
Rumah >Peranti teknologi >AI >Bacaan Kelajuan Kuantum Benar: Menembusi had GPT-4 yang hanya boleh memahami 50 halaman teks pada satu masa, penyelidikan baharu berkembang kepada berjuta-juta token
Bacaan Kelajuan Kuantum Benar: Menembusi had GPT-4 yang hanya boleh memahami 50 halaman teks pada satu masa, penyelidikan baharu berkembang kepada berjuta-juta token

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-28 10:37:241104semak imbas
Lebih sebulan yang lalu, GPT-4 OpenAI telah dikeluarkan. Selain pelbagai demonstrasi visual yang sangat baik, ia juga melaksanakan kemas kini penting: ia boleh mengendalikan token konteks yang panjangnya 8k secara lalai, tetapi boleh sehingga 32K (kira-kira 50 halaman teks). Ini bermakna apabila bertanya soalan kepada GPT-4, kita boleh memasukkan teks yang lebih panjang daripada sebelumnya. Ini sangat meluaskan senario aplikasi GPT-4 dan boleh mengendalikan perbualan panjang, teks panjang serta carian dan analisis fail dengan lebih baik.
Walau bagaimanapun, rekod ini telah dipecahkan dengan cepat: CoLT5 daripada Google Research mengembangkan panjang token konteks yang boleh dikendalikan oleh model kepada 64k .
Penerobosan sedemikian bukanlah mudah, kerana model yang menggunakan seni bina Transformer ini semuanya menghadapi masalah: Transformer memproses dokumen panjang secara pengiraan sangat mahal, kerana kos perhatian meningkat dengan input Panjangnya berkembang secara kuadratik, menjadikannya semakin sukar untuk menggunakan model besar pada input yang lebih panjang.
Walaupun begitu, penyelidik masih membuat penemuan ke arah ini. Beberapa hari yang lalu, kajian daripada timbunan teknologi AI perbualan sumber terbuka DeepPavlov dan institusi lain menunjukkan bahawa: Dengan menggunakan seni bina yang dipanggil Recurrent Memory Transformer (RMT), mereka boleh meningkatkan panjang konteks berkesan BERT model. kepada 2 juta token (kira-kira bersamaan dengan 3,200 halaman teks mengikut kaedah pengiraan OpenAI), sambil mengekalkan ketepatan perolehan memori yang tinggi (Nota: Recurrent Memory Transformer telah dicadangkan oleh Aydar Bulatov et al. dalam kertas di kaedah NeurIPS 2022) . Kaedah baharu ini membolehkan penyimpanan dan pemprosesan maklumat tempatan dan global, dan aliran maklumat antara segmen jujukan input melalui penggunaan berulang.

Penulis menyatakan bahawa dengan menggunakan kaedah berasaskan token mudah yang diperkenalkan oleh Bulatov et al Mekanisme memori Memory Transformer, mereka boleh menggabungkan RMT dengan model Transformer terlatih seperti BERT, dan menggunakan GPU Nvidia GTX 1080Ti untuk melaksanakan perhatian penuh dan operasi ketepatan penuh pada jujukan lebih daripada 1 juta token.

Alamat kertas: https://arxiv.org/pdf/2304.11062.pdf
Namun, sesetengah orang telah mengingatkan bahawa ini bukan "makan tengah hari percuma" sebenar. daripada. Oleh itu, ia belum lagi revolusi, tetapi ia mungkin menjadi asas kepada paradigma seterusnya (token mungkin panjang tidak terhingga).
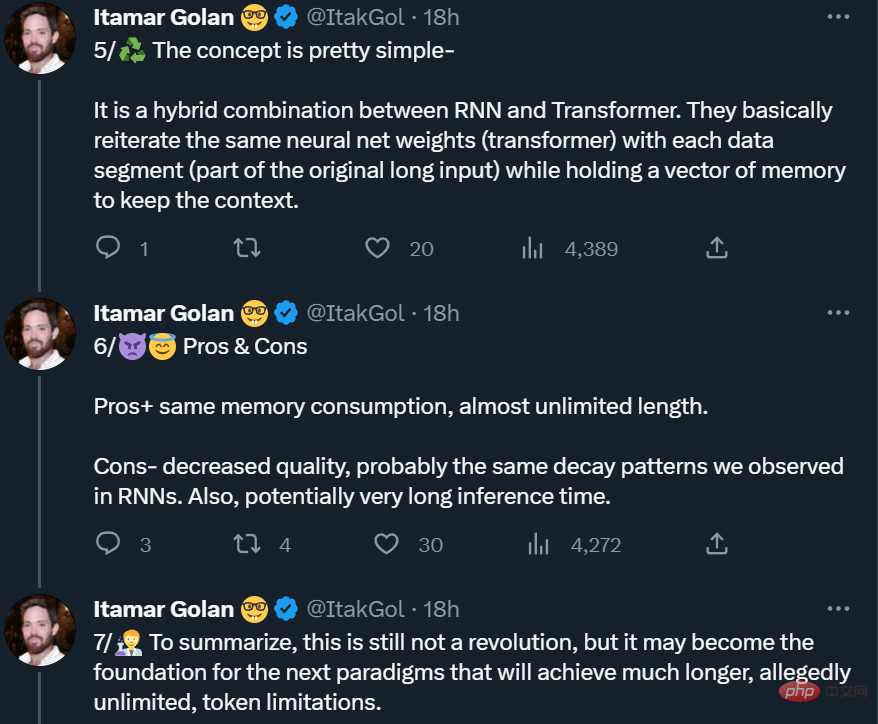
Recurrent Memory Transformer
Kajian ini mengamalkan kaedah Recurrent Memory Transformer yang dicadangkan oleh Bulatov et al. pada 2022 (RMT) dan tukar kepada kaedah pasang dan main Mekanisme utama adalah seperti yang ditunjukkan dalam rajah di bawah:
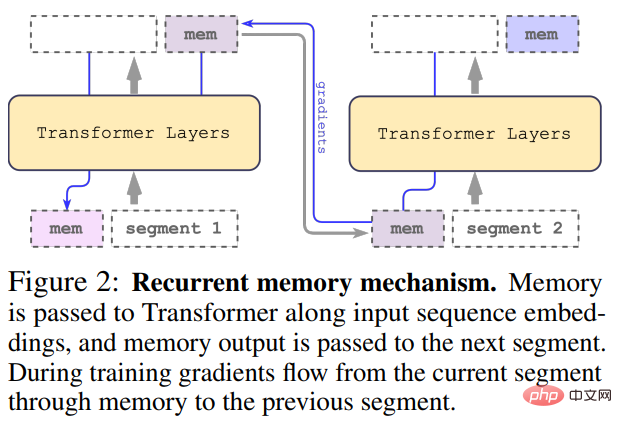
Input panjang dibahagikan kepada berbilang segmen dan vektor memori ditambahkan sebelum pembenaman dan diproses segmen pertama bersama-sama dengan token segmen. Untuk model pengekod tulen seperti BERT, memori hanya ditambah sekali pada permulaan segmen, tidak seperti (Bulatov et al., 2022), di mana model penyahkod tulen membahagikan memori kepada bahagian baca dan tulis. Untuk langkah masa τ dan segmen
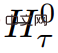
, gelung dilaksanakan seperti berikut:

Di mana, N ialah bilangan lapisan Transformer. Selepas penyebaran ke hadapan,
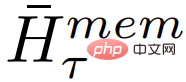
mengandungi token ingatan yang dikemas kini bagi segmen τ.
Segmen jujukan input diproses mengikut tertib. Untuk mendayakan sambungan berulang, kajian menghantar output token memori daripada segmen semasa ke input segmen seterusnya:
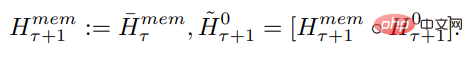
Kedua-dua memori dan gelung dalam RMT hanya berdasarkan token memori global. Ini membolehkan Transformer tulang belakang kekal tidak berubah, menjadikan keupayaan peningkatan memori RMT serasi dengan mana-mana model Transformer.
Kecekapan pengiraan
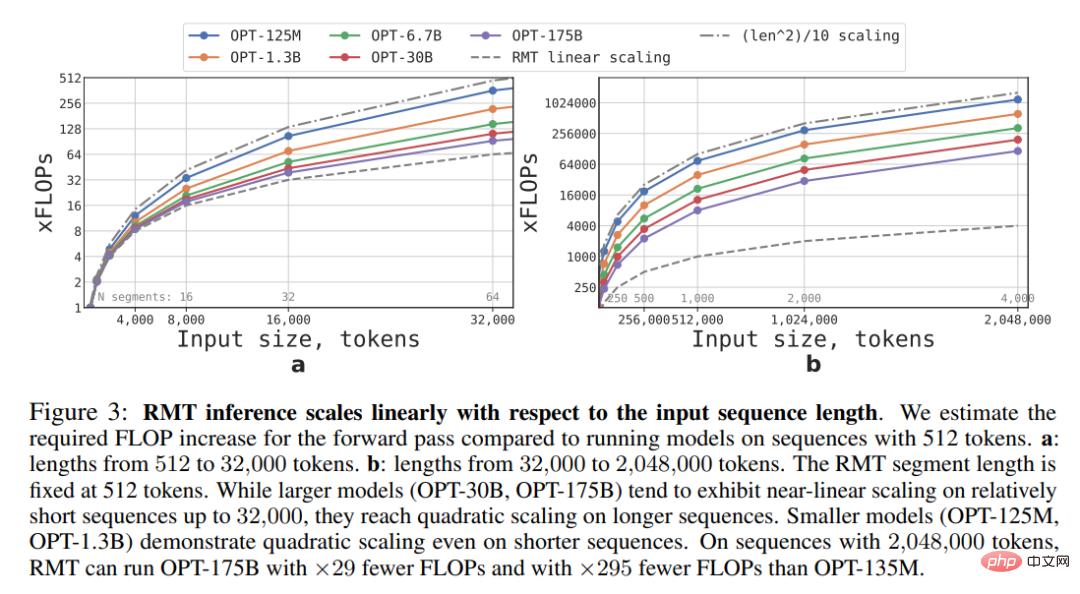
Kajian ini menganggarkan FLOP yang diperlukan untuk model RMT dan Transformer dengan saiz dan panjang jujukan yang berbeza.
Seperti yang ditunjukkan dalam Rajah 3 di bawah, jika panjang segmen ditetapkan, RMT boleh menskala secara linear untuk sebarang saiz model. Kajian ini mencapai penskalaan linear dengan membahagikan jujukan input kepada segmen dan mengira matriks perhatian lengkap hanya dalam sempadan segmen.
Disebabkan beban pengiraan yang berat pada lapisan FFN, model Transformer yang lebih besar cenderung mempamerkan penskalaan kuadratik yang lebih perlahan dengan panjang jujukan. Walau bagaimanapun, untuk jujukan yang sangat panjang lebih besar daripada 32000, ia kembali kepada pengembangan kuadratik. Untuk jujukan dengan lebih daripada satu segmen (> 512 dalam kajian ini), RMT memerlukan lebih sedikit FLOP daripada model akiklik dan boleh mengurangkan bilangan FLOP sehingga 295 kali. RMT memberikan pengurangan relatif yang lebih besar dalam FLOP untuk model yang lebih kecil, tetapi pengurangan 29x dalam FLOP untuk model OPT-175B adalah ketara dari segi mutlak.
Tugas Ingatan
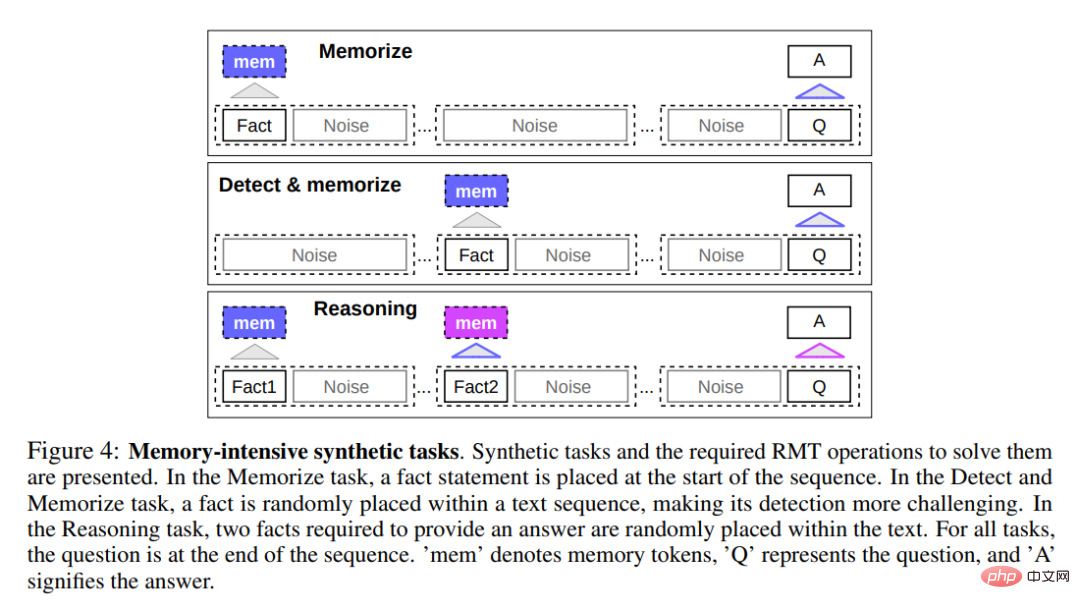
Untuk menguji keupayaan ingatan, kajian itu membina set data sintetik yang memerlukan hafalan fakta mudah dan penaakulan asas. Input tugasan terdiri daripada satu atau lebih fakta dan soalan yang hanya boleh dijawab menggunakan semua fakta. Untuk meningkatkan kesukaran tugasan, kajian juga menambah teks bahasa semula jadi yang tidak berkaitan dengan soalan atau jawapan untuk bertindak sebagai bunyi bising, jadi model ditugaskan untuk memisahkan fakta daripada teks yang tidak berkaitan dan menggunakan fakta untuk menjawab soalan.

Memori fakta
Item pertama tugasnya adalah untuk menguji keupayaan RMT untuk menulis dan menyimpan maklumat dalam ingatan untuk jangka masa yang lama, seperti yang ditunjukkan di bahagian atas Rajah 4 di bawah. Dalam kes yang paling mudah, fakta cenderung berada di awal input, dan soalan sentiasa di penghujung. Jumlah teks yang tidak berkaitan antara soalan dan jawapan secara beransur-ansur meningkat ke tahap di mana keseluruhan input tidak sesuai dengan input model tunggal.

Pengesanan fakta dan ingatan
Pengesanan fakta meningkatkan kesukaran tugasan dengan mengalihkan fakta ke kedudukan rawak dalam input, seperti yang ditunjukkan di tengah-tengah Rajah 4 di atas. Ini memerlukan model untuk terlebih dahulu membezakan fakta daripada teks yang tidak berkaitan, menulis fakta ke dalam ingatan, dan kemudian menggunakannya untuk menjawab soalan pada akhir.
Menggunakan fakta yang dihafal untuk menaakul
Satu lagi operasi ingatan ialah menaakul menggunakan fakta yang dihafal dan konteks semasa. Untuk menilai fungsi ini, penyelidik menggunakan tugas yang lebih kompleks di mana dua fakta dijana dan diletakkan dalam urutan input, seperti yang ditunjukkan di bahagian bawah Rajah 4 di atas. Soalan yang ditanya pada akhir urutan diterangkan sedemikian rupa sehingga fakta sewenang-wenangnya mesti digunakan untuk menjawab soalan dengan betul.

Hasil eksperimen
Para penyelidik menggunakan 4 hingga 8 GPU NVIDIA 1080ti untuk melatih dan menilai model . Untuk urutan yang lebih panjang, mereka menggunakan NVIDIA A100 40GB tunggal untuk mempercepatkan penilaian.
Pembelajaran Kursus
Para penyelidik mendapati bahawa menggunakan pelan latihan boleh meningkatkan ketepatan dan kestabilan penyelesaian dengan ketara seks. Pada mulanya, RMT dilatih pada versi tugasan yang lebih pendek dan meningkatkan panjang tugasan dengan menambah segmen lain apabila latihan berkumpul. Proses pembelajaran kursus diteruskan sehingga panjang input yang diperlukan dicapai.
Dalam percubaan, penyelidik mula-mula memulakan dengan urutan yang sesuai untuk satu segmen. Saiz segmen sebenar ialah 499, tetapi disebabkan oleh 3 token khas BERT dan 10 ruang letak memori yang dikekalkan daripada input model, saiznya ialah 512. Mereka ambil perhatian bahawa selepas latihan mengenai tugas yang lebih pendek, RMT lebih mudah untuk menyelesaikan versi tugasan yang lebih panjang, terima kasih kepada fakta bahawa ia menggunakan lebih sedikit langkah latihan untuk menumpu kepada penyelesaian yang sempurna.
Keupayaan ekstrapolasi
Apakah keupayaan generalisasi RMT kepada panjang jujukan yang berbeza? Untuk menjawab soalan ini, penyelidik menilai model yang dilatih pada bilangan segmen yang berbeza untuk menyelesaikan tugas yang lebih panjang, seperti yang ditunjukkan dalam Rajah 5 di bawah.
Mereka memerhatikan bahawa model cenderung menunjukkan prestasi yang lebih baik pada tugasan yang lebih pendek, dengan satu-satunya pengecualian ialah tugas inferens segmen tunggal, yang menjadi Sangat sukar untuk diselesaikan. Satu penjelasan yang mungkin ialah kerana saiz tugasan melebihi satu segmen, model tidak lagi "menjangkakan" masalah dalam segmen pertama, mengakibatkan penurunan kualiti.
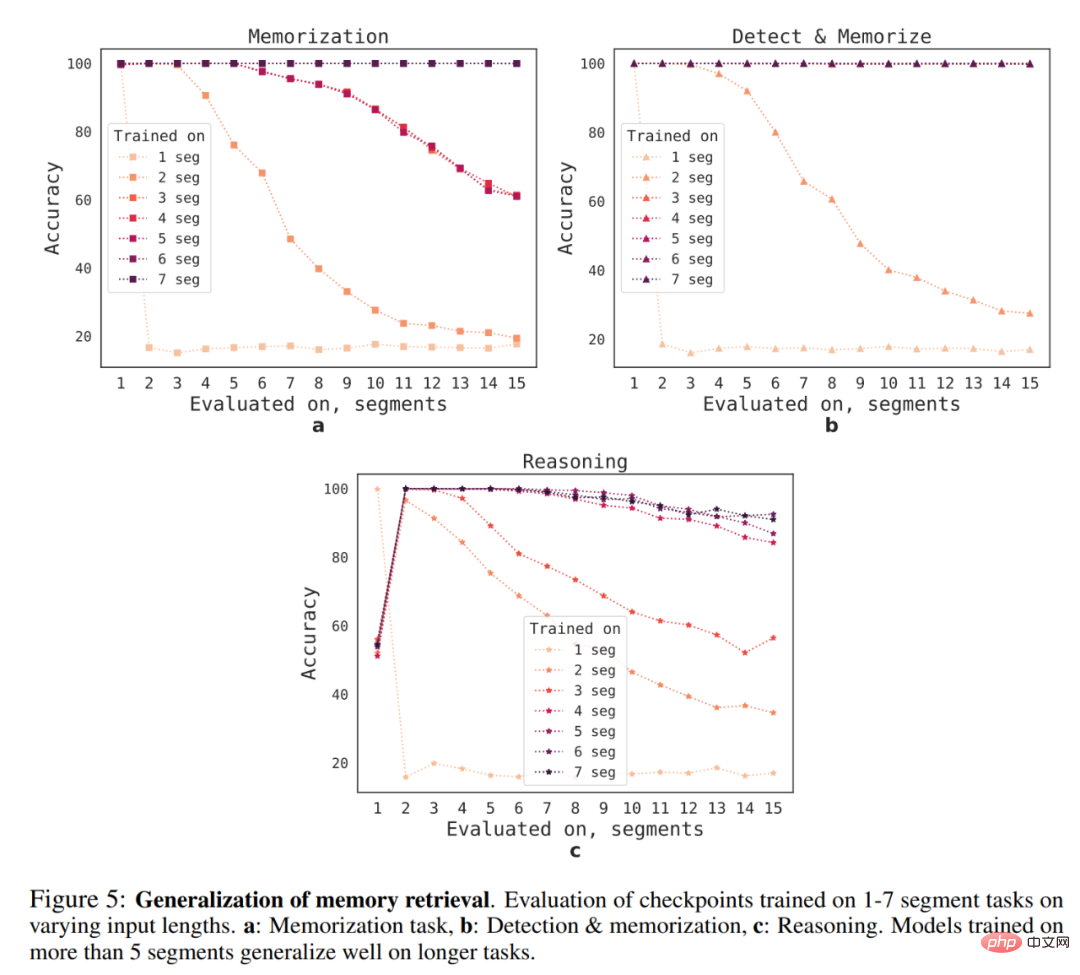
Menariknya, keupayaan RMT untuk membuat generalisasi kepada urutan yang lebih panjang juga muncul apabila bilangan segmen latihan meningkat. Selepas latihan pada 5 atau lebih segmen, RMT boleh membuat generalisasi hampir sempurna kepada tugasan dua kali lebih lama.
Untuk menguji batasan generalisasi, penyelidik meningkatkan saiz tugas pengesahan kepada 4096 segmen atau 2,043,904 token (seperti ditunjukkan dalam Rajah 1 di atas), RMT pada jujukan yang begitu panjang Dilakukan menghairankan dengan baik. Tugas pengesanan dan ingatan adalah yang paling mudah, dan tugas inferens adalah yang paling kompleks.
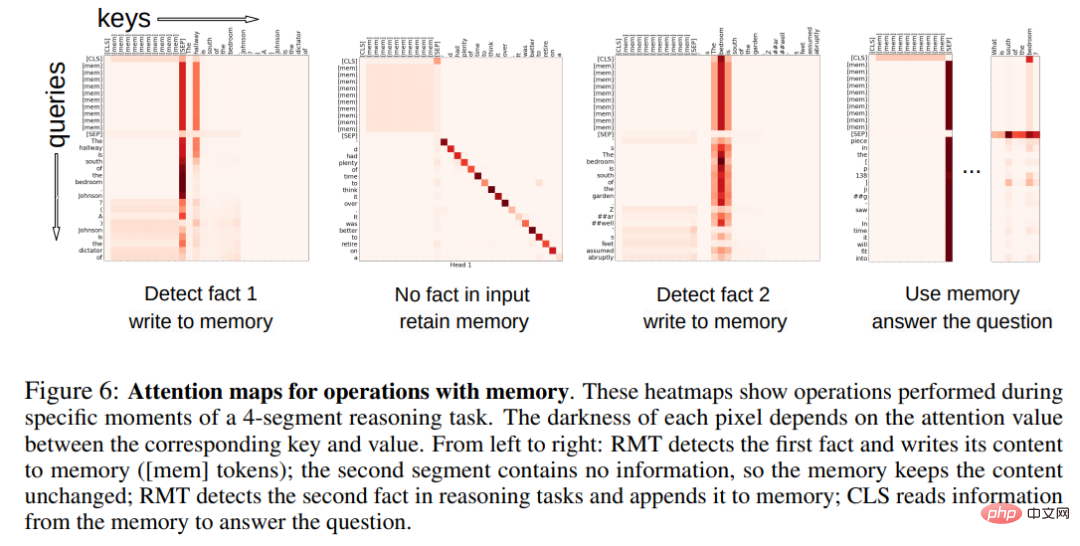
Corak perhatian operasi ingatan
Dalam Rajah 6 di bawah, dengan meneliti perhatian RMT pada segmen tertentu, penyelidik memerhatikan bahawa operasi ingatan sepadan dengan perhatian khusus model. Tambahan pula, prestasi ekstrapolasi yang tinggi pada jujukan yang sangat panjang dalam Bahagian 5.2 menunjukkan keberkesanan operasi ingatan yang dipelajari, walaupun digunakan beribu-ribu kali.
Sila rujuk kertas asal untuk butiran lanjut teknikal dan eksperimen.
Atas ialah kandungan terperinci Bacaan Kelajuan Kuantum Benar: Menembusi had GPT-4 yang hanya boleh memahami 50 halaman teks pada satu masa, penyelidikan baharu berkembang kepada berjuta-juta token. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI