
Rumah >Peranti teknologi >AI >Gambar + audio bertukar menjadi video dalam beberapa saat! SadTalker sumber terbuka Universiti Xi'an Jiaotong: Pergerakan kepala dan bibir supernatural, dwibahasa dalam bahasa Cina dan Inggeris, dan juga boleh menyanyi
Gambar + audio bertukar menjadi video dalam beberapa saat! SadTalker sumber terbuka Universiti Xi'an Jiaotong: Pergerakan kepala dan bibir supernatural, dwibahasa dalam bahasa Cina dan Inggeris, dan juga boleh menyanyi

- 王林ke hadapan
- 2023-05-01 15:16:062036semak imbas
Dengan populariti konsep orang digital dan perkembangan teknologi generasi yang berterusan, tidak lagi menjadi masalah untuk menjadikan watak dalam gambar bergerak mengikut input audio.
Walau bagaimanapun, masih terdapat banyak masalah dalam "menjana video avatar bercakap melalui imej muka dan sekeping audio suara", seperti pergerakan kepala yang tidak wajar dan ekspresi muka yang herot , wajah orang dalam video dan gambar terlalu berbeza dan isu lain.
Baru-baru ini, penyelidik dari Universiti Xi'an Jiaotong dan yang lain mencadangkan model SadTalker, yang belajar dalam medan gerakan tiga dimensi untuk menjana pekali gerakan 3D 3DMM daripada audio (pose kepala, ekspresi) dan menggunakan pemapar muka 3D baharu untuk menjana pergerakan kepala.

Pautan kertas: https://arxiv.org/pdf/2211.12194.pdf
Laman utama projek: https://sadtalker.github.io/
Audio boleh dalam Bahasa Inggeris , Cina, lagu dan watak dalam video juga boleh mengawal kadar sekelip mata!
Untuk mempelajari pekali gerakan yang realistik, para penyelidik secara eksplisit memodelkan perkaitan antara audio dan jenis pekali gerakan yang berbeza secara berasingan: melalui pekali suling dan muka yang dipaparkan 3D , pelajari ekspresi muka yang tepat daripada audio; reka PoseVAE melalui VAE bersyarat untuk mensintesis gaya pergerakan kepala yang berbeza.
Akhir sekali, pekali gerakan tiga dimensi yang dijana dipetakan ke ruang titik kunci tiga dimensi yang tidak diselia bagi pemaparan muka, dan video akhir disintesis.
Akhir sekali, ditunjukkan dalam eksperimen bahawa kaedah ini mencapai prestasi terkini dari segi penyegerakan gerakan dan kualiti video.
Pemalam untuk stable-diffusion-webui juga telah dikeluarkan!
Foto + audio = video
Penciptaan manusia digital, persidangan video dan banyak bidang lain memerlukan teknologi "menggunakan audio suara untuk menghidupkan foto pegun", tetapi pada masa ini Ini tetap menjadi tugas yang sangat mencabar.
Karya sebelum ini tertumpu terutamanya kepada penjanaan "gerakan bibir" kerana hubungan antara pergerakan bibir dan pertuturan adalah yang paling kuat Kerja lain juga cuba menjana pergerakan lain yang berkaitan (seperti pergerakan kepala). . (pose separa), tetapi kualiti video yang dihasilkan masih sangat luar biasa dan terhad oleh pose pilihan, kabur, pengubahsuaian identiti dan herotan muka.
Kaedah popular lain ialah animasi muka berasaskan terpendam, yang terutamanya memfokuskan pada kategori gerakan tertentu dalam animasi muka perbualan Ia juga sukar untuk mensintesis video berkualiti tinggi kerana Walaupun muka 3D model mengandungi perwakilan yang sangat dipisahkan yang boleh digunakan untuk mempelajari trajektori gerakan kedudukan berbeza pada muka secara bebas, ekspresi tidak tepat dan jujukan gerakan tidak semulajadi masih akan dihasilkan.
Berdasarkan pemerhatian di atas, penyelidik mencadangkan SadTalker (Stylized Audio-Driven Talking-head), sistem penjanaan video dipacu audio yang digayakan melalui modulasi pekali tiga dimensi tersirat.
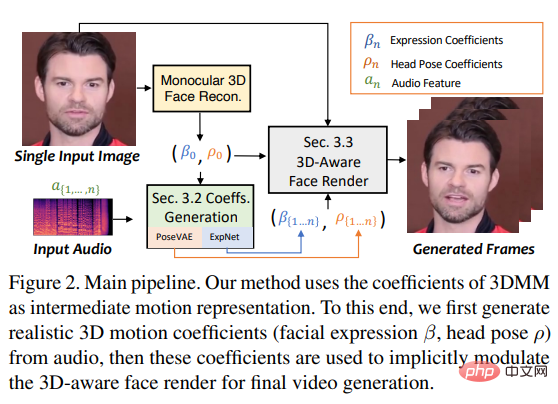
Untuk mencapai matlamat ini, penyelidik menganggap pekali gerakan 3DMM sebagai perwakilan perantaraan dan membahagikan tugas kepada Kedua-dua bahagian utama (ungkapan dan pose) bertujuan untuk menjana pekali gerakan yang lebih realistik (seperti pose kepala, pergerakan bibir dan kerdipan mata) daripada audio, dan mempelajari setiap gerakan secara individu untuk mengurangkan ketidakpastian.
Akhirnya memacu imej sumber melalui pemaparan wajah sedar 3D yang diilhamkan oleh face-vid2vid.
Muka 3D
Oleh kerana video kehidupan sebenar dirakam dalam persekitaran tiga dimensi, maklumat tiga dimensi adalah penting untuk meningkatkan keaslian video yang dijana walau bagaimanapun, kerja sebelum ini jarang dianggap sebagai ruang tiga dimensi kerana hanya satu satah digunakan . Sukar untuk mendapatkan imej jarang tiga dimensi yang asli, dan pemapar muka berkualiti tinggi sukar direka bentuk.
Diinspirasikan oleh kaedah pembinaan semula 3D kedalaman imej tunggal terkini, penyelidik menggunakan ruang model ubah bentuk tiga dimensi (3DMM) yang diramalkan sebagai perwakilan perantaraan.
Dalam 3DMM, bentuk muka tiga dimensi S boleh dipisahkan sebagai:
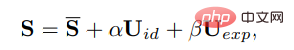
di mana S ialah bentuk purata muka manusia tiga dimensi, Uid dan Uexp ialah penyelarasan identiti dan ekspresi model boleh berubah LSFM Koefisien α (80 dimensi) dan β (64 dimensi) menerangkan identiti dan ekspresi watak. masing-masing; untuk mengekalkan perbezaan postur, pekali r dan t masing-masing mewakili pusingan kepala dan terjemahan untuk mencapai penjanaan pekali bebas identiti, hanya parameter gerakan dimodelkan sebagai {β, r, t}.
Iaitu, pose kepala ρ = [r, t] dan pekali ekspresi β dipelajari secara berasingan daripada audio yang dipacu, dan kemudian menggunakan pekali gerakan ini dimodulasi secara tersirat untuk pemaparan muka Akhir sintesis video.
Gerakan jarang melalui audio
Pekali gerakan tiga dimensi mengandungi pose dan ekspresi kepala, di mana kepala pose ialah gerakan Global, manakala ekspresi agak setempat, jadi mempelajari sepenuhnya semua pekali akan membawa ketidakpastian yang besar kepada rangkaian, kerana hubungan antara postur kepala dan audio agak lemah, manakala pergerakan bibir sangat berkorelasi dengan audio .
Jadi SadTalker menggunakan PoseVAE dan ExpNet berikut untuk menjana pergerakan postur dan ekspresi kepala masing-masing.
ExpNet
Sangat berguna untuk mempelajari model umum yang boleh "menjana pekali ekspresi yang tepat daripada audio" Sukar, atas dua sebab:
1) Audio-ke-ungkapan bukan tugas pemetaan satu-satu untuk aksara yang berbeza; >2) Terdapat beberapa tindakan berkaitan audio dalam pekali ungkapan, yang akan menjejaskan ketepatan ramalan.
Matlamat reka bentuk ExpNet adalah untuk mengurangkan ketidakpastian ini bagi masalah identiti watak, penyelidik menggerakkan ekspresi melalui pekali ekspresi bingkai pertama yang dikaitkan dengan orang tertentu. 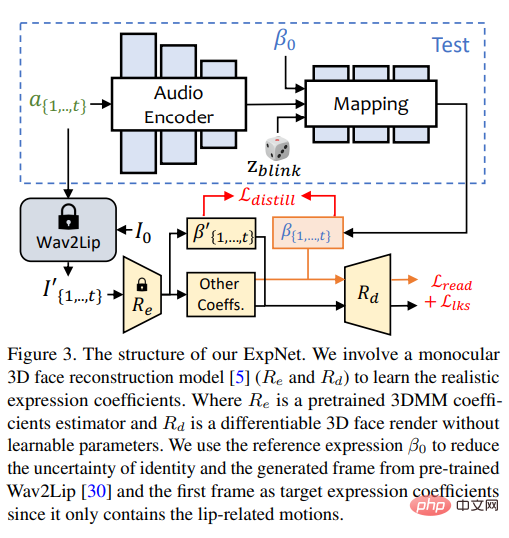
Untuk mengurangkan berat pergerakan komponen muka lain dalam perbualan semula jadi, hanya pekali gerakan bibir (gerakan bibir sahaja) digunakan sebagai sasaran pekali melalui rangkaian terlatih Wav2Lip dan pembinaan semula 3D yang mendalam.
Bagi pergerakan muka halus lain (seperti mata berkedip), dsb., ia boleh diperkenalkan dalam kehilangan tanda tanda tambahan pada imej yang diberikan.
PoseVAE
Penyelidik mereka bentuk model berasaskan VAE untuk mempelajari imej sebenar berkaitan identiti dalam video perbualan ( sedar identiti) pergerakan kepala yang digayakan.
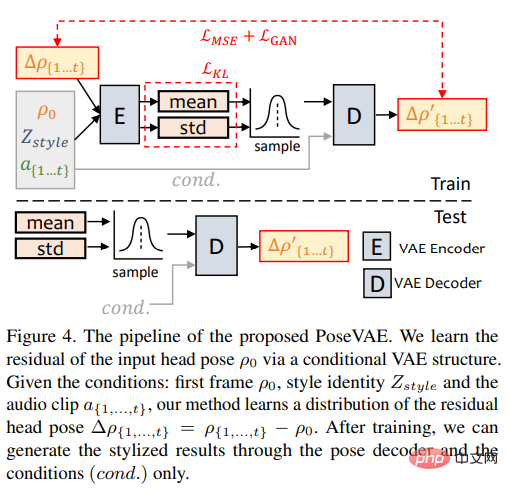 Dalam latihan, pose VAE dilatih pada n bingkai tetap menggunakan struktur berasaskan penyahkod-pengekod , di mana pengekod dan penyahkod ialah kedua-dua MLP dua lapisan, dan input mengandungi pose kepala bingkai-t berterusan, yang dibenamkan ke dalam pengedaran Gaussian dalam penyahkod, rangkaian belajar untuk menjana pose bingkai-t daripada pengedaran pensampelan.
Dalam latihan, pose VAE dilatih pada n bingkai tetap menggunakan struktur berasaskan penyahkod-pengekod , di mana pengekod dan penyahkod ialah kedua-dua MLP dua lapisan, dan input mengandungi pose kepala bingkai-t berterusan, yang dibenamkan ke dalam pengedaran Gaussian dalam penyahkod, rangkaian belajar untuk menjana pose bingkai-t daripada pengedaran pensampelan.
Perlu diambil perhatian bahawa PoseVAE tidak menjana pose secara langsung, tetapi mempelajari baki pose bersyarat bagi bingkai pertama Ini juga membolehkan kaedah menjana keadaan yang lebih lama di bawah keadaan bingkai pertama dalam ujian, pergerakan kepala yang lebih stabil dan berterusan.
Menurut CVAE, ciri audio dan pengecam gaya yang sepadan juga ditambahkan pada PoseVAE sebagai syarat untuk kesedaran irama dan gaya identiti.
Model menggunakan perbezaan KL untuk mengukur taburan gerakan yang dijana; ia menggunakan kerugian kuasa dua purata dan kerugian adversarial untuk memastikan kualiti penjanaan.
Pemarahan muka sedar 3D
Selepas menjana pekali gerakan tiga dimensi yang realistik, para penyelidik meluluskan reka bentuk yang terperinci Animator imej 3D untuk memaparkan video akhir.
Kaedah animasi imej yang dicadangkan baru-baru ini face-vid2vid secara tersirat boleh mempelajari maklumat 3D daripada satu imej, tetapi kaedah ini memerlukan video sebenar sebagai isyarat memandu tindakan dan kertas ini The face rendering yang dicadangkan dalam boleh didorong oleh pekali 3DMM.
Penyelidik mencadangkan mappingNet untuk mempelajari hubungan antara pekali gerakan 3DMM yang jelas (pose dan ekspresi kepala) dan titik kunci 3D tanpa pengawasan yang tersirat.
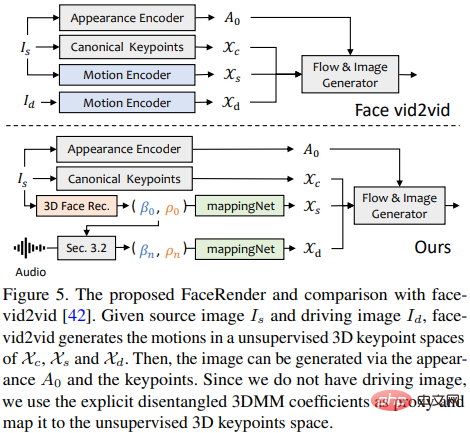
mappingNet dibina melalui beberapa lapisan konvolusi satu dimensi, dan menggunakan pekali masa tetingkap masa untuk melicinkan seperti PIRenderer; kajian Para penyelidik mendapati bahawa pekali gerakan sejajar muka dalam PIRenderer akan banyak mempengaruhi keaslian gerakan dalam penjanaan video dipacu audio, jadi mappingNet hanya menggunakan pekali untuk ekspresi dan pose kepala.
Fasa latihan terdiri daripada dua langkah: mula-mula ikut kertas asal dan latih face-vid2vid dengan cara yang diawasi sendiri kemudian bekukan pengekod penampilan, penganggar titik kunci kanonik dan penjana imej Selepas semua parameter, mappingNet dilatih pada pekali 3DMM video kebenaran tanah dalam cara yang dibina semula untuk penalaan halus.
Menggunakan kehilangan L1 untuk latihan yang diselia dalam domain titik kunci yang tidak diselia dan memberikan video hasil akhir seperti pelaksanaan asalnya.
Hasil eksperimen
Untuk membuktikan keunggulan kaedah ini, penyelidik memilih penunjuk Jarak Permulaan Frechet (FID) dan Pengesanan Kabur Kebarangkalian Terkumpul (CPBD) untuk menilai imej Kualiti, di mana FID menilai terutamanya ketulenan bingkai yang dijana, dan CPBD menilai kejelasan bingkai yang dijana.
Untuk menilai tahap pemeliharaan identiti, ArcFace digunakan untuk mengekstrak pembenaman identiti imej, dan kemudian kesamaan kosinus (CSIM) pembenaman identiti antara imej sumber dan bingkai yang dihasilkan dikira.
Untuk menilai penyegerakan bibir dan bentuk bibir, penyelidik menilai perbezaan persepsi bentuk bibir daripada Wav2Lip, termasuk skor jarak (LSE-D) dan skor keyakinan (LSE-C) .
Dalam penilaian gerakan kepala, kepelbagaian gerakan kepala yang dijana dikira menggunakan sisihan piawai pembenaman ciri gerakan kepala yang diekstrak oleh Hopenet daripada bingkai yang dijanakan Beat Align dikira untuk menilai ketekalan audio dan pergerakan kepala yang dijana.
Dalam kaedah perbandingan, beberapa kaedah penjanaan avatar bercakap yang paling maju telah dipilih, termasuk MakeItTalk, Audio2Head dan kaedah penjanaan audio-ke-ungkapan (Wav2Lip, PC-AVS), menggunakan berat Pusat Pemeriksaan awam dinilai.
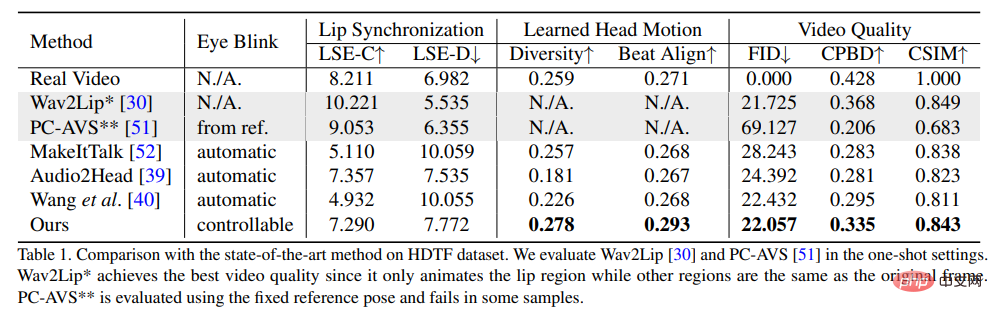
Dapat dilihat daripada keputusan eksperimen bahawa kaedah yang dicadangkan dalam artikel boleh menunjukkan kualiti video dan pengepala keseluruhan yang lebih baik kepelbagaian pose kepala, sambil juga menunjukkan prestasi yang setanding dengan kaedah penjanaan kepala lain yang bercakap sepenuhnya dari segi metrik penyegerakan bibir.
Para penyelidik percaya bahawa metrik penyegerakan bibir ini terlalu sensitif kepada audio, jadi pergerakan bibir yang tidak semulajadi mungkin mendapat skor yang lebih baik, tetapi kaedah yang dicadangkan dalam artikel itu mencapai skor yang serupa dengan video sebenar juga menunjukkan kelebihan kaedah ini.

Seperti yang dapat dilihat dalam hasil visual yang dihasilkan oleh kaedah yang berbeza, kualiti visual kaedah ini sangat serupa dengan video sasaran asal, dan berbeza daripada yang dijangkakan Postur juga sangat serupa.
Berbanding dengan kaedah lain, Wav2Lip menjana separuh muka kabur dan Audio2Head mengalami kesukaran untuk mengekalkan identiti imej sumber Audio2Head sahaja; menjana video muka yang herot disebabkan herotan 2D.
Atas ialah kandungan terperinci Gambar + audio bertukar menjadi video dalam beberapa saat! SadTalker sumber terbuka Universiti Xi'an Jiaotong: Pergerakan kepala dan bibir supernatural, dwibahasa dalam bahasa Cina dan Inggeris, dan juga boleh menyanyi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI