
Rumah >Java >javaTutorial >Apakah sebab Java tidak boleh membaca fail binari bukan teks menggunakan aliran aksara
Apakah sebab Java tidak boleh membaca fail binari bukan teks menggunakan aliran aksara

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-30 15:34:14873semak imbas
Membaca fail
Apabila saya mula-mula mempelajari bahagian strim IO Java, buku itu mengatakan bahawa hanya strim bait boleh digunakan untuk membaca fail binari bukan teks seperti gambar dan strim aksara tidak boleh digunakan , jika tidak fail akan rosak. Jadi saya sentiasa ingat ini, tetapi mengapa ia tidak boleh digunakan sentiasa menjadi keraguan saya. Hari ini, saya memikirkan masalah ini sekali lagi, jadi saya boleh menyelesaikannya sekali lagi.
Mula-mula kita lihat contoh kod tentang menyalin imej: Nota: Komputer saya mempunyai laluan D:/DB Jika anda tidak mempunyai folder DB, anda mesti mencipta satu.
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ReadImage {
public static void main(String[] args) throws IOException {
String imgPath = "D:/DB/husky/kkk.jpeg";
String byteImgCopyPath = "D:/DB/husky/byteCopykkk.jpeg";
String charImgCopyPath = "D:/DB/husky/charCopykkk.jpeg";
Path srcPath = Paths.get(imgPath);
Path desPath2 = Paths.get(byteImgCopyPath);
Path desPath3 = Paths.get(charImgCopyPath);
byteRead(srcPath.toFile(), desPath2.toFile());
System.out.println("字节复制执行成功!");
characterRead(srcPath.toFile(), desPath3.toFile());
System.out.println("字符复制执行成功!");
}
static void byteRead(File src, File des) throws IOException {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(des))) {
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
}
}
static void characterRead(File src, File des) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(src), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new FileWriter(des))) {
int hasRead = 0;
char[] c = new char[1024];
while ((hasRead = reader.read(c)) != -1) {
writer.write(c, 0, hasRead);
}
}
}
}Hasil berjalan: Ia boleh dilihat bahawa fail binari seperti imej tidak boleh dibaca menggunakan strim aksara dan strim bait mesti digunakan.

Perubahan saiz imej: Ia boleh dilihat bahawa saiz imej berubah selepas menggunakan strim aksara, tetapi tidak apabila menggunakan aliran bait.

Kenapa ni?
Melalui contoh di atas, kita dapat melihat bahawa memang mustahil untuk menyalin fail menggunakan aliran aksara, dan selepas menggunakan aliran aksara untuk menyalin fail, saiz fail juga akan berubah, yang membawa kepada tajuk kita akan berbincang hari ini.
Mari kita fikirkan dahulu mengapa teks boleh dipaparkan apabila fail teks dibuka? Kita semua tahu bahawa fail yang diproses oleh komputer, sama ada fail teks atau bukan teks, akhirnya disimpan dalam bentuk binari di dalam komputer.
Buka fail teks menggunakan mod heksadesimal editor teks:
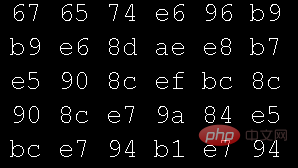
Gunakan mod perenambelasan editor Buka fail gambar yang digunakan oleh program di atas dalam mod tersuai:
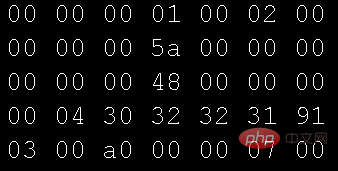
Membandingkan data dalam kedua-dua gambar, anda tidak sepatutnya menemui sebarang perbezaan, tetapi mengapa data teks dipaparkan? Ini adalah soalan yang sangat asas. Semua kursus asas di universiti merangkumi aspek ini -Jadual pengekodan aksara. Saya mula-mula belajar bahasa C, dan jadual pengekodan paling awal yang saya hubungi ialah ASCII (Kod Standard Amerika untuk Pertukaran Maklumat Kemudian, apabila saya belajar Java, saya bersentuhan dengan Unicode (Kod Universal). asalnya. Yang paling biasa digunakan pada masa ini Ia adalah UTF-8, pengekodan aksara panjang berubah untuk Unicode)
Nota: Menggunakan UTF-8 juga dibahagikan. ke dalam BOM (Byte Order Mark, characters) Section mark order) dan tiada dua bentuk, dan mencampurkannya akan membawa kepada ralat Jika anda berminat, anda boleh mempelajarinya.

Peranan jadual pengekodan aksara ditunjukkan dalam pengekodan Untuk memetik petikan daripada ensiklopedia:
Teks. dilihat pada monitor, Gambar dan maklumat lain dalam komputer sebenarnya bukanlah apa yang kita lihat Walaupun anda tahu bahawa semua maklumat disimpan dalam cakera keras, anda tidak dapat melihat apa-apa di dalam apabila anda memisahkannya, hanya beberapa cakera. . Katakan anda menggunakan mikroskop untuk membesarkan cakera, dan anda akan melihat bahawa permukaan cakera tidak rata Tempat cembung dimagnetkan, dan tempat cekung tidak bermagnet, dan tempat cekung mewakili nombor 0. Cakera keras hanya boleh menggunakan 0 dan 1 untuk mewakili semua teks, gambar dan maklumat lain. Jadi bagaimanakah huruf "A" disimpan pada cakera keras? Mungkin komputer Xiao Zhang menyimpan huruf "A" sebagai 1100001, manakala komputer Xiao Wang menyimpan huruf "A" sebagai 11000010. Dengan cara ini, kedua-dua pihak akan salah faham apabila mereka bertukar maklumat. Sebagai contoh, Xiao Zhang menghantar 1100001 kepada Xiao Wang Xiao Wang tidak menyangka bahawa 1100001 adalah huruf "A", tetapi mungkin menganggap ia adalah huruf "X". Jadi apabila Xiao Wang menggunakan Notepad untuk mengakses 1100001 yang disimpan pada cakera keras , mesej ralat muncul pada skrin Apa yang dipaparkan ialah huruf "X". Dalam erti kata lain, Xiao Zhang dan Xiao Wang menggunakan jadual pengekodan yang berbeza.
Jadi jadual pengekodan aksara ialah pemetaan satu sama satu antara nombor binari dan aksara , contohnya, 65 (nombor) mewakili A, jadi kod berikut akan menjadi output pada skrin A.
char c = 65; System.out.println(c);
Mari gunakan gelung untuk mengujinya:
char c = 0;
for (int i = 9999; i < 10009; i++) {
c = (char) i;
System.out.print(c+" ");
}Hasil ujian: (Sudah tentu, ini bergantung pada jadual pengekodan aksara semasa anda. Jika anda menggunakan ASCII, ia mungkin menarik.)
这样就解释了前面那个问题(为什么文本文件打开可以显示文字?),我们之所以可以看见文本文件的字符是因为计算机按照我们文件的编码(ASCII、UTF-8或者GBK等),从字符编码表中找出来对应的字符。 所以,当我们使用记事本打开二进制文件会看到乱码,这就是原因。文件的复制过程也是复制的二进制数据,而不是真实的文字。
因此可以这样理解文件复制的过程:
字符流:二进制数据 --编码-> 字符编码表 --解码-> 二进制数据
字节流:二进制数据 —> 二进制数据
所以问题就是出现在编码和解码的过程中,既然是字符的编码表,那它就是包含所有的字符,但是字符的数量是有限的,这就意味着它不能表示一些超过编码表的字符,因为根本不存在表中。所以,JVM 会使用一些字符进行替换,基本上都是乱码(所以大小会发生变化),而且如果有一个数据恰好是-1,那么读取就会中断,引起数据丢失。
例如如下代码使用字符流读取就会错误:
String filename = "D:/DB/fos.txt"; //文件名
byte[] b = new byte[] {-1, -1}; //两个字节,127的二进制就是 1111 1111
//数据写入文件
try (FileOutputStream fos = new FileOutputStream(filename)) {
fos.write(b, 0, b.length); //将两个127连续写入,就是 1111 1111 1111 1111
}
File file = new File(filename);
//输出文件的大小
System.out.println("file length: " + file.length());
char[] c = new char[2];
//使用字符流读取文件
try (FileReader reader = new FileReader(filename)) {
int count = reader.read(c); //Java使用Unicode编码,读取的是从 0-65535 之间的数字。
System.out.println("以文本形式输出:" + new String(c, 0, count)+" "+count);
for (char d : c) {
System.out.println("字符为:" + d);
}
}
System.out.println("表示字符:" + c[0]);
//再写入文件
try (FileWriter writer = new FileWriter(filename)) {
writer.write(c, 0, 2);
}
File f = new File(filename);
System.out.println("file length: " + f.length());结果:

说明: 我将两个1字节的-1写入(字节流)了文本文件(注意是字节:-1,不是字符:-1),然后再读取(字符流),再写入(字符流)就已经出现了问题。读取出的字符显示了一个奇怪的符号,而且它的值为:65533,这个值如果用字节表示的话,一个字节是不够的,所以文件的大小就会变化。在非文本的二进制数据中,出现这种情况都是正常的,因为本来就不是按照字符编码的。
因为字符都是正数,而非字符编码的话,字节数可能是负数(很可能),但是负数在字符看来就是正数,这也是为什么-1,被读成 65533的原因。可以看出来,读取就已经错误了。
注意: 这里的重点是对于使用字符流读取非文本文件,在读取-写入的过程中的问题。
Atas ialah kandungan terperinci Apakah sebab Java tidak boleh membaca fail binari bukan teks menggunakan aliran aksara. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Bagaimana untuk Melukis Segi Empat Berterusan dalam JPanel Tanpa Kemerosotan Prestasi?
- Bagaimana untuk Mengelakkan \'Xerces Hell\' dalam Java/Maven?
- Penantian Tersirat lwn Eksplisit dalam Selenium: Bilakah Anda Harus Memilih Menunggu Eksplisit?
- Apakah JavaBeans dan Bagaimana Ia Digunakan dalam Aplikasi Java?
- Bagaimanakah Saya Mencari Kelas Java Secara Pengaturcaraan yang Melaksanakan Antara Muka Khusus?