
Rumah >Peranti teknologi >AI >Set arahan diperhalusi sumber terbuka Microsoft membantu membangunkan versi rumah GPT-4, menyokong penjanaan dwibahasa dalam bahasa Cina dan Inggeris.
Set arahan diperhalusi sumber terbuka Microsoft membantu membangunkan versi rumah GPT-4, menyokong penjanaan dwibahasa dalam bahasa Cina dan Inggeris.

- 王林ke hadapan
- 2023-04-26 14:58:091331semak imbas
"Arahan" ialah faktor utama dalam kemajuan terobosan model ChatGPT, yang boleh menjadikan output model bahasa lebih selaras dengan "keutamaan manusia."
Tetapi anotasi arahan memerlukan banyak tenaga kerja Walaupun dengan model bahasa sumber terbuka, adalah sukar bagi institusi akademik dan syarikat kecil yang tidak mempunyai dana yang mencukupi untuk melatih ChatGPT mereka sendiri.
Baru-baru ini, penyelidik Microsoft menggunakan teknologi Arahan Kendiri yang dicadangkan sebelum ini untuk buat pertama kali cuba menggunakan model GPT-4 untuk menjana model bahasa secara automatik Data arahan memangkas diperlukan .

Pautan kertas: https://arxiv.org/pdf/2304.03277.pdf
Pautan kod: https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
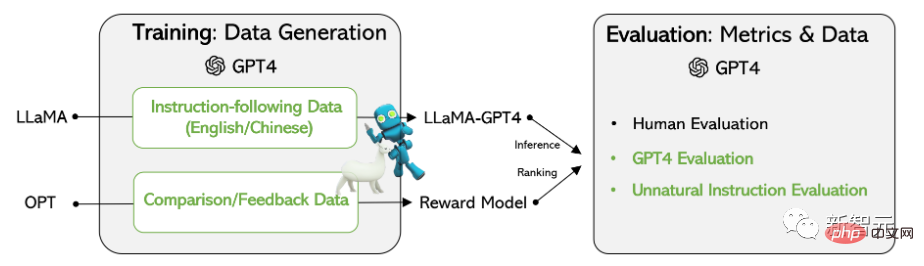
Hasil eksperimen pada model LLaMA sumber terbuka Meta menunjukkan bahawa 52,000 data mengikut arahan bahasa Inggeris dan Cina yang dijana oleh GPT-4 mengatasi arahan yang dijana oleh model terkini yang terkini mengenai tugasan baharu Data, para penyelidik juga mengumpul maklum balas dan data perbandingan daripada GPT-4 untuk penilaian komprehensif dan latihan model ganjaran.
Data latihan
Pengumpulan data
Para penyelidik menggunakan semula model Alpaca yang dikeluarkan oleh Universiti Stanford 52,000 arahan digunakan, setiap satunya menerangkan tugas yang perlu dilakukan oleh model, dan mengikut strategi dorongan yang sama seperti Alpaca, dengan mengambil kira situasi dengan dan tanpa input, sebagai konteks pilihan atau input tugasan menggunakan model bahasa Besar output jawapan kepada arahan.

Dalam set data Alpaca, output dijana menggunakan GPT-3.5 (text-davinci-003), tetapi dalam Dalam kertas kerja ini, penyelidik memilih untuk menggunakan GPT-4 untuk menjana data, termasuk empat set data berikut:
1 Data Mengikuti Arahan Bahasa Inggeris: Untuk setiap satu daripada 52,000 arahan yang dikumpul di Alpaca, jawapan GPT-4 Bahasa Inggeris disediakan.

Kerja masa hadapan ialah mengikuti proses berulang dan membina set data baharu menggunakan GPT-4 dan arahan kendiri .
2 Data Mengikuti Arahan Bahasa Cina: Gunakan ChatGPT untuk menterjemah 52,000 arahan ke dalam bahasa Cina, dan minta GPT-4 menjawab arahan ini dalam bahasa Cina, dan Binaan ini model mengikut arahan bahasa Cina berdasarkan LLaMA dan mengkaji keupayaan generalisasi silang bahasa bagi penalaan arahan.
3 Data Perbandingan: Memerlukan GPT-4 untuk memberikan penilaian dari 1 hingga 10 untuk balasannya sendiri, dan menilai GPT-4, GPT Respons bagi tiga model -3.5 dan OPT-IML diberi markah untuk melatih model ganjaran.
4 Jawapan kepada arahan yang tidak wajar: Jawapan kepada GPT-4 ialah 68,000. Dinyahkodkan pada set data sebanyak tiga kali ganda (arahan, input, output), subset ini digunakan untuk mengukur perbezaan skala antara GPT-4 dan model yang ditala arahan.
Statistik
Para penyelidik membandingkan set balasan keluaran Bahasa Inggeris GPT-4 dan GPT-3.5: untuk setiap keluaran, kata kerja akar dan kata nama objek langsung telah diekstrak, dan dalam setiap Kekerapan pasangan kata kerja-kata nama yang unik ialah dikira ke atas set keluaran.
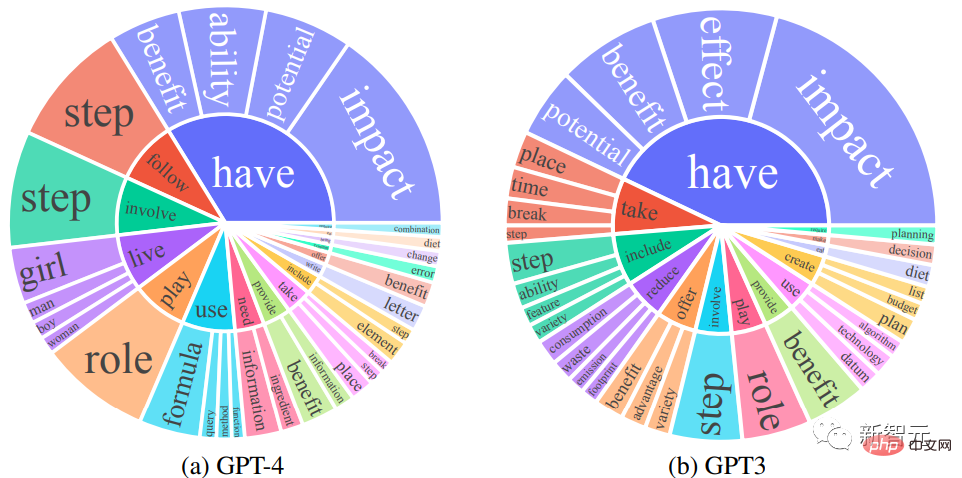
Pasangan kata kerja-kata nama dengan kekerapan lebih tinggi daripada 10
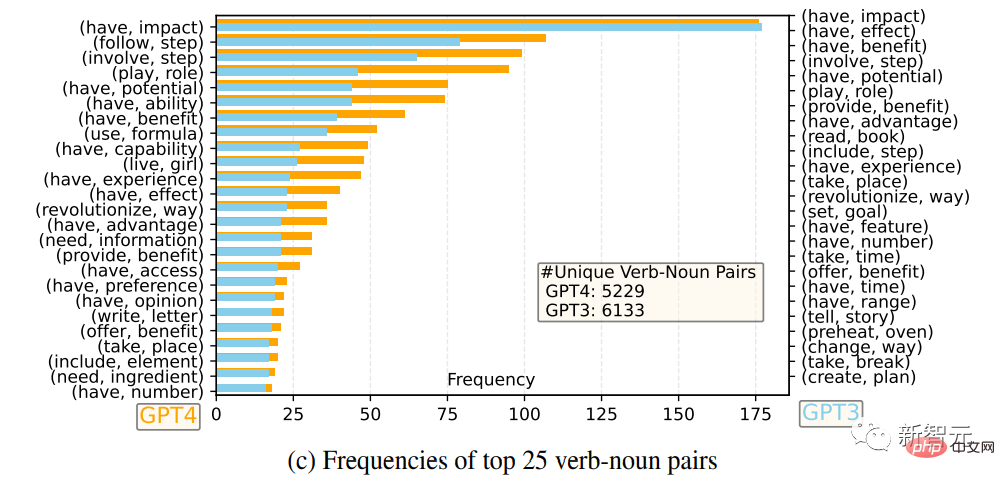
25 pasangan kata kerja-kata nama yang paling kerap
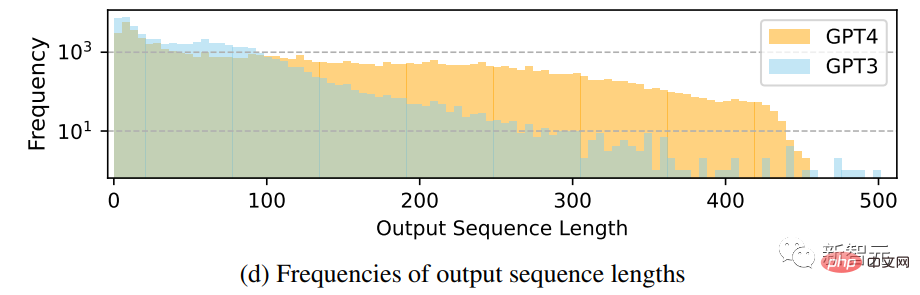
Perbandingan taburan kekerapan bagi panjang jujukan output
Dapat dilihat bahawa GPT-4 cenderung menjana lebih banyak data daripada GPT-3.5 Untuk jujukan panjang, fenomena long tail data GPT-3.5 dalam Alpaca adalah lebih jelas daripada taburan output GPT-4 Ini mungkin kerana set data Alpaca melibatkan proses pengumpulan data berulang, dan contoh arahan yang serupa dialih keluar dalam setiap lelaran Ini tidak tersedia dalam penjanaan data satu kali semasa.
Walaupun prosesnya mudah, data mengikut arahan yang dijana oleh GPT-4 mempamerkan prestasi penjajaran yang lebih berkuasa.
Model bahasa penalaan arahan
Penalaan Arahan Kendiri
Penyelidik berdasarkan LLaMA Selepas 7B pusat pemeriksaan diselia penalaan halus, dua model telah dilatih: LLaMA-GPT4 telah dilatih pada 52,000 data mengikut arahan bahasa Inggeris yang dijana oleh LLaMA-GPT4-CN telah dilatih pada 52,000 item Cina yang dijana oleh GPT-4 Dilatih mengikut arahan mengikut arahan; data.
Dua model digunakan untuk mengkaji kualiti data GPT-4 dan sifat generalisasi silang bahasa bagi LLM yang ditala arahan dalam satu bahasa.
Model Ganjaran
Pembelajaran Pengukuhan daripada Maklum Balas Manusia (RLHF) bertujuan untuk Menjajarkan tingkah laku LLM dengan keutamaan manusia supaya keluaran model bahasa lebih berguna kepada manusia.
Komponen utama RLHF ialah pemodelan ganjaran. Masalahnya boleh dirumuskan sebagai tugasan regresi untuk meramalkan skor ganjaran yang diberikan segera dan balasan Kaedah ini biasanya memerlukan data Perbandingan berskala besar , iaitu membandingkan respons dua model kepada gesaan yang sama.
Model sumber terbuka sedia ada, seperti Alpaca, Vicuna dan Dolly, tidak menggunakan RLHF kerana kos yang tinggi untuk membuat anotasi data perbandingan, dan penyelidikan terkini menunjukkan bahawa GPT-4 boleh Mengenal pasti dan betulkan kesilapan anda sendiri dan nilai dengan tepat kualiti respons anda.
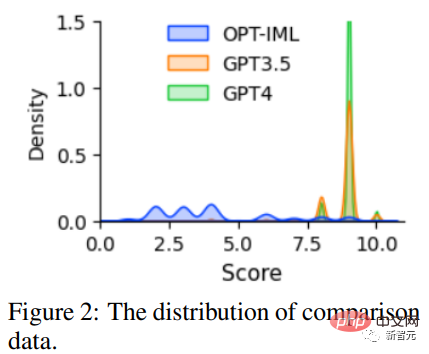
Untuk mempromosikan penyelidikan tentang RLHF, penyelidik mencipta data perbandingan menggunakan GPT-4 untuk menilai kualiti data, Para penyelidik melatih model ganjaran berdasarkan OPT 1.3B untuk menjaringkan balasan yang berbeza: untuk satu balasan gesaan dan K, GPT-4 memberikan skor antara 1 dan 10 untuk setiap balasan.
Hasil Eksperimen
Menilai prestasi model yang ditala arahan kendiri untuk tugasan yang tidak pernah dilihat sebelumnya pada data GPT-4 kekal sebagai tugas yang sukar .
Memandangkan matlamat utama adalah untuk menilai keupayaan model untuk memahami dan mematuhi pelbagai arahan tugas, untuk mencapai matlamat ini, penyelidik menggunakan tiga jenis penilaian dan disahkan oleh keputusan kajian itu, "Menggunakan data yang dijana GPT-4 adalah kaedah yang berkesan untuk menala arahan model bahasa yang besar berbanding dengan data yang dijana secara automatik oleh mesin lain.
Penilaian Manusia
Untuk menilai kualiti penjajaran model bahasa besar selepas menala arahan ini, penyelidik mengikuti kriteria penjajaran yang dicadangkan sebelum ini: jika Pembantu adalah membantu, jujur dan tidak berbahaya (HHH) jika ia sejajar dengan kriteria penilaian manusia, yang juga digunakan secara meluas untuk menilai sejauh mana sistem AI konsisten dengan nilai manusia.
Kemanfaatan: Sama ada ia boleh membantu manusia mencapai matlamat mereka, model yang boleh menjawab soalan dengan tepat adalah membantu.
Kejujuran: Sama ada untuk memberikan maklumat yang benar dan menyatakan ketidakpastiannya apabila perlu untuk mengelakkan pengguna manusia yang mengelirukan, model yang memberikan maklumat palsu adalah tidak jujur.
Ketidakmudaratan: Model yang menjana ucapan kebencian atau menggalakkan keganasan tidak berbahaya jika ia tidak mendatangkan kemudaratan kepada manusia.
Berdasarkan kriteria penjajaran HHH, penyelidik menggunakan platform penyumberan ramai Amazon Mechanical Turk untuk menilai secara manual hasil penjanaan model.
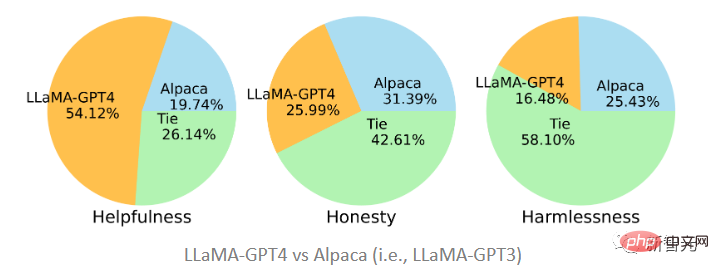
Kedua-dua model yang dicadangkan dalam artikel itu telah diperhalusi pada data yang dijana oleh GPT-4 dan GPT-3 Dapat dilihat bahawa LLaMA-GPT4 jauh lebih baik daripada Alpaca (19.74%) yang disesuaikan dengan GPT-3 dari segi kebergunaan dengan perkadaran 51.2%. seri. GPT-3 adalah lebih baik.
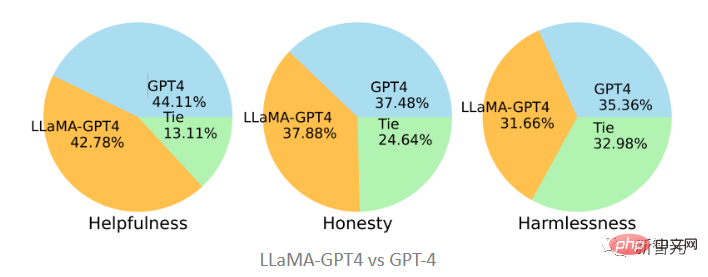
Jika dibandingkan dengan GPT-4 asal, boleh didapati bahawa kedua-duanya agak konsisten dalam ketiga-tiga piawaian . Iaitu, prestasi LLaMA selepas menala arahan GPT-4 adalah serupa dengan GPT-4 yang asal.
Penilaian automatik GPT-4
Diilhamkan oleh Vicuna, penyelidik juga memilih untuk menggunakan GPT-4 untuk penilaian. kualiti respons yang dijana oleh model chatbot yang berbeza kepada 80 soalan yang tidak kelihatan telah dikumpul daripada model LLaMA-GPT-4(7B) dan GPT-4, dan jawapan daripada model lain diperoleh daripada penyelidikan terdahulu, dan kemudian ditanya GPT-4. menjaringkan kualiti balasan antara dua model pada skala dari 1 hingga 10 dan membandingkan keputusan dengan model bersaing kuat yang lain (ChatGPT dan GPT-4).
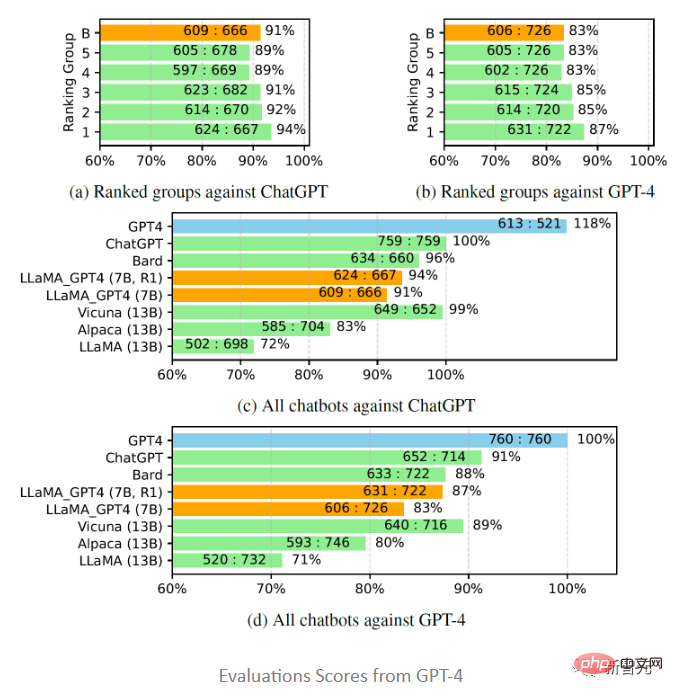
Hasil penilaian menunjukkan bahawa data maklum balas dan model ganjaran berkesan dalam meningkatkan prestasi LLaMA menggunakan GPT-4 LLaMA melakukan penalaan arahan dan selalunya berprestasi lebih baik daripada penalaan teks-davinci-003 (iaitu Alpaca) dan tiada penalaan (iaitu LLaMA GPT4 melebihi prestasi 13B Alpaca dan LLaMA, tetapi berbeza daripada GPT-4 Berbanding dengan); chatbot komersial besar lain, masih ada jurang.
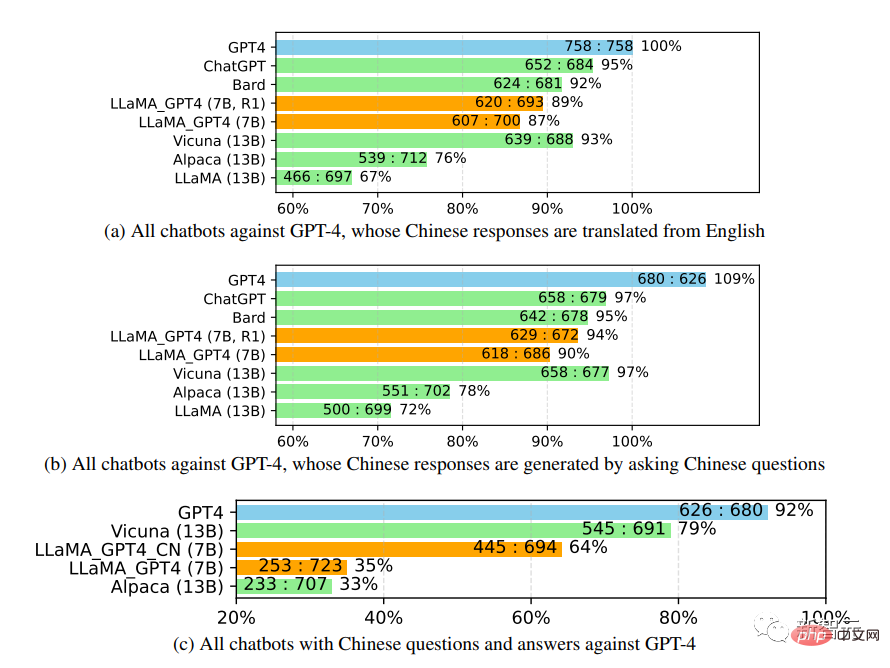
Apabila mengkaji lebih lanjut prestasi chatbot Cina, GPT-4 mula-mula digunakan untuk menterjemah soalan chatbot daripada bahasa Inggeris Dalam bahasa Cina, menggunakan GPT-4 untuk mendapatkan jawapan, dua pemerhatian menarik boleh diperolehi:
1 Boleh didapati bahawa penunjuk skor relatif bagi penilaian GPT-4 adalah agak konsisten. , kedua-duanya dari segi model lawan yang berbeza (iaitu ChatGPT atau GPT-4) dan bahasa (iaitu Inggeris atau Cina).
2 Hanya untuk keputusan GPT-4, balasan yang diterjemahkan menunjukkan prestasi yang lebih baik daripada balasan yang dijana oleh bahasa Cina, mungkin kerana GPT-4 Ia dilatih. dalam korpus Inggeris yang lebih kaya daripada bahasa Cina, jadi ia mempunyai keupayaan mengikut arahan bahasa Inggeris yang lebih kuat.
Penilaian Arahan Tidak Semulajadi
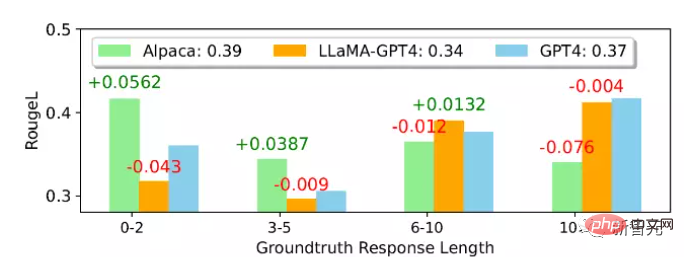
Daripada purata Dari segi ROUGE- Skor L, Alpaca lebih baik daripada LLaMA-GPT 4 dan GPT-4 Dapat dilihat bahawa LLaMA-GPT4 dan GPT4 secara beransur-ansur berprestasi lebih baik apabila panjang balasan kebenaran tanah meningkat, dan akhirnya berprestasi lebih baik apabila panjang melebihi 4. Prestasi tinggi bermakna. arahan boleh diikuti dengan lebih baik apabila adegan lebih kreatif.
Dalam subset yang berbeza, tingkah laku LLaMA-GPT4 dan GPT-4 adalah hampir sama; apabila panjang jujukan adalah pendek, kedua-dua LLaMA-GPT4 dan GPT-4 boleh menjana Balasan mudah yang memberikan jawapan fakta asas tetapi menambah perkataan tambahan untuk menjadikan balasan lebih seperti sembang boleh menyebabkan skor ROUGE-L yang lebih rendah.
Atas ialah kandungan terperinci Set arahan diperhalusi sumber terbuka Microsoft membantu membangunkan versi rumah GPT-4, menyokong penjanaan dwibahasa dalam bahasa Cina dan Inggeris.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI