
Rumah >Peranti teknologi >AI >DeepMind berkata: Model AI perlu menurunkan berat badan, dan autoregresi menjadi trend utama
DeepMind berkata: Model AI perlu menurunkan berat badan, dan autoregresi menjadi trend utama

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-27 16:49:08978semak imbas
Program perhatian autoregresif dengan Transformer sebagai teras sentiasa sukar untuk mengatasi kesukaran skala. Untuk tujuan ini, DeepMind/Google baru-baru ini telah menubuhkan projek baharu untuk mencadangkan cara yang baik untuk membantu program sebegini dengan berkesan melangsingkan badan.
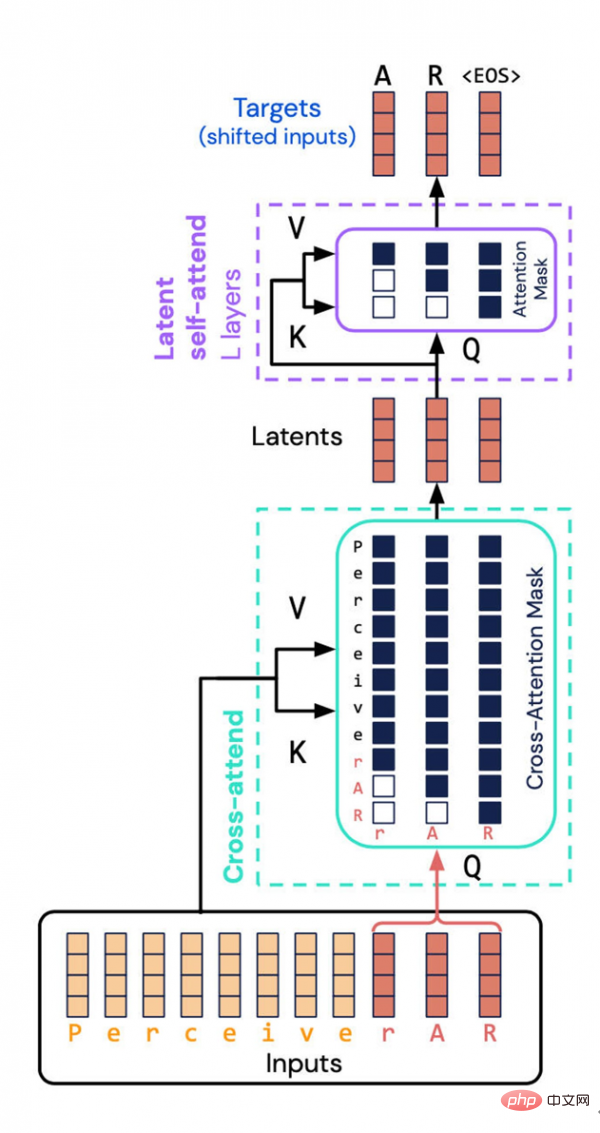
Seni bina Perceiver AR yang dicipta oleh DeepMind dan Google Brain mengelakkan tugasan intensif sumber - mengira gabungan sifat input dan output ke dalam ruang terpendam. Sebaliknya, mereka memperkenalkan "penyamaran sebab" ke dalam ruang terpendam, dengan itu mencapai susunan autoregresif Transformer biasa.
Salah satu trend pembangunan yang paling mengagumkan dalam bidang kecerdasan buatan/pembelajaran mendalam ialah saiz model semakin besar dan besar. Pakar dalam bidang ini mengatakan bahawa memandangkan skala sering dikaitkan secara langsung dengan prestasi, gelombang pengembangan volum ini berkemungkinan berterusan.
Walau bagaimanapun, skala projek semakin besar dan lebih besar, dan sumber yang digunakan secara semula jadi meningkat, yang menyebabkan pembelajaran mendalam menimbulkan isu sosial dan etika baharu. Dilema ini telah menarik perhatian jurnal saintifik arus perdana seperti Nature.
Disebabkan ini, kita mungkin perlu kembali kepada perkataan lama "kecekapan" - program AI Adakah terdapat sebarang ruang untuk peningkatan kecekapan selanjutnya?
Para saintis dari jabatan DeepMind dan Google Brain baru-baru ini telah mengubah suai rangkaian neural Perceiver yang mereka lancarkan tahun lepas, dengan harapan dapat meningkatkan kecekapannya dalam menggunakan sumber pengkomputeran.
Program baharu ini dinamakan Perceiver AR. AR di sini berasal daripada "autoregressive", yang juga merupakan satu lagi hala tuju pembangunan program pembelajaran yang semakin mendalam hari ini. Autoregression ialah teknik yang membolehkan mesin menggunakan output sebagai input baru kepada program Ia adalah operasi rekursif, dengan itu membentuk peta perhatian di mana pelbagai elemen berkaitan antara satu sama lain.
Transformer rangkaian saraf popular yang dilancarkan oleh Google pada 2017 juga mempunyai ciri autoregresif ini. Malah, GPT-3 kemudian dan versi pertama Perceiver meneruskan laluan teknikal autoregresif.
Sebelum Perceiver AR, Perceiver IO, yang dilancarkan pada bulan Mac tahun ini, merupakan versi kedua Perceiver.
Inovasi asal Perceiver adalah menggunakan Transformer dan membuat pelarasan supaya ia boleh menyerap pelbagai input secara fleksibel, termasuk teks, bunyi dan imej, dengan itu melepaskan diri daripada pergantungan pada jenis input tertentu. Ini membolehkan penyelidik membangunkan rangkaian saraf menggunakan pelbagai jenis input.
Sebagai ahli aliran zaman, Perceiver, seperti projek model lain, telah mula menggunakan mekanisme perhatian autoregresif untuk mencampurkan mod input yang berbeza dan domain tugas yang berbeza. Kes penggunaan sedemikian juga termasuk Laluan Google, Gato DeepMind dan data2vec Meta.
Pada bulan Mac tahun ini, Andrew Jaegle, pencipta versi pertama Perceiver, dan pasukan rakan sekerjanya mengeluarkan versi "IO". Versi baharu ini mempertingkatkan jenis output yang disokong oleh Perceiver, membolehkan sejumlah besar output yang mengandungi pelbagai struktur, termasuk bahasa teks, medan aliran optik, urutan audio-visual dan juga set simbol yang tidak tertib, dsb. Perceiver IO malah boleh menjana arahan pengendalian dalam permainan "StarCraft 2".
Dalam kertas terbaharu ini, Perceiver AR telah dapat melaksanakan pemodelan autoregresif am untuk konteks yang panjang. Tetapi semasa penyelidikan, Jaegle dan pasukannya juga menghadapi cabaran baharu: cara menskalakan model apabila menangani pelbagai tugas input dan output berbilang modal.
Masalahnya ialah kualiti autoregresif Transformer, dan mana-mana program yang sama membina peta perhatian input-ke-output, memerlukan saiz pengedaran besar-besaran sehingga ratusan ribu elemen.
Ini adalah kelemahan mematikan mekanisme perhatian. Lebih tepat lagi, segala-galanya perlu diberi perhatian untuk membina taburan kebarangkalian peta perhatian.
Seperti yang disebutkan oleh Jaegle dan pasukannya dalam kertas kerja, memandangkan bilangan perkara yang perlu dibandingkan antara satu sama lain meningkat dalam input, penggunaan sumber pengkomputeran model akan menjadi semakin dibesar-besarkan:
Semacam ini Terdapat konflik antara struktur konteks yang panjang dan sifat pengiraan Transformers. Transformer berulang kali melakukan operasi perhatian sendiri pada input, yang menyebabkan keperluan pengiraan berkembang secara kuadratik dengan panjang input dan secara linear dengan kedalaman model. Lebih banyak data input, lebih banyak teg input sepadan dengan kandungan data yang diperhatikan, corak dalam data input menjadi lebih halus dan kompleks, dan lapisan yang lebih dalam mesti digunakan untuk memodelkan corak yang dijana. Disebabkan kuasa pengkomputeran yang terhad, pengguna Transformer terpaksa sama ada memotong input model (menghalang pemerhatian corak yang lebih jauh) atau mengehadkan kedalaman model (dengan itu menafikannya daripada keupayaan ekspresif untuk memodelkan corak yang kompleks).
Malah, versi pertama Perceiver juga cuba meningkatkan kecekapan Transformers: ia tidak melakukan perhatian secara langsung, tetapi melakukan perhatian terhadap potensi perwakilan input. Dengan cara ini, keperluan kuasa pengkomputeran untuk memproses tatasusunan input yang besar boleh "(dipisahkan) daripada keperluan kuasa pengkomputeran yang sepadan dengan rangkaian dalam yang besar."
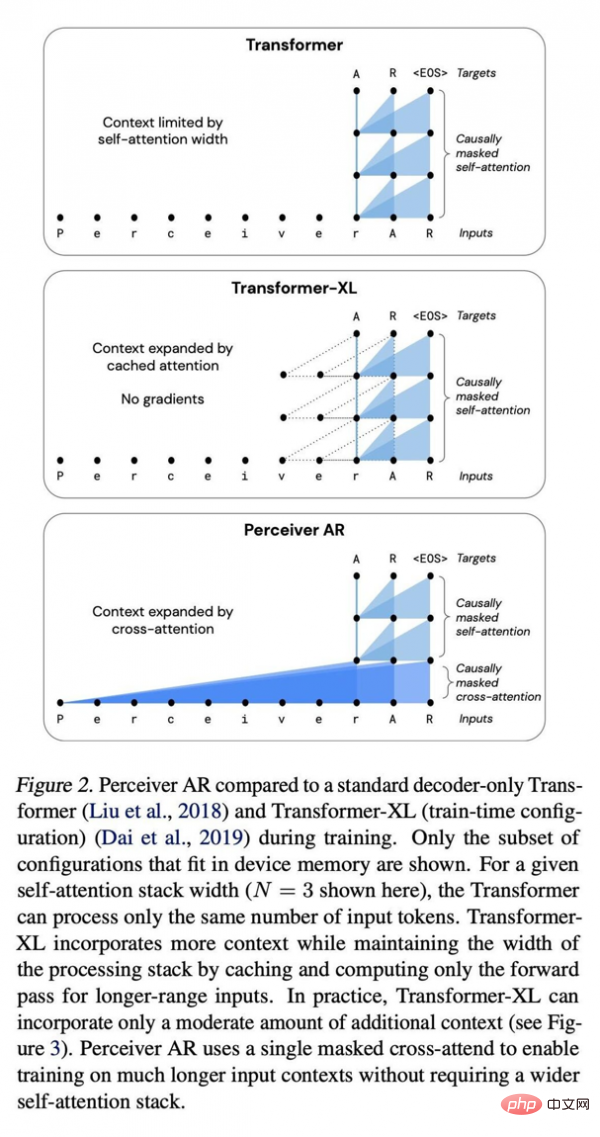
Perbandingan antara Perceiver AR, rangkaian dalam Transformer standard dan Transformer XL yang dipertingkatkan.
Di bahagian terpendam, perwakilan input dimampatkan, menjadikannya enjin perhatian yang lebih cekap. Dengan cara ini, "dengan rangkaian dalam, kebanyakan pengiraan sebenarnya berlaku pada timbunan perhatian kendiri," dan bukannya perlu beroperasi pada input yang tidak terkira banyaknya.
Tetapi cabaran masih wujud, kerana perwakilan asas tidak mempunyai konsep susunan, jadi Perceiver tidak boleh menjana output seperti Transformer. Tertib adalah penting dalam autoregresi, dan setiap output hendaklah hasil daripada input sebelum ia, bukan produk selepasnya.
Tetapi memandangkan setiap model terpendam memberi perhatian kepada semua input tanpa mengira lokasinya, "untuk penjanaan autoregresif yang memerlukan setiap output model mesti bergantung hanya pada input sebelumnya," tulis para penyelidik, Perceiver tidak akan digunakan secara langsung . "
Bagi Perceiver AR, pasukan penyelidik melangkah lebih jauh dan memasukkan urutan ke dalam Perceiver untuk mendayakan regresi automatik.
Kuncinya di sini ialah melakukan apa yang dipanggil "penyelidikan sebab-sebab" pada input dan perwakilan terpendam. Pada bahagian input, pelekat sebab melakukan "perhatian silang", manakala pada bahagian perwakilan asas ia memaksa program untuk memberi perhatian hanya kepada perkara yang datang sebelum simbol tertentu. Kaedah ini memulihkan arahan Transformer dan masih boleh mengurangkan jumlah pengiraan dengan ketara.
Hasilnya ialah Perceiver AR boleh mencapai hasil pemodelan yang setanding dengan Transformer berdasarkan lebih banyak input, tetapi dengan prestasi yang lebih baik.
Mereka menulis, "Perceiver AR dapat mengenal pasti dan mempelajari corak konteks panjang yang mempunyai sekurang-kurangnya 100k token dalam tugas replikasi sintetik sebagai perbandingan, Transformer mempunyai had keras sebanyak 2048 token, Semakin banyak token." , semakin lama konteksnya dan semakin kompleks output program.
Berbanding dengan seni bina Transformer dan Transformer-XL yang menggunakan penyahkod tulen secara meluas, Perceiver AR adalah lebih cekap dan secara fleksibel boleh menukar sumber pengkomputeran sebenar yang digunakan semasa ujian mengikut belanjawan sasaran.
Makalah itu menulis bahawa dalam keadaan perhatian yang sama, masa jam dinding untuk mengira Perceiver AR adalah jauh lebih pendek, dan ia boleh menyerap lebih banyak konteks (iaitu lebih banyak simbol input) dengan belanjawan kuasa pengkomputeran yang sama:
Panjang konteks Transformer dihadkan kepada 2048 token, yang bersamaan dengan hanya menyokong 6 lapisan - kerana model yang lebih besar dan konteks yang lebih panjang memerlukan jumlah memori yang besar. Menggunakan konfigurasi 6 lapisan yang sama, kami boleh memanjangkan jumlah panjang konteks memori Transformer-XL kepada 8192 token. Perceiver AR boleh memanjangkan panjang konteks kepada 65k penanda, dan dengan pengoptimuman lanjut, ia dijangka melebihi 100k.
Semua ini menjadikan pengkomputeran lebih fleksibel: “Kami dapat mengawal jumlah pengiraan yang dihasilkan oleh model tertentu semasa ujian dengan lebih baik, membolehkan kami mencapai keseimbangan yang stabil antara kelajuan dan prestasi ."
Jaegle dan rakan sekerja juga menulis bahawa pendekatan ini berfungsi untuk sebarang jenis input dan tidak terhad kepada simbol perkataan. Contohnya piksel dalam imej boleh disokong:
Proses yang sama berfungsi untuk sebarang input yang boleh diisih, selagi teknik penyamaran sebab-musabab digunakan. Sebagai contoh, saluran RGB sesuatu imej boleh diisih mengikut tertib imbasan raster dengan menyahkod saluran warna R, G dan B bagi setiap piksel dalam turutan, mengikut tertib atau tidak tertib.
Pengarang menemui potensi besar dalam Perceiver dan menulis dalam kertas kerja, "Perceiver AR ialah calon yang ideal untuk model autoregresif tujuan am konteks panjang
Tetapi jika anda ingin mengejar Untuk kecekapan pengiraan yang lebih tinggi, satu lagi faktor ketidakstabilan tambahan perlu ditangani. Penulis menunjukkan bahawa komuniti penyelidikan juga baru-baru ini cuba mengurangkan keperluan pengiraan perhatian autoregresif melalui "sparsity" (iaitu, proses mengehadkan kepentingan yang diberikan kepada beberapa elemen input).
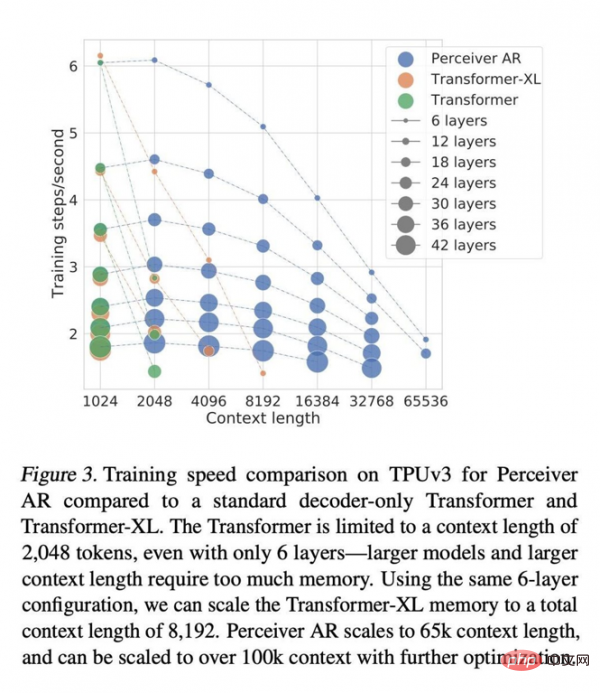
Dalam masa jam dinding yang sama, Perceiver AR dapat menjalankan lebih banyak daripada input dengan bilangan lapisan yang sama simbol, atau memendekkan dengan ketara masa pengiraan dengan bilangan larian simbol input yang sama. Penulis percaya bahawa fleksibiliti yang sangat baik ini boleh membawa kepada kaedah peningkatan kecekapan umum untuk rangkaian besar.
Tetapi sparsity juga mempunyai kekurangannya yang tersendiri, yang utama ialah ianya terlalu kaku. Kertas itu menulis, "Kelemahan menggunakan kaedah sparsity ialah sparsity ini mesti dicipta melalui pelarasan manual atau kaedah heuristik. Heuristik ini selalunya hanya terpakai untuk bidang tertentu dan selalunya sukar untuk disesuaikan dengan OpenAI dan NVIDIA pada 2019 The Sparse Transformer dikeluarkan pada 2017 adalah projek sparsity.
Mereka menjelaskan, "Sebaliknya, kerja kami tidak memerlukan penciptaan manual corak jarang pada lapisan perhatian, sebaliknya membenarkan rangkaian untuk belajar secara autonomi input konteks panjang yang memerlukan lebih perhatian dan perlu melaluinya. Rangkaian menyebarkan. "
Kertas itu juga menambah bahawa "operasi tumpuan silang awal mengurangkan bilangan kedudukan dalam urutan dan boleh dianggap sebagai satu bentuk pembelajaran yang jarang"
Dalam hal ini Cara ini sendiri yang dipelajari dengan cara ini mungkin menjadi satu lagi alat yang berkuasa dalam kit alat model pembelajaran mendalam dalam beberapa tahun akan datang.
Atas ialah kandungan terperinci DeepMind berkata: Model AI perlu menurunkan berat badan, dan autoregresi menjadi trend utama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI