
Rumah >Peranti teknologi >AI >Resapan Lembut: Rangka kerja baharu Google menjadualkan, mempelajari dan membuat sampel dengan betul daripada proses resapan sejagat
Resapan Lembut: Rangka kerja baharu Google menjadualkan, mempelajari dan membuat sampel dengan betul daripada proses resapan sejagat

- 王林ke hadapan
- 2023-04-30 13:22:061511semak imbas
Kami tahu bahawa model berasaskan skor dan model kebarangkalian penyebaran resapan (DDPM) ialah dua kelas model generatif berkuasa yang menjana sampel dengan menyongsangkan proses resapan. Kedua-dua jenis model ini telah disatukan menjadi satu rangka kerja dalam makalah "Pemodelan generatif berasaskan skor melalui persamaan pembezaan stokastik" oleh Yang Song dan penyelidik lain, dan dikenali secara meluas sebagai model resapan.
Pada masa ini, model resapan telah mencapai kejayaan besar dalam beberapa siri aplikasi termasuk imej, audio, penjanaan video dan menyelesaikan masalah songsang. Dalam kertas kerja "Menjelaskan ruang reka bentuk model generatif berasaskan penyebaran", penyelidik seperti Tero Karras menganalisis ruang reka bentuk model resapan dan mengenal pasti tiga peringkat, iaitu i) memilih penjadualan tahap hingar, ii) memilih parameter rangkaian. isasi (setiap parameterisasi menjana fungsi kehilangan yang berbeza), iii) mereka bentuk algoritma pensampelan.
Baru-baru ini, dalam makalah arXiv "Soft Diffusion: Score Matching for General Corruption" yang dikendalikan bersama oleh Google Research dan UT-Austin, beberapa penyelidik percaya bahawa masih terdapat model penyebaran Langkah penting : rasuah. Secara umumnya, rasuah ialah proses menambah hingar amplitud yang berbeza, dan untuk DDMP juga memerlukan penskalaan semula. Walaupun terdapat percubaan untuk menggunakan pengedaran berbeza untuk penyebaran, rangka kerja umum masih kurang. Oleh itu, para penyelidik mencadangkan rangka kerja reka bentuk model penyebaran untuk proses kerosakan yang lebih umum.
Secara khusus, mereka mencadangkan objektif latihan baharu yang dipanggil Padanan Skor Lembut dan kaedah pensampelan baru, Pensampel Momentum. Keputusan teori menunjukkan bahawa untuk proses kerosakan yang memenuhi syarat keteraturan, Soft Score MatchIng dapat mempelajari skor mereka (iaitu, kecerunan kemungkinan) bahawa resapan mesti mengubah mana-mana imej kepada mana-mana imej dengan kemungkinan bukan sifar.
Dalam bahagian eksperimen, penyelidik melatih model pada CelebA dan CIFAR-10 Model yang dilatih pada CelebA mencapai skor SOTA FID model resapan linear - 1.85. Pada masa yang sama, model yang dilatih oleh penyelidik adalah jauh lebih pantas daripada model yang dilatih menggunakan penyebaran denoising Gaussian yang asal.

Alamat kertas: https://arxiv.org/pdf/2209.05442.pdf
Gambaran Keseluruhan Kaedah
Secara umumnya, model resapan menjana imej dengan menyongsangkan proses kerosakan yang meningkatkan bunyi secara beransur-ansur. Para penyelidik menunjukkan cara belajar menyongsangkan resapan yang melibatkan degradasi deterministik linear dan bunyi aditif stokastik.

Secara khusus, penyelidik menunjukkan rangka kerja untuk menggunakan model kerosakan yang lebih umum untuk melatih model resapan, yang terdiri daripada tiga bahagian, masing-masing, untuk objektif latihan baharu. Padanan Skor Lembut, kaedah pensampelan novel Sampel Momentum, dan penjadualan mekanisme kerosakan.
Mula-mula mari kita lihat pada sasaran latihan Padanan Skor Lembut Nama ini diilhamkan oleh penapisan lembut, istilah fotografi yang merujuk kepada penapis yang mengalih keluar butiran halus. Ia mempelajari pecahan proses kerosakan linear konvensional dengan cara yang boleh dibuktikan, juga menggabungkan proses penapisan ke dalam rangkaian, dan melatih model untuk meramalkan imej selepas kerosakan yang sepadan dengan pemerhatian resapan.
Selagi penyebaran memberikan kebarangkalian bukan sifar kepada mana-mana pasangan imej yang bersih dan rosak, objektif latihan ini boleh membuktikan bahawa skor dipelajari. Selain itu, keadaan ini sentiasa berpuas hati apabila terdapat bunyi tambahan dalam kerosakan.
Secara khusus, penyelidik meneroka proses kerosakan dalam bentuk berikut.

Dalam proses itu, penyelidik mendapati bunyi bising mempunyai manfaat empirikal (iaitu keputusan yang lebih baik) dan teori (iaitu untuk mempelajari pecahan). . Ini juga menjadi perbezaan utama daripada Cold Diffusion, kerja serentak yang membalikkan rasuah yang menentukan.
Yang kedua ialah kaedah persampelan Persampelan Momentum. Para penyelidik menunjukkan bahawa pilihan pensampel mempunyai kesan yang signifikan terhadap kualiti sampel yang dihasilkan. Mereka mencadangkan Momentum Sampler untuk menyongsangkan proses kerosakan linear universal. Pensampel menggunakan gabungan cembung rasuah dengan tahap resapan yang berbeza dan diilhamkan oleh kaedah momentum dalam pengoptimuman.
Kaedah persampelan ini diilhamkan oleh rumusan berterusan model resapan yang dicadangkan dalam kertas kerja oleh Yang Song et al. Algoritma untuk Pensampel Momentum ditunjukkan di bawah.

Rajah di bawah secara visual menunjukkan kesan kaedah pensampelan yang berbeza ke atas kualiti sampel yang dijana. Imej yang diambil dengan Naive Sampler di sebelah kiri kelihatan berulang dan kurang terperinci, manakala Momentum Sampler di sebelah kanan meningkatkan kualiti pensampelan dan skor FID dengan ketara.

Perkara terakhir ialah penjadualan. Walaupun jenis degradasi dipratakrifkan (seperti kabur), menentukan jumlah kerosakan pada setiap langkah resapan bukanlah perkara remeh. Para penyelidik mencadangkan alat berprinsip untuk membimbing reka bentuk proses kerosakan. Untuk mencari jadual, mereka meminimumkan jarak Wasserstein antara pengedaran di sepanjang laluan. Secara intuitif, penyelidik mahukan peralihan yang lancar daripada pengedaran yang rosak sepenuhnya kepada pengedaran yang bersih.
Hasil eksperimen
Para penyelidik menilai kaedah yang dicadangkan pada CelebA-64 dan CIFAR-10, yang kedua-duanya adalah garis dasar standard untuk penjanaan imej. Tujuan utama eksperimen adalah untuk memahami peranan jenis kerosakan.
Para penyelidik mula-mula cuba menggunakan bunyi kabur dan amplitud rendah untuk kerosakan. Keputusan menunjukkan bahawa model cadangan mereka mencapai keputusan SOTA pada CelebA, iaitu, skor FID 1.85, mengatasi semua kaedah lain yang hanya menambah hingar dan mungkin menskala semula imej. Di samping itu, skor FID yang diperoleh pada CIFAR-10 ialah 4.64, iaitu kompetitif walaupun tidak mencapai SOTA.

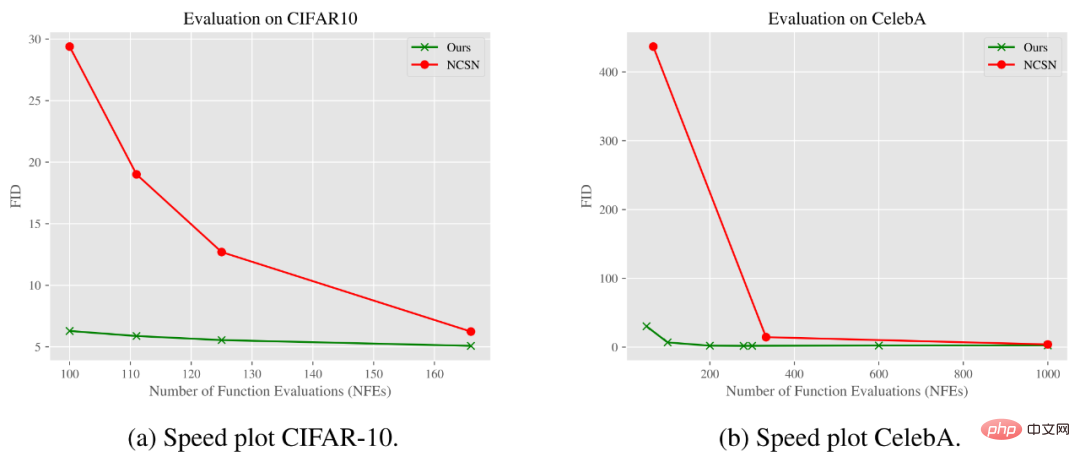
Selain itu, pada set data CIFAR-10 dan CelebA, kaedah penyelidik juga menunjukkan prestasi yang lebih baik pada metrik lain, masa pensampelan. Satu lagi faedah tambahan ialah kelebihan pengiraan yang ketara. Penyahkaburan (hampir tiada hingar) nampaknya merupakan manipulasi yang lebih cekap berbanding kaedah penyahhidratan penjanaan imej.
Graf di bawah menunjukkan cara skor FID berubah dengan Bilangan Penilaian Fungsi (NFE). Seperti yang dapat dilihat daripada keputusan, model kami boleh mencapai kualiti yang sama atau lebih baik daripada model penyebaran denoising Gaussian standard menggunakan langkah yang jauh lebih sedikit pada set data CIFAR-10 dan CelebA.
Atas ialah kandungan terperinci Resapan Lembut: Rangka kerja baharu Google menjadualkan, mempelajari dan membuat sampel dengan betul daripada proses resapan sejagat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI