
Rumah >Peranti teknologi >AI >Perbandingan komprehensif empat model 'Carian ChatGPT'! Dianotasi tangan oleh doktor Cina dari Stanford: New Bing mempunyai kefasihan yang paling rendah, dan hampir separuh daripada ayat tidak dipetik.
Perbandingan komprehensif empat model 'Carian ChatGPT'! Dianotasi tangan oleh doktor Cina dari Stanford: New Bing mempunyai kefasihan yang paling rendah, dan hampir separuh daripada ayat tidak dipetik.

- 王林ke hadapan
- 2023-05-01 23:28:09944semak imbas
Sejurus selepas keluaran ChatGPT, Microsoft berjaya melancarkan "Bing Baharu" bukan sahaja harga sahamnya naik mendadak, malah mengancam untuk menggantikan Google dan memasuki era baharu enjin carian.
Tetapi adakah Bing baharu benar-benar cara yang betul untuk memainkan model bahasa yang besar? Adakah jawapan yang dijana sebenarnya berguna kepada pengguna? Sejauh manakah petikan dalam ayat itu boleh dipercayai?
Baru-baru ini, penyelidik Stanford mengumpul sejumlah besar pertanyaan pengguna daripada sumber yang berbeza dan menganalisis empat enjin carian generatif popular, Bing Chat, NeevaAI, Penilaian manusia dilakukan oleh perplexity.ai dan YouChat .

Pautan kertas: https://arxiv.org/pdf/2304.09848.pdf
Hasil eksperimen mendapati bahawa respons daripada enjin carian generatif sedia ada adalah fasih dan bermaklumat, tetapi selalunya mengandungi kenyataan tanpa bukti dan petikan yang tidak tepat.
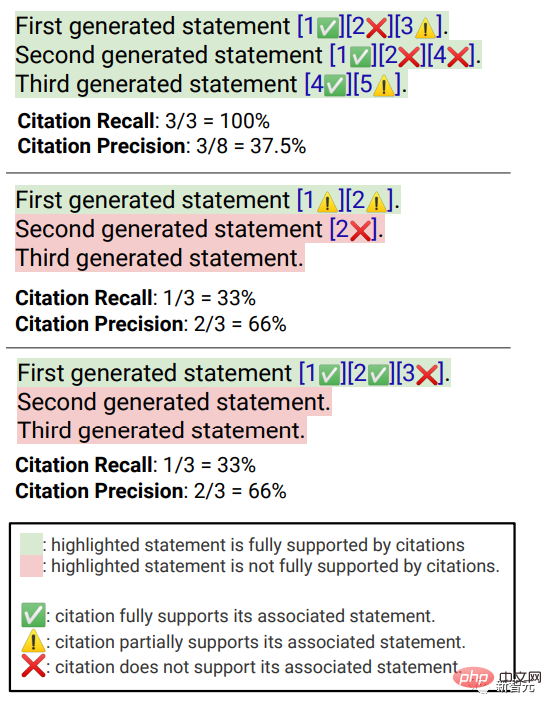
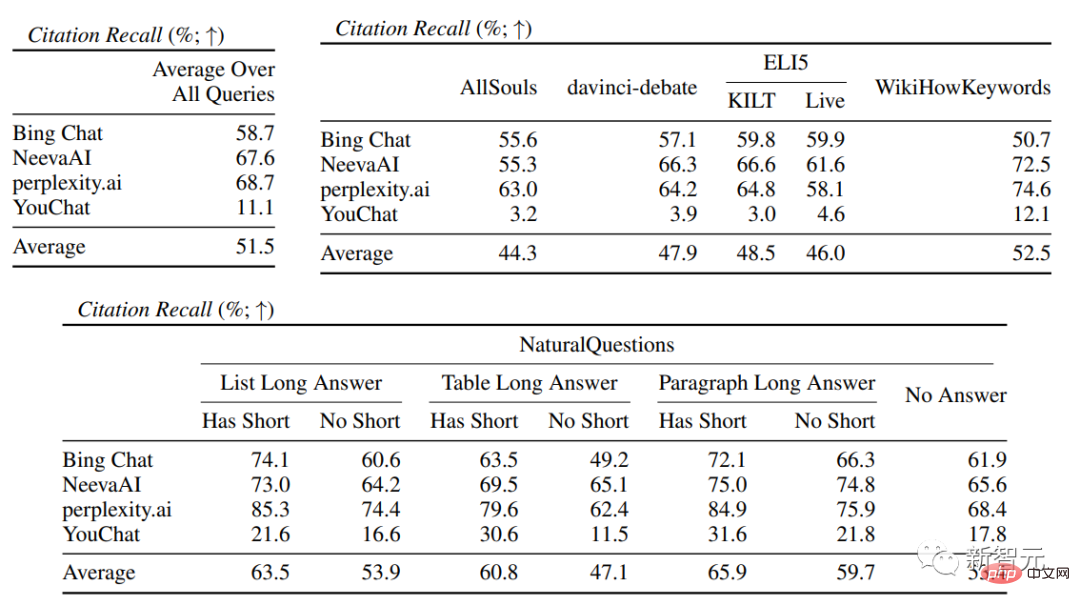
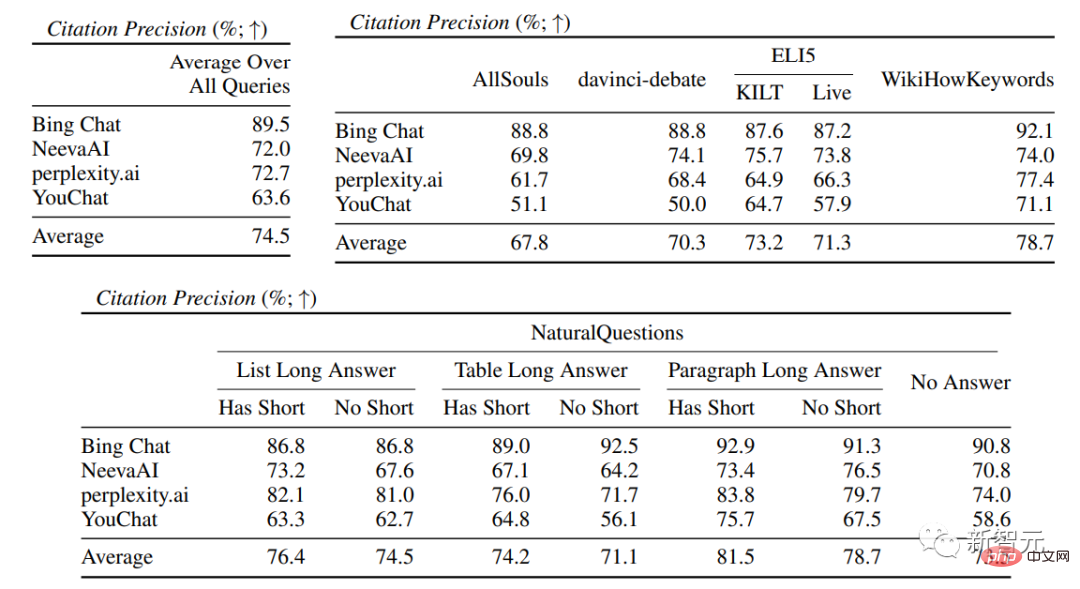
Secara purata, hanya 51.5% daripada petikan boleh menyokong sepenuhnya ayat yang dijana, dan hanya 74.5% daripada petikan boleh digunakan sebagai sokongan bukti untuk ayat yang berkaitan.
Para penyelidik percaya bahawa keputusan ini terlalu rendah untuk sistem yang berkemungkinan menjadi alat utama untuk pengguna yang mencari maklumat, terutamanya memandangkan beberapa ayat masih boleh dipercayai memerlukan pengoptimuman selanjutnya.

Halaman utama peribadi: https://cs.stanford.edu/~nfliu/
Pengarang pertama Nelson Liu ialah pelajar kedoktoran tahun keempat dalam Kumpulan Pemprosesan Bahasa Semulajadi Universiti Stanford Penyelianya ialah Percy Liang Beliau lulus dari Universiti Washington dengan ijazah sarjana muda membina sistem NLP yang praktikal, terutamanya untuk aplikasi carian maklumat.
Jangan percaya enjin carian generatif
Pada Mac 2023, Microsoft melaporkan bahawa "kira-kira satu pertiga daripada pengguna pratonton harian menggunakan [Bing] setiap hari "Sembang" , dan Bing Chat menyediakan 45 juta sembang pada bulan pertama pratonton awamnya Dalam erti kata lain, menyepadukan model bahasa besar ke dalam enjin carian sangat boleh dipasarkan dan berkemungkinan besar mengubah pintu masuk carian ke Internet.

Tetapi pada masa ini, enjin carian generatif sedia ada berdasarkan teknologi model bahasa besar masih mempunyai masalah ketepatan yang rendah, tetapi khususnya ketepatan enjin carian belum lagi dinilai sepenuhnya, dan batasan enjin carian baharu belum lagi difahami sepenuhnya.
Kebolehsahkan adalah kunci untuk meningkatkan kredibiliti enjin carian, iaitu, menyediakan pautan luar kepada petikan untuk setiap ayat dalam jawapan yang dihasilkan Sebagai sokongan bukti, ia boleh memudahkan pengguna untuk mengesahkan ketepatan jawapan.
Para penyelidik menjalankan penilaian manual ke atas empat enjin carian generatif komersil (Bing Chat, NeevaAI, perplexity.ai, YouChat) dengan mengumpulkan soalan daripada jenis dan sumber yang berbeza.
Petunjuk penilaian terutamanya termasuk kelancaran , iaitu Sama ada teks yang dijana adalah koheren; iaitu, yang dihasilkan Perkadaran ayat tentang laman web luaran yang mengandungi sokongan petikan; Kefasihan Juga memaparkan pertanyaan pengguna, balasan yang dijana dan pernyataan "Balasan adalah fasih dan koheren dari segi semantik", Anotasi dinilai data pada skala Likert lima mata. Utiliti yang dirasakan Serupa dengan kelancaran, Anotasi diminta menilai persetujuan mereka dengan kenyataan bahawa respons itu berguna dan bermaklumat kepada pertanyaan pengguna. Panggilan semula petikan Panggilan semula petikan merujuk kepada petikan yang disokong sepenuhnya oleh petikan berkaitannya dan layak menerima The perkadaran ayat yang disahkan, jadi pengiraan penunjuk ini memerlukan mengenal pasti ayat dalam respons yang layak untuk pengesahan, dan menilai sama ada setiap ayat yang layak untuk pengesahan disokong oleh petikan yang berkaitan. Dalam proses "Mengenal pasti Ayat yang Patut Disahkan" , penyelidik mempertimbangkan setiap ayat yang dijana tentang dunia luar. Semuanya berbaloi mengesahkan, walaupun yang mungkin kelihatan jelas dan remeh, kerana apa yang kelihatan seperti "akal sehat" yang jelas kepada sesetengah pembaca mungkin sebenarnya tidak betul. Matlamat sistem enjin carian hendaklah menyediakan sumber rujukan untuk semua ayat yang dijana tentang dunia luar, membolehkan pembaca mengesahkan dengan mudah sebarang naratif dalam respons yang dihasilkan, dan bukan untuk demi kesederhanaan. Jadi sebenarnya, anotasi mengesahkan semua ayat yang dijana, kecuali untuk respons yang sistemnya adalah orang pertama, seperti "Sebagai model bahasa, saya tidak mampu.. . ", atau soalan kepada pengguna, seperti "Adakah anda ingin mengetahui lebih lanjut?" dsb. Menilai "sama ada pernyataan yang layak untuk pengesahan disokong secukupnya oleh petikan yang berkaitan" sumber) rangka kerja penilaian, anotasi melakukan anotasi binari, iaitu jika pendengar biasa bersetuju bahawa "berdasarkan halaman web yang dipetik, ia boleh disimpulkan...", maka petikan itu boleh menyokong sepenuhnya balasan. Ketepatan petikan
Sokongan penuh : Semua maklumat dalam ayat disokong oleh petikan. Sokongan separa : Sesetengah maklumat dalam ayat disokong oleh petikan, tetapi bahagian lain mungkin tiada atau bercanggah. Sokongan yang tidak relevan (Tiada sokongan) : Jika halaman web yang dirujuk adalah tidak relevan atau bercanggah sama sekali. Hasil eksperimen
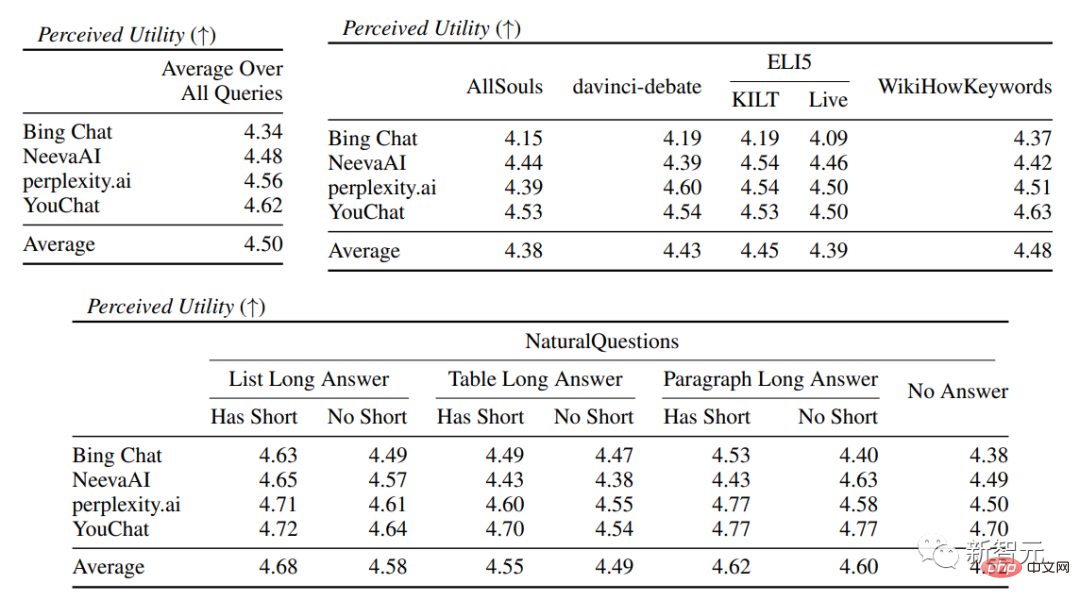
Dalam penilaian enjin carian khusus, anda dapat melihat bahawa Bing Chat mempunyai penilaian kefasihan/kebergunaan terendah (4.40/ 4.34) , diikuti oleh NeevaAI (4.43/4.48), perplexity.ai (4.51/4.56) dan YouChat (4.59/4.62). Dalam kategori pertanyaan pengguna yang berbeza, boleh dilihat bahawa soalan carian yang lebih pendek biasanya lebih fasih daripada soalan yang panjang, dan biasanya hanya menjawab pengetahuan fakta beberapa soalan yang sukar Soalan selalunya memerlukan pengagregatan jadual atau halaman web yang berbeza, dan proses sintesis mengurangkan aliran keseluruhan. Dalam penilaian petikan, dapat dilihat bahawa enjin carian generatif sedia ada sering gagal memetik halaman web sepenuhnya atau betul, dengan purata hanya 51.5% ayat yang dijana disokong sepenuhnya oleh petikan (Ingat semula), hanya 74.5% daripada petikan menyokong sepenuhnya ayat berkaitan mereka (Ketepatan). Nilai ini tidak boleh diterima untuk sistem enjin carian yang sudah mempunyai berjuta-juta pengguna, terutamanya apabila menjana respons selalunya mengandungi sejumlah besar maklumat. dan Terdapat perbezaan besar dalam ingatan semula petikan dan ketepatan antara enjin carian generatif yang berbeza , dengan perplexity.ai mencapai ingatan tertinggi ( 68.7), manakala NeevaAI (67.6 ), Bing Chat (58.7) dan YouChat (11.1) adalah lebih rendah. Sebaliknya, Bing Chat mencapai ketepatan tertinggi (89.5) , diikuti oleh perplexity.ai (72.7), NeevaAI (72.0) dan YouChat ( 63.6 ) Merentas pertanyaan pengguna yang berbeza, jurang ingatan semula petikan antara pertanyaan NaturalQuestions dengan jawapan panjang dan pertanyaan bukan NaturalQuestions adalah hampir 11% (masing-masing 58.5 dan 47.8); Begitu juga, ingatan petikan antara pertanyaan NaturalQuestions dengan jawapan pendek dan pertanyaan NaturalQuestions tanpa jawapan pendek Perbezaannya hampir 10% (63.4 untuk pertanyaan dengan jawapan pendek, 53.6 untuk pertanyaan dengan jawapan yang panjang sahaja, dan 53.4 untuk pertanyaan tanpa jawapan panjang atau pendek). Dalam soalan tanpa sokongan halaman web, kadar petikan akan lebih rendah Contohnya, apabila menilai soalan kertas AllSouls terbuka, enjin carian generatif The recall kadar hanya 44.3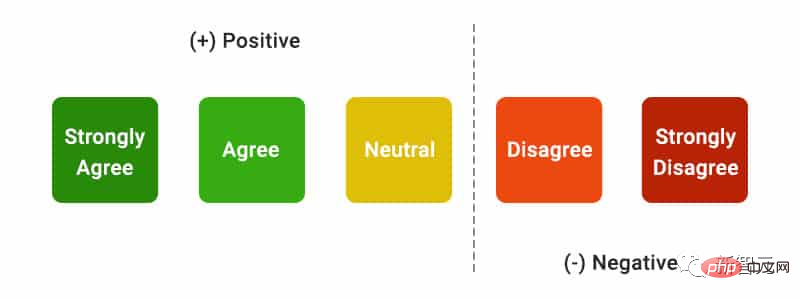
Atas ialah kandungan terperinci Perbandingan komprehensif empat model 'Carian ChatGPT'! Dianotasi tangan oleh doktor Cina dari Stanford: New Bing mempunyai kefasihan yang paling rendah, dan hampir separuh daripada ayat tidak dipetik.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI