
Rumah >Peranti teknologi >AI >Gunakan GPT-3 untuk membina chatbot perusahaan yang memenuhi keperluan perniagaan anda
Gunakan GPT-3 untuk membina chatbot perusahaan yang memenuhi keperluan perniagaan anda

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-24 21:43:111584semak imbas

Latar Belakang
Chatbots atau pembantu khidmat pelanggan ialah alatan AI yang berharap untuk mencapai nilai perniagaan melalui penghantaran teks atau suara kepada pengguna melalui Internet. Pembangunan chatbots telah berkembang pesat dalam beberapa tahun kebelakangan ini, daripada robot awal berdasarkan logik mudah kepada kecerdasan buatan semasa berdasarkan pemahaman bahasa semula jadi (NLU). Bagi yang terakhir, rangka kerja atau perpustakaan yang paling biasa digunakan semasa membina chatbots tersebut termasuk RASA asing, Dialogflow, Amazon Lex, dsb., serta syarikat utama domestik Baidu, iFlytek, dsb. Rangka kerja ini boleh menyepadukan pemprosesan bahasa semula jadi (NLP) dan NLU untuk memproses teks input, mengklasifikasikan niat dan mencetuskan tindakan yang betul untuk menjana respons.
Dengan kemunculan model bahasa besar (LLM), kami boleh terus menggunakan model ini untuk membina chatbot yang berfungsi sepenuhnya. Salah satu contoh LLM yang terkenal ialah Generative Pre-trained Transformer 3 daripada OpenAI (GPT-3: chatgpt adalah berdasarkan penalaan halus gpt dan menambah model maklum balas manusia), yang boleh memperhalusi model dengan menggunakan dialog atau data sesi , menjana teks yang menyerupai perbualan semula jadi. Keupayaan ini menjadikannya pilihan terbaik untuk membina chatbot tersuai.
Hari ini kita akan bercakap tentang cara membina chatbot perbualan mudah kita sendiri dengan memperhalusi model GPT-3.
Selalunya, kami ingin memperhalusi model pada set data contoh perbualan perniagaan kami, seperti rekod perbualan perkhidmatan pelanggan, log sembang atau sari kata dalam filem. Proses penalaan halus melaraskan parameter model agar lebih sesuai dengan data perbualan ini, menjadikan chatbot lebih baik dalam memahami dan bertindak balas terhadap input pengguna.
Untuk memperhalusi GPT-3, kami boleh menggunakan perpustakaan Transformers Hugging Face, yang menyediakan model terlatih dan alat penalaan halus. Perpustakaan menyediakan beberapa model GPT-3 dengan saiz dan keupayaan yang berbeza. Lebih besar model, lebih banyak data yang boleh dikendalikan dan lebih tinggi kemungkinan ketepatannya. Walau bagaimanapun, demi kesederhanaan, kami menggunakan antara muka OpenAI kali ini, yang boleh melaksanakan penalaan halus dengan menulis sejumlah kecil kod.
Langkah seterusnya ialah kami menggunakan OpenAI GPT-3 untuk melaksanakan set data boleh didapati dari sini. Maaf, saya menggunakan set data asing sekali lagi set di China.
1 Cipta kunci API Terbuka
Membuat akaun adalah sangat mudah, anda hanya boleh membuka pautan ini. Kita boleh mengakses model pada OpenAI melalui kunci openai. Langkah-langkah untuk mencipta kunci API adalah seperti berikut:
- Log masuk ke akaun anda
- Pergi ke penjuru kanan sebelah atas halaman dan klik pada nama akaun anda, lungsur ke bawah dan klik " Lihat Kunci API"
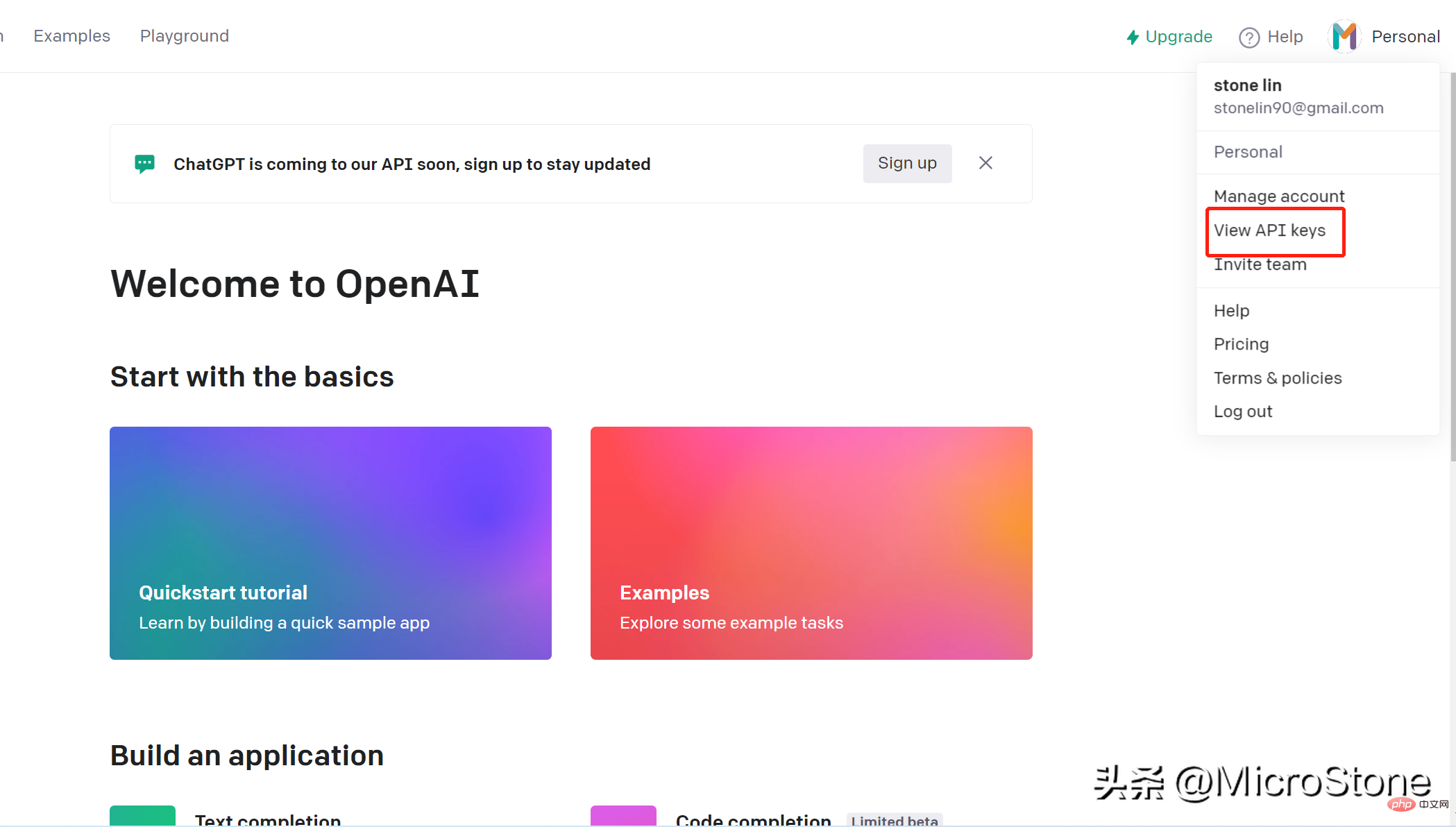
- Klik "Buat Kunci Baharu", ingat untuk menyalin kunci yang dijana dengan segera , ingat dan simpan, jika tidak anda tidak akan dapat melihatnya lagi.
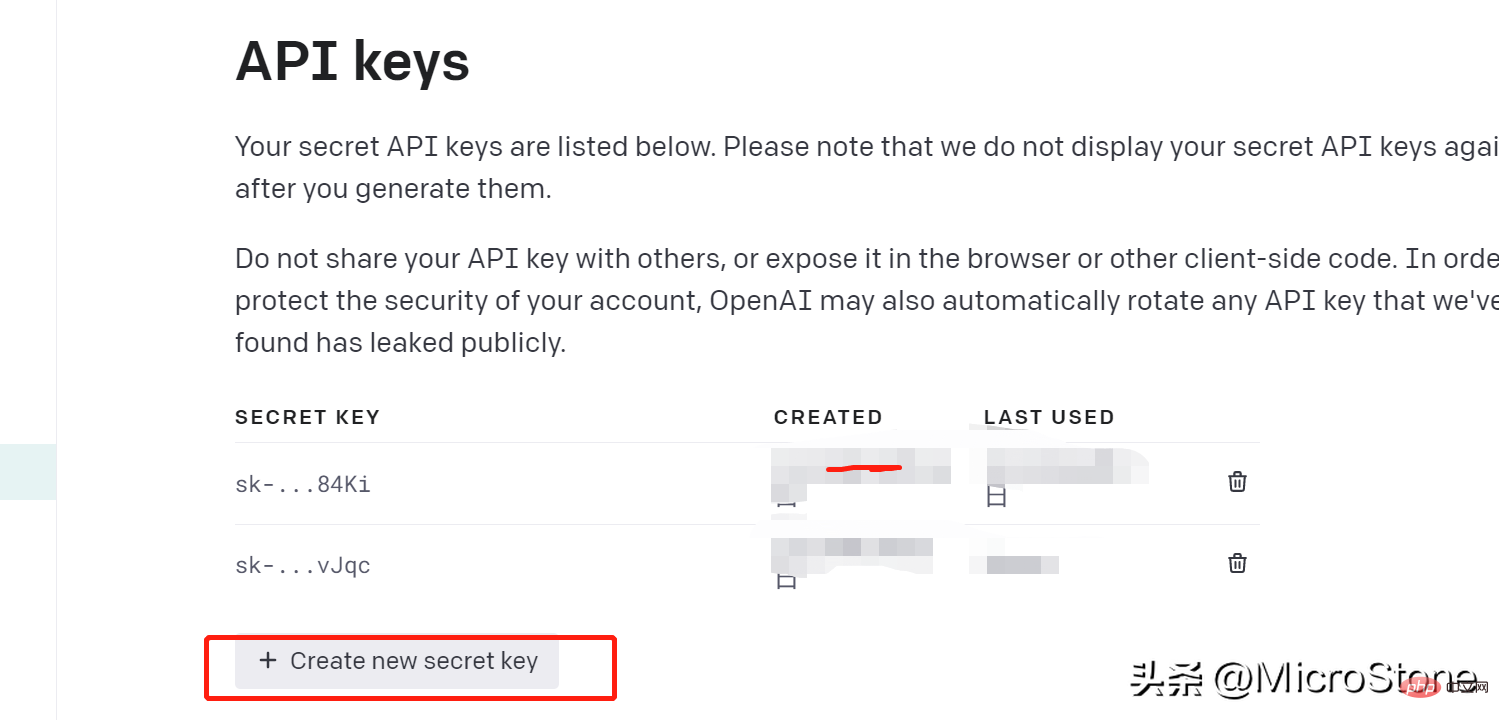
2 Sediakan data
Kami telah mencipta kunci api, kemudian kami boleh mula menyediakan data untuk model penalaan halus, di sini Set data boleh dilihat.

Langkah 1:
Pasang OpenAI library pip install openai
Selepas pemasangan, kami boleh memuatkan data:
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))Kami memuatkan soalan ke dalam lajur AI Temuduga dan jawapan yang sepadan ke dalam lajur Manusia. Kami juga perlu mencipta fail .env pembolehubah persekitaran untuk memegang OPENAI_API_KEY
Seterusnya, kami menukar data kepada standard GPT-3. Menurut dokumentasi, pastikan data berada dalam format JSONL dengan dua kekunci Ini penting: cepat mis.
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }untuk menyusun semula set data untuk menampung perkara di atas, pada asasnya menggelungkan setiap baris dalam data. bingkai, Dan tetapkan teks kepada Manusia dan teks AI Temubual untuk Selesai.
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')Gunakan arahan prepare_data Beberapa soalan akan ditanya apabila kami boleh memberikan jawapan Y atau N.
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")Akhir sekali, fail bernama data_prepared.jsonl dibuang ke dalam direktori.
3. Model Fun-tuning
Untuk menyeronokan model, kita hanya perlu menjalankan satu baris arahan:
os .system( "openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci " )
这基本上使用准备好的数据从 OpenAI 训练davinci模型,fine-tuning后的模型将存储在用户配置文件下,可以在模型下的右侧面板中找到。
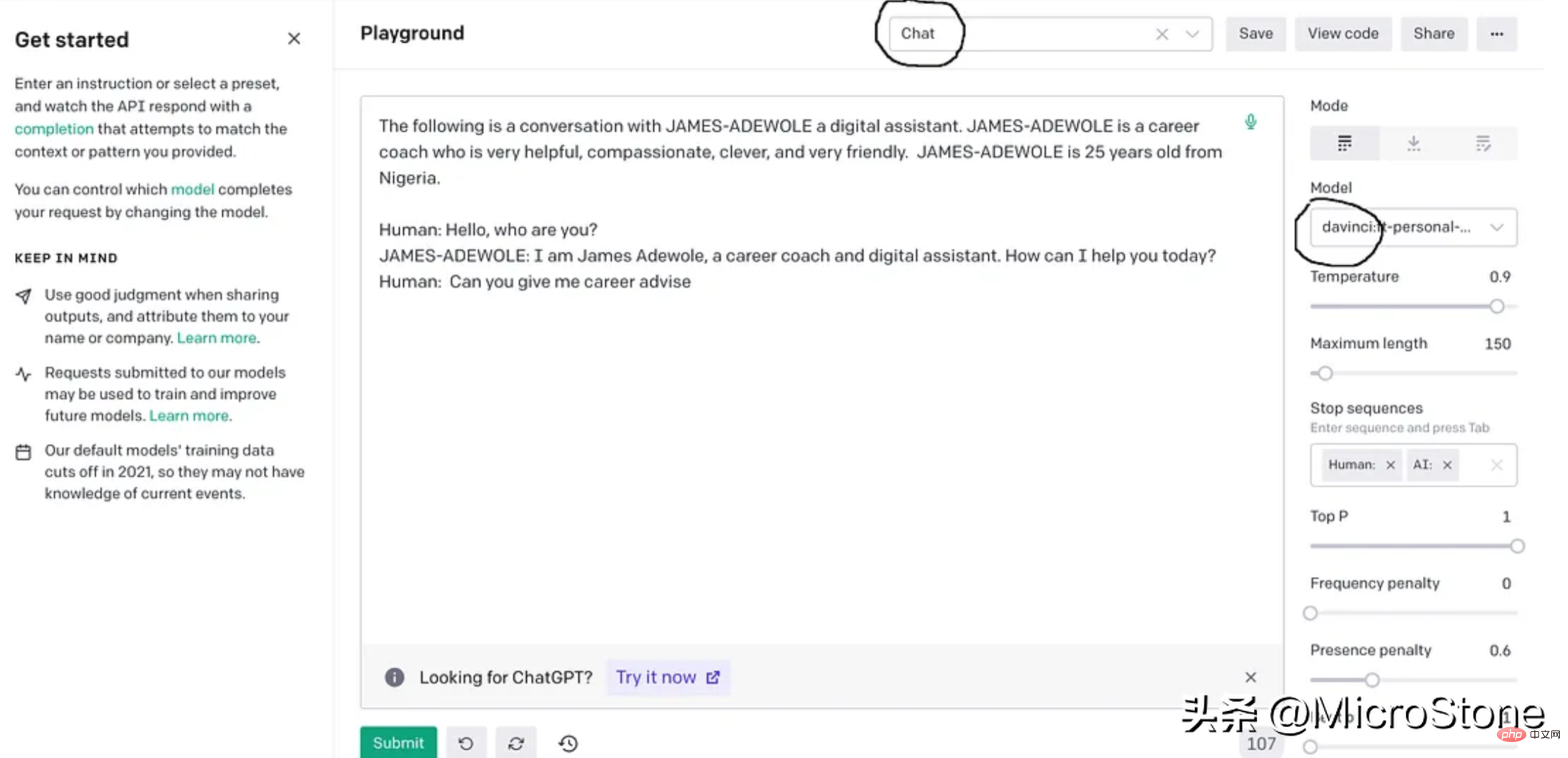
4、模型调试
我们可以使用多种方法来验证我们的模型。可以直接从 Python 脚本、OpenAI Playground 来测试,或者使用 Flask 或 FastAPI 等框构建 Web 服务来测试。
我们先构建一个简单的函数来与此实验的模型进行交互。
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()
output = generate_response(input_text)
print(output)把它们放在一起。
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")
os.system("openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci ")
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()示例响应:
input_text = "what is breadth first search algorithm" output = generate_response(input_text)
The breadth-first search (BFS) is an algorithm for discovering all the reachable nodes from a starting point in a computer network graph or tree data structure
结论
GPT-3 是一种强大的大型语言生成模型,最近火到无边无际的chatgpt就是基于GPT-3上fine-tuning的,我们也可以对GPT-3进行fine-tuning,以构建适合我们自己业务的聊天机器人。fun-tuning过程调整模型的参数可以更好地适应业务对话数据,让机器人更善于理解和响应业务的需求。经过fine-tuning的模型可以集成到聊天机器人平台中以处理用户交互,还可以为聊天机器人生成客服回复习惯与用户交互。整个实现可以在这里找到,数据集可以从这里下载。
Atas ialah kandungan terperinci Gunakan GPT-3 untuk membina chatbot perusahaan yang memenuhi keperluan perniagaan anda. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI