
Rumah >Peranti teknologi >AI >Tidak perlu menulis kod, model BabyGPT yang paling mudah boleh dibuat dengan tangan: karya baharu bekas pengarah AI Tesla
Tidak perlu menulis kod, model BabyGPT yang paling mudah boleh dibuat dengan tangan: karya baharu bekas pengarah AI Tesla

- 王林ke hadapan
- 2023-04-27 20:25:05994semak imbas
Kami tahu bahawa siri GPT OpenAI telah membuka era baharu kecerdasan buatan melalui kaedah berskala besar dan pra-latihan, bagaimanapun, bagi kebanyakan penyelidik, model besar bahasa (LLM) dihadkan oleh saiz dan kuasa pengkomputeran mereka . Permintaan nampaknya tidak dapat dicapai. Semasa teknologi berkembang ke atas, orang ramai juga telah meneroka model GPT "paling mudah".
Baru-baru ini, Andrej Karpathy, bekas pengarah AI Tesla dan yang baru kembali ke OpenAI, memperkenalkan cara paling mudah untuk bermain GPT, yang mungkin membantu lebih ramai orang memahami konsep di sebalik AI popular ini model.
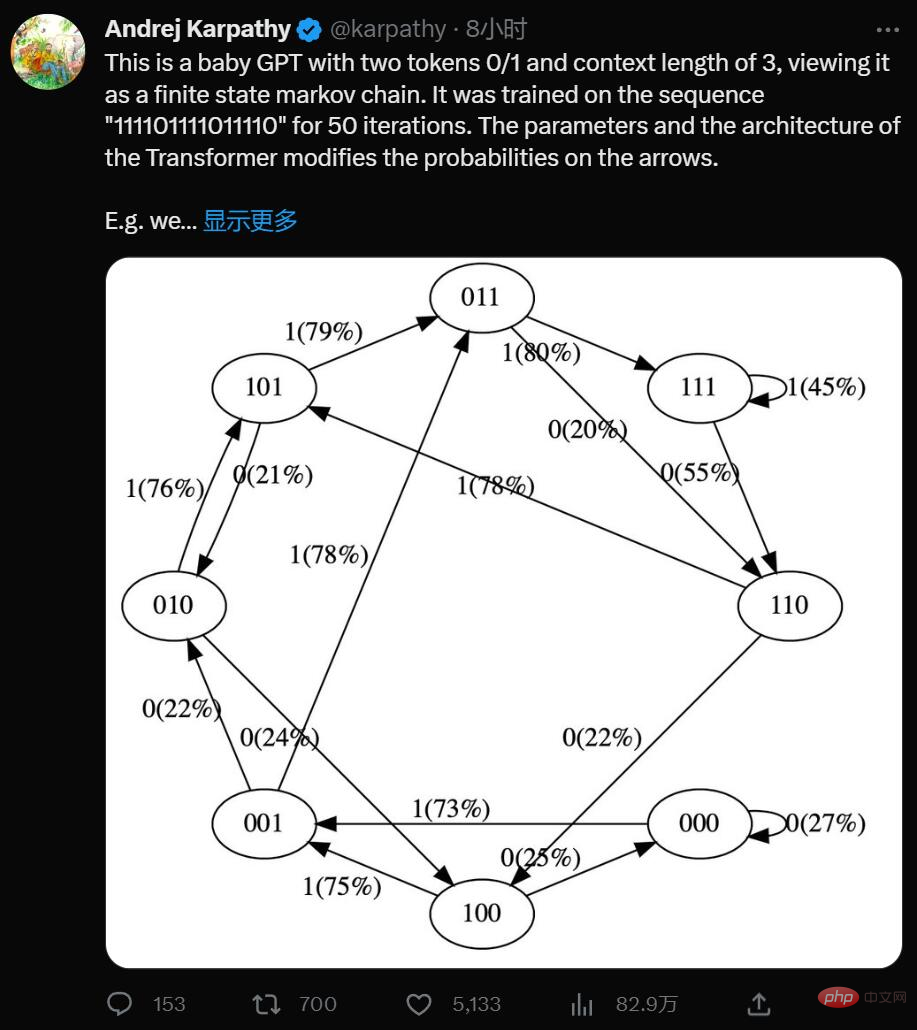
Ya, ini ialah GPT minimalis dengan dua token 0/1 dan panjang konteks 3, anggap ia sebagai rantaian State Markov terhad. Ia dilatih pada urutan "111101111011110" untuk 50 lelaran, dan parameter dan seni bina Transformer mengubah suai kebarangkalian pada anak panah.
Sebagai contoh kita boleh lihat:
- Dalam data latihan, nyatakan 101 secara deterministik beralih kepada 011, jadi peralihan ini Kebarangkalian menjadi lebih tinggi (79%). Tetapi tidak hampir 100%, kerana hanya 50 langkah pengoptimuman dilakukan di sini.
- Negeri 111 masing-masing pergi ke 111 dan 110 dengan kebarangkalian 50%, yang model telah hampir pelajari (45%, 55%).
- Tidak pernah menemui keadaan seperti 000 semasa latihan, tetapi mempunyai kebarangkalian peralihan yang agak tajam, seperti 73% pergi ke 001. Ini adalah hasil daripada bias induktif Transformer. Anda mungkin berfikir ini adalah 50%, kecuali bahawa dalam penggunaan sebenar hampir setiap urutan input adalah unik dan tidak muncul secara literal dalam data latihan.
Melalui pemudahan, Karpathy telah menjadikan model GPT mudah untuk digambarkan, membolehkan anda memahami keseluruhan sistem secara intuitif.
Anda boleh mencubanya di sini: https://colab.research.google.com/drive/1SiF0KZJp75rUeetKOWqpsA8clmHP6jMg?usp=sharing
🎜>Malah, walaupun dalam versi awal GPT, saiz model agak besar: pada tahun 2018, OpenAI mengeluarkan model GPT generasi pertama, yang boleh dilihat daripada kertas "Meningkatkan Pemahaman Bahasa oleh Generatif Pra-Latihan" Difahamkan bahawa ia menggunakan struktur Penyahkod Transformer 12 lapisan dan menggunakan kira-kira 5GB data teks tanpa pengawasan untuk latihan.
Tetapi jika anda memudahkan konsepnya, GPT ialah rangkaian saraf yang mengambil beberapa jujukan token diskret dan meramalkan kebarangkalian token seterusnya dalam jujukan. Contohnya, jika terdapat hanya dua token 0 dan 1, maka GPT binari kecil boleh memberitahu kami sebagai contoh:
[0,1,0] ---> GPT ---> [P (0) = 20%, P (1) = 80%]
Di sini, GPT mengambil jujukan bit [0,1, 0] , dan mengikut tetapan parameter semasa, kebarangkalian untuk meramalkan yang seterusnya menjadi 1 ialah 80%. Yang penting, panjang konteks GPT dihadkan secara lalai. Jika panjang konteks ialah 3, maka mereka hanya boleh menggunakan sehingga 3 token pada input. Dalam contoh di atas, jika kita membalikkan syiling berat sebelah dan sampel 1 yang sepatutnya seterusnya, kita akan beralih daripada keadaan asal [0,1,0] kepada keadaan baharu [1,0,1]. Kami menambah bit baharu di sebelah kanan (1) dan memotong jujukan kepada panjang konteks 3 dengan membuang bit paling kiri (0), dan proses ini boleh diulang berulang kali kepada peralihan antara keadaan.
Jelas sekali, GPT ialah rantai Markov keadaan terhingga: terdapat set keadaan terhingga dan anak panah peralihan kemungkinan di antara mereka. Setiap keadaan ditakrifkan oleh tetapan token tertentu pada input GPT (cth. [0,1,0]). Kita boleh mengalihkannya ke keadaan baharu dengan kebarangkalian tertentu, seperti [1,0,1]. Mari lihat cara ia berfungsi secara terperinci:
# hyperparameters for our GPT # vocab size is 2, so we only have two possible tokens: 0,1 vocab_size = 2 # context length is 3, so we take 3 bits to predict the next bit probability context_length = 3
Input kepada rangkaian saraf GPT ialah jujukan token panjang konteks_panjang. Token ini adalah diskret, jadi ruang keadaan adalah mudah:
print ('state space (for this exercise) = ', vocab_size ** context_length)
# state space (for this exercise) = 8Butiran: Lebih tepatnya, GPT boleh mengambil sebarang bilangan token daripada 1 hingga context_length. Jadi jika panjang konteks ialah 3, pada dasarnya kita boleh memasukkan 1, 2 atau 3 token semasa cuba meramalkan token seterusnya. Kami mengabaikan perkara ini di sini dan menganggap bahawa panjang konteks adalah "dimaksimumkan" hanya untuk memudahkan beberapa kod di bawah, tetapi ia patut diingat.
print ('actual state space (in reality) = ', sum (vocab_size ** i for i in range (1, context_length+1)))
# actual state space (in reality) = 14我们现在要在 PyTorch 中定义一个 GPT。出于本笔记本的目的,你无需理解任何此代码。
现在让我们构建 GPT 吧:
config = GPTConfig ( block_size = context_length, vocab_size = vocab_size, n_layer = 4, n_head = 4, n_embd = 16, bias = False, ) gpt = GPT (config)
对于这个笔记本你不必担心 n_layer、n_head、n_embd、bias,这些只是实现 GPT 的 Transformer 神经网络的一些超参数。
GPT 的参数(12656 个)是随机初始化的,它们参数化了状态之间的转移概率。如果你平滑地更改这些参数,就会平滑地影响状态之间的转换概率。
现在让我们试一试随机初始化的 GPT。让我们获取上下文长度为 3 的小型二进制 GPT 的所有可能输入:
def all_possible (n, k): # return all possible lists of k elements, each in range of [0,n) if k == 0: yield [] else: for i in range (n): for c in all_possible (n, k - 1): yield [i] + c list (all_possible (vocab_size, context_length))
[[0, 0, 0], [0, 0, 1], [0, 1, 0], [0, 1, 1], [1, 0, 0], [1, 0, 1], [1, 1, 0], [1, 1, 1]]
这是 GPT 可能处于的 8 种可能状态。让我们对这些可能的标记序列中的每一个运行 GPT,并获取序列中下一个标记的概率,并绘制为可视化程度比较高的图形:
# we'll use graphviz for pretty plotting the current state of the GPT
from graphviz import Digraph
def plot_model ():
dot = Digraph (comment='Baby GPT', engine='circo')
for xi in all_possible (gpt.config.vocab_size, gpt.config.block_size):
# forward the GPT and get probabilities for next token
x = torch.tensor (xi, dtype=torch.long)[None, ...] # turn the list into a torch tensor and add a batch dimension
logits = gpt (x) # forward the gpt neural net
probs = nn.functional.softmax (logits, dim=-1) # get the probabilities
y = probs [0].tolist () # remove the batch dimension and unpack the tensor into simple list
print (f"input {xi} ---> {y}")
# also build up the transition graph for plotting later
current_node_signature = "".join (str (d) for d in xi)
dot.node (current_node_signature)
for t in range (gpt.config.vocab_size):
next_node = xi [1:] + [t] # crop the context and append the next character
next_node_signature = "".join (str (d) for d in next_node)
p = y [t]
label=f"{t}({p*100:.0f}%)"
dot.edge (current_node_signature, next_node_signature, label=label)
return dot
plot_model ()input [0, 0, 0] ---> [0.4963349997997284, 0.5036649107933044] input [0, 0, 1] ---> [0.4515703618526459, 0.5484296679496765] input [0, 1, 0] ---> [0.49648362398147583, 0.5035163760185242] input [0, 1, 1] ---> [0.45181113481521606, 0.5481888651847839] input [1, 0, 0] ---> [0.4961162209510803, 0.5038837194442749] input [1, 0, 1] ---> [0.4517717957496643, 0.5482282042503357] input [1, 1, 0] ---> [0.4962802827358246, 0.5037197470664978] input [1, 1, 1] ---> [0.4520467519760132, 0.5479532480239868]
我们看到了 8 个状态,以及连接它们的概率箭头。因为有 2 个可能的标记,所以每个节点有 2 个可能的箭头。请注意,在初始化时,这些概率中的大多数都是统一的(在本例中为 50%),这很好而且很理想,因为我们甚至根本没有训练模型。
下面开始训练:
# let's train our baby GPT on this sequence seq = list (map (int, "111101111011110")) seq
[1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0]
# convert the sequence to a tensor holding all the individual examples in that sequence
X, Y = [], []
# iterate over the sequence and grab every consecutive 3 bits
# the correct label for what's next is the next bit at each position
for i in range (len (seq) - context_length):
X.append (seq [i:i+context_length])
Y.append (seq [i+context_length])
print (f"example {i+1:2d}: {X [-1]} --> {Y [-1]}")
X = torch.tensor (X, dtype=torch.long)
Y = torch.tensor (Y, dtype=torch.long)
print (X.shape, Y.shape)我们可以看到在那个序列中有 12 个示例。现在让我们训练它:
# init a GPT and the optimizer torch.manual_seed (1337) gpt = GPT (config) optimizer = torch.optim.AdamW (gpt.parameters (), lr=1e-3, weight_decay=1e-1)
# train the GPT for some number of iterations for i in range (50): logits = gpt (X) loss = F.cross_entropy (logits, Y) loss.backward () optimizer.step () optimizer.zero_grad () print (i, loss.item ())
print ("Training data sequence, as a reminder:", seq)
plot_model ()我们没有得到这些箭头的准确 100% 或 50% 的概率,因为网络没有经过充分训练,但如果继续训练,你会期望接近。
请注意一些其他有趣的事情:一些从未出现在训练数据中的状态(例如 000 或 100)对于接下来应该出现的 token 有很大的概率。如果在训练期间从未遇到过这些状态,它们的出站箭头不应该是 50% 左右吗?这看起来是个错误,但实际上是可取的,因为在部署期间的真实应用场景中,几乎每个 GPT 的测试输入都是训练期间从未见过的输入。我们依靠 GPT 的内部结构(及其「归纳偏差」)来适当地执行泛化。
大小比较:
- GPT-2 有 50257 个 token 和 2048 个 token 的上下文长度。所以 `log2 (50,257) * 2048 = 每个状态 31,984 位 = 3,998 kB。这足以实现量变。
- GPT-3 的上下文长度为 4096,因此需要 8kB 的内存;大约相当于 Atari 800。
- GPT-4 最多 32K 个 token,所以大约 64kB,即 Commodore64。
- I/O 设备:一旦开始包含连接到外部世界的输入设备,所有有限状态机分析就会崩溃。在 GPT 领域,这将是任何一种外部工具的使用,例如必应搜索能够运行检索查询以获取外部信息并将其合并为输入。
Andrej Karpathy 是 OpenAI 的创始成员和研究科学家。但在 OpenAI 成立一年多后,Karpathy 便接受了马斯克的邀请,加入了特斯拉。在特斯拉工作的五年里,他一手促成了 Autopilot 的开发。这项技术对于特斯拉的完全自动驾驶系统 FSD 至关重要,也是马斯克针对 Model S、Cybertruck 等车型的卖点之一。
今年 2 月,在 ChatGPT 火热的背景下,Karpathy 回归 OpenAI,立志构建现实世界的 JARVIS 系统。

最近一段时间,Karpathy 给大家贡献了很多学习材料,包括详解反向传播的课程 、重写的 minGPT 库、从零开始构建 GPT 模型的完整教程等。
Atas ialah kandungan terperinci Tidak perlu menulis kod, model BabyGPT yang paling mudah boleh dibuat dengan tangan: karya baharu bekas pengarah AI Tesla. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI