
Rumah >Peranti teknologi >AI >Bolehkah Resapan Stabil mengatasi algoritma seperti JPEG dan meningkatkan pemampatan imej sambil mengekalkan kejelasan?
Bolehkah Resapan Stabil mengatasi algoritma seperti JPEG dan meningkatkan pemampatan imej sambil mengekalkan kejelasan?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-27 08:28:072192semak imbas
Model penjanaan imej berasaskan teks sangat popular Bukan sahaja model resapan yang popular, tetapi juga model Resapan Stable sumber terbuka.

Baru-baru ini, seorang jurutera perisian Switzerland, Matthias Bühlmann, secara tidak sengaja mendapati bahawa Stable Diffusion bukan sahaja boleh digunakan untuk menjana imej; >Mampatkan imej peta bit walaupun dengan nisbah mampatan yang lebih tinggi daripada JPEG dan WebP.
Contohnya, foto llama, imej asal ialah 768KB, yang boleh dimampatkan kepada 5.66KB menggunakan JPEG dan Stable Diffusion boleh terus memampatkannya kepada 4.98KB dan boleh memelihara lebih banyak butiran peleraian tinggi dan kurang artifak mampatan, jelas lebih baik daripada algoritma mampatan lain.

Walau bagaimanapun, kaedah pemampatan ini juga mempunyai kelemahan, iaitu tidak sesuai untuk memampatkan imej muka dan teks dalam sesetengah kes seterusnya, ia akan menjana beberapa imej asal tanpa sebarang kandungan .

Walaupun melatih semula pengekod auto juga boleh mencapai kesan mampatan yang serupa dengan Resapan Stabil, tetapi menggunakan Resapan Stabil Salah satu kelebihan utama adakah seseorang telah melabur berjuta-juta dana untuk membantu anda melatih satu, jadi mengapa anda membelanjakan wang untuk melatih model mampatan sekali lagi?
Cara Resapan Stabil memampatkan imejModel resapan mencabar penguasaan model generatif, dan model Resapan Stabil sumber terbuka yang sepadan juga mencetuskan revolusi artistik dalam komuniti pembelajaran mesin.

Resapan Stabil diperoleh dengan menggabungkan tiga rangkaian neural terlatih, iaitu pengekod auto variasi (VAE) , Model U-Net dan pengekod teks.
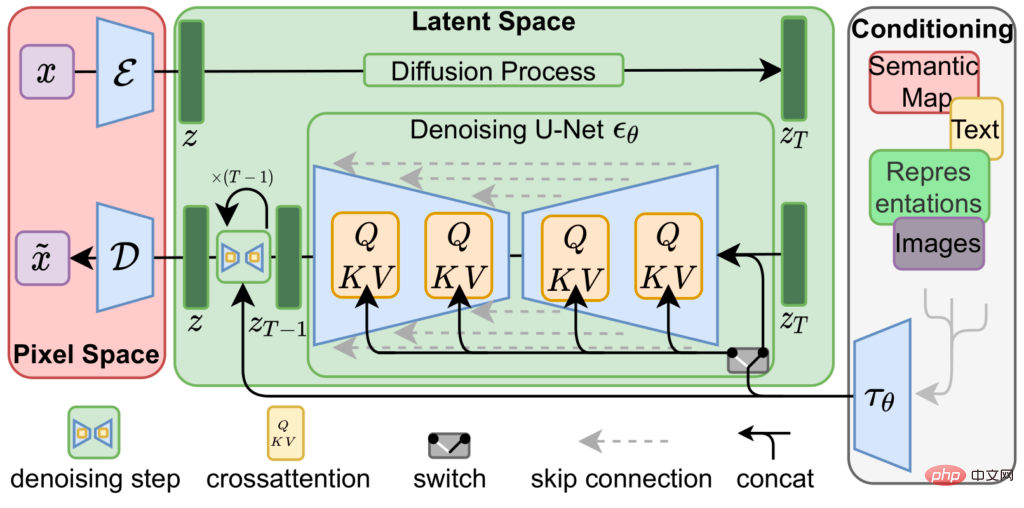
Pengekod auto variasi mengekod dan menyahkod imej dalam ruang imej untuk mendapatkan vektor perwakilan imej dalam ruang pendam , mewakili imej sumber (3x8 atau 4x8bit 512x512) sebagai vektor dengan peleraian lebih rendah (64x64) dengan ketepatan lebih tinggi (4x32bit) >.
Proses latihan VAE untuk mengekod imej ke dalam ruang terpendam terutamanya bergantung pada pembelajaran penyeliaan kendiri, iaitu input dan output adalah kedua-dua imej sumber, supaya model dilatih lebih lanjut , versi model yang berbeza Perwakilan ruang terpendam mungkin kelihatan berbeza.
Selepas memetakan semula dan mentafsir ke dalam imej berwarna 4 saluran menggunakan perwakilan ruang terpendam bagi Stable Diffusion v1.4, ia kelihatan seperti imej tengah di bawah, dalam imej sumber Ciri utama masih kelihatan .

Perlu diambil perhatian bahawa VAE dikodkan pergi balik sekali dan tidak rugi.
Sebagai contoh, selepas penyahkodan, nama ANNA pada pita biru tidak sejelas imej sumber, dan kebolehbacaan berkurangan dengan ketara.
Pengekod auto variasi dalam Stable Diffusion v1.4tidak begitu baik dalam mewakiliteks kecil dan imej muka , saya tidak tahu sama ada ia akan dipertingkatkan dalam v1.5.
Algoritma mampatan utama Resapan Stabil ialah menggunakan perwakilan ruang terpendam imej ini untuk menjana imej baharu daripada penerangan teks pendek.
Bermula daripada hingar rawak yang diwakili oleh ruang terpendam, keluarkan bunyi secara berulang bagi imej ruang terpendam menggunakan U-Net terlatih sepenuhnya, dan keluarkan model dengan perwakilan yang lebih mudah bahawa ia menyangka ia dalam bunyi ini Ramalan "melihat" adalah sedikit seperti apabila kita melihat awan, kita boleh memulihkan bentuk atau wajah dalam fikiran kita daripada bentuk yang tidak teratur .
Apabila Stable Diffusion digunakan untuk menjana imej, langkah denoising berulang ini dipandu oleh komponen ketiga, pengekod teks, yang menyediakan U-Net dengan maklumat mengenainya Maklumat tentang perkara yang perlu cuba lihat dalam bunyi.
Walau bagaimanapun, untuk tugasan pemampatan, tiada pengekod teks diperlukan, jadi proses percubaan hanya mencipta pengekodan rentetan kosong Digunakan untuk beritahu U-Net untuk melakukan unguide denoising semasa pembinaan semula imej.
Untuk menggunakan Stable Diffusion sebagai codec mampatan imej, algoritma perlu memampatkan perwakilan terpendam yang dihasilkan oleh VAE dengan berkesan.
Dalam eksperimen, boleh didapati bahawa menurunkan persampelan perwakilan terpendam atau terus menggunakan kaedah pemampatan imej lossy sedia ada akan mengurangkan kualiti imej yang dibina semula.
Tetapi penulis mendapati bahawa penyahkodan VAE nampaknya sangat berkesan dalam pengkuantitian perwakilan terpendam.
Penskalaan, pengapitan dan pemetaan semula potensi daripada titik terapung kepada integer tidak bertanda 8-bit hanya menghasilkan ralat pembinaan semula yang kecil.

Dengan mengukur perwakilan terpendam 8-bit, saiz data yang diwakili oleh imej kini ialah 64*64*4*8bit=16kB, yang adalah lebih kecil daripada tidak dimampatkan Imej sumber ialah 512*512*3*8bit=768kB
Jika bilangan bit perwakilan pendam kurang daripada 8 bit, ia tidak akan menghasilkan lebih baik keputusan.
Jika anda terus melakukan memaletkan dan mengadu pada imej, kesan pengkuantitian akan bertambah baik lagi.
Mencipta perwakilan palet menggunakan perwakilan terpendam 256*4*8 bit vektor dan Floyd-Steinberg dithering, memampatkan lagi saiz data kepada 64*64*8+256* 4*8bit =5kB

Penyelewengan palet angkasa terpendam akan menimbulkan bunyi, sekali gus memesongkan hasil penyahkodan. Walau bagaimanapun, memandangkan Stable Diffusion adalah berdasarkan penyingkiran bunyi terpendam, U-Net boleh digunakan untuk mengeluarkan bunyi yang disebabkan oleh jitter.
Selepas 4 lelaran, hasil pembinaan semula secara visual sangat hampir dengan versi tidak terkuantisasi.

Walaupun jumlah data sangat berkurangan (imej sumber adalah 155 kali lebih besar daripada imej termampat), kesannya sangat baik, tetapi ia juga memperkenalkan Beberapa artifak (seperti corak hati dalam imej asal yang tidak ada).
Menariknya, artifak yang diperkenalkan oleh skema mampatan ini mempunyai kesan yang lebih besar pada kandungan imej berbanding kualiti imej, dan imej yang dimampatkan dengan cara ini mungkin mengandungi jenis artifak mampatan ini.
Pengarang juga menggunakan zlib untuk melakukan pemampatan tanpa kehilangan palet dan indeks Dalam sampel ujian, kebanyakan keputusan mampatan adalah kurang daripada 5kb , tetapi kaedah pemampatan ini masih mempunyai lebih banyak ruang untuk pengoptimuman.
Untuk menilai codec mampatan ini, pengarang tidak menggunakan sebarang imej ujian standard yang terdapat dalam talian kerana imej di Internet berkemungkinan besar digunakan dalam latihan Kepekatan Resapan Stabil telah berlaku, dan memampatkan imej sedemikian boleh mengakibatkan kelebihan kontras yang tidak adil.
Untuk membuat perbandingan seadil mungkin, pengarang menggunakan tetapan pengekod kualiti tertinggi daripada perpustakaan imej Python, serta menambah pemampatan data tanpa kehilangan data JPG yang dimampat menggunakan mozjpeg perpustakaan.
Perlu diingat bahawa walaupun hasil Stable Diffusion secara subjektif kelihatan jauh lebih baik daripada imej mampat JPG dan WebP, mereka tidak jauh lebih baik dari segi ukuran standard seperti PSNR atau SSIM, tetapi tidak lebih teruk.
hanya memperkenalkan jenis artifak yang kurang ketara kerana ia menjejaskan kandungan imej lebih daripada kualiti imej.
Kaedah mampatan ini juga agak berbahaya, walaupun kualiti ciri yang dibina semula adalah tinggi, kandungan mungkin dipengaruhi oleh artifak mampatan, walaupun ia kelihatan sangat tajam.
Sebagai contoh, dalam imej ujian, walaupun Stable Diffusion sebagai codec jauh lebih baik dalam mengekalkan kualiti imej, malah butiran kamera boleh dipelihara ( yang sukar untuk kebanyakan algoritma pemampatan tradisional), tetapi kandungannya masih dipengaruhi oleh artifak mampatan dan ciri halus seperti bentuk bangunan mungkin berubah.

Walaupun sememangnya mustahil untuk mengenal pasti lebih banyak nilai sebenar dalam imej termampat JPG berbanding dalam imej mampat Resapan Stabil, mampatan Resapan Stabil hasil kualiti visual yang tinggi boleh memperdayakan kerana artifak mampatan dalam JPG dan WebP lebih mudah dikesan.
Jika anda juga ingin menghasilkan semula percubaan, pengarang telah membuka sumber kod pada Colab.
Pautan kod: https://colab.research.google.com/drive/1Ci1VYHuFJK5eOX9TB0Mq4NsqkeDrMaaH?usp=sharing >
Akhirnya, penulis mengatakan bahawa eksperimen yang direka dalam artikel itu masih agak mudah, tetapi kesannya masih mengejutkan, Masih banyak ruang untuk penambahbaikan dalam masa depan .
Atas ialah kandungan terperinci Bolehkah Resapan Stabil mengatasi algoritma seperti JPEG dan meningkatkan pemampatan imej sambil mengekalkan kejelasan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI