
Rumah >Peranti teknologi >AI >Google sedang mengoptimumkan model resapan Telefon mudah alih Samsung menjalankan Stable Diffusion dan menghasilkan imej dalam masa 12 saat.
Google sedang mengoptimumkan model resapan Telefon mudah alih Samsung menjalankan Stable Diffusion dan menghasilkan imej dalam masa 12 saat.

- 王林ke hadapan
- 2023-04-28 08:19:141084semak imbas
Stable Diffusion terkenal dalam bidang penjanaan imej seperti ChatGPT dalam model besar perbualan. Ia mampu mencipta imej realistik bagi mana-mana teks input yang diberikan dalam berpuluh-puluh saat. Oleh kerana Stable Diffusion mempunyai lebih daripada 1 bilion parameter, dan disebabkan oleh pengkomputeran dan sumber memori yang terhad pada peranti, model ini dijalankan terutamanya dalam awan.
Tanpa reka bentuk dan pelaksanaan yang teliti, menjalankan model ini pada peranti boleh mengakibatkan peningkatan kependaman disebabkan oleh proses penyahnodahan berulang dan penggunaan memori yang berlebihan.
Cara menjalankan Stable Diffusion pada peranti telah membangkitkan minat penyelidikan semua orang Sebelum ini, seorang penyelidik membangunkan aplikasi yang menggunakan Stable Diffusion untuk menjana imej pada iPhone 14 Pro menggunakan lebih kurang 2GiB memori aplikasi.
Apple juga telah membuat beberapa pengoptimuman untuk ini. Mereka boleh menjana imej dengan resolusi 512x512 dalam setengah minit pada iPhone, iPad, Mac dan peranti lain. Qualcomm mengikuti rapat di belakang, menjalankan Stable Diffusion v1.5 pada telefon Android, menjana imej dengan resolusi 512x512 dalam masa kurang daripada 15 saat.
Baru-baru ini, dalam kertas kerja yang diterbitkan oleh Google "Speed As All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations", mereka melaksanakan dipacu GPU. Stable Diffusion 1.4 dijalankan pada peranti, mencapai prestasi kependaman inferens SOTA (pada Samsung S23 Ultra, ia hanya mengambil masa 11.5 saat untuk menjana imej 512 × 512 melalui 20 lelaran). Tambahan pula, kajian ini tidak khusus untuk satu peranti sebaliknya, ia adalah pendekatan umum yang boleh digunakan untuk menambah baik semua model resapan yang berpotensi.
Penyelidikan ini membuka banyak kemungkinan untuk menjalankan AI generatif secara setempat pada telefon anda tanpa sambungan data atau pelayan awan. Stable Diffusion hanya dikeluarkan pada musim luruh lepas, dan ia sudah boleh dipalamkan ke peranti dan dijalankan hari ini, yang menunjukkan betapa pantas medan ini berkembang.

Alamat kertas: https://arxiv.org/pdf/2304.11267.pdf
Untuk mencapai kelajuan penjanaan ini, Google telah mengemukakan beberapa cadangan pengoptimuman. Mari kita lihat cara Google mengoptimumkan.
Pengenalan kaedah
Penyelidikan ini bertujuan untuk mencadangkan kaedah pengoptimuman untuk meningkatkan kelajuan gambar rajah Vincentian model resapan berskala besar cadangan pengoptimuman juga Sesuai untuk model penyebaran besar yang lain.
Pertama, mari kita lihat komponen utama Resapan Stabil, termasuk: penyusun teks, penjanaan hingar, rangkaian neural denoising dan penyahkod imej (penyahkod imej, seperti yang ditunjukkan dalam Rajah 1 di bawah .
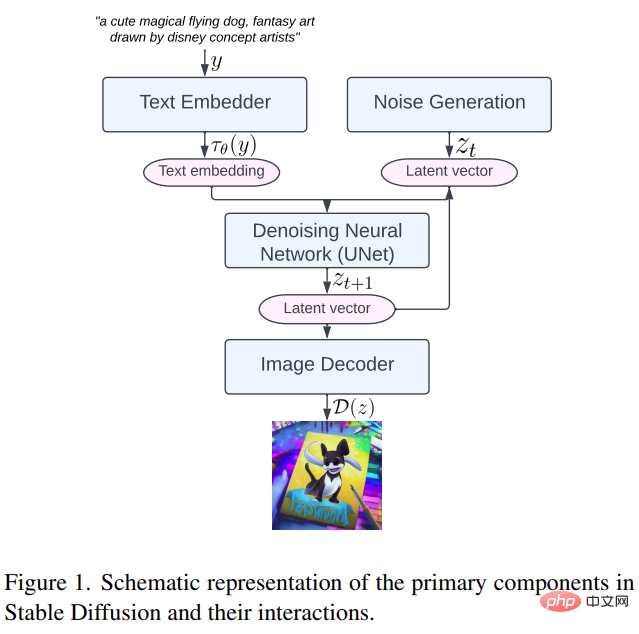
Kemudian mari kita lihat dengan lebih dekat tiga kaedah yang dicadangkan dalam kajian ini
Inti khusus: Norma Kumpulan dan GELU
Kaedah Normalisasi Kumpulan (GN) Prinsip kerjanya ialah membahagikan saluran peta ciri kepada lebih kecil kumpulan dan menormalkan setiap kumpulan secara bebas, sekali gus menjadikan GN kurang bergantung pada saiz kelompok dan lebih sesuai untuk pelbagai saiz kelompok dan seni bina rangkaian . kernel yang boleh melakukan semua operasi ini dalam satu arahan GPU tanpa sebarang Tensor perantaraan
Unit linear ralat Gaussian (GELU) ialah fungsi pengaktifan model yang biasa digunakan yang mengandungi sejumlah besar angka. pengiraan, seperti pendaraban, penambahan, dan fungsi ralat Gaussian Lorek khusus untuk menyepadukan pengiraan berangka ini dan operasi pembahagian dan pendaraban yang disertakan supaya ia boleh dilakukan dalam satu panggilan cat AI untuk meningkatkan kecekapan modul perhatian<.>Pengubah teks-ke-imej dalam Stable Diffusion membantu memodelkan pengagihan bersyarat, yang penting untuk tugas penjanaan teks-ke-imej. Walau bagaimanapun, mekanisme kendiri/perhatian silang menghadapi kesukaran dalam memproses urutan panjang disebabkan oleh kerumitan ingatan dan kerumitan masa. Berdasarkan ini, kajian ini mencadangkan dua kaedah pengoptimuman untuk mengurangkan kesesakan pengiraan. Di satu pihak, untuk mengelakkan daripada melaksanakan keseluruhan pengiraan softmax pada matriks yang besar, kajian ini menggunakan shader GPU untuk mengurangkan operasi pengiraan, yang mengurangkan jejak memori dan keseluruhannya dengan ketara. kependaman tensor perantaraan Kaedah khusus ditunjukkan dalam Rajah 2 di bawah. 
Sebaliknya, penyelidikan ini menggunakan FlashAttention [7], algoritma perhatian tepat yang menyedari IO, yang menjadikan Memori Lebar Jalur tinggi (HBM) memerlukan akses yang lebih sedikit daripada mekanisme perhatian standard, meningkatkan kecekapan keseluruhan.
Konvolusi Winograd
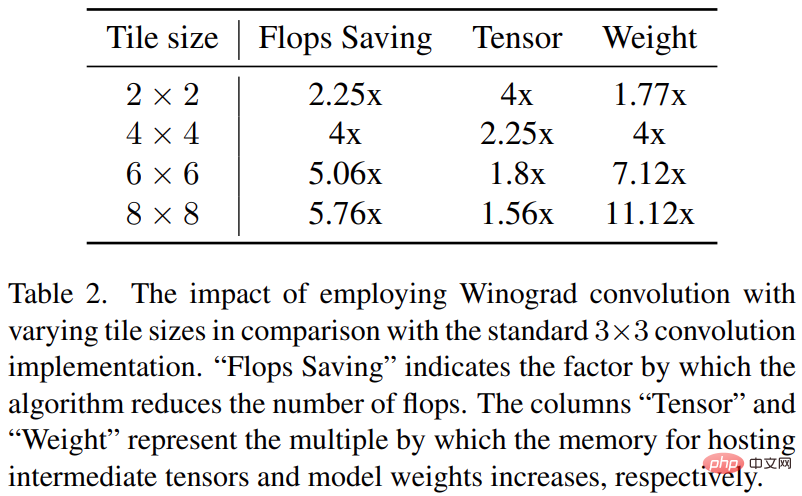
Konvolusi Winograd menukarkan operasi konvolusi kepada siri pendaraban matriks. Kaedah ini boleh mengurangkan banyak operasi pendaraban dan meningkatkan kecekapan pengiraan. Walau bagaimanapun, ini juga meningkatkan penggunaan memori dan ralat berangka, terutamanya apabila menggunakan jubin yang lebih besar.
Tulang belakang Resapan Stabil sangat bergantung pada lapisan konvolusi 3×3, terutamanya dalam penyahkod imej, di mana ia menyumbang 90%. Kajian ini menyediakan analisis mendalam tentang fenomena ini untuk meneroka potensi manfaat menggunakan Winograd dengan saiz jubin yang berbeza pada lilitan kernel 3 × 3. Penyelidikan telah mendapati bahawa saiz jubin 4 × 4 adalah optimum kerana ia memberikan keseimbangan terbaik antara kecekapan pengiraan dan penggunaan memori.
Kajian telah ditanda aras pada pelbagai peranti: Samsung S23 Ultra (Adreno 740) dan iPhone 14 Pro Max (A16). Keputusan penanda aras ditunjukkan dalam Jadual 1 di bawah:
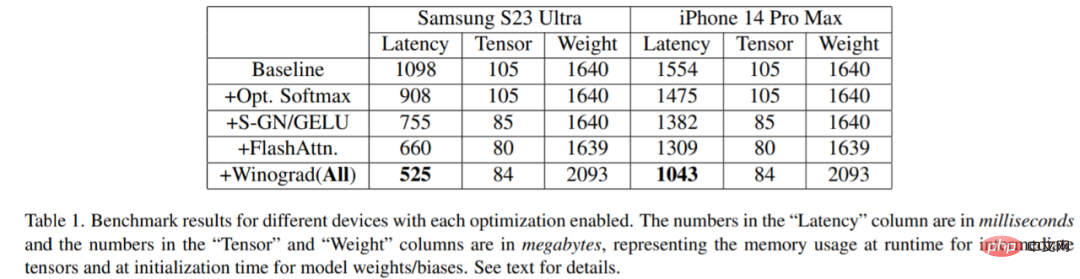
Adalah jelas bahawa kependaman berkurangan secara beransur-ansur apabila setiap pengoptimuman diaktifkan (Boleh difahamkan masa untuk menjana imej semakin berkurangan). Khususnya, berbanding garis dasar: pengurangan kependaman 52.2% pada Samsung S23 Ultra; 32.9% pengurangan kependaman pada iPhone 14 Pro Max. Di samping itu, kajian ini juga menilai kependaman hujung ke hujung Samsung S23 Ultra, menjana imej 512 × 512 piksel dalam 20 langkah lelaran denoising, mencapai keputusan SOTA dalam masa kurang daripada 12 saat.
Peranti kecil boleh menjalankan model AI generatif mereka sendiri. Apakah maksud ini untuk masa hadapan? Kita boleh mengharapkan gelombang.
Atas ialah kandungan terperinci Google sedang mengoptimumkan model resapan Telefon mudah alih Samsung menjalankan Stable Diffusion dan menghasilkan imej dalam masa 12 saat.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI