
Rumah >Peranti teknologi >AI >CLIP tidak turun ke bumi? Anda memerlukan model yang lebih memahami bahasa Cina
CLIP tidak turun ke bumi? Anda memerlukan model yang lebih memahami bahasa Cina

- PHPzke hadapan
- 2023-04-25 08:58:072006semak imbas
Artikel ini memperkenalkan model perwakilan imej dan teks pralatihan berskala besar Cina CLIP yang dibuka baru-baru ini oleh Damo Academy Magic Community ModelScope, yang boleh memahami dengan lebih baik imej Internet Cina dan Cina, serta boleh melaksanakan pelbagai tugas seperti imej dan pengambilan teks dan klasifikasi imej sampel sifar Untuk mencapai hasil terbaik, kod dan model semuanya adalah sumber terbuka, jadi pengguna boleh menggunakan Magic untuk bermula dengan cepat.

- Pintu masuk penggunaan model: https://modelscope.cn/models/damo/multi-modal_clip-vit-base-patch16_zh/summary
- Github: https://github.com/OFA-Sys/Chinese-CLIP
- Kertas: https://arxiv.org/pdf /2211.01335.pdf
- Tunjuk cara mendapatkan semula grafik dan teks: https://modelscope.cn/studios/damo/chinese_clip_applications/summary
1 . Pengenalan
Dalam ekosistem Internet semasa, terdapat banyak tugas dan senario berkaitan pelbagai mod, seperti pengambilan imej dan teks, klasifikasi imej, kandungan video dan imej serta teks serta senario lain. Dalam beberapa tahun kebelakangan ini, penjanaan imej, yang telah menjadi popular di seluruh Internet, telah menjadi lebih popular dan telah keluar dengan cepat daripada kalangan. Di sebalik tugasan ini, model pemahaman imej dan teks yang berkuasa jelas diperlukan. Saya percaya semua orang akan terbiasa dengan model CLIP yang dilancarkan oleh OpenAI pada tahun 2021. Melalui pembelajaran perbandingan menara berkembar teks imej yang mudah dan sejumlah besar korpus teks imej, model ini mempunyai keupayaan penjajaran ciri teks imej yang ketara, dan boleh digunakan dalam pengelasan imej sampel sifar, Ia mempunyai hasil yang cemerlang dalam perolehan semula modal dan juga digunakan sebagai modul utama dalam model penjanaan imej seperti DALLE2 dan Stable Diffusion.
Tetapi malangnya, pra-latihan OpenAI CLIP terutamanya menggunakan data grafik dan teks dari dunia Inggeris dan tidak boleh menyokong bahasa Cina secara semula jadi. Walaupun terdapat penyelidik dalam komuniti yang telah menyaring versi berbilang bahasa Multilingual-CLIP (mCLIP) melalui teks terjemahan, ia tidak dapat memenuhi keperluan dunia Cina dengan baik, dan pemahaman teks dalam bidang Cina tidak begitu baik, seperti mencari "Spring Festival Couplets" , tetapi apa yang dikembalikan ialah kandungan berkaitan Krismas:

mCLIP Retrieve demo Carian untuk "Spring Festival Couplets" Return results
Ini juga menunjukkan bahawa kita memerlukan KLIP yang lebih memahami bahasa Cina, bukan sahaja memahami bahasa kita, tetapi juga memahami imej dunia China.
2. Kaedah
Penyelidik dari DAMO Academy mengumpul data pasangan teks imej Cina berskala besar (kira-kira 200 juta skala), termasuk data daripada subset Cina LAION-5B , data Cina Wukong dan menterjemah data grafik dan teks daripada COCO, Genom Visual, dsb. Kebanyakan imej dan teks latihan datang daripada set data awam, yang sangat mengurangkan kesukaran pembiakan. Dari segi kaedah latihan, untuk meningkatkan kecekapan latihan dan kesan model model secara berkesan, para penyelidik mereka bentuk proses latihan dua peringkat:
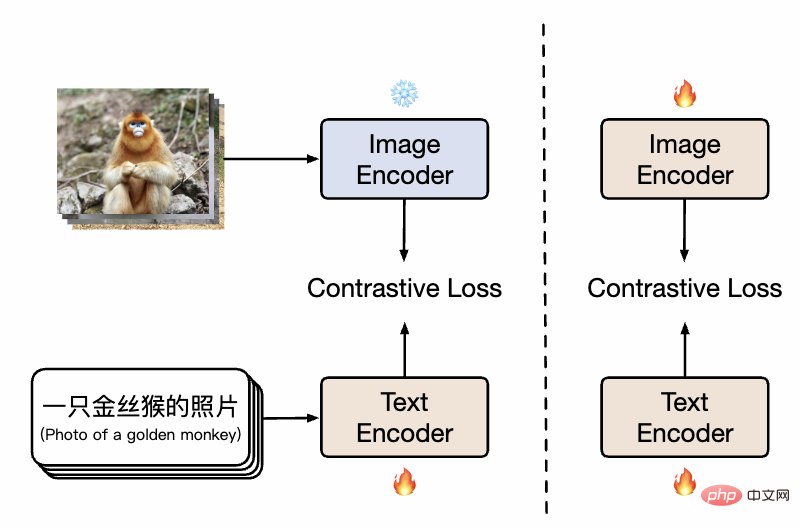
Rajah kaedah CLIP Cina
Seperti yang ditunjukkan dalam rajah, pada peringkat pertama, model menggunakan imej pra-latihan sedia ada model dan teks pra-latihan Model ini memulakan menara berkembar Cina-CLIP secara berasingan dan membekukan parameter sisi imej, membolehkan model bahasa mengaitkan dengan ruang perwakilan pra-latihan imej sedia ada sambil mengurangkan overhed latihan. Selepas itu, pada peringkat kedua, parameter sisi imej tidak dibekukan, membolehkan model imej dan model bahasa dikaitkan sambil memodelkan pengedaran data dengan ciri Cina. Para penyelidik mendapati bahawa berbanding dengan pra-latihan dari awal, kaedah ini menunjukkan hasil percubaan yang jauh lebih baik pada pelbagai tugas hiliran, dan kecekapan penumpuannya yang jauh lebih tinggi juga bermakna overhed latihan yang lebih kecil. Berbanding dengan hanya melatih bahagian teks dalam satu peringkat latihan, menambah peringkat kedua latihan secara berkesan boleh meningkatkan lagi kesan pada grafik hiliran dan tugasan teks, terutamanya grafik dan tugas teks asli bahasa Cina (bukannya diterjemahkan daripada set data bahasa Inggeris).
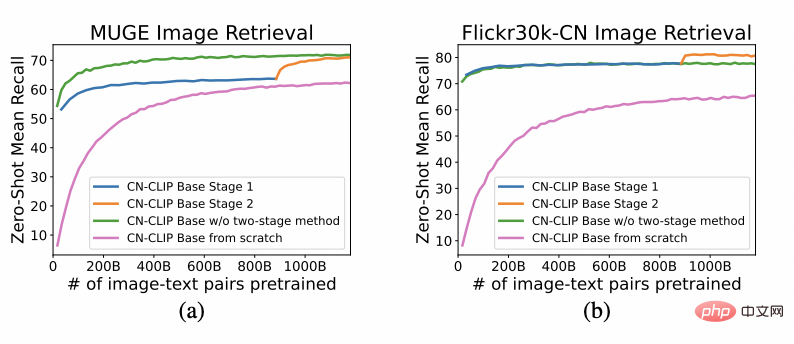
pada dua set data: imej e-dagang Cina MUGE dan perolehan teks, imej umum versi terjemahan Flickr30K-CN dan perolehan teks Perhatikan trend perubahan kesan pukulan sifar semasa pra-latihan diteruskan
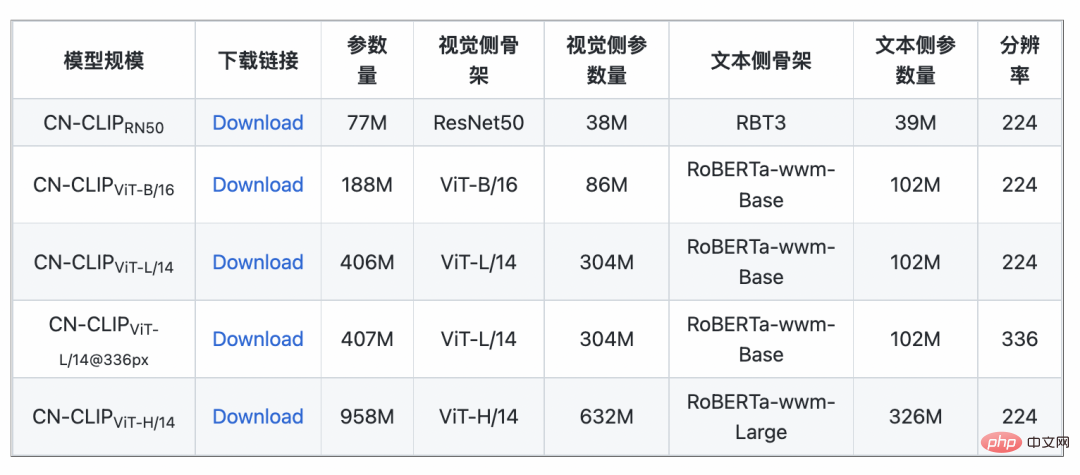
Menggunakan strategi ini, penyelidik telah melatih model berbilang skala, daripada ResNet-50, ViT-Base dan Large yang paling kecil kepada ViT-Huge Semuanya kini terbuka dan pengguna boleh mengaksesnya sepenuhnya atas permintaan model yang paling sesuai dengan senario anda:
3 Eksperimen
Berbilang data eksperimen menunjukkan bahawa Chinese-CLIP boleh digunakan dalam. Pencapaian rentas modal Cina telah mencapai prestasi terbaik Pada set data perolehan imej e-dagang asli Cina MUGE, CLIP Cina berbilang skala telah mencapai prestasi terbaik pada skala ini. Pada set data seperti Flickr30K-CN yang berasal dari Inggeris, CLIP Cina boleh melebihi model garis dasar domestik dengan ketara seperti Wukong, Taiyi dan R2D2, tanpa mengira sampel sifar atau tetapan penalaan halus. Ini sebahagian besarnya disebabkan oleh imej dan korpus teks pra-latihan Cina yang lebih besar, dan Cina-CLIP adalah berbeza daripada beberapa model perwakilan imej dan teks domestik sedia ada untuk meminimumkan kos latihan dan membekukan keseluruhan bahagian imej menggunakan dua strategi latihan Berperingkat untuk menyesuaikan diri dengan lebih baik dalam bidang Cina:
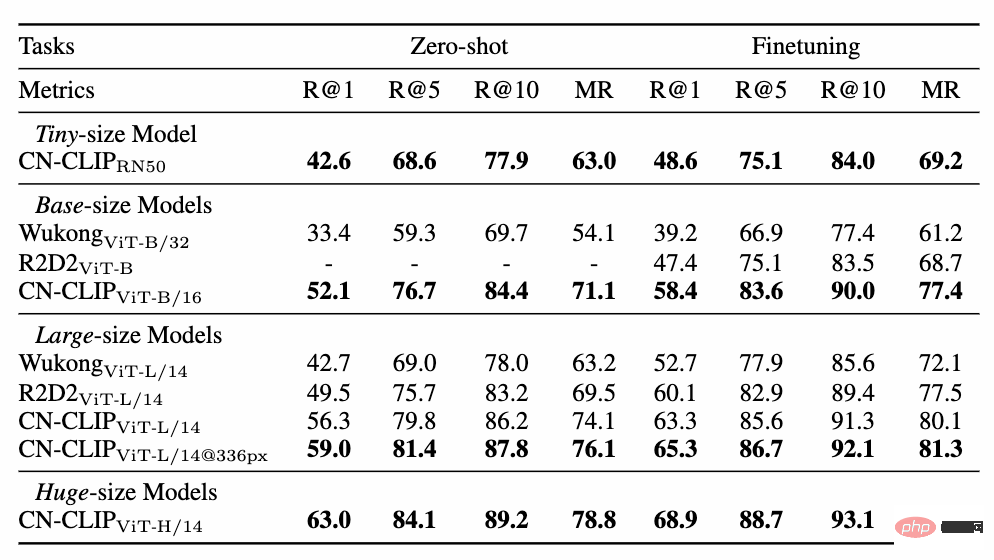
Data pengambilan imej dan teks e-dagang Cina MUGE Tetapkan hasil percubaan
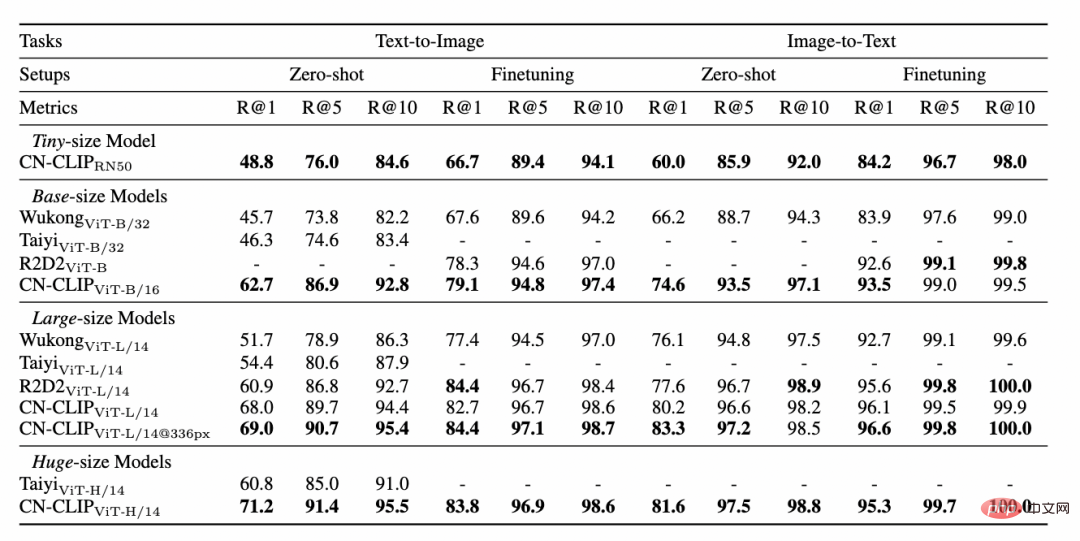
Flickr30K-CN set data hasil percubaan set imej dan teks pengambilan semula teks
Pada masa yang sama, penyelidik mengesahkan kesan CLIP Cina pada set data pengelasan imej tangkapan sifar. Memandangkan tidak banyak tugas pengelasan imej tangkapan sifar yang berwibawa dalam bidang bahasa Cina, para penyelidik sedang menguji versi terjemahan bahasa Inggeris bagi set data. Chinese-CLIP boleh mencapai prestasi yang setanding dengan CLIP pada tugasan ini melalui gesaan Cina dan label kategori:
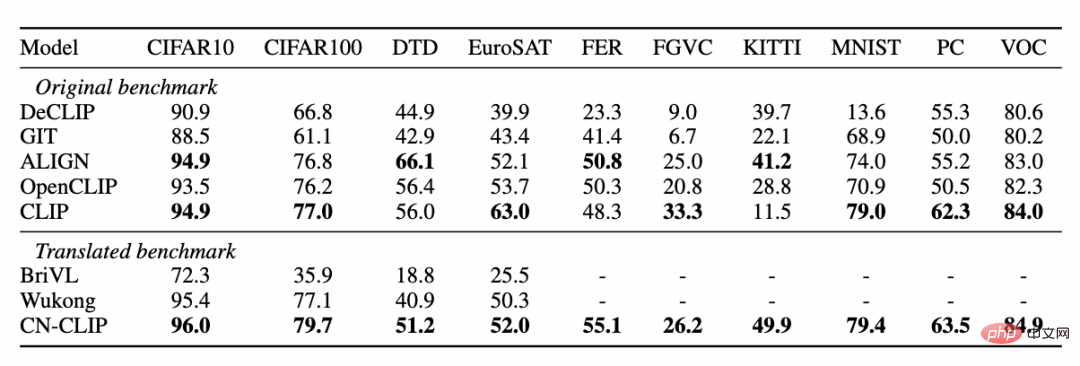
Pengkelasan sifar tangkapan keputusan percubaan
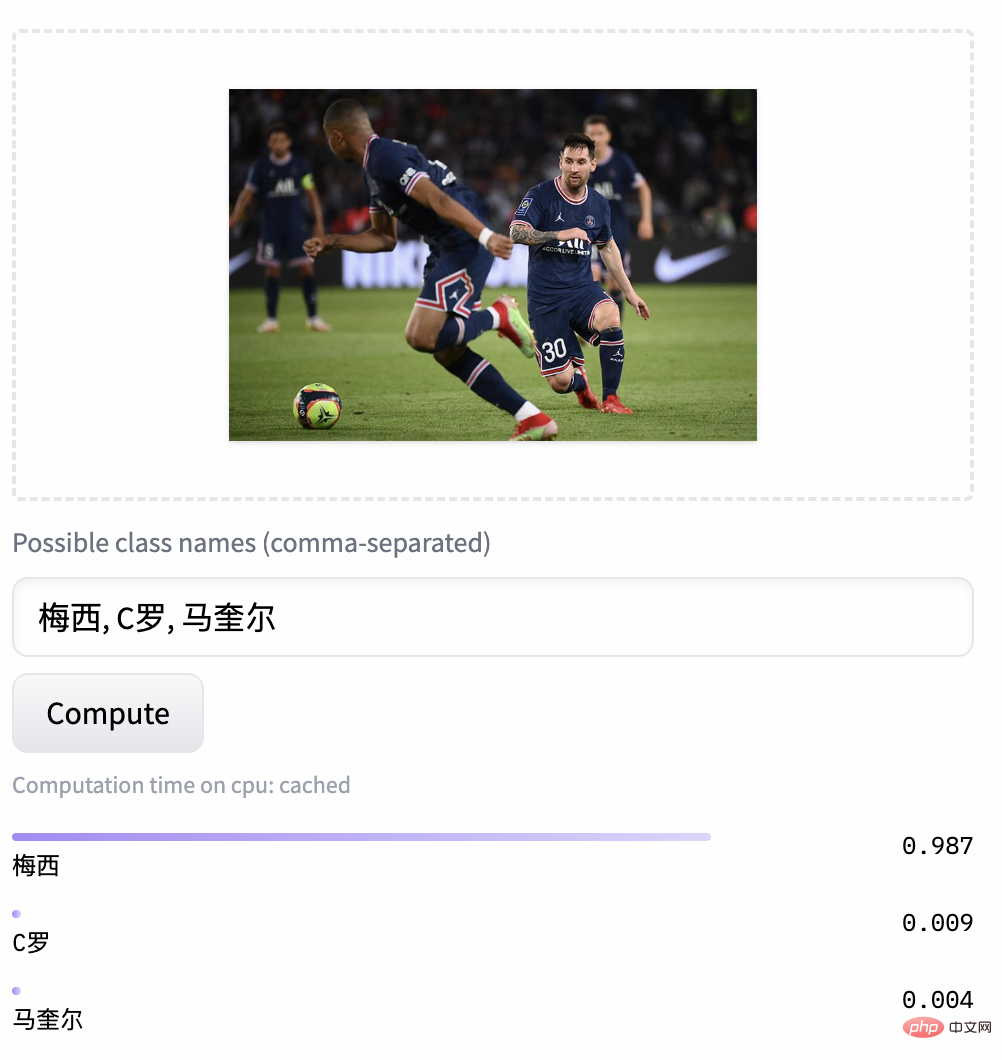
Contoh klasifikasi imej tangkapan sifar
4. Penggunaan pantas
Bagaimana saya boleh menggunakan Chinese-CLIP? Ia sangat mudah. Klik pautan pada permulaan artikel untuk melawat komuniti Moda atau menggunakan kod sumber terbuka Anda boleh melengkapkan pengekstrakan ciri imej dan teks dan pengiraan persamaan dalam beberapa baris sahaja. Untuk penggunaan dan pengalaman pantas, komuniti Moda menyediakan Buku Nota dengan persekitaran yang dikonfigurasikan Anda boleh menggunakannya dengan mengklik pada sudut kanan atas.

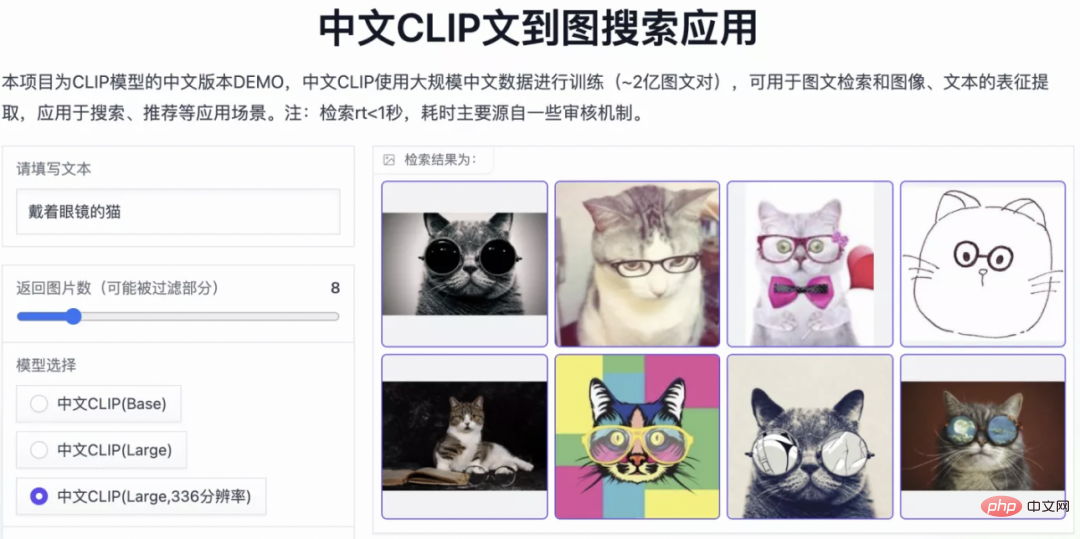
Chinese-CLIP juga menyokong pengguna untuk menggunakan data mereka sendiri untuk finetune, dan juga menyediakan demo perolehan semula imej dan teks untuk semua orang benar-benar mengalami Cina -Kesan model CLIP pelbagai skala:
5 Kesimpulan
Kali ini komuniti Damoda melancarkan Cina-. Projek CLIP, Ia menyediakan model pemahaman imej dan teks pra-latihan yang sangat baik untuk majoriti pengguna penyelidikan dan industri berbilang mod Cina, membantu semua orang memulakan dengan cepat dengan ciri imej dan teks & pengiraan persamaan, pengambilan imej dan teks serta sifar- pengelasan sampel tanpa sebarang ambang, dan anda boleh mencubanya Ia sesuai untuk membina aplikasi berbilang modal yang lebih kompleks seperti penjanaan imej. Rakan-rakan yang ingin menunjukkan kemahiran mereka dalam bidang multi-modal Cina, sila jangan ketinggalan! Dan ini hanyalah salah satu aplikasi dalam komuniti Moda ModelScope membolehkan banyak model asas dalam bidang AI memainkan peranan sebagai asas aplikasi, menyokong kelahiran model, aplikasi dan juga produk yang lebih inovatif.
Atas ialah kandungan terperinci CLIP tidak turun ke bumi? Anda memerlukan model yang lebih memahami bahasa Cina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI