
Rumah >Peranti teknologi >AI >Penyelidikan menunjukkan: Sumber data kekal sebagai hambatan utama untuk AI
Penyelidikan menunjukkan: Sumber data kekal sebagai hambatan utama untuk AI

- 王林ke hadapan
- 2023-04-28 11:49:061259semak imbas
Data adalah nadi kepada mesin. Tanpa itu, anda tidak boleh membina apa-apa yang berkaitan dengan AI. Banyak organisasi masih bergelut untuk mendapatkan data yang baik dan bersih untuk mengekalkan AI dan inisiatif pembelajaran mesin mereka, menurut laporan Keadaan AI dan Pembelajaran Mesin Appen yang dikeluarkan minggu ini.
Menurut tinjauan Appen tentang kecerdasan buatan, antara empat peringkat kecerdasan buatan - perolehan data, penyediaan data, latihan dan penggunaan model, dan penilaian model berpandukan manusia, perolehan data menggunakan paling banyak sumber dan kos yang paling banyak. Yang paling lama dan paling mencabar. 504 pemimpin perniagaan dan pakar teknologi.
Secara purata, pemerolehan data menggunakan 34% daripada belanjawan AI organisasi, manakala penyediaan data dan ujian model dan penggunaan setiap menyumbang 24%, dan penilaian model 15%, menurut tinjauan Appen, yang dijalankan oleh Harris Tinjauan telah dijalankan dan termasuk pembuat keputusan IT, pemimpin dan pengurus perniagaan, dan pengamal teknologi dari Amerika Syarikat, United Kingdom, Ireland dan Jerman.
Dari segi masa, perolehan data menggunakan kira-kira 26% masa organisasi, manakala penyediaan data dan ujian model, penggunaan dan penilaian model masing-masing menyumbang 24% dan 23%. Akhir sekali, 42% ahli teknologi menganggap penyumberan data sebagai peringkat paling mencabar dalam kitaran hayat AI, berbanding penilaian model (41%), ujian dan penggunaan model (38%) dan penyediaan data (34%).
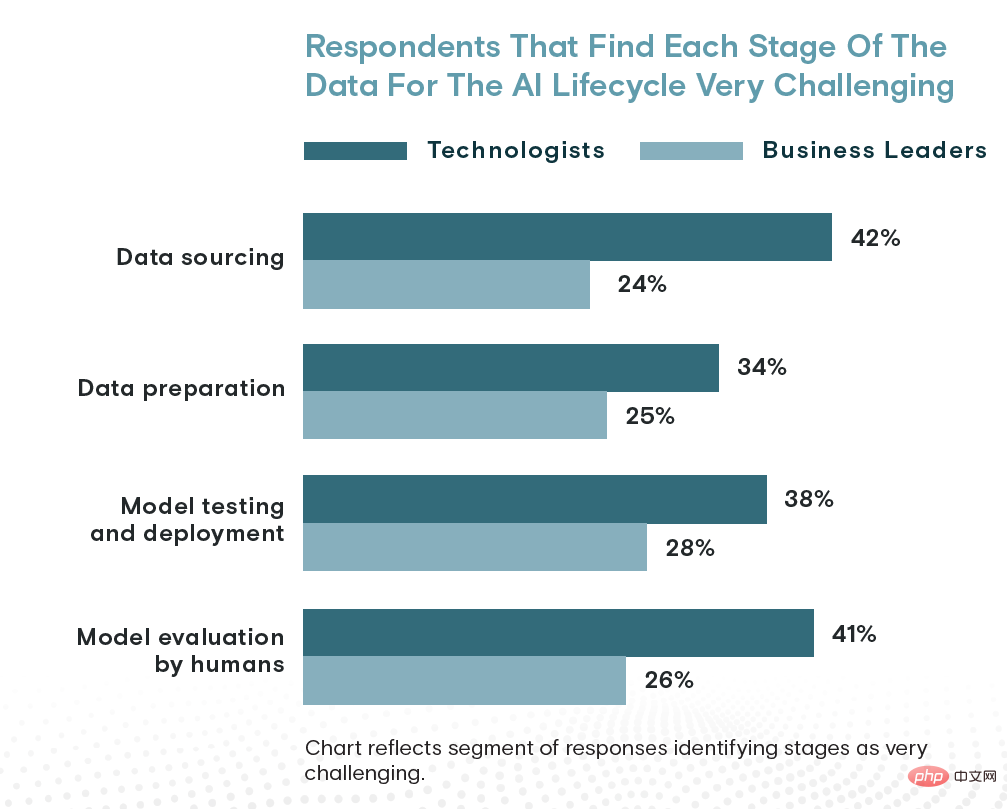
Menurut pakar teknologi, penyumberan data adalah cabaran terbesar yang dihadapi oleh kecerdasan buatan. Tetapi pemimpin perniagaan melihat perkara secara berbeza...
Walaupun menghadapi cabaran, organisasi berusaha untuk melakukannya. Menurut Appen, empat perlima (81%) responden berkata mereka yakin mereka mempunyai data yang mencukupi untuk menyokong inisiatif AI mereka. Mungkin kunci kejayaan ini: Sebilangan besar (88%) sedang menambah data mereka dengan menggunakan pembekal data latihan AI luaran seperti Appen.
Walau bagaimanapun, ketepatan data diragui. Appen mendapati hanya 20% responden melaporkan ketepatan data melebihi 80%. Hanya 6% (kira-kira 1 dalam 10) mengatakan data mereka adalah 90% tepat atau lebih baik. Dalam erti kata lain, satu daripada lima data mengandungi ralat untuk lebih daripada 80% organisasi.
Dengan mengambil kira perkara ini, mungkin tidak menghairankan bahawa hampir separuh (46%) responden bersetuju bahawa ketepatan data adalah penting "tetapi kami boleh membetulkannya," menurut tinjauan Appen. Hanya 2% berkata ketepatan data bukanlah keperluan besar, manakala 51% bersetuju ia adalah keperluan kritikal.
Nampaknya pandangan Appen CTO Wilson Pang tentang kepentingan kualiti data sepadan dengan 48% pelanggan yang percaya kualiti data tidak penting.
"Ketepatan data adalah penting untuk kejayaan model AI dan ML, kerana data yang kaya dengan kualiti menghasilkan output model yang lebih baik dan pemprosesan yang konsisten serta membuat keputusan," kata Pang dalam laporan itu. “Untuk mencapai hasil yang baik, set data mestilah tepat, komprehensif dan berskala.”
Lebih 90% responden Appen berkata mereka menggunakan data berlabel pra-label
Pang memberitahu dalam temu bual baru-baru ini bahawa peningkatan pembelajaran mendalam dan AI berpusatkan data telah mengubah motivasi kejayaan AI daripada pemodelan sains data dan pembelajaran mesin yang baik kepada pengumpulan, pengurusan dan penandaan data yang baik. Ini benar terutamanya untuk teknik pembelajaran pemindahan hari ini, di mana pengamal AI melangkah ke atas model bahasa pra-terlatih atau penglihatan komputer yang besar dan melatih semula set lapisan kecil dengan data mereka sendiri.
Data yang lebih baik juga boleh membantu menghalang berat sebelah yang tidak perlu daripada menjalar ke dalam model AI dan selalunya menghalang hasil AI yang tidak diingini. Ini benar terutamanya untuk model bahasa besar, kata Ilia Shifrin, pengarah kanan AI di Appen.
"Syarikat menghadapi satu lagi cabaran dengan peningkatan model bahasa besar (LLM) yang dilatih mengenai data perangkak web berbilang bahasa," kata Shifrin dalam laporan itu. "Model ini sering mempamerkan tingkah laku yang tidak baik disebabkan oleh banyaknya bahasa toksik, serta berat sebelah kaum, jantina dan agama dalam korpus latihan."
Bias dalam data web menimbulkan beberapa isu perit, walaupun terdapat beberapa kaedah penyelesaian (mengubah rejimen latihan, menapis data latihan dan output model, dan belajar daripada maklum balas dan ujian manusia), tetapi lebih banyak penyelidikan diperlukan untuk mewujudkan piawaian yang baik untuk penanda aras LLM dan kaedah penilaian model, kata Shifrin.
Menurut Appen, pengurusan data kekal sebagai halangan terbesar yang dihadapi AI. Tinjauan mendapati bahawa 41% orang dalam kitaran AI percaya pengurusan data adalah kesesakan terbesar. Kekurangan data menduduki tempat keempat, dengan 30% menyebutnya sebagai penghalang terbesar kepada kejayaan AI.
Tetapi ada berita baik: masa yang diluangkan oleh organisasi untuk mengurus dan menyediakan data semakin menurun. Tahun ini, ia hanya melebihi 47%, berbanding 53% dalam laporan tahun lepas, kata Appen.
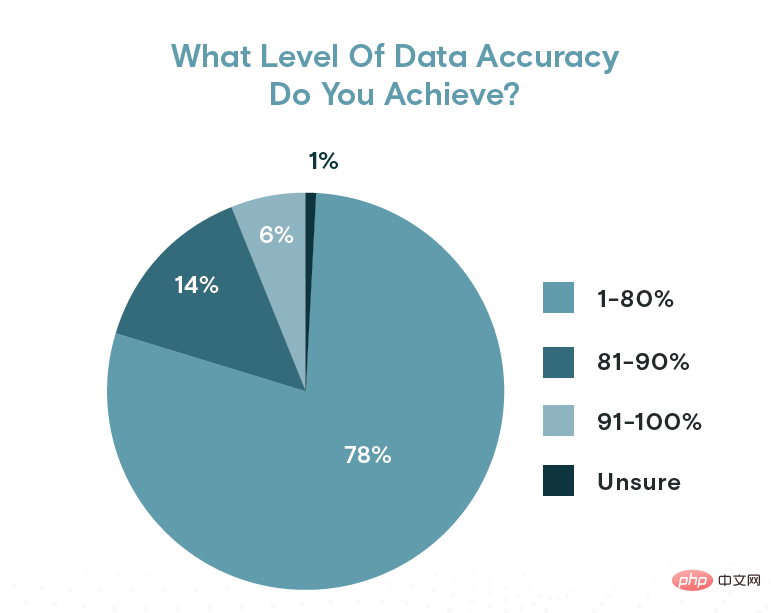
Tahap ketepatan data mungkin tidak setinggi yang diingini oleh sesetengah organisasi
“Majoriti responden menggunakan pembekal data luaran dan boleh disimpulkan bahawa dengan penyumberan luar penyumberan dan penyediaan data, saintis data menjimatkan wang pengurusan yang betul, masa yang diperlukan untuk membersihkan dan melabel data,” kata syarikat pelabelan data itu.
Walau bagaimanapun, berdasarkan kadar ralat yang agak tinggi dalam data, mungkin organisasi tidak seharusnya mengecilkan proses penyumberan dan penyediaan data mereka (sama ada dalaman atau luaran). Terdapat banyak keperluan yang bersaing dalam membina dan menyelenggara proses AI—mengupah profesional data yang berkelayakan merupakan satu lagi keperluan utama yang dikenal pasti oleh Appen. Walau bagaimanapun, sehingga kemajuan ketara dicapai dalam pengurusan data, organisasi harus terus memberi tekanan kepada pasukan mereka untuk terus memacu kepentingan kualiti data.
Kaji selidik itu juga mendapati bahawa 93% organisasi sangat atau agak bersetuju bahawa AI beretika harus menjadi "asas" projek AI. Ketua Pegawai Eksekutif Appen Mark Brayan berkata ia adalah permulaan yang baik, tetapi masih banyak lagi kerja yang perlu dilakukan. "Masalahnya ialah ramai orang menghadapi cabaran untuk cuba membina AI yang hebat dengan set data yang lemah, yang mewujudkan halangan penting untuk mencapai matlamat mereka," kata Brayan dalam kenyataan akhbar.
Menurut laporan Appen, data dalaman yang dikumpul tersuai kekal sebagai majoriti set data organisasi yang digunakan untuk AI, mencakupi 38% hingga 42% daripada data. Data sintetik menunjukkan prestasi yang sangat mengejutkan, mencakupi 24% hingga 38% daripada data organisasi, manakala data pra-label (biasanya diperoleh daripada penyedia perkhidmatan data) menyumbang 23% hingga 31% daripada data.
Data sintetik khususnya berpotensi untuk mengurangkan kejadian berat sebelah dalam projek AI yang sensitif, dengan 97% responden Appen mengatakan mereka menggunakan data sintetik "semasa membangunkan set data latihan inklusif."
Penemuan menarik lain daripada laporan itu termasuk:
- 77% organisasi melatih semula model mereka setiap bulan atau suku tahunan
- 55% organisasi AS mendakwa Mereka mendahului; pesaing, berbanding 44% di Eropah;
- 42% organisasi melaporkan pelancaran AI yang "berluas", berbanding 51% dalam laporan Kecerdasan Buatan 2021
- 7% organisasi melaporkan belanjawan AI melebihi $5 juta, berbanding 9% tahun lepas.
Atas ialah kandungan terperinci Penyelidikan menunjukkan: Sumber data kekal sebagai hambatan utama untuk AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI