
Rumah >Peranti teknologi >AI >GPU gred pengguna berjaya menjalankan model besar dengan 176 bilion parameter
GPU gred pengguna berjaya menjalankan model besar dengan 176 bilion parameter

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-28 12:19:061335semak imbas
Menjalankan model berskala besar pada GPU pengguna ialah cabaran berterusan untuk komuniti pembelajaran mesin.
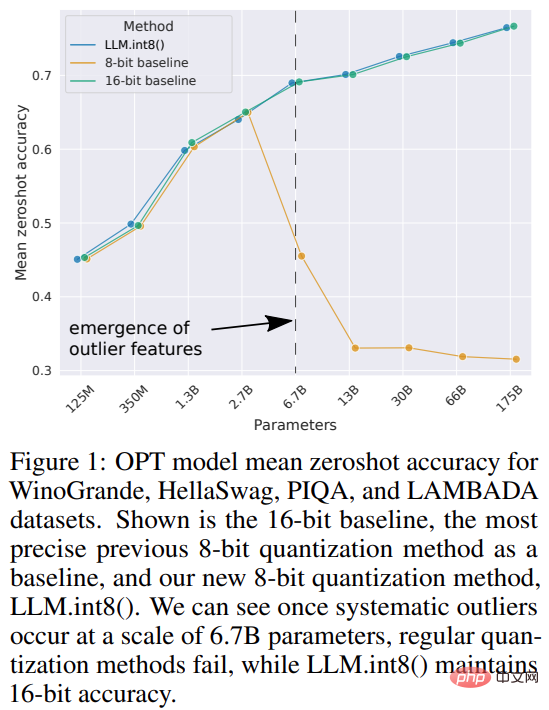
Saiz model bahasa semakin besar. PaLM mempunyai parameter 540B, OPT, GPT-3 dan BLOOM mempunyai parameter 176B Model masih bergerak dalam lebih besar arah tuju.

Model ini sukar dijalankan pada peranti yang mudah diakses. Sebagai contoh, BLOOM-176B perlu dijalankan pada lapan 80GB A100 GPU (~$15,000 setiap satu) untuk menyelesaikan tugas inferens, manakala penalaan halus BLOOM-176B memerlukan 72 GPU sedemikian. Model yang lebih besar seperti PaLM akan memerlukan lebih banyak sumber.
Kita perlu mencari cara untuk mengurangkan keperluan sumber model ini sambil mengekalkan prestasi model. Pelbagai teknik telah dibangunkan dalam bidang yang cuba mengurangkan saiz model, seperti kuantisasi dan penyulingan.
BLOOM telah dicipta tahun lepas oleh lebih 1,000 penyelidik sukarelawan dalam projek yang dipanggil "BigScience", yang dikendalikan oleh syarikat permulaan kecerdasan buatan Hugging Face dengan dana daripada kerajaan Perancis Pada 12 Julai tahun ini model BLOOM dikeluarkan secara rasmi.
Menggunakan inferens Int8 akan mengurangkan jejak memori model dengan ketara tanpa mengurangkan prestasi ramalan model. Berdasarkan ini, penyelidik dari University of Washington, Meta AI Research Institute (dahulunya Facebook AI Research) dan institusi lain bersama-sama menjalankan kajian dengan HuggingFace, cuba menjadikan BLOOM-176B terlatih berjalan pada GPU yang lebih sedikit, dan kaedah yang dicadangkan bersepadu sepenuhnya ke dalam HuggingFace Transformers.

- Alamat kertas: https://arxiv.org/pdf/2208.07339.pdf
- Alamat Github: https://github.com/timdettmers/bitsandbytes
Penyelidikan ini mencadangkan proses pengkuantitian Int8 berskala bilion pertama untuk pengubah, yang tidak menjejaskan prestasi Penaakulan model. Ia boleh memuatkan pengubah parameter 175B dengan pemberat 16-bit atau 32-bit dan menukar lapisan unjuran suapan dan perhatian kepada 8-bit. Ia memotong separuh memori yang diperlukan untuk inferens sambil mengekalkan prestasi ketepatan penuh.
Kajian itu menamakan gabungan pengkuantitian vektor dan penguraian ketepatan campuran LLM.int8(). Percubaan menunjukkan bahawa dengan menggunakan LLM.int8(), adalah mungkin untuk melakukan inferens dengan LLM sehingga 175B parameter pada GPU pengguna tanpa penurunan prestasi. Pendekatan ini bukan sahaja memberi penerangan baharu tentang kesan outlier pada prestasi model, tetapi juga membolehkan untuk kali pertama menggunakan model yang sangat besar, seperti OPT-175B/BLOOM, pada pelayan tunggal dengan GPU gred pengguna.
Pengenalan Kaedah
Saiz model pembelajaran mesin bergantung pada bilangan parameter dan ketepatannya, biasanya float32, float16 atau bfloat16 satu. float32 (FP32) bermaksud perwakilan IEEE 32-bit floating-point standard, dan pelbagai nombor titik terapung boleh diwakili menggunakan jenis data ini. FP32 menyimpan 8 bit untuk "eksponen", 23 bit untuk "mantissa", dan 1 bit untuk tanda nombor. Selain itu, kebanyakan perkakasan menyokong operasi dan arahan FP32.
Manakala float16 (FP16) menyimpan 5 bit untuk eksponen dan 10 bit untuk mantissa. Ini menjadikan julat nombor FP16 yang boleh diwakili jauh lebih rendah daripada FP32, mendedahkannya kepada risiko limpahan (cuba mewakili nombor yang sangat besar) dan aliran bawah (mewakili jumlah yang sangat kecil).
Apabila limpahan berlaku, anda mendapat hasil NaN (bukan nombor), dan jika anda melakukan pengiraan berurutan seperti dalam rangkaian saraf, banyak kerja akan runtuh. bfloat16 (BF16) mengelakkan masalah ini. BF16 menyimpan 8 bit untuk eksponen dan 7 bit untuk perpuluhan, bermakna BF16 boleh mengekalkan julat dinamik yang sama seperti FP32.
Sebaik-baiknya, latihan dan inferens harus dilakukan dalam FP32, tetapi ia lebih perlahan daripada FP16/BF16, jadi gunakan ketepatan campuran untuk meningkatkan kelajuan latihan. Tetapi dalam amalan, pemberat separuh ketepatan juga memberikan kualiti yang serupa dengan FP32 semasa inferens. Ini bermakna kita boleh menggunakan separuh berat ketepatan dan menggunakan separuh GPU untuk mencapai hasil yang sama.
Tetapi bagaimana jika kita boleh menggunakan jenis data yang berbeza untuk menyimpan pemberat ini dengan memori yang kurang? Kaedah yang dipanggil kuantisasi telah digunakan secara meluas dalam pembelajaran mendalam.
Kajian ini mula-mula menggunakan 2-bait BF16/FP16 separuh ketepatan dan bukannya 4-bait FP32 ketepatan dalam eksperimen, mencapai keputusan inferens yang hampir sama. Dengan cara ini, model dikurangkan separuh. Tetapi jika anda mengurangkan lagi nombor ini, ketepatan akan berkurangan, dan kualiti inferens akan menurun dengan mendadak.
Untuk mengimbangi ini, kajian ini memperkenalkan kuantiti 8bit. Kaedah ini menggunakan satu perempat daripada ketepatan dan oleh itu hanya memerlukan satu perempat daripada saiz model, tetapi ini tidak dicapai dengan mengeluarkan separuh lagi bit.
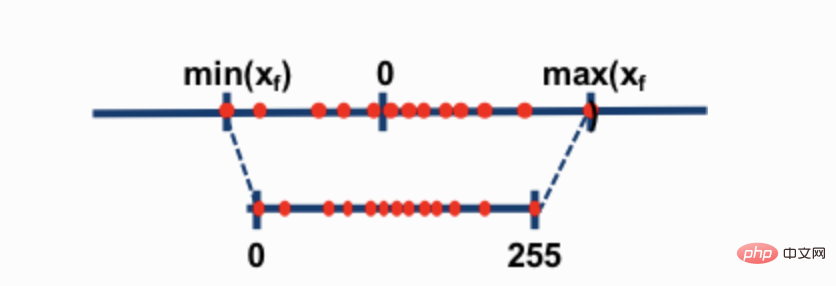
Dua teknik pengkuantitian 8-bit yang paling biasa ialah pengkuantitian titik sifar dan pengkuantitian absmax (maksimum mutlak). Kedua-dua kaedah memetakan nilai titik terapung kepada nilai int8 (1 bait) yang lebih padat.
Sebagai contoh, dalam pengkuantitian titik sifar, jika julat data ialah -1.0-1.0 dan dikuantisasi kepada -127-127, faktor pengembangan ialah 127. Pada faktor pengembangan ini, contohnya nilai 0.3 akan dikembangkan kepada 0.3*127 = 38.1. Kuantiti biasanya melibatkan pembundaran, yang memberi kita 38. Jika kita membalikkan ini, kita mendapat 38/127=0.2992 - ralat kuantiti 0.008 dalam contoh ini. Ralat yang kelihatan kecil ini cenderung terkumpul dan berkembang apabila ia merebak melalui lapisan model dan menyebabkan kemerosotan prestasi.
Walaupun teknik ini mampu mengukur model pembelajaran mendalam, teknik ini sering mengakibatkan ketepatan model yang berkurangan. Tetapi LLM.int8(), disepadukan ke dalam perpustakaan Hugging Face Transformers dan Accelerate, ialah teknik pertama yang tidak merendahkan prestasi walaupun untuk model besar dengan parameter 176B (seperti BLOOM).
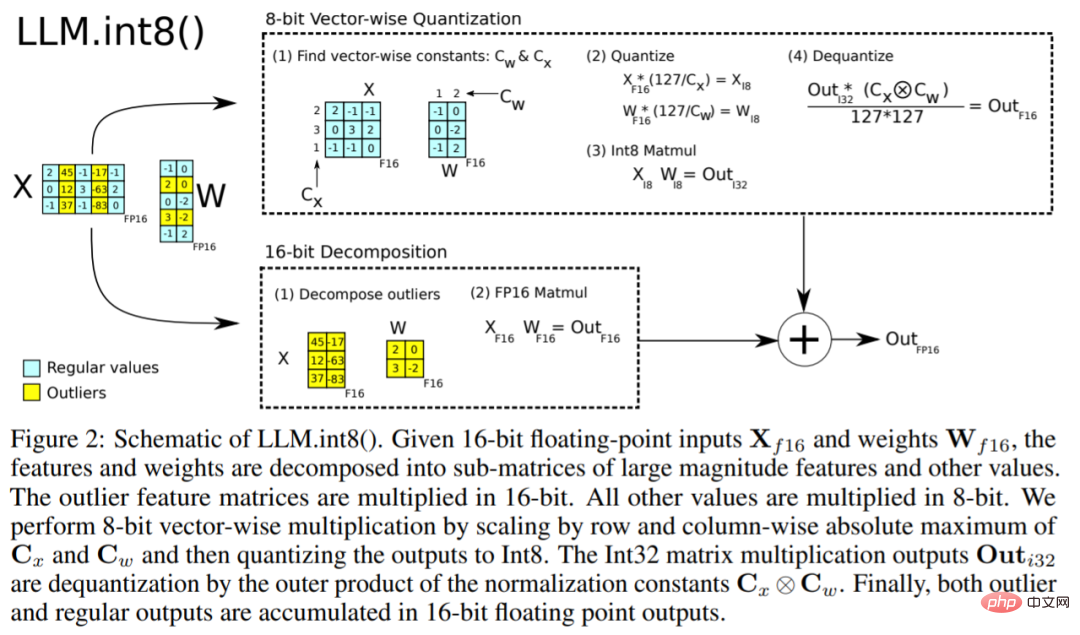
Algoritma LLM.int8() boleh dijelaskan seperti ini Pada asasnya, LLM.int8() cuba melengkapkan pengiraan pendaraban matriks dalam tiga langkah:
- Daripada keadaan tersembunyi input. , Ekstrak outlier (iaitu nilai lebih besar daripada ambang tertentu) mengikut lajur.
- Pendaraban matriks bagi outlier dalam FP16 dengan bukan outlier dalam int8.
- Dequantize bukan outlier dalam FP16 dan tambah outlier dan bukan outlier untuk mendapatkan hasil yang lengkap.
Langkah-langkah ini boleh diringkaskan dalam animasi di bawah:

Akhir sekali, kajian Juga tertumpu pada soalan: Adakah ia lebih pantas daripada model asli?
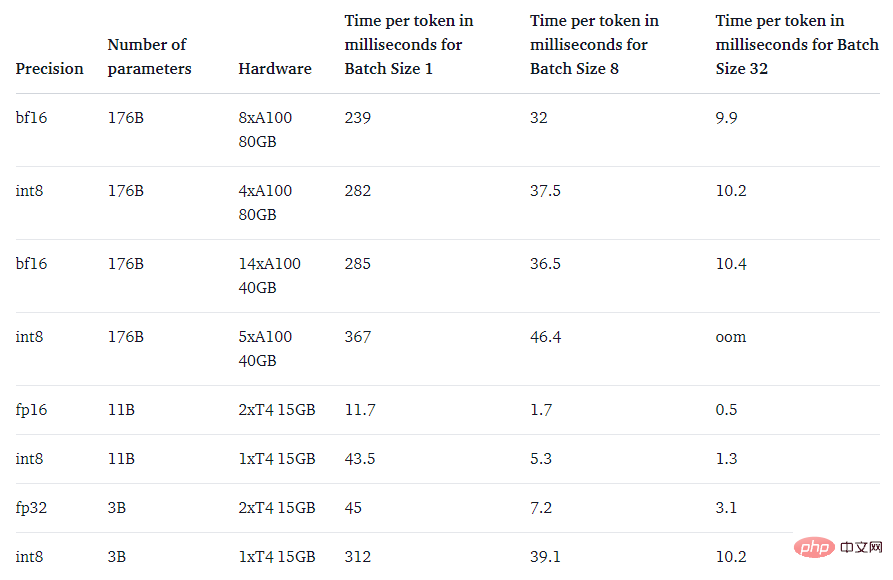
Tujuan utama kaedah LLM.int8() adalah untuk menjadikan model besar lebih mudah diakses tanpa mengurangkan prestasi. Walau bagaimanapun, jika ia sangat perlahan, ia tidak begitu berguna. Pasukan penyelidik menanda aras kelajuan penjanaan berbilang model dan mendapati bahawa BLOOM-176B dengan LLM.int8() adalah lebih kurang 15% hingga 23% lebih perlahan daripada versi fp16 - yang boleh diterima sepenuhnya. Dan model yang lebih kecil seperti T5-3B dan T5-11B mempunyai nyahpecutan yang lebih besar. Pasukan penyelidik sedang berusaha untuk meningkatkan kelajuan model kecil ini.
Atas ialah kandungan terperinci GPU gred pengguna berjaya menjalankan model besar dengan 176 bilion parameter. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI