cara terbaik untuk mewakili graf, dan mengubah perhatian untuk menyesuaikan diri dengan data baharu ini.
Ditunjukkan di bawah adalah beberapa kaedah yang mencapai keputusan terkini atau menutup pada Penanda Aras Graf Terbuka Stanford:
- Transformer Graf untuk Pembelajaran Graf-ke-Jujukan, memperkenalkan Transformer graf, yang mewakili nod sebagai gabungan benam dan benam kedudukannya Hubungan nod mewakili laluan terpendek antara kedua-duanya, dan menggabungkan kedua-duanya menjadi hubungan—— Tingkatkan diri. -fokus.
- Memikirkan Semula Transformers Graf dengan Perhatian Spektrum, memperkenalkan Rangkaian Perhatian Spektrum (SAN), ini menggabungkan ciri nod dengan pengekodan kedudukan yang dipelajari (dikira daripada vektor/nilai ciri Laplacian) Ke atas, digunakan sebagai kunci dan pertanyaan dalam perhatian, nilai perhatian adalah ciri kelebihan.
- GRPE: Pengekodan Kedudukan Relatif untuk Pengubah Graf, memperkenalkan pengekodan kedudukan relatif graf Transformer, yang menggabungkan pengekodan kedudukan peringkat graf dengan maklumat nod, pengekodan kedudukan peringkat tepi dengan maklumat nod dan gabungkan kedua-duanya dalam perhatian untuk mewakili graf.
- Perhatian Kendiri Global sebagai Pengganti untuk Graph Convolution memperkenalkan Edge Augmented Transformer, seni bina yang membenamkan nod dan tepi secara berasingan dan mengagregatkannya dalam perhatian yang diubah suai.
- Adakah Transformers Berprestasi Teruk untuk Perwakilan Graf, memperkenalkan Graphormer Microsoft, yang mendapat tempat pertama apabila ia keluar di OGB. Seni bina menggunakan ciri nod sebagai pertanyaan/kunci/nilai dalam perhatian dan menggabungkan perwakilannya dengan pemusatan, ruang dan pengekodan tepi dalam mekanisme perhatian.
Penyelidikan terkini "Transformers Tulen ialah Pelajar Graf Berkuasa" memperkenalkan TokenGT dalam kaedah, mewakili graf input sebagai satu siri benam nod dan tepi, iaitu, menggunakan Dipertingkat biasa dengan pengecam nod persimpangan dan pengecam jenis yang boleh dilatih, tanpa benam kedudukan, dan memberi jujukan ini sebagai input kepada Transformers, kaedah ini sangat mudah tetapi sangat berkesan.

Alamat kertas: https://arxiv.org/pdf/2207.02505.pdf
Selain itu, dalam kajian "Resipi untuk Transformer Graf Umum, Berkuasa, Boleh Skala", tidak seperti kaedah lain, ia memperkenalkan bukan model tetapi rangka kerja, dipanggil GraphGPS, yang membolehkan rangkaian penghantaran mesej digabungkan dengan Transformer Linear (jauh) bergabung untuk mencipta rangkaian hibrid dengan mudah. Rangka kerja ini juga mengandungi beberapa alat untuk mengira pengekodan kedudukan dan struktur (nod, graf, aras tepi), penambahan ciri, jalan rawak, dsb.

Alamat kertas: https://arxiv.org/abs/2205.12454
Gunakan Graf Transformer masih berada di peringkat awal, tetapi buat masa ini ia sangat menjanjikan. Mereka boleh mengurangkan beberapa had GNN, seperti menskalakan kepada graf yang lebih besar atau lebih padat, atau tanpa mempertingkatkan saiz model.
Atas ialah kandungan terperinci Pembelajaran mesin graf ada di mana-mana, menggunakan Transformer untuk mengurangkan pengehadan GNN. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI