
Rumah >Peranti teknologi >AI >Penyelidikan menunjukkan bahawa pembelajaran berjalin berwajaran berasaskan persamaan boleh menangani masalah 'amnesia' dalam pembelajaran mendalam dengan berkesan
Penyelidikan menunjukkan bahawa pembelajaran berjalin berwajaran berasaskan persamaan boleh menangani masalah 'amnesia' dalam pembelajaran mendalam dengan berkesan

- 王林ke hadapan
- 2023-04-26 21:40:07928semak imbas
Tidak seperti manusia, rangkaian saraf tiruan dengan cepat melupakan maklumat yang dipelajari sebelum ini apabila mempelajari perkara baharu dan mesti dilatih semula dengan menyelangi maklumat lama dan baharu bagaimanapun, menyelang semua maklumat lama sangat memakan masa dan mungkin tidak diperlukan. Ia mungkin mencukupi untuk memasukkan hanya maklumat lama yang hampir sama dengan maklumat baharu.
Baru-baru ini, Prosiding Akademi Sains Kebangsaan (PNAS) menerbitkan kertas kerja, "Pembelajaran dalam rangkaian saraf dalam dan otak dengan pembelajaran berjalin berwajaran persamaan", yang ditulis oleh seorang felo Persatuan Diraja Kanada, Diterbitkan oleh pasukan ahli sains saraf terkenal Bruce McNaughton. Kerja mereka mendapati bahawa dengan menjalankan latihan interleaving berwajaran persamaan bagi maklumat lama dengan maklumat baharu, rangkaian dalam boleh mempelajari perkara baharu dengan cepat, bukan sahaja mengurangkan kadar lupa, tetapi juga menggunakan data yang kurang ketara.
Pengarang juga membuat hipotesis bahawa pemberat persamaan boleh dicapai dalam otak dengan menjejaki trajektori keceriaan berterusan neuron aktif baru-baru ini dan dinamik penarik neurodinamik. Penemuan ini boleh membawa kepada kemajuan selanjutnya dalam neurosains dan pembelajaran mesin.
Latar Belakang Penyelidikan
Memahami cara otak belajar sepanjang hayat kekal sebagai cabaran jangka panjang.
Dalam rangkaian saraf tiruan (ANN), penyepaduan maklumat baharu terlalu cepat boleh menghasilkan gangguan bencana, di mana pengetahuan yang diperoleh sebelum ini hilang secara tiba-tiba. Teori Sistem Pembelajaran Pelengkap (CLST) mencadangkan bahawa ingatan baru boleh disepadukan secara beransur-ansur ke dalam neokorteks dengan mengaitkannya dengan pengetahuan sedia ada.
CLST menyatakan bahawa otak bergantung pada sistem pembelajaran pelengkap: hippocampus (HC) untuk pemerolehan pantas kenangan baharu, dan neocortex (NC) untuk penyepaduan beransur-ansur data baharu ke dalam konteks pengetahuan berstruktur yang tidak relevan. Semasa "tempoh luar talian", seperti semasa tidur dan rehat yang tenang, HC mencetuskan ulang tayang pengalaman terbaharu dalam NC, manakala NC secara spontan mengambil dan menyilangkan perwakilan kategori sedia ada. Main semula bersilang membolehkan pelarasan tambahan berat sinaptik NC dalam cara penurunan kecerunan untuk mencipta perwakilan kategori bebas konteks yang menyepadukan kenangan baharu secara elegan dan mengatasi gangguan bencana. Banyak kajian telah berjaya menggunakan ulang tayang berjalin untuk mencapai pembelajaran sepanjang hayat rangkaian saraf.
Namun, apabila mengaplikasikan CLST dalam amalan, terdapat dua isu penting yang perlu diselesaikan. Pertama, bagaimanakah interleaving komprehensif maklumat boleh berlaku apabila otak tidak dapat mengakses semua data lama? Satu penyelesaian yang mungkin ialah "latihan semu", di mana input rawak boleh mencetuskan main balik generatif perwakilan dalaman tanpa akses eksplisit kepada contoh yang dipelajari sebelum ini. Dinamik seperti penarik mungkin membenarkan otak melengkapkan "latihan pseudo", tetapi kandungan "latihan palsu" masih belum dijelaskan. Oleh itu, persoalan kedua ialah adakah selepas setiap aktiviti pembelajaran baru, otak mempunyai masa yang mencukupi untuk mencantumkan semua maklumat yang dipelajari sebelum ini.
Algoritma Similarity-Weighted Interleaved Learning (SWIL) dianggap sebagai penyelesaian kepada masalah kedua, yang menunjukkan bahawa hanya interleaving mempunyai persamaan representasi yang ketara dengan maklumat baharu, maklumat lama mungkin mencukupi. Kajian tingkah laku empirikal menunjukkan bahawa maklumat baharu yang sangat konsisten boleh disepadukan dengan cepat ke dalam pengetahuan berstruktur NC dengan sedikit gangguan. Ini menunjukkan bahawa kelajuan maklumat baharu disepadukan bergantung pada ketekalannya dengan pengetahuan sedia ada. Diilhamkan oleh keputusan tingkah laku ini, dan dengan mengkaji semula taburan gangguan bencana yang diperoleh sebelum ini antara kategori, McClelland et al menunjukkan bahawa SWIL boleh digunakan dalam konteks dengan dua kategori hipernim (mis., "buah" ialah "epal" dan "pisang" ""), setiap zaman menggunakan kurang daripada 2.5 kali jumlah data untuk mempelajari maklumat baharu, mencapai prestasi yang sama seperti melatih rangkaian pada semua data. Walau bagaimanapun, para penyelidik tidak menemui kesan yang sama apabila menggunakan set data yang lebih kompleks, menimbulkan kebimbangan mengenai kebolehskalaan algoritma.
Eksperimen menunjukkan bahawa rangkaian neural tiruan tak linear dalam boleh mempelajari maklumat baharu dengan menjalin subset maklumat lama sahaja yang berkongsi sejumlah besar persamaan perwakilan dengan maklumat baharu. Dengan menggunakan algoritma SWIL, ANN dapat mempelajari maklumat baharu dengan cepat dengan tahap ketepatan yang sama dan gangguan minimum, sambil menggunakan jumlah maklumat lama yang sangat kecil yang dibentangkan dengan setiap zaman, yang bermaksud penggunaan data yang tinggi dan pembelajaran pantas.
Pada masa yang sama, SWIL juga boleh digunakan pada rangka kerja pembelajaran jujukan. Di samping itu, mempelajari kategori baharu boleh meningkatkan penggunaan data. Jika maklumat lama mempunyai persamaan yang sangat sedikit dengan kategori yang dipelajari sebelum ini, maka jumlah maklumat lama yang disampaikan akan menjadi lebih kecil, yang berkemungkinan menjadi kes sebenar pembelajaran manusia.
Akhir sekali, penulis mencadangkan model teori tentang cara SWIL dilaksanakan dalam otak, dengan kecenderungan keterujaan berkadar dengan pertindihan maklumat baharu.
Model dinamik DNS digunakan pada set data pengelasan imej
Eksperimen oleh McClelland et al menunjukkan bahawa pada kelinearan mendalam dengan satu lapisan tersembunyi Dalam rangkaian , SWIL boleh mempelajari kategori baharu, serupa dengan Fully Interleaved Learning (FIL), yang menyelangi keseluruhan kategori lama dengan kategori baharu, tetapi jumlah data yang digunakan dikurangkan sebanyak 40%.
Walau bagaimanapun, rangkaian telah dilatih pada set data yang sangat mudah dengan hanya dua kategori hipernim, yang menimbulkan persoalan tentang kebolehskalaan algoritma.
Mula-mula teroka cara pembelajaran kategori berbeza berkembang dalam rangkaian neural linear dalam dengan satu lapisan tersembunyi untuk set data yang lebih kompleks seperti Fashion-MNIST. Selepas mengalih keluar kategori "but" dan "beg", model itu mencapai ketepatan ujian sebanyak 87% pada baki lapan kategori. Pasukan pengarang kemudiannya melatih semula model untuk mempelajari kelas "boot" (baharu) di bawah dua keadaan berbeza, setiap satu diulang 10 kali:
- Pembelajaran Berfokus (FoL), iaitu. Hanya kelas "but" baharu sahaja dibentangkan;
- Pembelajaran interleaved sepenuhnya (FIL), iaitu semua kategori (kategori baharu + kategori yang dipelajari sebelumnya) dibentangkan dengan kebarangkalian yang sama. Dalam kedua-dua kes, sejumlah 180 imej dipersembahkan setiap zaman, dengan imej yang sama dalam setiap zaman.
Rangkaian telah diuji pada sejumlah 9000 imej yang tidak pernah dilihat, dengan set data ujian terdiri daripada 1000 imej setiap kelas, tidak termasuk kelas "beg" . Latihan berhenti apabila prestasi rangkaian mencapai asimtot.
Seperti yang dijangkakan, FoL menyebabkan gangguan kepada kategori lama, manakala FIL mengatasinya (Rajah 1, lajur 2). Seperti yang dinyatakan di atas, gangguan FoL terhadap data lama berbeza mengikut kategori, yang merupakan sebahagian daripada inspirasi asal untuk SWIL dan mencadangkan hubungan persamaan hierarki antara kategori "but" baharu dan kategori lama. Sebagai contoh, penarikan semula "sneaker" ("sneakers") dan "sandal" ("sandal") berkurangan lebih cepat daripada "seluar" ("seluar") (Rajah 1, lajur 2), mungkin disebabkan oleh penyepaduan baru Kelas "but" secara selektif menukar pemberat sinaptik yang mewakili kelas "sneaker" dan "sandal", menyebabkan lebih banyak gangguan.
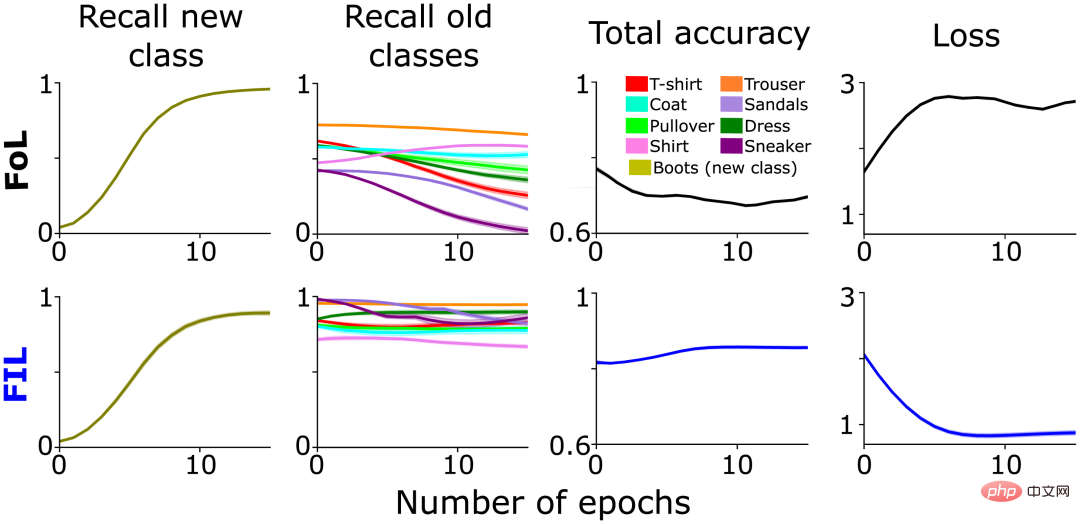
Rajah 1: Analisis perbandingan prestasi rangkaian pra-latihan dalam mempelajari kelas "boot" baharu dalam dua kes: FoL (atas) dan FIL (bawah). Dari kiri ke kanan, ingat untuk meramalkan kelas "but" baharu (zaitun), memanggil semula untuk kelas sedia ada (diplot dalam warna berbeza), ketepatan keseluruhan (skor tinggi bermakna ralat rendah) dan kehilangan entropi silang (keseluruhan Ukuran ralat) lengkung ialah fungsi bilangan zaman pada set data ujian yang disimpan.
Kira persamaan antara kategori yang berbeza
Apabila FoL mempelajari kategori baharu, prestasi klasifikasi pada kategori lama yang serupa akan menurun dengan ketara.
Hubungan antara persamaan atribut berbilang kategori dan pembelajaran telah diterokai sebelum ini, dan telah ditunjukkan bahawa rangkaian linear dalam boleh memperoleh atribut konsisten yang diketahui dengan cepat. Sebaliknya, menambah cabang baharu atribut yang tidak konsisten pada hierarki kategori sedia ada memerlukan pembelajaran yang perlahan, meningkat dan berperingkat.
Dalam kerja semasa, pasukan pengarang menggunakan kaedah yang dicadangkan untuk mengira persamaan pada tahap ciri. Secara ringkas, persamaan kosinus antara purata vektor pengaktifan setiap kelas kelas sedia ada dan baharu dalam lapisan tersembunyi sasaran (biasanya lapisan kedua terakhir) dikira. Rajah 2A menunjukkan matriks persamaan yang dikira oleh pasukan pengarang berdasarkan fungsi pengaktifan lapisan kedua dari rangkaian pra-latihan untuk kategori "but" baharu dan kategori lama berdasarkan dataset MNIST Fesyen.
Persamaan antara kategori adalah konsisten dengan persepsi visual kita terhadap objek. Sebagai contoh, dalam rajah pengelompokan hierarki (Rajah 2B), kita boleh melihat hubungan antara kelas "but" dan kelas "sneaker" dan "sandal", serta antara "baju" ("baju") dan "t. -shirt" (" T-shirt") mempunyai persamaan yang tinggi antara kategori. Matriks persamaan (Rajah 2A) sepadan dengan tepat dengan matriks kekeliruan (Rajah 2C). Semakin tinggi persamaan, lebih mudah untuk mengelirukan, sebagai contoh, kategori "baju" mudah dikelirukan dengan kategori "T-shirt", "jumper" dan "jaket", yang menunjukkan bahawa ukuran persamaan meramalkan dinamik pembelajaran daripada rangkaian saraf.
Dalam graf hasil FoL dalam bahagian sebelumnya (Rajah 1), terdapat keluk persamaan kelas yang serupa dalam keluk ingat semula kategori lama. Berbanding dengan kategori lama yang berbeza ("seluar", dll.), FoL dengan cepat melupakan kategori lama yang serupa ("sneaker" dan "sandal") apabila mempelajari kategori "but" baharu.
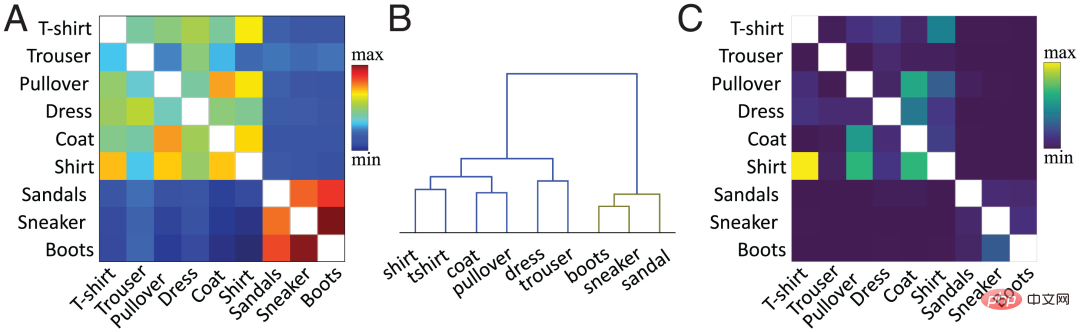
Rajah 2: (A) Pasukan pengarang mengira hasil berdasarkan fungsi pengaktifan lapisan kedua dari pra- rangkaian terlatih. Matriks persamaan dengan kelas dan kelas "boot" baharu, di mana nilai pepenjuru (persamaan untuk kelas yang sama diplot dalam warna putih) dialih keluar. (B) Pengelompokan hierarki matriks persamaan dalam A. (C) Matriks kekeliruan yang dihasilkan oleh algoritma FIL selepas latihan untuk mempelajari kelas "boot". Nilai pepenjuru dialih keluar untuk kejelasan skala.
Rangkaian neural linear mendalam merealisasikan pembelajaran yang pantas dan cekap tentang perkara baharu
Seterusnya, 3 syarat baharu ditambah berdasarkan dua syarat pertama , dinamik pembelajaran klasifikasi baharu telah dikaji, di mana setiap keadaan diulang 10 kali:
- FoL (jumlah n=6000 imej/zaman);
- FIL (jumlah n=54000 imej/zaman, 6000 imej/kelas); Interleaved Learning, PIL) menggunakan subset kecil imej (jumlah n = 350 imej/zaman, lebih kurang 39 imej/kelas), dan imej bagi setiap kategori (kategori baharu + kategori sedia ada) diproses dengan pemaparan Probabilistik yang sama; 🎜> SWIL, melatih semula setiap zaman menggunakan jumlah imej yang sama seperti PIL, tetapi menimbang imej kelas sedia ada berdasarkan persamaan dengan kelas "but" (baharu); ), latih semula menggunakan bilangan imej kelas "boot" yang sama seperti SWIL, tetapi pemberat imej kelas sedia ada adalah sama (Rajah 3A).
- Pasukan pengarang menggunakan set data ujian yang sama yang dinyatakan di atas (jumlah n=9000 imej). Latihan dihentikan apabila prestasi rangkaian saraf mencapai asimtot dalam setiap keadaan. Walaupun kurang data latihan digunakan setiap zaman, ketepatan meramalkan kelas "but" baharu mengambil masa lebih lama untuk mencapai asimtot, dan PIL mempunyai ingatan semula yang lebih rendah berbanding FIL (H=7.27, P
0.05). Pembelajaran kelas "boot" baharu dalam EqWIL (H=10.99, P
Pasukan pengarang menggunakan dua kaedah berikut untuk membandingkan SWIL dan FIL:
Nisbah memori, iaitu nisbah bilangan imej yang disimpan dalam FIL dan SWIL, menunjukkan storan Jumlah data dikurangkan
Nisbah kelajuan, iaitu nisbah jumlah bilangan kandungan yang dibentangkan dalam FIL dan SWIL untuk mencapai ketepatan tepu ingatan kategori baharu, menunjukkan; bahawa masa yang diperlukan untuk mempelajari kategori baharu dikurangkan.
- SWIL boleh mempelajari kandungan baharu dengan keperluan data yang dikurangkan, nisbah memori = 154.3x (54000/350), dan lebih pantas, nisbah pecutan = 77.1x ( 54000/(350) ×2)). Walaupun bilangan imej yang berkaitan dengan kandungan baharu adalah lebih kecil, model boleh mencapai prestasi yang sama dengan menggunakan SWIL, yang memanfaatkan struktur hierarki pengetahuan terdahulu model. SWIL menyediakan penimbal perantaraan antara PIL dan EqWIL, membenarkan penyepaduan kategori baharu dengan gangguan minimum kepada kategori sedia ada.
(A) Pasukan pengarang pra-melatih rangkaian saraf untuk mempelajari kategori "but" baharu (zaitun hijau) sehingga prestasi stabil: 1) FoL (jumlah n=6000 imej/zaman 2) FIL (jumlah n=54000 imej/zaman 3) PIL (jumlah n=350 imej/zaman) 4 ) SWIL (jumlah n=350 imej/zaman) dan 5) EqWIL (jumlah n=350 imej/zaman). (B) FoL (hitam), FIL (biru), PIL (coklat), SWIL (magenta) dan EqWIL (emas) meramalkan kategori baharu, kategori lama yang serupa (“sneaker” dan “sandal”) dan kategori lama yang berbeza Kadar ingatan, jumlah ketepatan meramal semua kategori, dan kehilangan entropi silang pada set data ujian, di mana abscissa ialah bilangan zaman. 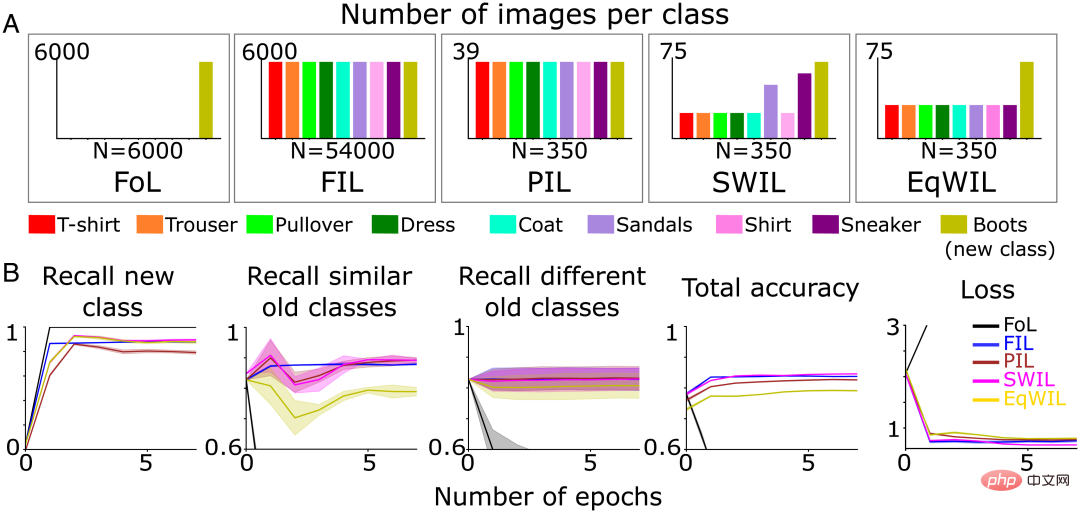
Mempelajari kategori baharu dalam CNN menggunakan SWIL berdasarkan CIFAR10
Seterusnya, untuk menguji sama ada SWIL boleh berfungsi dalam persekitaran yang lebih kompleks, The pasukan pengarang melatih CNN bukan linear 6 lapisan (Rajah 4A) dengan lapisan keluaran yang disambungkan sepenuhnya untuk mengecam imej bagi baki 8 kategori berbeza (kecuali "kucing" dan "kereta") dalam set data CIFAR10. Mereka juga melatih semula model untuk mempelajari kelas "kucing" di bawah 5 keadaan latihan berbeza yang ditakrifkan sebelum ini (FoL, FIL, PIL, SWIL dan EqWIL). Rajah 4C menunjukkan taburan imej dalam setiap kategori di bawah 5 keadaan. Jumlah imej setiap zaman ialah 2400 untuk keadaan SWIL, PIL dan EqWIL, manakala jumlah imej setiap zaman ialah 45000 dan 5000 untuk FIL dan FoL masing-masing. Pasukan pengarang melatih rangkaian secara berasingan untuk setiap situasi sehingga prestasi stabil. Mereka menguji model pada sejumlah 9000 imej yang tidak dilihat sebelum ini (1000 imej/kelas, tidak termasuk kelas "kereta"). Rajah 4B ialah matriks persamaan yang dikira oleh pasukan pengarang berdasarkan set data CIFAR10. Kelas "kucing" lebih serupa dengan kelas "anjing", manakala kelas haiwan lain tergolong dalam cawangan yang sama (Rajah 4B kiri).Menurut rajah pokok (Rajah 4B), kategori "trak" ("trak"), "kapal" ("kapal") dan "pesawat" ("kapal terbang") dipanggil kategori lama yang berbeza, kecuali " kucing" "Baki kategori haiwan di luar kategori dipanggil kategori lama yang serupa. Untuk FoL, model mempelajari kelas "kucing" baharu tetapi melupakan kelas lama. Sama seperti keputusan set data Fashion-MNIST, terdapat kecerunan gangguan dalam kedua-dua kelas "anjing" (paling serupa dengan kelas "kucing") dan kelas "trak" (paling kurang serupa dengan kelas "kucing" ), antaranya kelas "anjing" yang dilupakan mempunyai kadar tertinggi, manakala kategori "trak" mempunyai kadar lupa yang paling rendah.
Seperti yang ditunjukkan dalam Rajah 4D, algoritma FIL mengatasi gangguan bencana apabila mempelajari kelas "kucing" baharu. Untuk algoritma PIL, model menggunakan 18.75 kali jumlah data dalam setiap zaman untuk mempelajari kelas "kucing" baharu, tetapi kadar ingatan semula kelas "kucing" adalah lebih tinggi daripada FIL (H=5.72, P0.05; lihat Jadual 2 dan Rajah 4D). SWIL mempunyai kadar ingatan yang lebih tinggi untuk kelas "kucing" baharu daripada PIL (H=7.89, P
FIL, PIL, SWIL dan EqWIL mempunyai prestasi yang sama dalam meramalkan kategori lama yang berbeza (H=0.6, P>0.05). SWI menggabungkan kelas "kucing" baharu lebih baik daripada PIL dan membantu mengatasi gangguan pemerhatian dalam EqWIL. Berbanding dengan FIL, menggunakan SWIL untuk mempelajari kategori baharu adalah lebih pantas, nisbah pecutan = 31.25x (45000×10/(2400×6)), manakala menggunakan kurang data (nisbah memori = 18.75x). Keputusan ini menunjukkan bahawa SWIL boleh mempelajari kategori baharu perkara dengan berkesan walaupun pada CNN bukan linear dan set data yang lebih realistik.
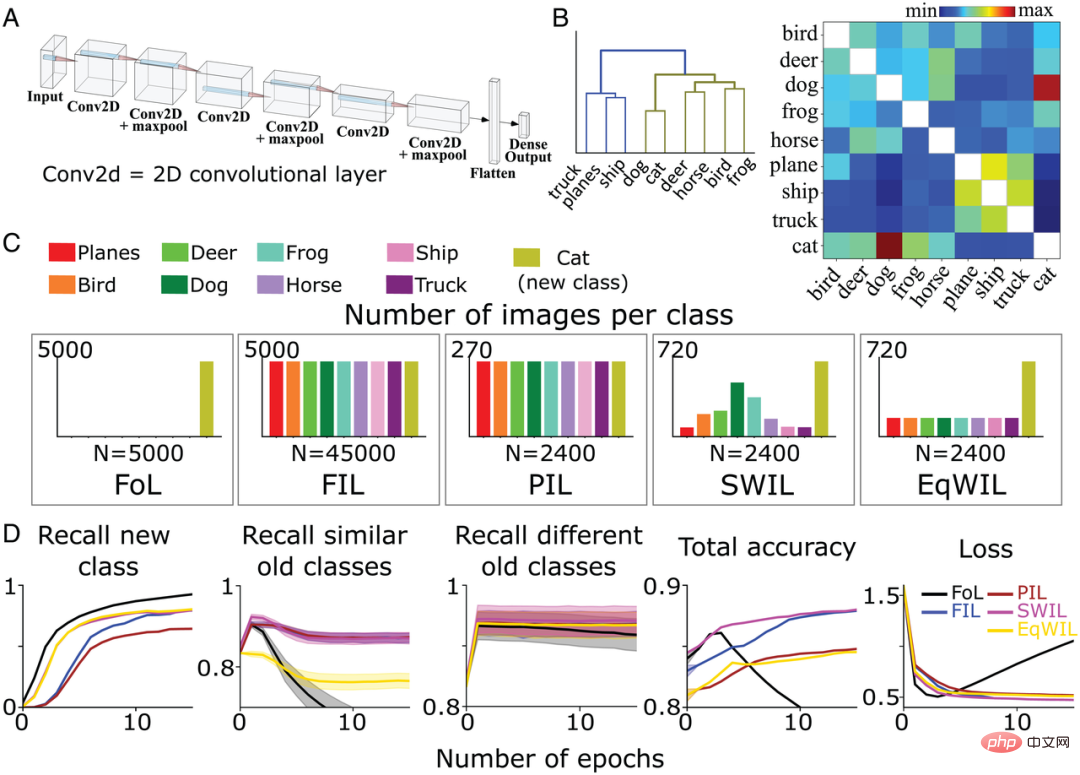
Rajah 4: (A) Pasukan pengarang menggunakan CNN bukan linear 6 lapisan dengan lapisan keluaran bersambung sepenuhnya untuk belajar data CIFAR10 8 kategori perkara yang perlu diberi tumpuan. (B) Matriks persamaan (kanan) dikira oleh pasukan pengarang berdasarkan fungsi pengaktifan lapisan konvolusi terakhir selepas mempersembahkan kelas "kucing" baharu. Menggunakan pengelompokan hierarki pada matriks persamaan (kiri) menunjukkan pengelompokan dua kategori hipernim Haiwan (hijau zaitun) dan Kenderaan (biru) dalam dendrogram. (C) Pasukan pengarang telah melatih CNN untuk mempelajari kelas "kucing" baharu (hijau zaitun) di bawah 5 keadaan berbeza sehingga prestasi stabil: 1) FoL (jumlah n=5000 imej/zaman 2) FIL (jumlah n.); =45000 imej/zaman 3) PIL (jumlah n=2400 imej/zaman 4) SWIL (jumlah n=2400 imej/zaman); Setiap keadaan diulang 10 kali. (D) FoL (hitam), FIL (biru), PIL (coklat), SWIL (magenta) dan EqWIL (emas) meramalkan kelas baharu, kelas lama yang serupa (kelas haiwan lain dalam dataset CIFAR10) dan kelas lama yang berbeza ( Recall kadar "kapal terbang", "kapal" dan "trak"), jumlah ketepatan ramalan semua kategori, dan kehilangan entropi silang pada set data ujian, di mana abscissa ialah bilangan zaman.
Impak konsistensi kandungan baharu dengan kategori lama terhadap masa pembelajaran dan data yang diperlukan
Jika kandungan baharu boleh ditambah pada kandungan sebelumnya Dalam kategori yang dipelajari tanpa memerlukan perubahan besar pada rangkaian, kedua-duanya dikatakan konsisten. Berdasarkan rangka kerja ini, mempelajari kategori baharu yang mengganggu kategori sedia ada yang lebih sedikit (konsistensi tinggi) boleh disepadukan dengan lebih mudah ke dalam rangkaian berbanding mempelajari kategori baharu yang mengganggu berbilang kategori sedia ada (konsistensi rendah).
Untuk menguji inferens di atas, pasukan pengarang menggunakan CNN pra-latihan dari bahagian sebelumnya untuk mempelajari kategori "kereta" baharu di bawah kesemua 5 keadaan pembelajaran yang diterangkan sebelum ini . Rajah 5A menunjukkan matriks persamaan bagi kategori "kereta" Berbanding dengan kategori sedia ada yang lain, "kereta" dan "trak", "kapal" dan "pesawat" berada di bawah nod aras yang sama, menunjukkan bahawa mereka lebih serupa. Untuk pengesahan lanjut, pasukan pengarang melakukan analisis visualisasi pengurangan dimensi t-SNE pada lapisan pengaktifan yang digunakan untuk pengiraan persamaan (Rajah 5B). Kajian mendapati bahawa kelas "kereta" bertindih dengan ketara dengan kelas kenderaan lain ("trak," "kapal," dan "pesawat"), manakala kelas "kucing" bertindih dengan kelas haiwan lain ("anjing," "katak" , "kuda" ("kuda"), "burung" ("burung") dan "rusa" ("rusa")) bertindih.
Selaras dengan jangkaan pasukan pengarang, FoL akan menghasilkan gangguan bencana apabila mempelajari kategori "kereta", dan lebih mengganggu kategori lama yang serupa Ini diatasi dengan menggunakan FIL (Rajah 5D). Untuk PIL, SWIL dan EqWIL, terdapat sejumlah n = 2000 imej setiap zaman (Rajah 5C). Menggunakan algoritma SWIL, model boleh mempelajari kategori "kereta" baharu dengan ketepatan yang serupa dengan FIL (H=0.79, P>0.05), dengan gangguan minimum kepada kategori sedia ada (termasuk kategori yang serupa dan berbeza). Seperti yang ditunjukkan dalam lajur 2 Rajah 5D, menggunakan EqWIL, model mempelajari kelas "kereta" baharu dengan cara yang sama seperti SWIL, tetapi dengan tahap gangguan yang lebih tinggi dengan kategori lain yang serupa (cth., "trak") (H=53.81 , P
Berbanding dengan FIL, SWIL boleh mempelajari kandungan baharu dengan lebih pantas, nisbah pecutan = 48.75x (45000×12/(2000×6)), dan keperluan memori dikurangkan, nisbah memori = 22.5x. Berbanding dengan "kucing" (48.75x lwn. 31.25x), "kereta" boleh belajar dengan lebih pantas dengan meninggalkan lebih sedikit kelas (seperti "trak", "kapal" dan "pesawat"), manakala "kucing" mempunyai lebih banyak Banyak kategori (seperti sebagai "anjing", "katak", "kuda", "katak" dan "rusa") bertindih. Eksperimen simulasi ini menunjukkan bahawa jumlah data kategori lama yang diperlukan untuk pembelajaran silang dan dipercepatkan bagi kategori baharu bergantung pada ketekalan maklumat baharu dengan pengetahuan sedia ada.
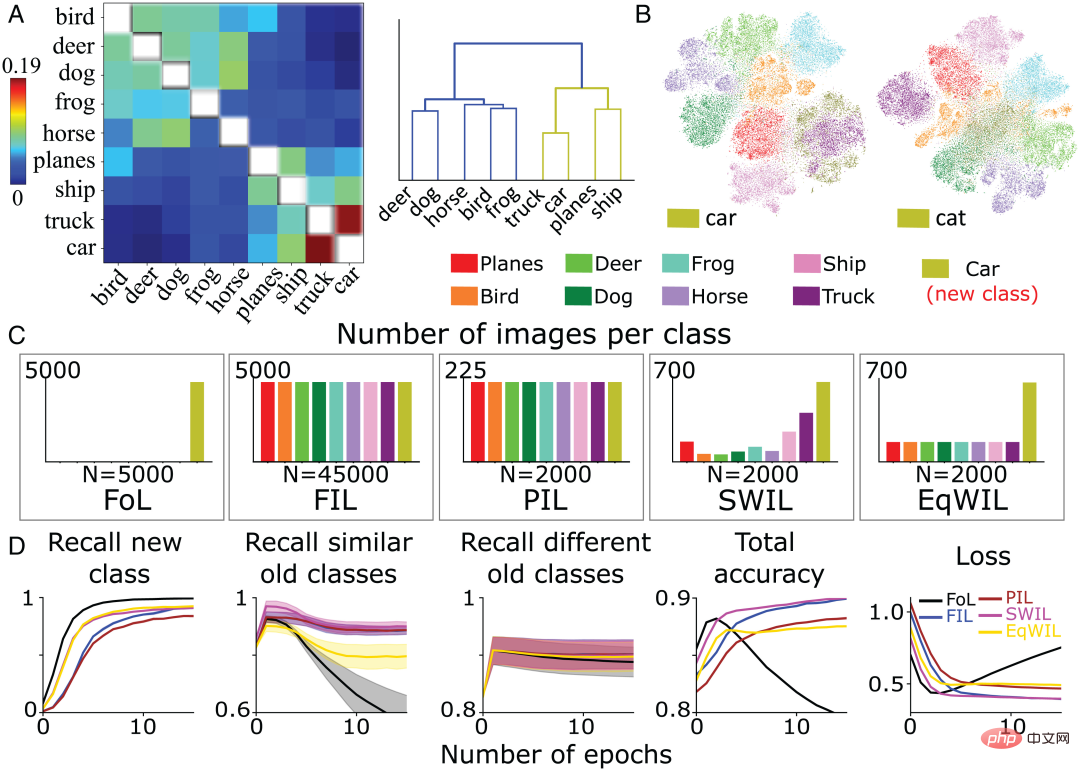
Rajah 5: (A) Pasukan pengarang mengira matriks persamaan berdasarkan fungsi pengaktifan lapisan kedua (kiri) , dan hasil pengelompokan hierarki matriks persamaan selepas mempersembahkan kategori "kereta" baharu (kanan). (B) Model mempelajari kategori "kereta" baharu dan kategori "kucing" masing-masing Selepas lapisan konvolusi terakhir melepasi fungsi pengaktifan, pasukan pengarang melaksanakan hasil visualisasi pengurangan dimensi t-SNE. (C) Pasukan pengarang telah melatih CNN untuk mempelajari kelas "kereta" baharu (hijau zaitun) di bawah 5 keadaan berbeza sehingga prestasi stabil: 1) FoL (jumlah n=5000 imej/zaman 2) FIL (jumlah n =45000 imej/zaman 3) PIL (jumlah n=2000 imej/zaman 4) SWIL (jumlah n=2000 imej/zaman); (D) FoL (hitam), FIL (biru), PIL (coklat), SWIL (magenta) dan EqWIL (emas) meramalkan kategori baharu, kategori lama yang serupa (“kapal terbang”, “kapal” dan “trak”) dan Penarikan balik kadar kategori lama yang berbeza (kategori haiwan lain dalam set data CIFAR10), jumlah ketepatan ramalan semua kategori, dan kehilangan entropi silang pada set data ujian, di mana abscissa ialah bilangan zaman. Setiap graf menunjukkan purata 10 ulangan, dan kawasan berlorek ialah ±1 SEM.
Menggunakan SWIL untuk pembelajaran urutan
Seterusnya, pasukan pengarang menguji sama ada SWIL boleh digunakan untuk mempelajari kandungan baharu yang dibentangkan dalam bentuk bersiri ( rangka pembelajaran urutan). Untuk tujuan ini, mereka menggunakan model CNN terlatih dalam Rajah 4 untuk mempelajari kelas "kucing" (tugas 1) dalam set data CIFAR10 di bawah keadaan FIL dan SWIL, dilatih hanya pada baki 9 kategori CIFAR10, dan kemudian dilatih pada setiap syarat Seterusnya melatih model untuk mempelajari kelas "kereta" baharu (tugasan 2). Lajur pertama Rajah 6 menunjukkan taburan bilangan imej dalam kategori lain apabila mempelajari kategori "kereta" di bawah keadaan SWIL (jumlah n=2500 imej/zaman). Ambil perhatian bahawa meramalkan kelas "kucing" juga mempelajari silang kelas "kereta" baharu. Memandangkan prestasi model adalah terbaik dalam keadaan FIL, SWIL hanya membandingkan hasil dengan FIL.
Seperti yang ditunjukkan dalam Rajah 6, keupayaan SWIL untuk meramalkan kategori baharu dan lama adalah bersamaan dengan FIL (H=14.3, P>0.05). Model ini menggunakan algoritma SWIL untuk mempelajari kategori "kereta" baharu dengan lebih pantas, dengan nisbah pecutan 45x (50000×20/(2500×8)), dan jejak memori setiap zaman adalah 20 kali kurang daripada FIL. Apabila model mempelajari kategori "kucing" dan "kereta", bilangan imej yang digunakan setiap zaman di bawah keadaan SWIL (nisbah memori dan nisbah kelajuan masing-masing ialah 18.75x dan 20x) adalah kurang daripada keseluruhan data yang digunakan setiap zaman di bawah FIL set keadaan (nisbah memori dan nisbah kelajuan masing-masing 31.25x dan 45x) dan masih mempelajari kategori baharu dengan cepat. Memperluas idea ini, apabila bilangan kategori yang dipelajari terus meningkat, pasukan pengarang menjangkakan masa pembelajaran model dan penyimpanan data akan dikurangkan secara eksponen, membolehkannya mempelajari kategori baharu dengan lebih cekap, mungkin mencerminkan apa yang berlaku apabila otak manusia sebenarnya belajar.
Hasil eksperimen menunjukkan bahawa SWIL boleh menyepadukan berbilang kelas baharu dalam rangka kerja pembelajaran jujukan, membolehkan rangkaian saraf meneruskan pembelajaran tanpa gangguan.
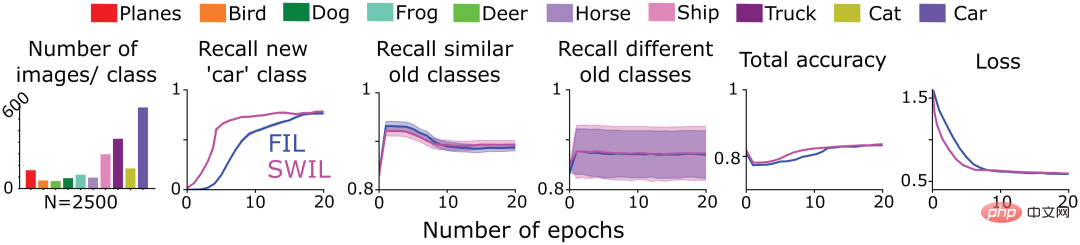
Rajah 6: Pasukan pengarang melatih CNN 6 lapisan untuk mempelajari kelas "kucing" baharu (tugasan 1 ), dan kemudian mempelajari kelas "kereta" (Tugas 2) sehingga prestasi stabil dalam dua kes berikut: 1) FIL: Mengandungi semua kelas lama (dilukis dalam warna berbeza) dan kelas baharu yang dibentangkan dengan kebarangkalian yang sama ("kucing"/" imej kereta "); 2) SWIL: ditimbang mengikut persamaan dengan kategori baharu ("kucing"/"kereta") dan menggunakan contoh kategori lama mengikut perkadaran. Sertakan juga kelas "kucing" yang dipelajari dalam Tugasan 1 dan beratkannya berdasarkan persamaan kelas "kereta" yang dipelajari dalam Tugasan 2. Subfigura pertama menunjukkan taburan bilangan imej yang digunakan dalam setiap zaman. Subfigura yang selebihnya masing-masing menunjukkan kadar ingatan semula FIL (biru) dan SWIL (magenta) dalam meramalkan kategori baharu, kategori lama yang serupa dan kategori lama yang berbeza, dan meramalkan. kadar ingat semua kategori Ketepatan keseluruhan, dan kehilangan entropi silang pada set data ujian, di mana absis ialah bilangan zaman.
Gunakan SWIL untuk meluaskan jarak antara kategori dan mengurangkan masa pembelajaran dan volum data
Pasukan pengarang akhirnya menguji generalisasi algoritma SWIL . Sahkan sama ada ia boleh mempelajari set data yang merangkumi lebih banyak kategori dan sama ada ia sesuai untuk seni bina rangkaian yang lebih kompleks.
Mereka melatih model CNN-VGG19 kompleks (19 lapisan kesemuanya) pada set data CIFAR100 (set latihan 500 imej/kategori, set ujian 100 imej/kategori) dan mempelajari 90 kategori. Rangkaian kemudiannya dilatih semula untuk mempelajari kategori baharu. Rajah 7A menunjukkan matriks persamaan yang dikira oleh pasukan pengarang berdasarkan fungsi pengaktifan lapisan kedua terakhir berdasarkan set data CIFAR100. Seperti yang ditunjukkan dalam Rajah 7B, kelas "kereta api" baharu serasi dengan banyak kelas pengangkutan sedia ada seperti "bas" ("bas"), "kereta api" ("trem") dan "traktor" ("traktor") dsb. ) adalah sangat serupa.
Berbanding dengan FIL, SWIL boleh mempelajari perkara baharu dengan lebih pantas (speedup=95.45x (45500×6/(1430×2))) dan menggunakan kurang data (Nisbah memori=31.8x) telah berkurangan dengan ketara, manakala prestasi pada asasnya adalah sama (H=8.21, P>0.05). Seperti yang ditunjukkan dalam Rajah 7C, di bawah syarat PIL (H=10.34, P
Pada masa yang sama, untuk meneroka sama ada jarak yang besar antara perwakilan kategori berbeza merupakan syarat asas untuk mempercepatkan pembelajaran model, pasukan pengarang melatih dua model rangkaian saraf tambahan:
- 6 lapisan CNN (sama seperti Rajah 4 dan Rajah 5 berdasarkan CIFAR10);
- VGG11 (11 lapisan) mempelajari 90 kategori dalam dataset CIFAR100, hanya dalam dua keadaan: FIL dan SWIL Latih kelas "kereta api" baharu.
Seperti yang ditunjukkan dalam Rajah 7B, untuk dua model rangkaian di atas, pertindihan antara kelas "kereta api" baharu dan kelas pengangkutan adalah lebih tinggi, tetapi dengan model VGG19 Dalam perbandingan, pemisahan setiap kategori adalah rendah. Berbanding dengan FIL, kelajuan SWIL mempelajari perkara baharu adalah secara kasarnya linear dengan pertambahan bilangan lapisan (cerun = 0.84). Keputusan ini menunjukkan bahawa meningkatkan jarak perwakilan antara kategori boleh mempercepatkan pembelajaran dan mengurangkan beban ingatan.
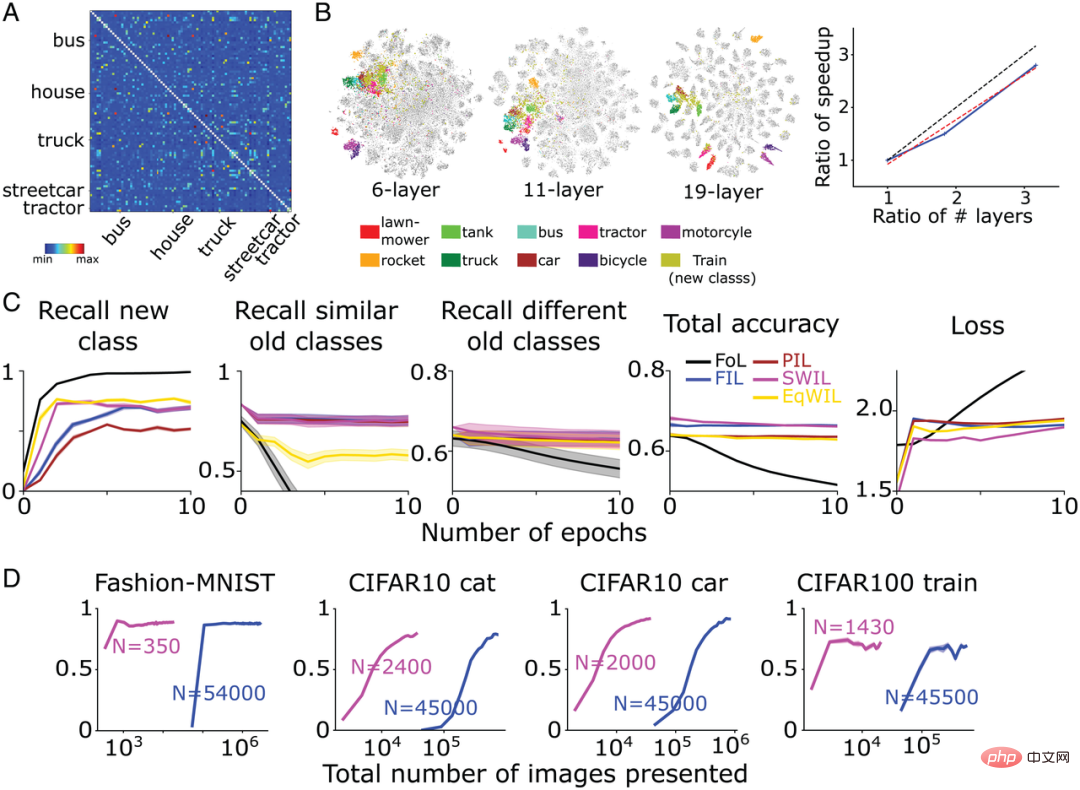
Rajah 7: (A) Selepas VGG19 mempelajari kelas "kereta api" baharu, pasukan pengarang berdasarkan yang terakhir lapisan Matriks persamaan yang dikira oleh fungsi pengaktifan. Lima kategori "trak", "kereta jalan", "bas", "rumah" dan "traktor" paling mirip dengan "kereta api". Kecualikan unsur pepenjuru daripada matriks persamaan (keserupaan=1). (B, kiri) Hasil visualisasi pengurangan dimensi t-SNE pasukan pengarang untuk rangkaian CNN, VGG11 dan VGG19 6 lapisan selepas melepasi lapisan terakhir terakhir fungsi pengaktifan. (B, kanan) Paksi menegak mewakili nisbah kelajuan (FIL/SWIL), dan paksi mendatar mewakili nisbah bilangan lapisan 3 rangkaian berbeza berbanding CNN 6 lapisan. Garis putus-putus hitam, garis putus-putus merah dan garis pepejal biru masing-masing mewakili garis piawai dengan cerun =1, garisan pemasangan terbaik dan hasil simulasi. (C) Situasi pembelajaran model VGG19: FoL (hitam), FIL (biru), PIL (coklat), SWIL (magenta) dan EqWIL (emas) meramalkan kelas "kereta api" baharu, kelas lama yang serupa (kelas pengangkutan) Dan penarikan balik kadar kategori lama yang berbeza (kecuali kategori pengangkutan), jumlah ketepatan ramalan semua kategori, dan kehilangan entropi silang pada set data ujian, di mana abscissa ialah nombor zaman. Setiap graf menunjukkan purata 10 ulangan, dan kawasan berlorek ialah ±1 SEM. (D) Dari kiri ke kanan, model meramalkan penarikan semula kelas "but" Fesyen-MNIST (Rajah 3), kelas "kucing" CIFAR10 (Rajah 4), kelas "kereta" CIFAR10 (Rajah 5) dan Kelas "kereta api" CIFAR100 sebagai fungsi daripada jumlah imej (skala log) yang digunakan oleh SWIL (magenta) dan FIL (biru). “N” mewakili jumlah bilangan imej yang digunakan dalam setiap zaman di bawah setiap keadaan pembelajaran (termasuk kategori baharu dan lama).
Adakah kelajuan akan dipertingkatkan lagi jika rangkaian dilatih pada lebih banyak kelas tidak bertindih dan jarak antara perwakilan lebih besar?
Untuk tujuan ini, pasukan pengarang menggunakan rangkaian linear dalam (digunakan untuk contoh Fesyen-MNIST dalam Rajah 1-3) dan melatihnya untuk mempelajari 8 Fesyen - Set data gabungan Kategori MNIST (tidak termasuk kategori "beg" dan "but") dan 10 Digit-MNIST kategori, dan kemudian melatih rangkaian untuk mempelajari kategori "but" baharu.
Selaras dengan jangkaan pasukan pengarang, “boot” lebih serupa dengan kategori lama “sandal” dan “sneaker”, diikuti oleh kategori Fesyen-MNIST yang lain (terutamanya termasuk imej kategori pakaian), dan akhirnya kelas Digit-MNIST (terutamanya termasuk imej digital).
Berdasarkan ini, pasukan pengarang mula-mula menyelitkan lebih banyak sampel kategori lama yang serupa, dan kemudian menjalin sampel kategori Fesyen-MNIST dan Digit-MNIST (jumlah n=350 imej/zaman) . Keputusan eksperimen menunjukkan bahawa, sama dengan FIL, SWIL boleh mempelajari kandungan kategori baharu dengan cepat tanpa gangguan, tetapi menggunakan subset data yang jauh lebih kecil, dengan nisbah memori 325.7x (114000/350) dan nisbah pecutan 162.85x (228000/228000). /350). Pasukan pengarang memerhatikan peningkatan sebanyak 2.1x (162.85/77.1) dalam hasil semasa, dengan peningkatan 2.25x dalam bilangan kategori (18/8) berbanding set data Fashion-MNIST.
Hasil percubaan dalam bahagian ini membantu menentukan bahawa SWIL boleh digunakan pada set data yang lebih kompleks (CIFAR100) dan model rangkaian saraf (VGG19), membuktikan generalisasi algoritma. Kami juga menunjukkan bahawa memperluaskan jarak dalaman antara kategori atau meningkatkan bilangan kategori tidak bertindih boleh meningkatkan lagi kelajuan pembelajaran dan mengurangkan beban memori.
Ringkasan
Rangkaian saraf tiruan menghadapi cabaran yang ketara dalam pembelajaran berterusan, selalunya mempamerkan gangguan bencana. Untuk mengatasi masalah ini, banyak kajian telah menggunakan pembelajaran interleaved sepenuhnya (FIL), di mana kandungan baharu dan lama dipelajari silang untuk melatih rangkaian secara bersama. FIL memerlukan jalinan semua maklumat sedia ada setiap kali ia mempelajari maklumat baharu, menjadikannya proses biologi yang tidak munasabah dan memakan masa. Baru-baru ini, beberapa kajian telah menunjukkan bahawa FIL mungkin tidak diperlukan, dan kesan pembelajaran yang sama boleh dicapai dengan menyilangkan kandungan lama sahaja yang mempunyai persamaan perwakilan yang ketara dengan kandungan baharu, iaitu menggunakan kaedah pembelajaran berjalin berwajaran persamaan (SWIL). Walau bagaimanapun, kebimbangan telah dinyatakan mengenai skalabiliti SWIL.
Kertas kerja ini memanjangkan algoritma SWIL dan mengujinya berdasarkan set data yang berbeza (Fashion-MNIST, CIFAR10 dan CIFAR100) dan model rangkaian saraf (rangkaian linear dalam dan CNN). Dalam semua keadaan, pembelajaran berjalin berwajaran persamaan (SWIL) dan pembelajaran berjalin berwajaran sama (EqWIL) berprestasi lebih baik dalam mempelajari kategori baharu berbanding pembelajaran berjalin separa (PIL). Ini adalah selaras dengan jangkaan pasukan pengarang, kerana SWIL dan EqWIL meningkatkan kekerapan relatif bagi kategori baharu berbanding dengan kategori lama.
Kami juga menunjukkan bahawa pemilihan teliti dan jalinan kandungan yang serupa mengurangkan gangguan bencana dengan kategori lama yang serupa berbanding dengan mensubsampelkan kategori sedia ada yang sama (iaitu pendekatan EqWIL). SWIL berprestasi sama seperti FIL dalam meramalkan kategori baharu dan sedia ada, tetapi dengan ketara mempercepatkan pembelajaran kandungan baharu (Rajah 7D) sambil mengurangkan data latihan yang diperlukan. SWIL boleh mempelajari kategori baharu dalam rangka kerja pembelajaran turutan, seterusnya menunjukkan keupayaan generalisasinya.
Akhir sekali, masa penyepaduan boleh dipendekkan jika ia mempunyai kurang pertindihan (jarak lebih besar) dengan kategori yang dipelajari sebelum ini daripada kategori baharu yang mempunyai persamaan dengan banyak kategori lama dan Lebih kecekapan data. Secara keseluruhan, keputusan eksperimen memberikan gambaran yang mungkin bahawa otak sebenarnya mengatasi salah satu kelemahan utama model CLST asal dengan mengurangkan masa latihan yang tidak realistik.
Atas ialah kandungan terperinci Penyelidikan menunjukkan bahawa pembelajaran berjalin berwajaran berasaskan persamaan boleh menangani masalah 'amnesia' dalam pembelajaran mendalam dengan berkesan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI