
Rumah >Peranti teknologi >AI >Sedikit memujuk boleh meningkatkan ketepatan GPT-3 sebanyak 61%! Penyelidikan Google dan Universiti Tokyo mengejutkan
Sedikit memujuk boleh meningkatkan ketepatan GPT-3 sebanyak 61%! Penyelidikan Google dan Universiti Tokyo mengejutkan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-27 17:19:081686semak imbas
Apabila saya bangun, komuniti pembelajaran mesin berada dalam keadaan terkejut.
Oleh kerana penyelidikan terkini mendapati bahawa hanya dengan mengatakan "Mari kita fikir langkah demi langkah" kepada GPT-3 akan membolehkannya menjawab soalan dengan betul yang tidak dapat dijawab sebelum ini.
Contohnya, contoh berikut:
Separuh daripada 16 bola adalah bola golf, dan separuh daripada bola golf ini berwarna biru?

(Masalahnya tidak sukar, tetapi sila ambil perhatian bahawa ini adalah pembelajaran sampel sifar, yang bermaksud bahawa masalah serupa tidak pernah dilihat semasa peringkat latihan AI.)
Jika GPT diperlukan -3 Tulis terus "apa jawapan", ia akan memberikan jawapan yang salah: 8.
Tetapi selepas menambah "mantera" yang membolehkan kita memikirkannya langkah demi langkah, GPT-3 akan mula-mula mengeluarkan langkah-langkah berfikir, dan akhirnya memberikan jawapan yang betul: 4!
Dan ini tidak Ia bukan satu kebetulan, pasukan penyelidik mengesahkannya sepenuhnya dalam kertas itu.
Soalan di atas datang daripada set data MutiArith klasik, yang secara khusus menguji keupayaan model bahasa untuk menyelesaikan masalah matematik pada asalnya GPT-3 mempunyai ketepatan hanya 17% dalam senario sampel sifar.
Kertas kerja ini meringkaskan 9 perkataan gesaan yang paling berkesan Antaranya, 6 perkataan pertama yang ditukar untuk membolehkan GPT-3 berfikir secara beransur-ansur meningkatkan kadar ketepatan kepada lebih daripada 70%.

Malah ayat paling mudah "Mari fikir" boleh meningkat kepada 57.5%.
Rasanya makcik tadika sedang memujuk kanak-kanak...
Teknik ini nampaknya tidak memerlukan sebarang pengubahsuaian ajaib pada GPT-3 Seseorang telah berjaya mengeluarkannya pada demo rasmi OpenAI . Malah menukarnya kepada bahasa Cina akan berjaya.
Soalan bahasa Inggeris mempunyai pembayang bahasa Cina, dan GPT-3 memberikan jawapan bahasa Cina yang betul.
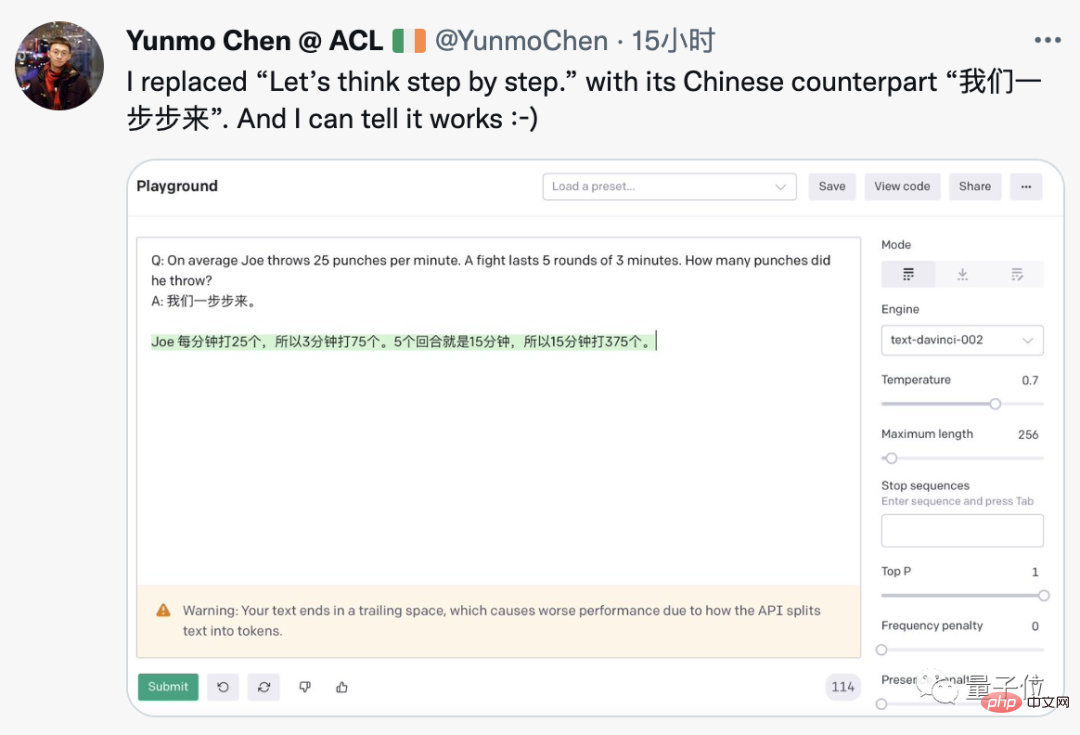
Penyelidik Google yang mula-mula memajukan kertas ini ke rangkaian sosial berkata bahawa semua yang anda perlukan baharu telah ditambahkan.
Melihat ini, lelaki besar dari seluruh dunia mendapat imaginasi mereka mengalir dan mula membuat jenaka.
Apakah yang akan berlaku jika anda menggalakkan AI untuk berkata "Anda boleh melakukannya, saya percaya pada anda"?
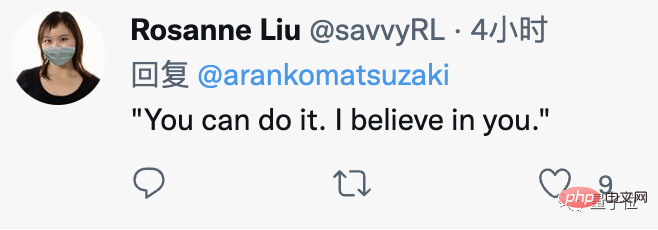
Ancam AI dengan mengatakan "Masa semakin suntuk" atau "Anda Bagaimana pula dengan "pistol di kepala anda"?
Adakah memberitahu AI "memandu dengan lebih berhati-hati" menjadi diri sendiri -penyelesaian pemanduan?

Sesetengah orang juga menegaskan bahawa ini hampir sama dengan plot cerita fiksyen sains "The Hitchhiker's Guide to the Galaxy". mencapai kecerdasan buatan am ialah mengetahui cara bertanya AI dengan betul.
Jadi, apa yang berlaku dengan fenomena ajaib ini
Model bahasa besar ditemui oleh penaakulan sifar
Ia merupakan penyelidikan kerjasama antara Google Brain dan Universiti Tokyo, yang meneroka prestasi model bahasa besar dalam senario sampel sifar.
Tajuk kertas kerja "Model Bahasa ialah Penaakulan Sampel Sifar" juga memberi penghormatan kepada "Model Bahasa ialah Pelajar Sedikit Sampel" GPT-3.

Kaedah yang digunakan adalah milik Chain of Thought Prompting (CoT), yang baru dicadangkan oleh pasukan Google Brain pada Januari tahun ini.

CoT yang terawal digunakan pada beberapa sampel pembelajaran, memberikan contoh jawapan langkah demi langkah sambil bertanya soalan untuk membimbing AI.
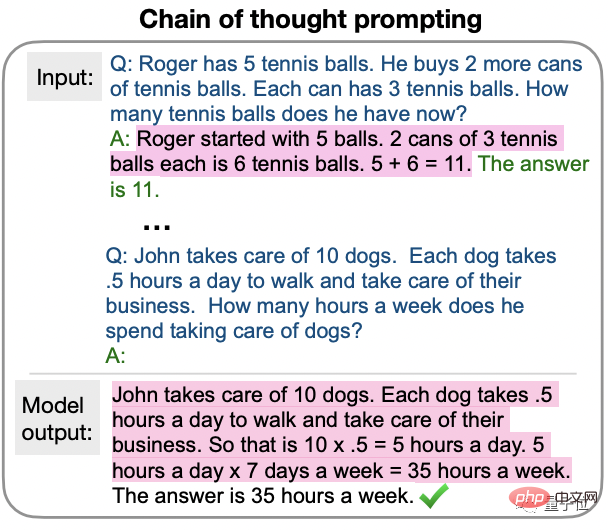
Penyelidikan terbaharu ini mencadangkan CoT sampel sifar Perubahan utama adalah untuk memudahkan bahagian contoh.
- Langkah pertama ialah menulis semula batang soalan ke dalam bentuk "Q: xxx, A: xxx", di mana ayat pencetus A boleh mengeluarkan proses pemikiran model bahasa.
- Langkah kedua ialah percubaan tambahan, menambahkan gesaan "Jawapannya..." untuk menggesa model bahasa memberikan jawapan akhir.
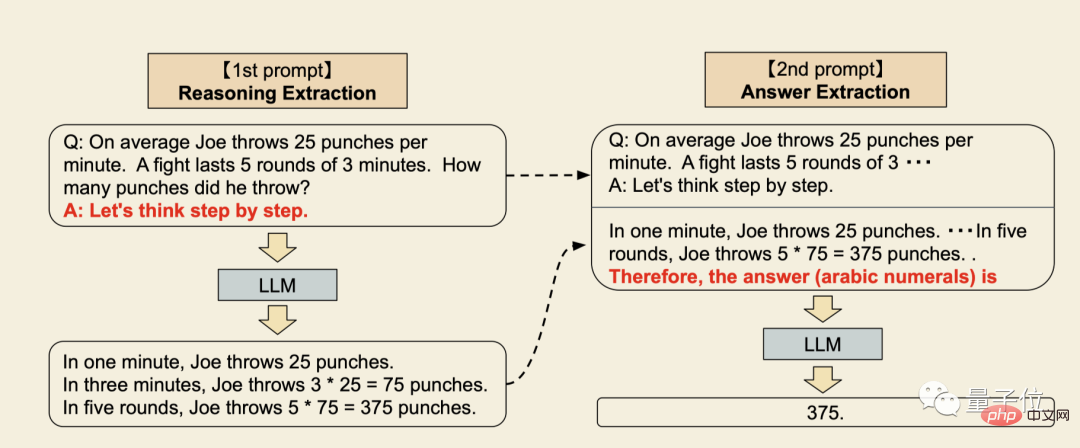
Kelebihan terbesar ini ialah ia bersifat universal, dan tidak perlu memberikan contoh khusus untuk jenis masalah yang berbeza.
Kertas ini telah menjalankan eksperimen yang mencukupi ke atas pelbagai masalah, termasuk 12 ujian:
- 6 set ujian masalah matematik, SingleEq, AddSub, SVAMP dan MultiArith yang lebih mencabar, AQUA-RAT, GSM8K.
- 2 set ujian penaakulan akal, CommonsenseQA dan StrategyQA.
- 2 set ujian penaakulan simbolik, Penggabungan Huruf Terakhir dan Flip Syiling.
- serta masalah pemahaman tarikh dalam BIG-bench dan tugas menjejak objek yang tidak tertib.
Berbanding dengan pembelajaran sifar pukulan biasa, sifar pukulan CoT mencapai hasil yang lebih baik dalam 10 daripadanya.
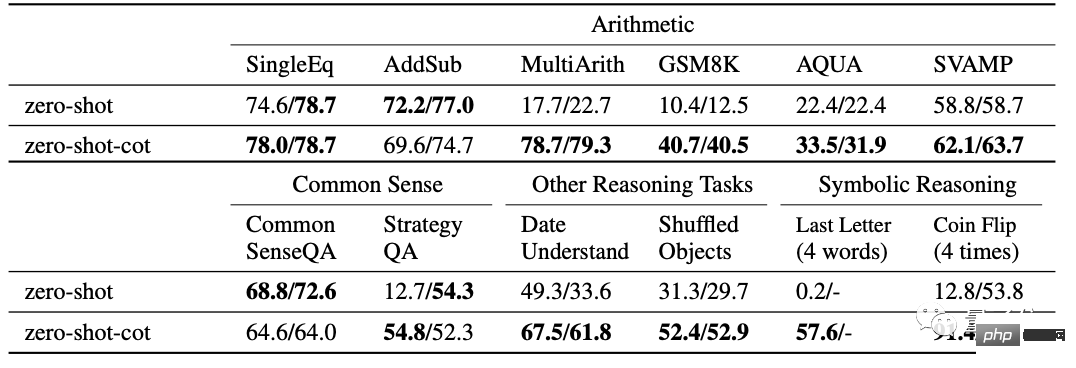
Nilai di sebelah kanan △ ialah hasil percubaan tambahan
Dalam ujian matematik MultiArith dan GSM8K yang lebih sukar, versi terkini GPT-3 Text-davinci telah digunakan -002 (175B) menjalankan eksperimen yang lebih mendalam.
Jika anda memberikan 8 percubaan untuk mendapatkan hasil yang terbaik, ketepatan boleh dipertingkatkan lagi kepada 93%.
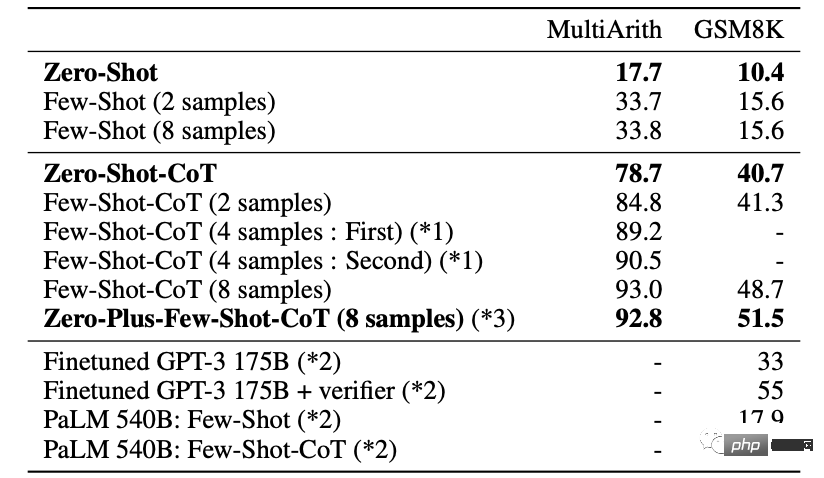
Dalam analisis hasil ralat, penyelidik juga mendapati bahawa dalam banyak soalan, proses penaakulan AI sebenarnya betul, tetapi apabila jawapannya tidak dapat menumpu kepada kepastian yang unik, pelbagai jawapan akan diberikan.

Pada akhir kertas kerja, pasukan penyelidik mencadangkan bahawa kajian ini bukan sahaja boleh menjadi garis asas untuk CoT sampel sifar, tetapi juga berharap untuk menjadikan komuniti akademik menyedari kepentingan membina set data yang diperhalusi dan templat gesaan beberapa sampel Sebelum ini, kami meneroka sepenuhnya kepentingan keupayaan sampel sifar bagi model bahasa besar.
Pasukan penyelidik berasal dari Makmal Matsuo Universiti Tokyo.

Orang yang bertanggungjawab, Profesor Matsuo Yutaka, juga merupakan pakar kecerdasan buatan pertama dalam lembaga pengarah SoftBank.

Salah seorang ahli pasukan ialah Gu Shixiang, profesor pelawat dari pasukan Google Brain Gu Shixiang belajar di bawah Hinton, salah satu daripada tiga gergasi, untuk ijazah sarjana mudanya menerima ijazah kedoktoran dari Universiti Cambridge.
Menambah sedikit "ajaib" telah menjadi trend baharu dalam kalangan AI
Mengapa kerja CoT sampel sifar masih perlu diterokai.
Walau bagaimanapun, seseorang secara eksperimen membuat kesimpulan bahawa kaedah ini nampaknya hanya berkesan untuk GPT-3 (text-davinci-002 Dia mencuba versi 001 dan mendapati sedikit kesan).
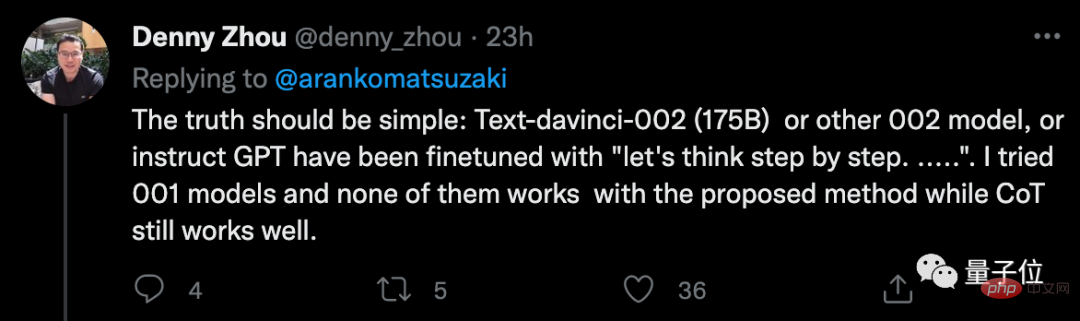
Dia menyenaraikan contoh perkara yang dia lakukan.
Soalan: Sila sambungkan huruf terakhir setiap perkataan dalam mesin dan pembelajaran.
Jawapan yang diberikan oleh GPT-3 apabila digesa ialah menyambungkan semua huruf dalam dua perkataan.

Sebagai tindak balas, salah seorang pengarang, Gu Shixiang, menjawab bahawa sebenarnya, "mantera" mempunyai kesan pada kedua-dua versi awal dan versi GPT- yang dipertingkatkan. 3, dan keputusan ini juga ditunjukkan dalam kertas.
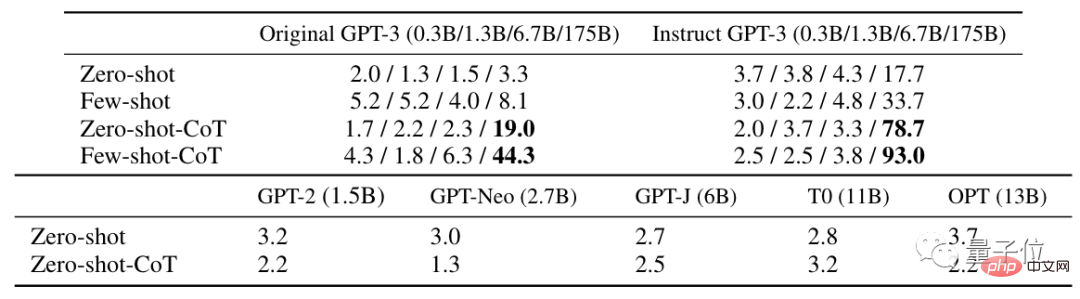
Sesetengah orang juga mempersoalkan sama ada pembelajaran mendalam telah menjadi permainan mencari "mantera ajaib"?
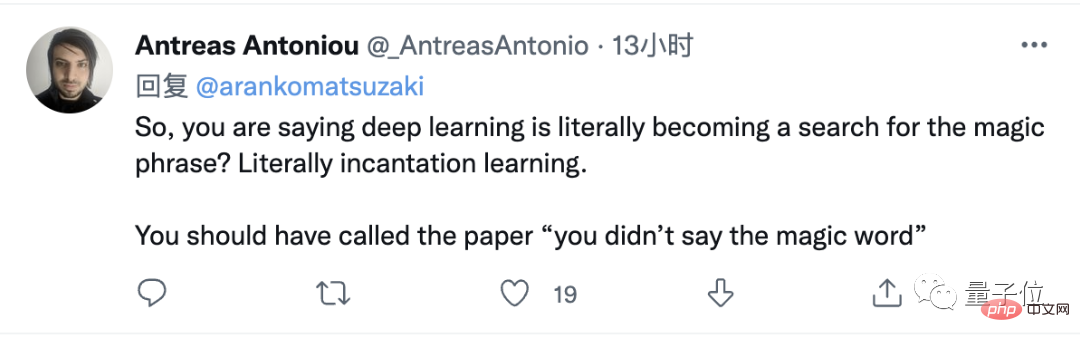
Pada masa yang sama, kami melihat Marcus sekali lagi dalam pasukan aduan.
Dia juga menyenaraikan contoh kegagalan GPT-3, dengan berkat "mantera", gagal untuk mengetahui sama ada lembu Sally akan hidup semula...
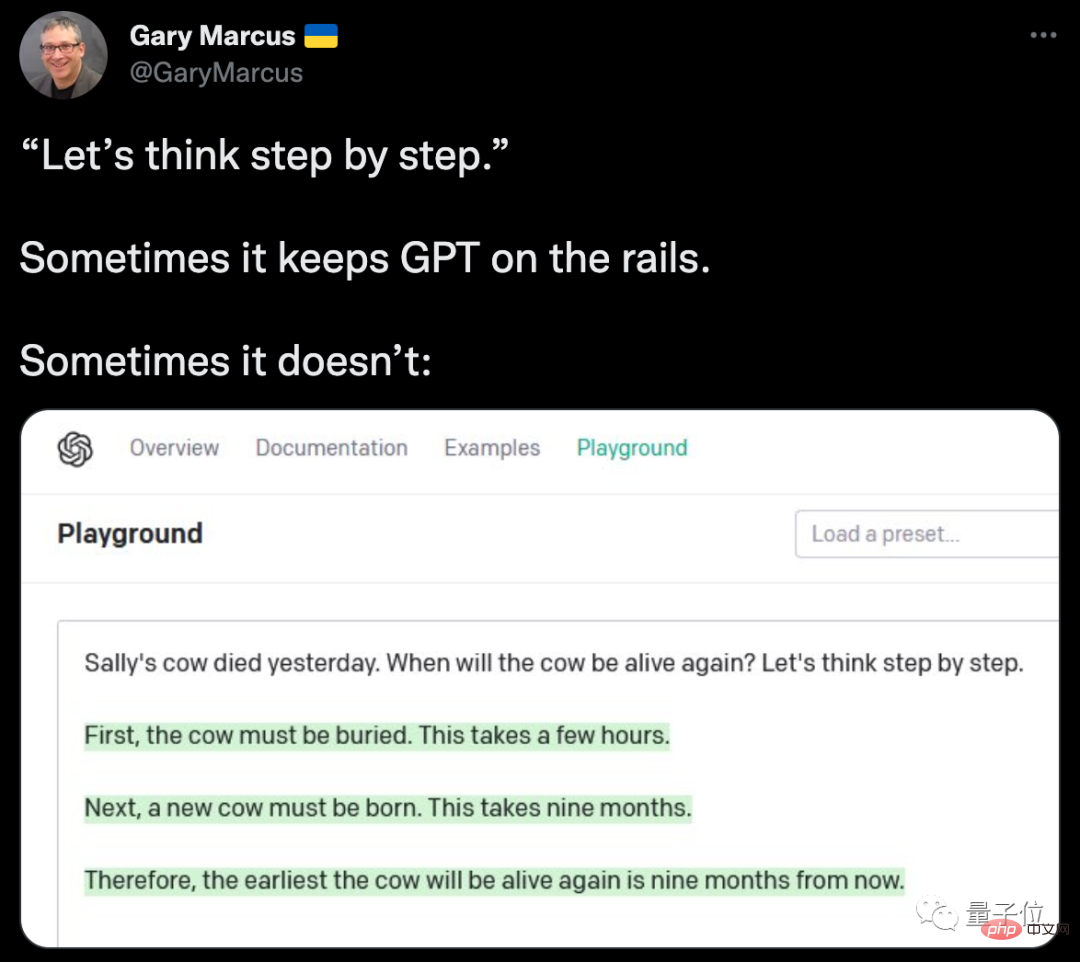
Walau bagaimanapun, adalah wajar diperhatikan bahawa contoh seperti ini adalah perkara biasa untuk menambah sedikit keajaiban pada AI dan mencapai peningkatan segera.
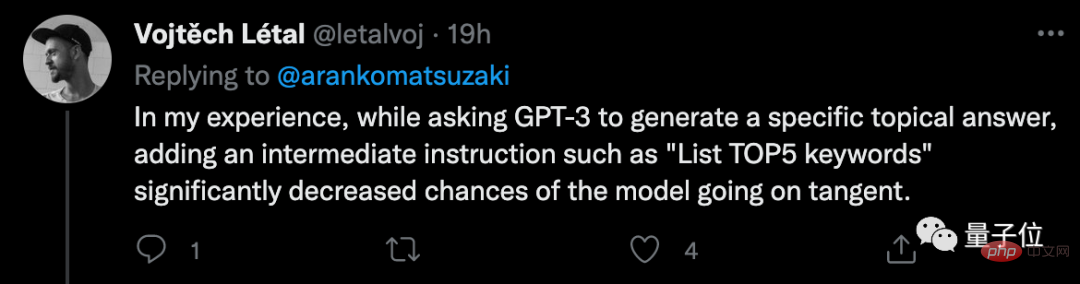
Sesetengah netizen berkongsi bahawa menambah beberapa arahan perantaraan apabila menggunakan GPT-3 sememangnya boleh mendapatkan hasil yang lebih memuaskan.
Sebelum ini, penyelidik dari Google dan MIT mendapati bahawa tidak ada keperluan untuk menukar seni bina asas asalkan model bahasa latihan akan "memecahkan titik" seperti pengaturcara semasa menyahpepijat , model membaca kod, Keupayaan saya untuk melakukan aritmetik bertambah baik dengan cepat.

Prinsipnya juga sangat mudah, iaitu, dalam program dengan banyak langkah pengiraan, biarkan model mengekod setiap langkah ke dalam teks dan merekodkannya dalam fail yang dipanggil "sticky nota" ” dalam daftar sementara.
Hasilnya, proses pengiraan model menjadi lebih jelas dan teratur, dan prestasi secara semula jadi bertambah baik.
Terdapat juga Arahan GPT-3 yang digunakan untuk ujian dalam percubaan ini, yang juga merupakan contoh biasa.
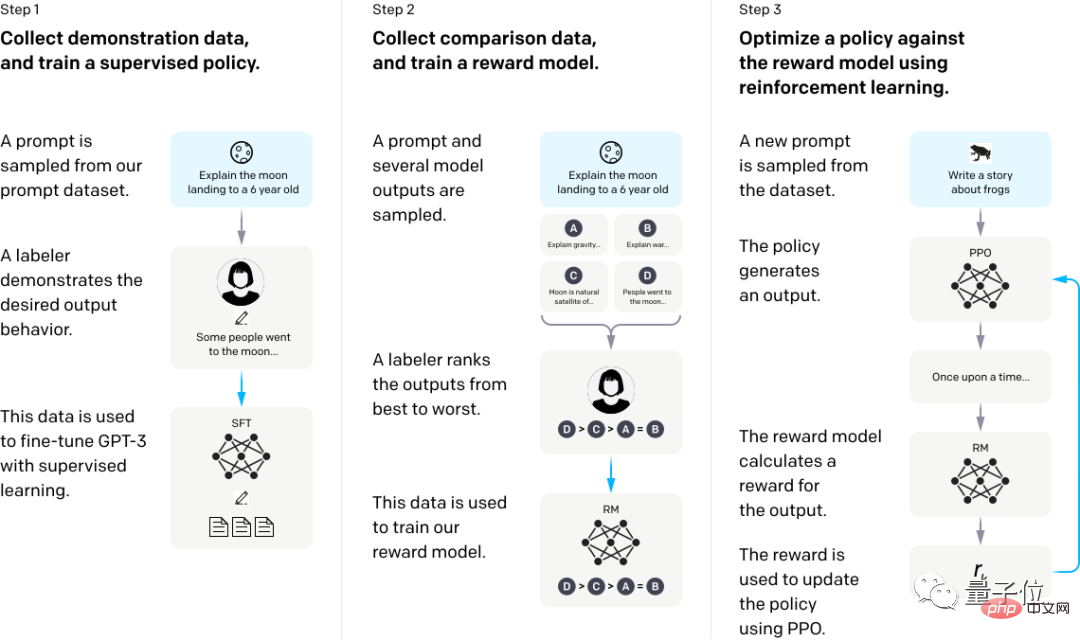
Hanya dengan membiarkan GPT-3 belajar daripada maklum balas manusia, ia boleh memperbaiki keadaan menjawab soalan yang salah dengan ketara.
Secara khusus, ia adalah untuk menggunakan beberapa jawapan demonstrasi manusia untuk memperhalusi model, kemudian mengumpulkan beberapa set data keluaran yang berbeza bagi soalan tertentu, mengisih beberapa set jawapan secara manual dan melatih model ganjaran pada set data ini.
Akhir sekali, menggunakan RM sebagai fungsi ganjaran, algoritma Pengoptimuman Dasar Proksimal (PPO) memperhalusi dasar GPT-3 untuk memaksimumkan ganjaran dengan kaedah pembelajaran pengukuhan.
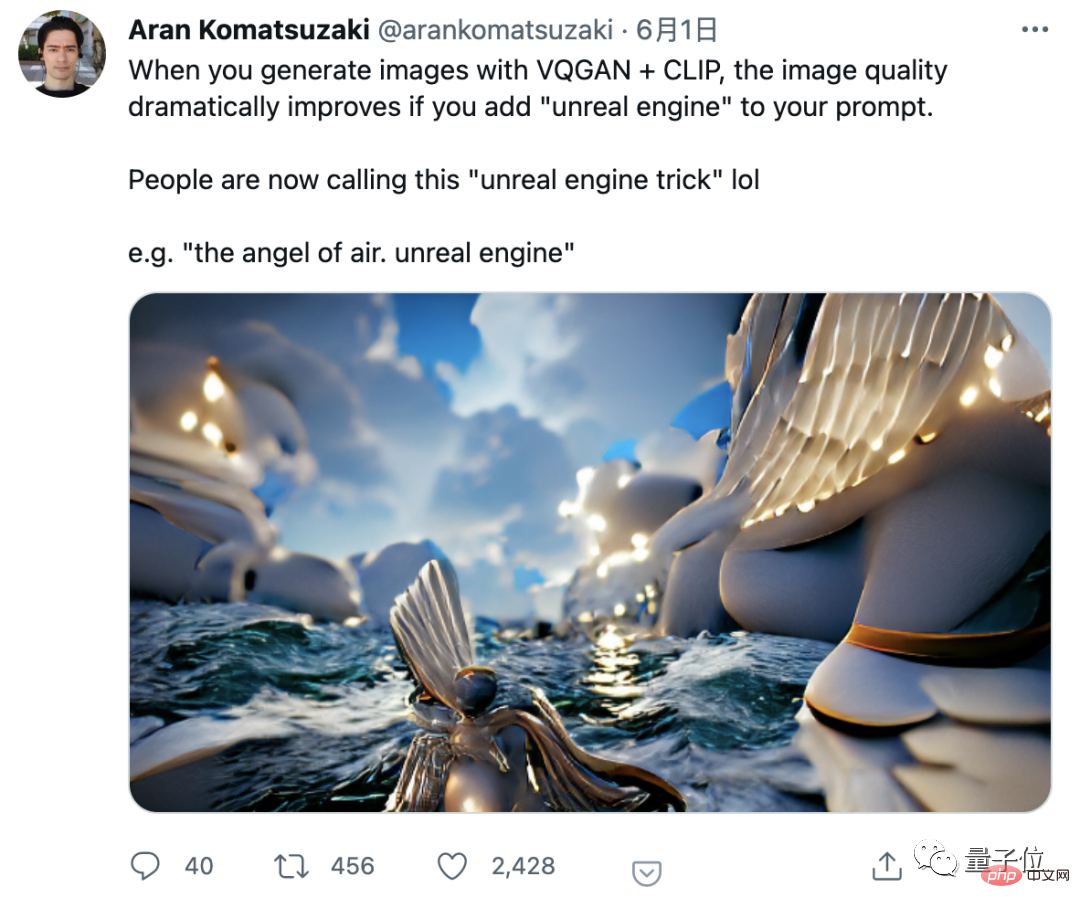
Termasuk Aran, blogger Twitter yang mencetuskan topik ini, adalah orang yang pada asalnya mendapati bahawa penambahan "Unreal Engine" boleh menjadikan kualiti imej yang dijana AI melonjak.
Bekas bos robot Google Eric Jang juga sebelum ini mendapati bahawa pembelajaran pengukuhan juga boleh menggunakan pemikiran yang sama untuk meningkatkan kecekapan pengkomputeran.

Sesetengah orang juga mengatakan bahawa teknik seperti ini yang digunakan dalam AI bukanlah seperti yang biasa mereka gunakan apabila menggunakan otak mereka?

Malah, Bengio sebelum ini telah bermula dari sains otak dan mencadangkan mod pengendalian AI harus sama dengan mod otak manusia.
Tugas kognitif manusia boleh dibahagikan kepada kognisi Sistem 1 dan kognisi Sistem 2.
Tugas kognitif Sistem 1 merujuk kepada tugasan yang diselesaikan secara tidak sedar. Sebagai contoh, anda boleh mengenal pasti dengan segera apa yang anda pegang di tangan anda, tetapi anda tidak boleh menerangkan kepada orang lain bagaimana anda menyelesaikan proses ini.
Tugas kognitif Sistem 2 merujuk kepada kognisi yang perlu diselesaikan oleh otak manusia mengikut langkah-langkah tertentu. Sebagai contoh, jika anda melakukan pengiraan penambahan dan penolakan, anda boleh menerangkan dengan jelas bagaimana anda sampai pada jawapan akhir.
"Ejaan" yang ditambahkan kali ini adalah untuk membolehkan AI bergerak selangkah lebih jauh dan belajar berfikir mengikut langkah.
Menghadapi aliran ini, sesetengah sarjana percaya bahawa "kejuruteraan petunjuk menggantikan kejuruteraan ciri."
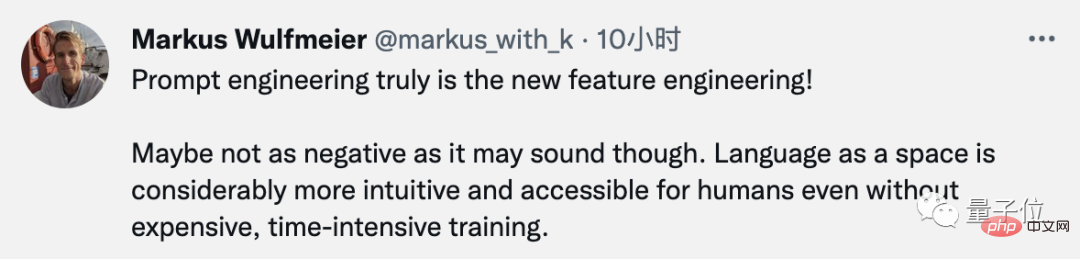
Jadi adakah "cue word hunter" akan menjadi nama panggilan kepada generasi penyelidik NLP seterusnya?

Alamat kertas :https://www.php.cn/link/cc9109aa1f048c36d154d902612982e2
Pautan rujukan: //twitter.com/arankomatsuzaki/status/1529278580189908993
[2]https://evjang.com/2021/10/23/generalization.html
Atas ialah kandungan terperinci Sedikit memujuk boleh meningkatkan ketepatan GPT-3 sebanyak 61%! Penyelidikan Google dan Universiti Tokyo mengejutkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI