
Rumah >Peranti teknologi >AI >Ia hanya mengambil masa 3 saat untuk mencuri suara anda! Microsoft mengeluarkan model sintesis pertuturan VALL-E: Netizen menyatakan bahawa ambang untuk 'penipuan telefon' telah diturunkan semula
Ia hanya mengambil masa 3 saat untuk mencuri suara anda! Microsoft mengeluarkan model sintesis pertuturan VALL-E: Netizen menyatakan bahawa ambang untuk 'penipuan telefon' telah diturunkan semula

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-28 22:34:051337semak imbas
Biar ChatGPT membantu anda menulis skrip dan Stable Diffusion menjana ilustrasi Adakah anda memerlukan pelakon suara untuk membuat video? Ia akan datang!
Baru-baru ini, penyelidik dari Microsoft mengeluarkan model text-to-speech (TTS) baharu VALL-E, yang hanya perlu menyediakan tiga saat sampel audio untuk mensimulasikan input suara manusia, dan Audio yang sepadan disintesis berdasarkan teks input, dan nada emosi penceramah juga boleh dikekalkan.

Pautan kertas: https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
Pautan projek: https://valle-demo.github. io/
Pautan kod: https://github.com/microsoft/unilm
Mari kita lihat kesannya dahulu: Katakan anda mempunyai rakaman 3 saat.
audio diversity_speaker: 00:0000:03
Kemudian hanya masukkan teks "Kerana kami tidak memerlukannya untuk mendapatkan ucapan yang disintesis."
diversity_s1 Audio: 00:0000:01
Walaupun menggunakan benih rawak yang berbeza, sintesis pertuturan yang diperibadikan boleh dilakukan.
diversity_s2 Audio: 00:0000:02
VALL-E juga boleh mengekalkan bunyi ambien pembesar suara, seperti memasukkan suara ini.
audio env_speaker: 00:0000:03
Kemudian menurut teks "Saya rasa ia seperti anda tahu um lebih mudah juga.", anda boleh mengeluarkan ucapan yang disintesis sambil mengekalkan bunyi ambien .
env_vall_e Audio: 00:0000:02
Dan VALL-E juga boleh mengekalkan emosi pembesar suara, seperti memasukkan suara marah.
anger_pt Audio: 00:0000:03
Berdasarkan teks "Kita kena kurangkan bilangan beg plastik.", anda juga boleh meluahkan emosi marah.
anger_ours Audio: 00:0000:02
Terdapat banyak lagi contoh di tapak web projek.
Dari segi metodologi, penyelidik melatih model bahasa VALL-E daripada pengekodan diskret yang diekstrak daripada model codec audio neural luar biasa, dan menganggap TTS sebagai tugas pemodelan bahasa bersyarat dan bukannya regresi isyarat berterusan.
Dalam peringkat pra-latihan, data latihan TTS yang diterima oleh VALL-E mencapai 60,000 jam pertuturan bahasa Inggeris, iaitu ratusan kali lebih besar daripada data yang digunakan oleh sistem sedia ada.
Selain itu, VALL-E juga telah menunjukkan keupayaan pembelajaran dalam konteks Ia boleh mensintesis pertuturan diperibadikan berkualiti tinggi dengan hanya menggunakan rakaman pendaftaran 3 saat pembesar suara yang tidak kelihatan sebagai gesaan bunyi.
Hasil eksperimen menunjukkan bahawa VALL-E dengan ketara mengatasi sistem TTS tangkapan sifar tercanggih dari segi keaslian pertuturan dan persamaan pembesar suara, dan juga boleh mengekalkan emosi pembesar suara dan akustik bunyi isyarat dalam persekitaran sintesis.
Sintesis pertuturan tangkapan sifar
Dalam dekad yang lalu, sintesis pertuturan telah membuat penemuan besar melalui pembangunan rangkaian saraf dan pemodelan hujung ke hujung.
Tetapi sistem text-to-speech (TTS) lata semasa biasanya menggunakan saluran paip dengan model akustik dan vocoder yang menggunakan spektrogram mel sebagai perwakilan perantaraan.
Walaupun sesetengah sistem TTS berprestasi tinggi boleh mensintesis pertuturan berkualiti tinggi daripada pembesar suara tunggal atau berbilang, ia masih memerlukan data bersih berkualiti tinggi daripada studio rakaman, yang tidak boleh dicapai dengan data berskala besar yang dikikis daripada Internet memenuhi keperluan data dan akan membawa kepada kemerosotan prestasi model.
Disebabkan jumlah data latihan yang agak kecil, sistem TTS semasa masih menghadapi masalah keupayaan generalisasi yang lemah.
Di bawah tetapan tugasan sifar, untuk pembesar suara yang belum muncul dalam data latihan, persamaan dan keaslian pertuturan akan menurun dengan mendadak.
Untuk menyelesaikan masalah TTS tangkapan sifar, kerja sedia ada biasanya menggunakan kaedah seperti penyesuaian pembesar suara dan pengekodan pembesar suara, yang memerlukan penalaan halus tambahan dan ciri reka bentuk yang kompleks , atau kerja struktur yang berat.
Daripada mereka bentuk rangkaian yang kompleks dan khusus untuk masalah ini, memandangkan kejayaan mereka dalam sintesis teks, para penyelidik percaya penyelesaian muktamad adalah untuk melatih model dengan sebanyak mungkin data yang pelbagai.
Model VALL-E
Dalam bidang sintesis teks, data tidak berlabel berskala besar daripada Internet dimasukkan terus ke dalam model Apabila jumlah data latihan meningkat, prestasi model adalah juga sentiasa bertambah baik.
Penyelidik memindahkan idea ini ke bidang sintesis pertuturan Model VALL-E ialah rangka kerja TTS pertama berdasarkan model bahasa, menggunakan data pertuturan yang besar, pelbagai dan berbilang penutur.
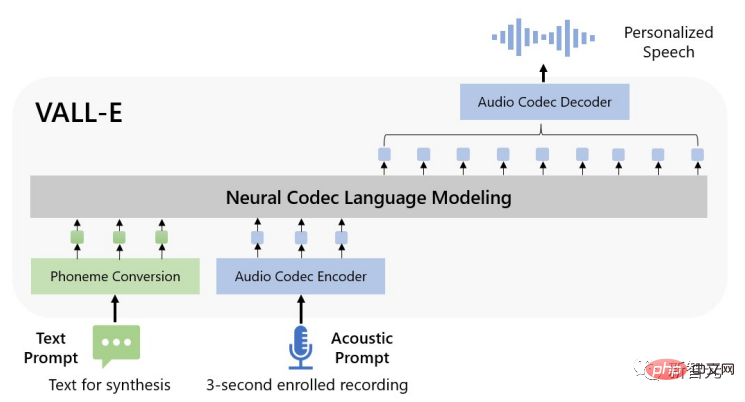
Untuk mensintesis pertuturan yang diperibadikan, model VALL-E menghasilkan token akustik yang sepadan berdasarkan token akustik dan gesaan fonem bagi rakaman 3 saat yang didaftarkan boleh mengehadkan penceramah dan maklumat kandungan.
Akhir sekali, token akustik yang dijana digunakan untuk mensintesis bentuk gelombang akhir dengan codec neural yang sepadan.
Token akustik diskret daripada model codec audio membolehkan TTS dianggap sebagai pemodelan bahasa codec bersyarat, jadi beberapa teknik model besar berasaskan petunjuk lanjutan (seperti GPT) boleh digunakan dalam tugasan TTS On.
Token akustik juga boleh menggunakan strategi pensampelan yang berbeza semasa proses inferens untuk menghasilkan hasil sintesis yang pelbagai dalam TTS.
Para penyelidik melatih VALL-E menggunakan set data LibriLight, yang terdiri daripada 60,000 jam pertuturan bahasa Inggeris dengan lebih daripada 7,000 pembesar suara unik. Data mentah adalah audio sahaja, jadi hanya model pengecaman pertuturan digunakan untuk menjana transkrip.
Berbanding dengan set data latihan TTS sebelumnya seperti LibriTTS, set data baharu yang disediakan dalam kertas kerja mengandungi lebih banyak pertuturan bising dan transkripsi yang tidak tepat, tetapi menyediakan pembesar suara dan daftar yang berbeza (prosodi ).
Para penyelidik percaya bahawa kaedah yang dicadangkan dalam artikel itu adalah teguh kepada bunyi bising dan boleh menggunakan data besar untuk mencapai umum yang baik.

Perlu diambil perhatian bahawa sistem TTS sedia ada sentiasa menggunakan berpuluh-puluh jam data pembesar suara satu bahasa atau ratusan jam data pembesar suara berbilang bahasa untuk latihan Lebih daripada ratusan kali lebih kecil daripada VALL-E.
Ringkasnya, VALL-E ialah kaedah model bahasa serba baharu untuk TTS, yang menggunakan pengekodan audio dan kod penyahkodan sebagai perwakilan perantaraan dan menggunakan sejumlah besar data berbeza untuk memberikan model keupayaan pembelajaran kontekstual yang berkuasa.
Penaakulan: Pembelajaran Dalam Konteks melalui Prompting
Pembelajaran dalam konteks ialah keupayaan menakjubkan model bahasa berasaskan teks yang boleh meramalkan label Input yang tidak kelihatan tanpa memerlukan kemas kini parameter tambahan.
Untuk TTS, jika model boleh mensintesis pertuturan berkualiti tinggi untuk pembesar suara ghaib tanpa penalaan halus, maka model tersebut dianggap mempunyai keupayaan pembelajaran kontekstual.
Walau bagaimanapun, sistem TTS sedia ada tidak mempunyai keupayaan pembelajaran dalam konteks yang kukuh kerana ia sama ada memerlukan penalaan halus tambahan atau mengalami degradasi yang ketara untuk pembesar suara yang tidak kelihatan.
Gesaan diperlukan untuk model bahasa mencapai pembelajaran konteks dalam situasi sifar pukulan.
Gesaan dan penaakulan yang direka oleh penyelidik adalah seperti berikut:
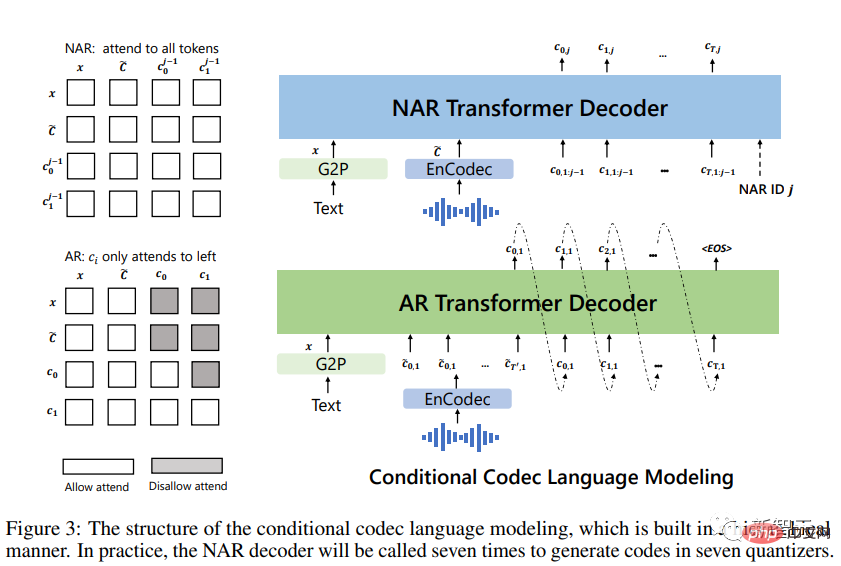
Mula-mula tukar teks ke dalam urutan fonem dan mengekodkan rakaman yang didaftarkan ke dalam matriks akustik untuk membentuk isyarat fonem dan isyarat akustik, kedua-duanya Digunakan dalam model AR dan NAR.
Untuk model AR, gunakan penyahkodan berasaskan pensampelan bersyarat pada pembayang, kerana carian pancaran boleh menyebabkan LM memasuki gelung tak terhingga di samping itu, kaedah berasaskan pensampelan boleh meningkatkan kepelbagaian output dengan ketara.
Untuk model NAR, gunakan penyahkodan tamak untuk memilih token dengan kebarangkalian tertinggi.
Akhir sekali, codec saraf digunakan untuk menjana bentuk gelombang yang dikondisikan pada lapan jujukan pengekodan.
Isyarat akustik mungkin tidak semestinya mempunyai hubungan semantik dengan pertuturan yang akan disintesis, jadi ia boleh dibahagikan kepada dua kes:
VALL-E: Matlamat utama adalah untuk penutur ghaib Menjana kandungan yang diberikan.
Input model ini ialah ayat teks, ucapan yang didaftarkan dan transkripsi yang sepadan dengannya. Tambahkan fonem transkripsi pertuturan yang didaftarkan sebagai isyarat fonem pada urutan fonem ayat yang diberikan, dan gunakan token akustik peringkat pertama pertuturan yang didaftarkan sebagai awalan akustik. Dengan isyarat fonem dan awalan akustik, VALL-E menjana token akustik untuk teks tertentu, mengklonkan suara pembesar suara.
VALL-E-continual: Menggunakan keseluruhan transkrip dan 3 saat pertama ujaran sebagai isyarat fonemik dan akustik, dan meminta model menjana kandungan berterusan.
Proses penaakulan adalah sama seperti menetapkan VALL-E, kecuali pertuturan yang didaftarkan dan pertuturan yang dijana adalah berterusan secara semantik.
Bahagian Eksperimen
Para penyelidik menilai VALL-E pada set data LibriSpeech dan VCTK, di mana semua pembesar suara yang diuji tidak muncul dalam korpus latihan.
VALL-E dengan ketara mengatasi sistem TTS tangkapan sifar tercanggih dari segi keaslian pertuturan dan persamaan pembesar suara, dengan Skor Pilihan Purata Perbandingan (CMOS) sebanyak +0.12 pada LibriSpeech dan persamaan +0.93 Darjah Min Skor Pilihan (SMOS).
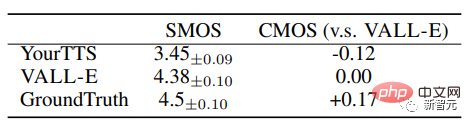
VALL-E juga melepasi sistem garis dasar dengan peningkatan prestasi +0.11 SMOS dan +0.23 CMOS pada VCTK, malah mencapai skor +0.04CMOS berbanding kebenaran asas, Tunjukkan bahawa pada VCTK, ucapan yang disintesis daripada pembesar suara ghaib adalah semula jadi seperti rakaman manusia.
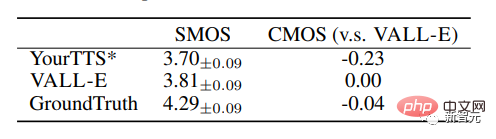
Tambahan pula, analisis kualitatif menunjukkan bahawa VALL-E mampu mensintesis output yang berbeza dengan 2 teks yang sama dan pembesar suara sasaran, yang mungkin memanfaatkan pseudo-data untuk tugasan pengecaman pertuturan yang dibuat.
Ia juga boleh didapati dalam eksperimen bahawa VALL-E boleh mengekalkan persekitaran bunyi (seperti gema) dan emosi yang didorong oleh bunyi (seperti kemarahan, dll.).
Risiko keselamatan
Jika teknologi berkuasa disalahgunakan, ia boleh menyebabkan kemudaratan kepada masyarakat Contohnya, ambang untuk penipuan telefon telah diturunkan semula!
Disebabkan potensi VALL-E untuk melakukan kerosakan dan penipuan, Microsoft tidak membuka kod atau antara muka VALL-E untuk ujian.
Sesetengah netizen berkongsi: Jika anda menghubungi pentadbir sistem, rakam beberapa perkataan yang mereka sebut "Hello", dan kemudian sintesis semula suara berdasarkan ayat ini "Hello, saya pentadbir sistem. "Suara saya ialah pengecam unik dan boleh disahkan dengan selamat "Saya selalu fikir ini adalah mustahil. Anda tidak dapat menyelesaikan tugas ini dengan begitu sedikit data. Sekarang nampaknya saya mungkin salah...
Dalam Pernyataan Etika akhir projek, penyelidik menyatakan bahawa "eksperimen dalam artikel ini adalah berdasarkan pengguna model sebagai penceramah sasaran dan diperolehi Dilakukan di bawah andaian persetujuan penceramah bagaimanapun, apabila model digeneralisasikan kepada pembesar suara yang tidak kelihatan, bahagian yang berkaitan harus disertakan dengan model penyuntingan pertuturan, termasuk protokol untuk memastikan bahawa penceramah bersetuju untuk melakukan pengubahsuaian dan sistem untuk mengesan pertuturan yang diedit. . "

Pengarang juga menyatakan dalam makalah bahawa memandangkan VALL-E boleh mensintesis pertuturan yang mengekalkan identiti penceramah, ia mungkin membawa potensi risiko penyalahgunaan model , Seperti memalsukan pengecaman suara atau meniru pembesar suara tertentu.
Untuk mengurangkan risiko ini, model pengesanan boleh dibina untuk membezakan sama ada klip audio disintesis oleh VALL-E. Semasa kami mengembangkan lagi model ini, kami juga akan mengamalkan prinsip AI Microsoft.
Rujukan:
https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
Atas ialah kandungan terperinci Ia hanya mengambil masa 3 saat untuk mencuri suara anda! Microsoft mengeluarkan model sintesis pertuturan VALL-E: Netizen menyatakan bahawa ambang untuk 'penipuan telefon' telah diturunkan semula. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI