
Rumah >Peranti teknologi >AI >Rahsia AI berpusatkan data dalam model GPT
Rahsia AI berpusatkan data dalam model GPT

- 王林ke hadapan
- 2023-04-30 17:58:071626semak imbas
Penterjemah | Imej datang dari artikel https://www.php.cn/link/f74412c3c1c8899f3c130bb30ed0e363, dihasilkan oleh penulis sendiri
Kecerdasan buatan membuat kemajuan yang luar biasa dalam mengubah cara kita hidup, bekerja dan berinteraksi dengan teknologi. Baru-baru ini, bidang yang telah mencapai kemajuan yang ketara ialah pembangunan model bahasa besar (LLM), seperti 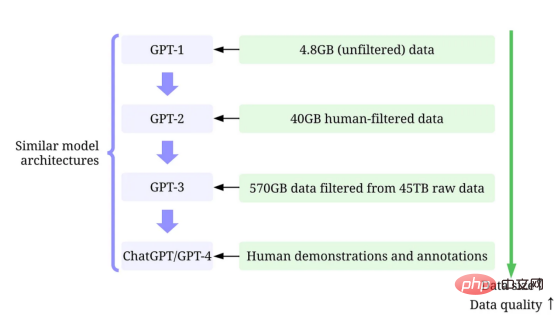
GPT-3,
ChatGPT dan GPT-4. Model ini mampu melaksanakan tugas seperti terjemahan bahasa, ringkasan teks dan menjawab soalan dengan ketepatan yang mengagumkan. Walaupun sukar untuk mengabaikan saiz model model bahasa besar yang semakin meningkat, adalah sama penting untuk menyedari bahawa kejayaan mereka sebahagian besarnya disebabkan oleh bilangan data berkualiti tinggi yang besar digunakan untuk melatih mereka data. Dalam artikel ini, kami akan memberikan gambaran keseluruhan kemajuan terkini dalam model bahasa besar daripada perspektif kecerdasan buatan berpusatkan data, merujuk kepada kertas tinjauan terbaru kami (tamat Pandangan dalam dokumen 1 dan 2) dan sumber teknikal pada GitHub
. Khususnya, kami akan melihat dengan lebih dekat model GPT melalui lensa kecerdasan buatan berpusatkan data, yang merupakan trend yang semakin berkembang dalam komuniti sains data A sudut pandangan. Kami akan mendedahkan kecerdasan buatan berpusatkan data di sebalik model GPT dengan membincangkan tiga matlamat kecerdasan buatan berpusatkan data - melatih pembangunan data, pembangunan data inferens dan konsep penyelenggaraan data.
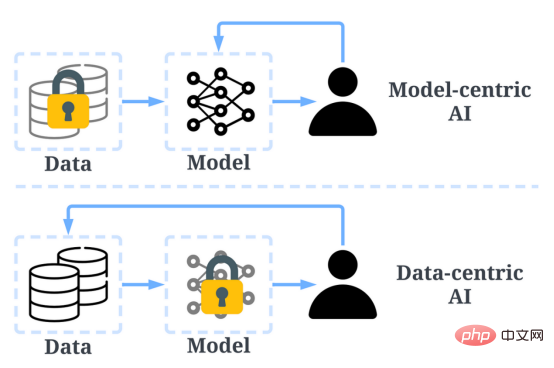
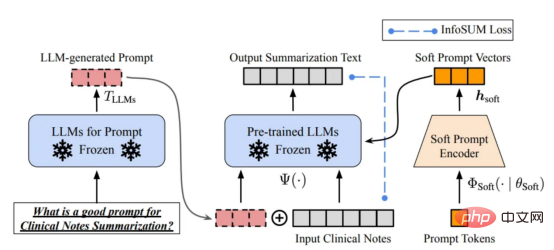
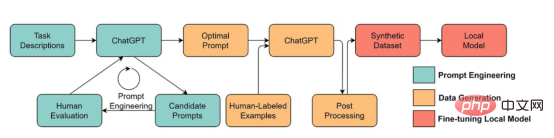
Model Bahasa Skala Besar lwn Model GPTLLM (Model Bahasa Skala Besar) ialah model pemprosesan bahasa semula jadi yang dilatih untuk membuat kesimpulan perkataan dalam konteks. Sebagai contoh, fungsi paling asas LLM adalah untuk meramalkan token yang hilang berdasarkan konteks. Untuk melakukan ini, LLM dilatih untuk meramalkan kebarangkalian setiap token calon daripada jumlah data yang besar. Contoh ilustrasi meramalkan kebarangkalian kehilangan token menggunakan model bahasa yang besar dengan konteks (oleh pengarang) Gambar ) Model GPT merujuk kepada satu siri model bahasa berskala besar yang dicipta oleh OpenAI, seperti GPT-1, GPT-2, GPT-3, ArahanGPT dan ChatGPT/GPT-4 . Seperti model bahasa berskala besar yang lain, seni bina model GPT banyak berdasarkan Transformers, yang menggunakan teks dan benam kedudukan sebagai input dan menggunakan lapisan perhatian untuk memodelkan hubungan antara token. Rajah seni bina model GPT-1, imej ini datang daripada kertas https://www.php.cn/link/c3bfbc2fc89bd1dd71ad5fc5ac96ae69 Model GPT kemudiannya menggunakan seni bina yang serupa dengan GPT-1, tetapi menggunakan lebih banyak parameter model, dengan lebih banyak lapisan, panjang konteks yang lebih besar, Saiz lapisan tersembunyi, dsb. Perbandingan pelbagai saiz model model GPT (gambar disediakan oleh pengarang) Kecerdasan buatan tertumpu kepada data ialah cara baharu pemikiran baharu tentang cara membina sistem kecerdasan buatan. Perintis kecerdasan buatan Andrew Ng telah memperjuangkan idea ini. Kecerdasan buatan berpusatkan data ialah disiplin kejuruteraan sistematik data yang digunakan untuk membina sistem kecerdasan buatan. - Andrew Ng Pada masa lalu, kami memberi tumpuan terutamanya pada mencipta model yang lebih baik (kecerdasan buatan berpusatkan model) apabila data pada asasnya tidak berubah. Walau bagaimanapun, pendekatan ini boleh menyebabkan masalah di dunia nyata kerana ia tidak mengambil kira isu berbeza yang boleh timbul dalam data, seperti label yang tidak tepat, pertindihan dan berat sebelah. Oleh itu, "overfitting" set data mungkin tidak semestinya membawa kepada tingkah laku model yang lebih baik. Sebaliknya, AI berpusatkan data memfokuskan pada meningkatkan kualiti dan kuantiti data yang digunakan untuk membina sistem AI. Ini bermakna perhatian akan tertumpu pada data itu sendiri, manakala modelnya agak tetap. Pendekatan berpusatkan data untuk membangunkan sistem AI mempunyai potensi yang lebih besar di dunia nyata kerana data yang digunakan untuk latihan akhirnya menentukan keupayaan maksimum model. Perlu diperhatikan bahawa "berpusatkan data" pada asasnya berbeza daripada "didorong data", kerana yang terakhir hanya menekankan penggunaan data untuk membimbing pembangunan kecerdasan buatan, manakala pembangunan AI selalunya masih tertumpu pada pembangunan model dan bukannya data kejuruteraan. Perbandingan kecerdasan buatan berpusatkan data dan AI berpusatkan model (imej daripada https://www.php .cn/link/f9afa97535cf7c8789a1c50a2cd83787Penulis kertas) Secara keseluruhannya, rangka kerja kecerdasan buatan berpusat data terdiri daripada tiga matlamat: Rangka kerja kecerdasan buatan berpusat data (imej daripada kertas https://www.php.cn/link/ f74412c3c1c8899f3c130bb630ed Pengarang) Beberapa bulan lalu, Yann LeCun, seorang pemimpin dalam industri kecerdasan buatan, menyatakan di Twitternya bahawa ChatGPT bukanlah perkara baharu. Malah, semua teknik yang digunakan dalam ChatGPT dan GPT-4 (Tpembelajaran pengubah dan pengukuhan daripada maklum balas manusia, dsb.) bukanlah teknologi baharu. Walau bagaimanapun, mereka telah mencapai hasil yang luar biasa yang tidak dapat dicapai oleh model sebelumnya. Jadi apa yang mendorong kejayaan mereka? Pertama sekali, kukuhkan latihan pembangunan data. Melalui pengumpulan data, pelabelan data dan strategi penyediaan data yang lebih baik, kuantiti dan kualiti data yang digunakan untuk melatih model GPT telah meningkat dengan ketara. Kedua, bangunkan data inferens. Memandangkan model GPT terkini telah menjadi cukup berkuasa, kami boleh mencapai pelbagai matlamat dengan melaraskan pembayang (atau melaraskan data inferens) semasa membetulkan model. Sebagai contoh, kita boleh melakukan ringkasan teks dengan menyediakan teks ringkasan bersama-sama arahan seperti "ringkaskan" atau "TL;DR" untuk membimbing proses inferens. Tweak segera, gambar oleh Disediakan oleh pengarang Merancang gesaan penaakulan yang betul ialah tugas yang mencabar. Ia sangat bergantung pada teknik heuristik. Tinjauan yang baik meringkaskan kaedah gesaan berbeza yang digunakan orang setakat ini. Kadangkala, isyarat yang serupa secara semantik pun boleh mempunyai output yang sangat berbeza. Dalam kes ini, penentukuran berasaskan kiu lembut mungkin diperlukan untuk mengurangkan percanggahan. Penentukuran berasaskan gesaan lembut. Imej ini datang daripada kertas https://arxiv.org/abs/2303.13035v1, dengan kebenaran daripada pengarang asal Penyelidikan tentang pembangunan besar data inferens model bahasa masih Di peringkat awal. Dalam masa terdekat, lebih banyak teknik pembangunan data inferens yang telah digunakan dalam tugasan lain boleh digunakan untuk bidang model bahasa besar. Dari segi penyelenggaraan data, ChatGPT/GPT-4, sebagai produk komersial, bukan sekadar latihan yang berjaya, tetapi memerlukan latihan yang berterusan dan penyelenggaraan. Jelas sekali, kami tidak tahu cara penyelenggaraan data dilakukan di luar OpenAI. Oleh itu, kami membincangkan beberapa strategi AI berpusatkan data umum yang mungkin telah digunakan atau akan digunakan dalam model GPT: Sistem ChatGPT/GPT-4 mampu mengumpul maklum balas pengguna melalui dua butang ikon "thumbs up" dan "thumbs down" seperti yang ditunjukkan dalam rajah untuk terus mempromosikan mereka pembangunan sistem. Tangkapan skrin di sini adalah dari https://chat.openai.com/chat. Kejayaan model bahasa berskala besar telah merevolusikan kecerdasan buatan. Melangkah ke hadapan, model bahasa yang besar boleh merevolusikan lagi kitaran hayat sains data. Untuk tujuan ini, kami membuat dua ramalan: Gunakan model bahasa yang besar untuk menjana data sintetik untuk melatih model, imej di sini adalah daripada makalah https:// /arxiv.org/abs/2303.04360, dengan izin daripada pengarang asal Saya harap ini artikel boleh digunakan dalam Inspire anda sendiri di tempat kerja. Anda boleh mengetahui lebih lanjut tentang rangka kerja AI yang mengutamakan data dan cara ia memanfaatkan model bahasa besar dalam kertas berikut: [1]Semakan kepintaran buatan berpusat data. [2]Prospek dan cabaran kecerdasan buatan berpusat data. Perhatikan bahawa kami juga mengekalkan repositori kod GitHub, yang akan dikemas kini dari semasa ke semasa sumber kecerdasan buatan berpusatkan data. Dalam artikel akan datang, saya akan menyelidiki tiga matlamat kecerdasan buatan berpusatkan data (melatih pembangunan data, pembangunan data inferens dan penyelenggaraan data) dan memperkenalkan kaedah seksual perwakilan. Zhu Xianzhong, editor komuniti 51CTO, blogger pakar 51CTO, pensyarah, guru komputer di sebuah universiti di Weifang, pengaturcaraan bebas komuniti Seorang veteran. Tajuk asal: Apakah Konsep AI Berpusatkan Data di belakang Model GPT?, pengarang: Henry Lai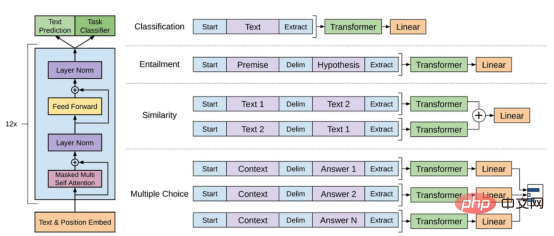

Apakah itu kecerdasan buatan berpusatkan data?
Mengapakah kecerdasan buatan berpusatkan data menjadikan model GPT begitu berjaya?

Apakah yang boleh dipelajari oleh komuniti sains data daripada gelombang model bahasa besar ini?
Rujukan
Pengenalan Penterjemah
Atas ialah kandungan terperinci Rahsia AI berpusatkan data dalam model GPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI