
Rumah >Peranti teknologi >AI >Analisis ringkas tentang peta jalan teknologi persepsi visual untuk pemanduan autonomi
Analisis ringkas tentang peta jalan teknologi persepsi visual untuk pemanduan autonomi

- 王林ke hadapan
- 2023-04-29 20:07:051633semak imbas
01 Latar Belakang
Pemanduan autonomi ialah peralihan beransur-ansur daripada peringkat ramalan ke peringkat perindustrian Prestasi khusus boleh dibahagikan kepada empat mata. Pertama sekali, dalam konteks data besar, skala set data berkembang pesat Akibatnya, butiran prototaip yang dibangunkan sebelum ini pada set data berskala kecil akan ditapis sebahagian besarnya, dan hanya kerja yang boleh berkesan pada besar. -data skala akan ditinggalkan. Yang kedua ialah penukaran fokus, daripada adegan monokular kepada berbilang paparan, yang membawa kepada peningkatan kerumitan. Kemudian terdapat kecenderungan ke arah reka bentuk mesra aplikasi, seperti pemindahan ruang output dari ruang imej ke ruang BEV.
Langkah terakhir ialah mempertimbangkan secara beransur-ansur kelajuan penaakulan daripada usaha mengejar ketepatan yang tulen sebelumnya. Pada masa yang sama, tindak balas pantas diperlukan dalam senario pemanduan autonomi, jadi keperluan prestasi akan mempertimbangkan kelajuan Selain itu, lebih banyak pertimbangan diberikan kepada cara menggunakan peranti tepi.
Satu lagi bahagian latar belakang ialah dalam 10 tahun yang lalu, persepsi visual telah berkembang pesat didorong oleh pembelajaran mendalam Terdapat banyak kerja dan beberapa kerja dalam arah arus perdana seperti klasifikasi, pengesanan dan segmentasi Paradigma yang cukup matang. Dalam proses pembangunan persepsi visual dalam senario pemanduan autonomi, aspek seperti definisi sasaran pengekodan ciri, paradigma persepsi dan penyeliaan telah banyak meminjam daripada arahan arus perdana ini, oleh itu, sebelum melakukan persepsi pemanduan autonomi, arah arus perdana ini harus diterokai. Berceloteh sedikit.
Di bawah latar belakang ini, sebilangan besar kerja pengesanan sasaran 3D pada set data berskala besar telah muncul pada tahun lalu, seperti ditunjukkan dalam Rajah 1 (yang ditandakan dengan warna merah ialah yang pertama) algoritma).
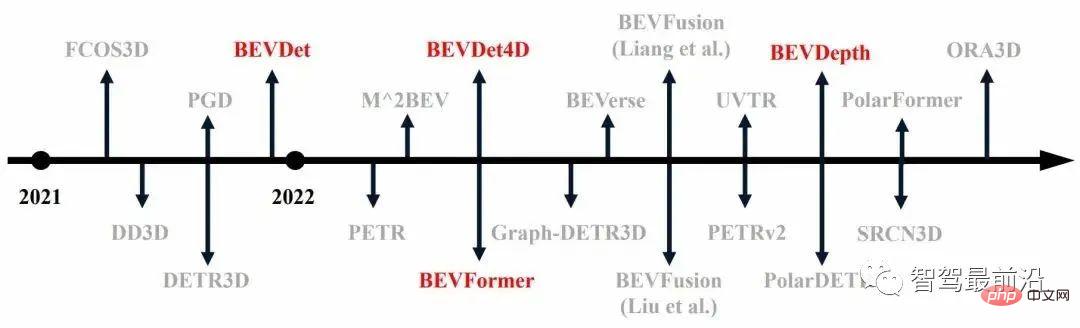
Rajah 1 Pembangunan pengesanan sasaran 3D pada tahun lalu
02 Laluan Teknikal
2.1 Mengangkat
Perbezaan antara persepsi visual dalam senario pemanduan autonomi dan persepsi visual arus perdana terutamanya terletak pada perbezaan ruang definisi sasaran yang diberikan Sasaran persepsi visual arus perdana ditakrifkan dalam ruang imej, manakala sasaran senario pemanduan autonomi ditakrifkan dalam. ruang 3 dimensi. Apabila input adalah semua imej, mendapatkan hasil dalam ruang 3 dimensi memerlukan proses Angkat Ini adalah isu teras persepsi visual untuk pemanduan autonomi.
Kita boleh membahagikan kaedah menyelesaikan masalah objek Lift kepada input, ciri perantaraan dan output Contoh tahap input ialah perubahan perspektif maklumat kedalaman, dan kemudian Gunakan maklumat kedalaman untuk menayangkan nilai RGB imej ke dalam ruang tiga dimensi untuk mendapatkan awan titik berwarna Kerja-kerja pengesanan awan titik yang berkaitan akan diikuti kemudian.
Apa yang lebih menjanjikan pada masa ini ialah transformasi tahap ciri atau tingkatan tahap ciri Contohnya, DETR3D, ini semua melakukan perubahan spatial pada tahap ciri ialah ia boleh mengelakkan pertindihan Untuk mengekstrak ciri peringkat imej, jumlah pengiraan adalah kecil, dan ia juga boleh mengelakkan masalah gabungan hasil lihat-sekitar peringkat output. Sudah tentu, penukaran peringkat ciri juga akan mempunyai beberapa masalah biasa Contohnya, beberapa OP pelik biasanya digunakan, yang menjadikan penggunaan tidak mesra.
Pada masa ini, proses Angkat tahap ciri yang lebih mantap adalah berdasarkan strategi mekanisme kedalaman dan perhatian, dan yang mewakili masing-masing adalah BEVDet dan DETR3D. Strategi berasaskan kedalaman adalah untuk melengkapkan proses Lift dengan mengira kedalaman setiap titik imej, dan kemudian menayangkan ciri ke dalam ruang 3 dimensi mengikut model pengimejan kamera. Strategi berdasarkan mekanisme perhatian adalah untuk mentakrifkan objek dalam ruang 3 dimensi sebagai pertanyaan, mencari ciri imej yang sepadan dengan titik tengah ruang tiga dimensi sebagai kunci dan nilai melalui parameter dalaman dan luaran, dan kemudian mengira objek 3 dimensi melalui perhatian Satu ciri objek dalam ruang.
Semua algoritma semasa pada asasnya sangat bergantung pada model kamera, sama ada berasaskan kedalaman atau berasaskan perhatian, yang mengakibatkan kepekaan terhadap penentukuran dan proses pengiraan yang kompleks. Algoritma yang meninggalkan model kamera selalunya kurang keteguhan, jadi aspek ini belum matang sepenuhnya.
2.2 Temporal
Maklumat temporal boleh meningkatkan kesan pengesanan sasaran dengan berkesan. Untuk senario pemanduan autonomi, pemasaan mempunyai makna yang lebih mendalam kerana kelajuan sasaran adalah salah satu sasaran persepsi utama dalam senario semasa. Fokus kelajuan terletak pada perubahan data bingkai tunggal tidak mempunyai maklumat perubahan yang mencukupi, jadi pemodelan diperlukan untuk menyediakan maklumat perubahan dalam dimensi masa. Kaedah pemodelan siri masa awan titik sedia ada adalah untuk mencampurkan awan titik berbilang bingkai sebagai input, supaya awan titik yang agak padat boleh diperoleh, menjadikan pengesanan lebih tepat. Selain itu, awan titik berbilang bingkai mengandungi maklumat berterusan Kemudian, semasa proses latihan rangkaian, BP digunakan untuk mempelajari cara mengekstrak maklumat berterusan ini untuk menyelesaikan tugasan seperti anggaran kelajuan yang memerlukan maklumat berterusan.
Kaedah pemodelan masa persepsi visual terutamanya diperoleh daripada BEVDet4D dan BEVFormer. BEVDet4D menyediakan maklumat berterusan untuk rangkaian seterusnya dengan hanya menggabungkan ciri dua bingkai. Laluan lain adalah berdasarkan perhatian, menyediakan kedua-dua bingkai sementara tunggal dan ciri lawan jam sebagai objek pertanyaan, dan kemudian menanyakan kedua-dua ciri ini secara serentak melalui perhatian untuk mengekstrak maklumat masa.
2.3 Kedalaman
Salah satu kelemahan terbesar persepsi visual pemanduan autonomi berbanding persepsi radar ialah anggaran kedalaman Ketepatan. Makalah "kedalaman kebarangkalian dan geometri: mengesan objek dalam perspektif" mengkaji kesan faktor berbeza pada skor prestasi dengan menggantikan kaedah GT Kesimpulan utama daripada analisis ialah anggaran kedalaman yang tepat boleh membawa peningkatan prestasi yang ketara.
Walau bagaimanapun, anggaran kedalaman merupakan halangan utama dalam persepsi visual semasa pada masa ini terdapat dua idea utama untuk penambahbaikan Satu ialah menggunakan kekangan geometri dalam PGD untuk melaksanakan ramalan pada peta kedalaman. memperhalusi. Satu lagi ialah menggunakan lidar sebagai penyeliaan untuk mendapatkan anggaran kedalaman yang lebih mantap.
Penyelesaian unggul pada masa ini dalam proses, BEVDepth, menggunakan maklumat kedalaman yang diberikan oleh lidar semasa proses latihan untuk mengawasi anggaran kedalaman semasa proses perubahan dan melaksanakan tugas utama persepsi. Pada masa yang sama.
2.4 Muti-modaliti/Multi-Task
Multi-tugas adalah untuk menyelesaikan berbilang tugas pada rangka kerja bersatu Pelbagai tugas persepsi, melalui pengiraan ini boleh mencapai tujuan menjimatkan sumber atau mempercepatkan penaakulan pengiraan. Walau bagaimanapun, kaedah semasa pada asasnya mencapai multi-tugas hanya dengan memproses ciri pada tahap yang berbeza selepas memperoleh ciri bersatu Terdapat masalah biasa penurunan prestasi selepas penggabungan tugas. Multimodaliti juga hampir universal dalam mencari bentuk yang boleh digabungkan secara langsung dalam keseluruhan penghakiman, dan kemudian mencapai gabungan mudah.
03 Siri BEVDet
3.1 BEVDet
Rangkaian BEVDet ditunjukkan dalam Rajah 2. Proses pengekstrakan ciri terutamanya menukar ciri ruang imej yang diekstrak kepada ciri ruang BEV, dan kemudian mengekodkan lagi ciri ini untuk mendapatkan ramalan yang boleh digunakan Ciri, dan akhirnya menggunakan ramalan padat untuk meramalkan sasaran.
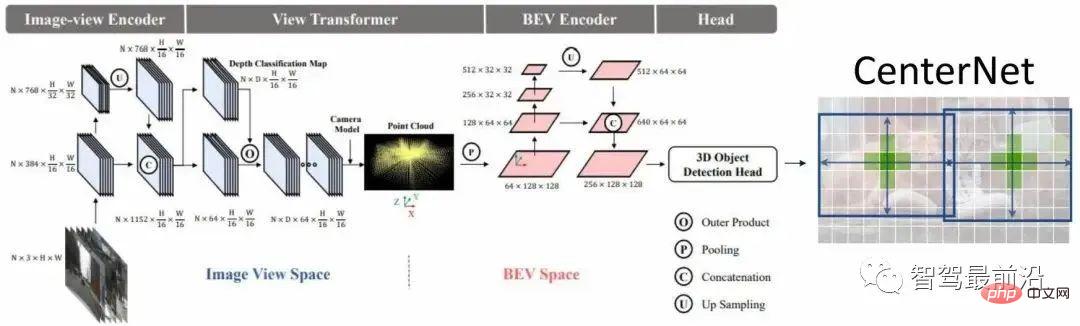
Rajah 2 Struktur rangkaian BEVDet
Proses modul perubahan perspektif dibahagikan kepada dua langkah Pertama, diandaikan bahawa saiz ciri yang akan diubah ialah VxCxHxW, dan kemudian kedalaman diramalkan dalam ruang imej dengan cara pengelasan. taburan kedalaman dimensi diperoleh Kemudian ini boleh digunakan Kedua-dua ciri kedalaman yang berbeza untuk mendapatkan ciri visual, kemudian gunakan model kamera untuk menayangkannya ke dalam ruang 3 dimensi, voxelize ruang 3 dimensi, dan kemudian melakukan proses percikan untuk mendapatkan ciri BEV.
Ciri yang sangat penting bagi modul perubahan perspektif ialah ia memainkan peranan pengasingan bersama dalam kelembapan data. Khususnya, melalui parameter dalaman kamera, titik pada sistem koordinat kamera boleh diperolehi dengan menayangkannya ke dalam ruang 3 dimensi Apabila penambahan data digunakan pada titik dalam ruang imej, untuk mengekalkan koordinat daripada titik pada sistem koordinat kamera Invarian, anda perlu melakukan transformasi songsang, iaitu, koordinat pada sistem koordinat kamera tidak berubah sebelum dan selepas penambahan, yang mempunyai kesan pengasingan bersama. Kelemahan pengasingan bersama ialah penambahan ruang imej tidak menyelaraskan pembelajaran ruang BEV Kelebihannya dapat meningkatkan kemantapan pembelajaran ruang BEV
Kita bermula dari. eksperimen Beberapa kesimpulan penting boleh dibuat daripada perkara di atas. Mula-mula, selepas menggunakan pengekod ruang BEV, algoritma lebih berkemungkinan jatuh ke dalam pemasangan berlebihan. Kesimpulan lain ialah pengembangan ruang BEV akan memberi impak yang lebih besar terhadap prestasi berbanding pengembangan ruang imej.
Terdapat juga korelasi antara saiz sasaran ruang BEV dan ketinggian kategori Pada masa yang sama, panjang pertindihan kecil antara sasaran akan menyebabkan beberapa masalah bahawa reka bentuk bukan kutub dalam ruang imej adalah Kaedah penindasan nilai besar tidak optimum. Teras strategi pecutan serentak adalah menggunakan kaedah pengkomputeran selari untuk memperuntukkan benang bebas kepada tugas pengkomputeran kecil yang berbeza untuk mencapai tujuan pecutan pengkomputeran selari Kelebihannya ialah tiada overhed memori grafik tambahan.
3.2 BEVDet4D
Struktur rangkaian BEVDet4D ditunjukkan dalam Rajah 3. Fokus utama rangkaian ini ialah cara menggunakan ciri bingkai masa terbalik pada bingkai semasa Kami memilih ciri input sebagai objek yang dikekalkan, tetapi tidak memilih ciri imej ini kerana pembolehubah sasaran ditakrifkan dalam ruang BEV. , dan imej Ciri-ciri tidak sesuai untuk pemodelan pemasaan langsung. Pada masa yang sama, ciri di sebalik Pengekod BEV tidak dipilih sebagai ciri gabungan berterusan, kerana kita perlu mengekstrak ciri berterusan dalam Pengekod BEV.
Memandangkan ciri yang dikeluarkan oleh modul perubahan perspektif agak jarang, Pengekod BEV tambahan disambungkan selepas perubahan perspektif untuk mengekstrak ciri BEV awal, dan kemudian melaksanakan pemodelan siri masa. Semasa gabungan masa, kami hanya menyambungkan ciri rangka lawan jam dengan jarum semasa dengan menjajarkannya untuk melengkapkan gabungan masa Sebenarnya, kami di sini menyerahkan tugas mengekstrak ciri pemasaan kepada yang kemudiannya.
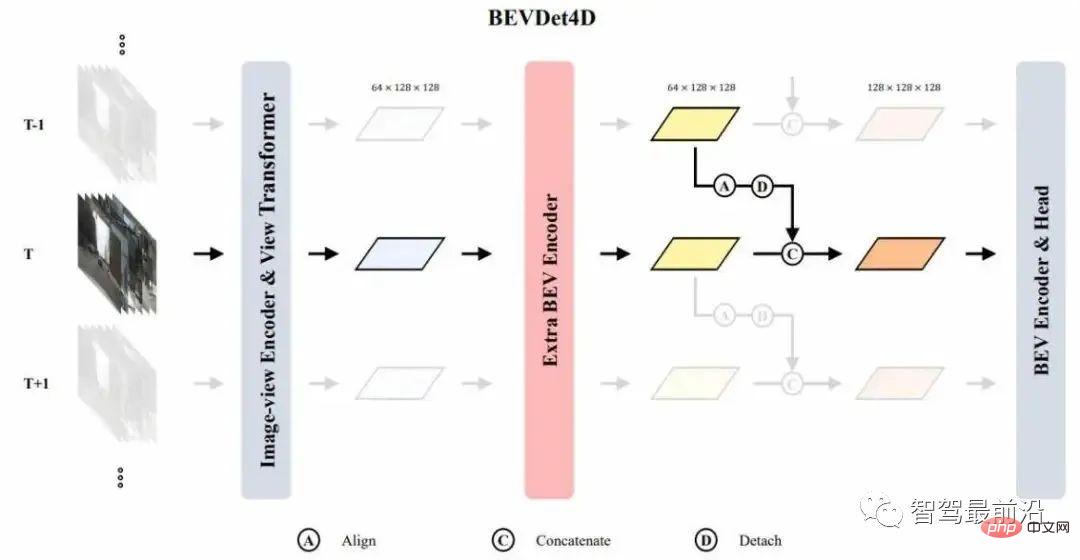
Rajah 3 struktur rangkaian BEVDet4D
Bagaimana untuk mereka bentuk pembolehubah sasaran yang sepadan dengan struktur rangkaian? Sebelum itu, kita perlu memahami beberapa ciri utama rangkaian Yang pertama ialah medan penerimaan ciri Oleh kerana rangkaian belajar melalui BP, medan penerimaan ciri ditentukan oleh ruang keluaran.
Ruang keluaran algoritma persepsi pemanduan autonomi secara amnya ditakrifkan sebagai ruang dalam julat tertentu di sekeliling kenderaan sendiri. Peta ciri boleh dianggap sebagai pengedaran seragam pada ruang berterusan, dengan titik sudut Disejajarkan dengan sampel diskret. Oleh kerana medan penerimaan peta ciri ditakrifkan dalam julat tertentu di sekeliling kereta sendiri, ia akan berubah dengan pergerakan kereta sendiri Oleh itu, pada dua nod masa yang berbeza, medan penerimaan peta ciri mempunyai tertentu nilai dalam sistem koordinat dunia.
Jika kedua-dua ciri disambungkan secara langsung, kedudukan sasaran statik dalam kedua-dua peta ciri adalah berbeza dan pengimbangan sasaran dinamik dalam dua peta ciri Ia adalah sama dengan offset ujian kendiri ditambah dengan offset sasaran dinamik dalam sistem koordinat dunia. Mengikut prinsip ketekalan corak, kerana mengimbangi sasaran dalam ciri yang disambungkan berkaitan dengan kenderaan sendiri, apabila menetapkan matlamat pembelajaran rangkaian, ia harus menjadi perubahan dalam kedudukan sasaran dalam ini. dua peta ciri.
Mengikut formula berikut, dapat disimpulkan bahawa sasaran pembelajaran tidak berkaitan dengan pergerakan ujian kendiri, tetapi hanya berkaitan dengan pergerakan sasaran dalam koordinat dunia. sistem.
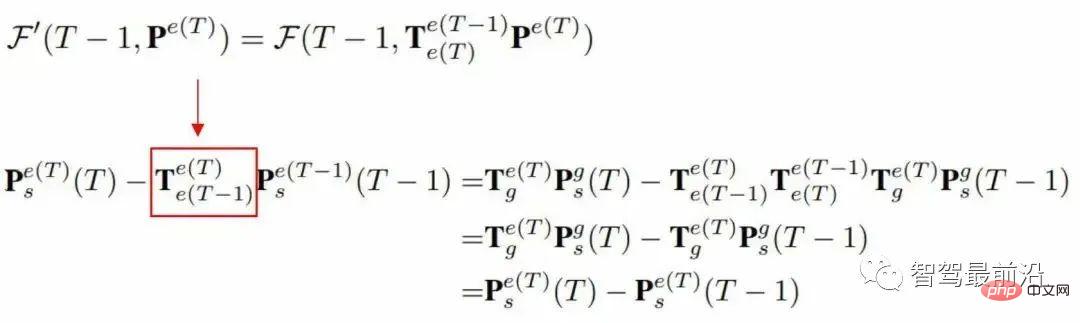
Perbezaan antara objektif pembelajaran yang kami peroleh daripada di atas dan kaedah arus perdana semasa ialah komponen masa dialih keluar, dan kelajuan adalah sama dengan anjakan/masa, tetapi kedua-dua ciri ini tidak menyediakan berkaitan masa Oleh itu, jika anda ingin mempelajari sasaran kelajuan ini, rangkaian perlu menganggarkan komponen masa dengan tepat, yang meningkatkan kesukaran pembelajaran. Dalam amalan, kita boleh menetapkan masa antara dua bingkai sebagai nilai malar semasa proses latihan Rangkaian selang masa yang berterusan boleh dipelajari dengan mempelajari BP.
Dalam penambahan domain masa, kami secara rawak menggunakan selang masa yang berbeza semasa proses latihan Pada selang masa yang berbeza, mengimbangi sasaran dalam dua gambar Berbeza, mengimbangi sasaran pembelajaran juga berbeza, untuk mencapai kesan Lupin model pada offset yang berbeza. Pada masa yang sama, model mempunyai kepekaan tertentu terhadap offset sasaran, iaitu, jika selang terlalu kecil, perubahan antara dua bingkai akan sukar untuk dilihat jika ia terlalu kecil. Oleh itu, memilih selang masa yang sesuai semasa ujian boleh meningkatkan prestasi generalisasi model dengan berkesan.
3.3 BEVDepth
Artikel ini menggunakan radar untuk mendapatkan anggaran kedalaman yang mantap, seperti ditunjukkan dalam Rajah 4 yang ditunjukkan. Ia menggunakan awan titik untuk mengawasi pengagihan kedalaman dalam modul perubahan Penyeliaan ini adalah jarang berbanding dengan pengawasan kedalaman yang disediakan oleh sasaran, tetapi ia tidak mencapai setiap piksel Pengawasan mendalam yang tepat juga agak jarang. Walau bagaimanapun, lebih banyak sampel boleh disediakan untuk meningkatkan prestasi generalisasi anggaran kedalaman ini.
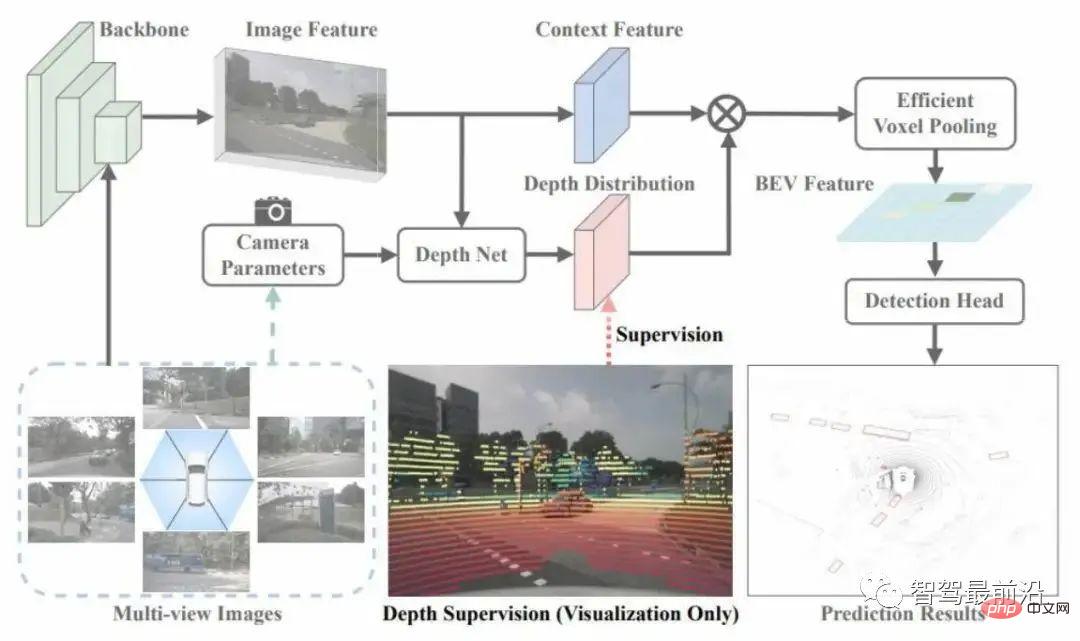
Rajah 4 Struktur rangkaian BEVDepth
Satu lagi aspek kerja ini adalah untuk membahagikan ciri dan kedalaman kepada dua cawangan untuk anggaran, dan menambah rangkaian baki tambahan pada cawangan anggaran kedalaman untuk meningkatkan medan penerimaan cawangan anggaran kedalaman. Penyelidik percaya bahawa ketepatan parameter dalaman dan luaran kamera akan menyebabkan konteks dan kedalaman menjadi tidak sejajar Apabila rangkaian anggaran kedalaman tidak cukup berkuasa, akan berlaku kehilangan ketepatan.
Akhir sekali, parameter dalaman kamera ini digunakan sebagai input cawangan anggaran kedalaman, menggunakan kaedah yang serupa dengan NSE untuk melakukan pelarasan peringkat saluran pada saluran ciri input. Ini boleh meningkatkan keteguhan rangkaian dengan berkesan kepada parameter dalaman kamera yang berbeza.
04 Had dan perbincangan berkaitan
Pertama, persepsi visual pemanduan autonomi Ia akhirnya menyediakan penggunaan, yang melibatkan isu data dan isu model. Masalah data melibatkan isu kepelbagaian dan anotasi data, kerana anotasi manual sangat mahal, jadi kita akan melihat sama ada anotasi automatik boleh dicapai pada masa hadapan.
Pada masa ini, pelabelan sasaran dinamik tidak pernah berlaku sebelum ini Untuk sasaran statik, pembinaan semula 3D boleh digunakan untuk mendapatkan pelabelan separa automatik atau separa automatik. Dari segi model, reka bentuk model semasa tidak teguh kepada penentukuran atau sensitif kepada penentukuran Jadi bagaimana untuk menjadikan model teguh kepada penentukuran atau bebas daripada penentukuran juga merupakan persoalan yang patut difikirkan.
Isu lain ialah pecutan struktur rangkaian. Bolehkah OP umum digunakan untuk mencapai perubahan perspektif?
Atas ialah kandungan terperinci Analisis ringkas tentang peta jalan teknologi persepsi visual untuk pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI