
Rumah >Peranti teknologi >AI >Media AS mendedahkan set data latihan model besar: sesetengah kandungan agak 'kotor'
Media AS mendedahkan set data latihan model besar: sesetengah kandungan agak 'kotor'

- PHPzke hadapan
- 2023-05-01 16:07:061310semak imbas

Berita pada 20 April, chatbot kecerdasan buatan telah menjadi semakin popular sejak empat bulan lalu, dan mereka dapat menyelesaikan pelbagai tugas, seperti menulis kertas akademik yang kompleks dan menjalankan penyelidikan Dialog yang sengit dan kebolehan yang menakjubkan.
Chatbots tidak berfikir seperti manusia, malah mereka tidak tahu apa yang mereka bincangkan. Mereka boleh meniru pertuturan manusia kerana kecerdasan buatan yang mendorong mereka telah menyerap sejumlah besar teks, kebanyakannya dikikis daripada internet.
Teks ini ialah sumber maklumat utama AI tentang dunia semasa pembinaannya, dan ia boleh memberi kesan yang mendalam terhadap cara AI bertindak balas. Jika kecerdasan buatan mencapai keputusan cemerlang dalam peperiksaan kehakiman, ini mungkin kerana data latihannya mengandungi beribu-ribu maklumat LSAT (Ujian Kemasukan Sekolah Undang-undang, Ujian Kemasukan Sekolah Undang-undang Amerika).
Syarikat teknologi sentiasa berahsia tentang maklumat yang mereka berikan kepada kecerdasan buatan. Jadi The Washington Post menetapkan untuk menganalisis salah satu set data penting ini, mendedahkan jenis tapak web proprietari, peribadi dan sering menyinggung perasaan yang digunakan untuk melatih AI.
Untuk meneroka susunan dalaman data latihan AI, Washington Post bekerjasama dengan penyelidik dari Allen Institute for Artificial Intelligence untuk menganalisis set data C4 Google. Set data ini ialah petikan besar lebih daripada 15 juta tapak web, yang kandungannya digunakan untuk melatih banyak AI berprofil tinggi berbahasa Inggeris, seperti T5 Google dan LLaMA Facebook. OpenAI tidak mendedahkan jenis set data yang mereka gunakan untuk melatih model yang menyokong chatbot ChatGPT.
Dalam tinjauan ini, penyelidik menggunakan data daripada syarikat analitik web Similarweb untuk mengklasifikasikan tapak web. Kira-kira satu pertiga daripada tapak ini tidak boleh diklasifikasikan dan dikecualikan, terutamanya kerana ia tidak lagi wujud di Internet. Para penyelidik kemudian meletakkan baki 10 juta tapak web berdasarkan bilangan "token" yang muncul pada setiap tapak web dalam set data. Token ialah sekeping kecil maklumat pemprosesan teks, biasanya perkataan atau frasa, digunakan untuk melatih model AI.
Dari Wikipedia ke WoWhead
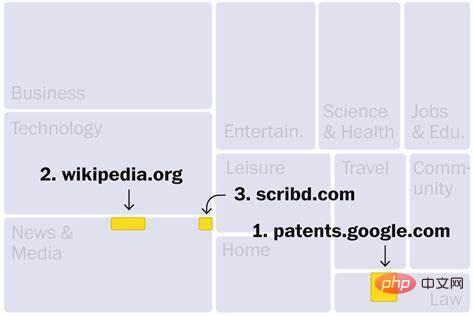
Tapak web dalam set data C4 terutamanya daripada industri seperti berita, hiburan, pembangunan perisian, perubatan dan penciptaan kandungan. Ini boleh menjelaskan mengapa medan ini mungkin diancam oleh gelombang baru kecerdasan buatan. Tiga tapak web teratas ialah: yang pertama ialah Carian Paten Google, yang mengandungi teks paten yang diterbitkan di seluruh dunia dan yang ketiga ialah Scribd, perpustakaan digital yang hanya menerima langganan berbayar; Selain itu, tapak web berpangkat tinggi lain termasuk Perpustakaan pasaran e-buku cetak rompak (No. 190), yang telah ditutup oleh Jabatan Kehakiman A.S. kerana aktiviti haram. Selain itu, terdapat sekurang-kurangnya 27 laman web dalam set data yang telah dikenal pasti oleh kerajaan AS sebagai pasaran produk cetak rompak dan tiruan.
Terdapat juga beberapa tapak teratas yang ditampilkan, seperti wowhead (No. 181), forum untuk pemain World of Warcraft dan tapak web yang diasaskan oleh Arianna Huffington untuk membantu memerangi keletihan Tapak Web ThriveGlobal (No. 175). . Selain itu, terdapat sekurang-kurangnya 10 tapak web yang menjual tempat pembuangan sampah, termasuk dumpsteroid (No. 183), tetapi nampaknya tidak lagi boleh diakses.
Walaupun kebanyakan tapak web selamat, sesetengah tapak web mempunyai isu privasi yang serius. Sebagai contoh, dua tapak web disenaraikan dalam senarai 100 teratas salinan pangkalan data pendaftaran pemilih negeri yang dihoskan secara persendirian. Walaupun data pengundi adalah umum, model ini mungkin menggunakan maklumat peribadi ini dengan cara yang tidak diketahui.
Tapak web industri dan komersil menduduki kategori terbesar (mengandungi 16% daripada token kategori). Di bahagian atas senarai ialah The Motley Fool (No. 13), yang memberikan nasihat pelaburan. Seterusnya ialah Kickstarter (No. 25), sebuah laman web yang membolehkan pengguna mengumpulkan projek kreatif. Patreon, yang mempunyai kedudukan lebih rendah di No. 2,398, membantu pencipta mengutip yuran bulanan daripada pelanggan untuk kandungan eksklusif.
Walau bagaimanapun, Kickstarter dan Patreon mungkin membenarkan AI mengakses idea artis dan salinan pemasaran, menimbulkan kebimbangan bahawa AI mungkin menyalin karya ini apabila memberikan cadangan kepada pengguna. Artis, yang pada masa ini tidak menerima sebarang pampasan apabila kerja mereka disertakan dalam data latihan AI, telah memfailkan tuntutan pelanggaran terhadap penjana teks-ke-imej Stable Diffusion, MidJourney dan DeviantArt.
Menurut analisis Washington Post ini, lebih banyak cabaran undang-undang mungkin akan datang: Terdapat lebih daripada 200 juta kejadian simbol hak cipta (menunjukkan karya yang didaftarkan sebagai harta intelek) dalam set data C4.
Tapak web teknikal ialah kategori kedua terbesar, menyumbang 15% daripada token kategori. Ini termasuk banyak platform yang membantu orang ramai membina tapak web, seperti Google Sites (No. 85), yang mempunyai halaman yang merangkumi segala-galanya daripada kelab judo di Reading, England, hingga ke tadika di New Jersey.
Set data C4 juga mengandungi lebih daripada 500,000 blog peribadi, menyumbang 3.8% daripada kandungan terperingkat. Platform penerbitan Medium menduduki tempat ke-46 dan merupakan tapak web teknologi kelima terbesar, dengan puluhan ribu blog di bawah nama domainnya. Selain itu, terdapat blog yang ditulis pada platform seperti WordPress, Tumblr, Blogpot, dan Live Journal.
Blog ini terdiri daripada profesional kepada peribadi, seperti blog yang dipanggil "Grumpy Rumblings" yang dikarang bersama oleh dua ahli akademik tanpa nama, yang salah seorang daripada mereka baru-baru ini menulis tentang cara pasangan mereka kehilangan pekerjaannya Bagaimana ia mempengaruhi cukai pasangan . Selain itu, terdapat beberapa blog popular yang memfokuskan pada permainan main peranan secara langsung dalam set data C4.
Kandungan rangkaian sosial seperti Facebook dan Twitter (yang dianggap teras web moden) disekat daripada merangkak, yang bermaksud kebanyakan set data yang digunakan untuk melatih kecerdasan buatan tidak dapat mengaksesnya. Gergasi teknologi seperti Facebook dan Google menggunakan sejumlah besar data perbualan, tetapi mereka belum tahu cara menggunakan maklumat pengguna peribadi untuk melatih model kecerdasan buatan untuk kegunaan dalaman atau untuk dijual sebagai produk.
Tapak berita dan media telah menduduki tempat ketiga merentas semua kategori, dan separuh daripada sepuluh tapak teratas ialah saluran berita: The New York Times menduduki tempat keempat, Los Angeles Times menduduki tempat keenam, dan laman web Guardian Newspaper menduduki tempat ketujuh, Laman web Forbes menduduki tempat kelapan, laman web Huffington Post menduduki tempat kesembilan, dan laman web Washington Post menduduki tempat ke-11. Seperti artis dan pencipta, beberapa organisasi berita telah mengkritik syarikat teknologi kerana menggunakan kandungan mereka tanpa kebenaran atau pampasan.
Pada masa yang sama, "Washington Post" juga mendapati bahawa beberapa media berada pada kedudukan rendah dalam penarafan kredibiliti bebas NewsGuard: seperti RT Rusia (65), laman web berita paling kanan breitbart (No. 159) dan laman web anti-imigresen vdare (No. 993) dengan kaitan dengan ketuanan kulit putih.
Chatbots telah terbukti berkongsi maklumat yang salah. Data latihan yang tidak boleh dipercayai boleh menyebabkan mereka menyebarkan berat sebelah dan mempromosikan maklumat salah tanpa pengguna dapat mengesannya ke sumber asal mereka.
Tapak web komuniti menyumbang kira-kira 5% daripada kandungan terperingkat, terutamanya laman web keagamaan.
Ikan apa yang tiada dalam penapis?
Seperti kebanyakan syarikat, Google menapis dan menyaring data sebelum menyalurkannya kepada AI. Selain mengalih keluar teks yang tidak bermakna dan berulang, syarikat itu juga menggunakan "senarai perkataan buruk" sumber terbuka yang merangkumi 402 istilah bahasa Inggeris dan emoji. Syarikat sering menggunakan set data berkualiti tinggi untuk memperhalusi model untuk menyekat kandungan yang tidak mahu dilihat oleh pengguna.
Walaupun senarai sedemikian bertujuan untuk mengehadkan model daripada terdedah kepada penghinaan kaum dan kandungan yang tidak sesuai semasa dilatih, banyak perkara membuatnya melepasi penapis. The Washington Post menemui ratusan laman web lucah dan lebih daripada 72,000 contoh "Nazi" dalam senarai perkataan yang dilarang.
Sementara itu, The Washington Post mendapati bahawa penapis gagal mengalih keluar beberapa kandungan yang mengganggu, termasuk tapak ketuanan putih, tapak anti-trans dan tapak yang terkenal kerana menganjurkan kempen gangguan terhadap individu Papan mesej tanpa nama 4chan. Kajian itu juga mendedahkan laman web yang mempromosikan teori konspirasi.
Adakah tapak web anda digunakan untuk melatih AI?
Mengikis web mungkin kedengaran seperti menyalin keseluruhan Internet, tetapi ia sebenarnya hanya mengumpulkan syot kilat, contoh halaman web pada masa tertentu. Dataset C4 pada asalnya dicipta oleh organisasi bukan untung CommonCrawl untuk merangkak kandungan web pada April 2019 dan merupakan sumber popular untuk latihan model kecerdasan buatan. CommonCrawl berkata organisasi itu cuba mengutamakan laman web yang paling penting dan bereputasi tetapi tidak cuba mengelak kandungan berlesen atau dilindungi hak cipta.
The Washington Post percaya bahawa adalah penting untuk membentangkan kandungan data yang lengkap dalam model kecerdasan buatan yang berpotensi untuk mengurus banyak aspek kehidupan moden manusia. Walau bagaimanapun, banyak tapak web dalam set data ini mengandungi bahasa yang sangat menyinggung perasaan, dan walaupun model dilatih untuk menutup perkataan ini, kandungan yang tidak menyenangkan mungkin masih ada.
Pakar mengatakan bahawa walaupun set data C4 adalah besar, model bahasa yang besar mungkin menggunakan set data yang lebih besar. Sebagai contoh, OpenAI mengeluarkan data latihan GPT-3 pada tahun 2020, yang mempunyai 40 kali ganda jumlah data yang dikikis web dalam C4. Data latihan GPT-3 termasuk semua Wikipedia Bahasa Inggeris, koleksi novel percuma oleh pengarang yang tidak diterbitkan yang kerap digunakan oleh syarikat teknologi besar, dan kompilasi teks terpaut yang dinilai tinggi oleh pengguna Reddit.
Pakar mengatakan banyak syarikat tidak merekodkan kandungan data latihan mereka (walaupun secara dalaman) kerana takut mengetahui maklumat yang boleh dikenal pasti secara peribadi, bahan berhak cipta dan data lain yang telah dicuri tanpa kebenaran. Memandangkan syarikat menyerlahkan cabaran untuk menerangkan cara chatbots membuat keputusan, ini adalah kawasan di mana eksekutif perlu memberikan jawapan yang telus.
Atas ialah kandungan terperinci Media AS mendedahkan set data latihan model besar: sesetengah kandungan agak 'kotor'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI