
Rumah >Peranti teknologi >AI >Penyelidikan baharu oleh pasukan Stanford Li Feifei mendapati bahawa mereka bentuk, menambah baik dan menilai data adalah kunci untuk mencapai kecerdasan buatan yang boleh dipercayai
Penyelidikan baharu oleh pasukan Stanford Li Feifei mendapati bahawa mereka bentuk, menambah baik dan menilai data adalah kunci untuk mencapai kecerdasan buatan yang boleh dipercayai

- 王林ke hadapan
- 2023-04-24 10:04:07909semak imbas
Di bawah aliran semasa pembangunan model AI yang beralih daripada tertumpu model kepada tertumpu data, kualiti data menjadi sangat penting.
Dalam proses pembangunan AI sebelumnya, set data selalunya dibetulkan dan usaha pembangunan tertumpu pada lelaran seni bina model atau proses latihan untuk meningkatkan prestasi garis dasar. Kini, dengan lelaran data menjadi tumpuan utama, kami memerlukan cara yang lebih sistematik untuk menilai, menapis, membersihkan dan menganotasi data yang digunakan untuk melatih dan menguji model AI.
Baru-baru ini, Weixin Liang, Li Feifei dan lain-lain daripada Jabatan Sains Komputer di Universiti Stanford bersama-sama menerbitkan artikel bertajuk "Kemajuan, cabaran dan peluang dalam mencipta data untuk AI yang boleh dipercayai" dalam "Kepintaran Mesin Alam Semulajadi" , membincangkan faktor dan kaedah utama untuk memastikan kualiti data dalam semua aspek keseluruhan proses data AI.

Alamat kertas: https://www.nature.com/articles/s42256-022-00516-1.epdf?sharing_token=VPzI-KWAm8tLG_BiXJnV9tRgN0jAjRgN0jAj3 rwhu7Hi_VBEr6peszIAFc6XO1tdlvV1lLJQtOvUFnSXpvW6_nu0Knc_dRekx6lyZNc6PcM1nslocIcut_qNW9OUg1IsbCfuL058R4MsYFqyzlb2E%3D
Langkah utama dalam proses data AI termasuk: reka bentuk data (pengumpulan dan rakaman data), penambahbaikan data (penapisan data, pembersihan, anotasi, peningkatan), dan strategi data untuk menilai dan memantau model AI, setiap yang Semua pautan akan menjejaskan kredibiliti model AI akhir.
Rajah 1: Pelan hala tuju pembangunan pendekatan berpusat data daripada reka bentuk data kepada penilaian.
1. Reka bentuk data untuk AI
Selepas mengenal pasti aplikasi kecerdasan buatan, langkah pertama dalam membangunkan model AI ialah mereka bentuk data (iaitu, mengenal pasti dan merekodkan sumber data).
Reka bentuk hendaklah proses berulang - menggunakan data percubaan untuk membangunkan model AI awal, kemudian mengumpul data tambahan untuk menampal had model. Kriteria utama untuk reka bentuk ialah memastikan data itu sesuai untuk tugasan dan meliputi skop yang mencukupi untuk mewakili pengguna dan senario yang berbeza yang mungkin dihadapi oleh model.
Dan set data yang kini digunakan untuk membangunkan AI selalunya mempunyai liputan terhad atau berat sebelah. Dalam AI perubatan, sebagai contoh, pengumpulan data pesakit yang digunakan untuk membangunkan algoritma adalah diedarkan secara tidak seimbang secara geografi, yang boleh mengehadkan kebolehgunaan model AI kepada populasi yang berbeza.
Salah satu cara untuk meningkatkan liputan data ialah melibatkan komuniti yang lebih luas dalam penciptaan data. Ini ditunjukkan oleh projek Common Voice, set data awam terbesar yang tersedia pada masa ini, yang mengandungi 11,192 jam transkripsi pertuturan dalam 76 bahasa daripada lebih 166,000 peserta.
Apabila data perwakilan sukar diperoleh, data sintetik boleh digunakan untuk mengisi jurang liputan. Contohnya, pengumpulan wajah sebenar selalunya melibatkan isu privasi dan bias pensampelan, manakala wajah sintetik yang dicipta oleh model generatif dalam kini digunakan untuk mengurangkan ketidakseimbangan dan berat sebelah data. Dalam penjagaan kesihatan, rekod perubatan sintetik boleh dikongsi untuk memudahkan penemuan pengetahuan tanpa mendedahkan maklumat sebenar pesakit. Dalam robotik, cabaran dunia sebenar ialah ujian muktamad, dan persekitaran simulasi kesetiaan tinggi boleh digunakan untuk membolehkan ejen belajar dengan lebih pantas dan selamat dalam tugasan yang kompleks dan jangka panjang.
Tetapi terdapat juga beberapa masalah dengan data sintetik. Sentiasa terdapat jurang antara data sintetik dan dunia sebenar, jadi kemerosotan prestasi sering berlaku apabila model AI yang dilatih pada data sintetik dipindahkan ke dunia nyata. Data sintetik juga boleh memburukkan lagi jurang data jika simulator tidak direka bentuk dengan mengambil kira kumpulan minoriti Prestasi model AI sangat bergantung pada konteks data latihan dan penilaian mereka, jadi adalah penting untuk mendokumenkan konteks reka bentuk data dalam piawai dan. pelaporan yang telus.
Kini, penyelidik telah mencipta pelbagai "label pemakanan data" untuk menangkap metadata tentang reka bentuk data dan proses anotasi. Metadata berguna termasuk statistik tentang jantina, jantina, bangsa dan lokasi geografi peserta dalam set data, yang boleh membantu mengetahui sama ada terdapat subkumpulan yang kurang diwakili yang tidak dilindungi. Data provenance juga merupakan jenis metadata yang menjejaki asal dan masa data serta proses dan kaedah yang menghasilkan data.
Metadata boleh disimpan dalam dokumen reka bentuk data khusus, yang penting untuk memerhati kitaran hayat dan konteks sosio-teknikal data. Dokumen boleh dimuat naik ke repositori data yang stabil dan terpusat seperti Zenodo.
2. Perbaik data: tapis, bersihkan, labelkan, tingkatkan
Selepas set data awal dikumpul, kami perlu menambah baik data untuk menyediakan data yang lebih berkesan untuk pembangunan AI. Ini ialah perbezaan utama antara pendekatan berpusatkan model kepada AI dan pendekatan berpusatkan data, seperti yang ditunjukkan dalam Rajah 2a Penyelidikan berpusatkan model biasanya berdasarkan data yang diberikan dan menumpukan pada meningkatkan seni bina model atau mengoptimumkan data ini. Penyelidikan berpusatkan data, sebaliknya, memfokuskan pada kaedah berskala untuk menambah baik data secara sistematik melalui proses seperti pembersihan data, penapisan, anotasi dan peningkatan, serta boleh menggunakan platform pembangunan model sehenti.

Rajah 2a: Perbandingan pendekatan berpusatkan model AI dan berpusatkan data. MNIST, COCO dan ImageNet adalah set data yang biasa digunakan dalam penyelidikan AI.
Penyaringan data
Jika set data sangat bising, kami perlu menyaring data dengan teliti sebelum latihan, yang boleh meningkatkan kebolehpercayaan dan generalisasi model dengan ketara. Imej kapal terbang dalam Rajah 2a ialah titik data bising yang harus dikeluarkan daripada set data burung.
Dalam Rajah 2b, empat model terkini yang dilatih pada data dermatologi besar yang digunakan sebelum ini semuanya berprestasi buruk disebabkan berat sebelah dalam data latihan, terutamanya pada imej kulit gelap Tidak bagus, dan Model 1 terlatih pada data yang lebih kecil dan berkualiti tinggi secara relatifnya lebih dipercayai pada kedua-dua warna kulit gelap dan cerah.
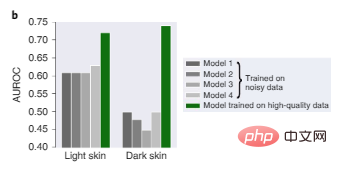
Rajah 2b: Prestasi ujian diagnostik dermatologi pada kulit cerah dan imej kulit gelap.
Rajah 2c menunjukkan bahawa ResNet, DenseNet dan VGG, tiga seni bina pembelajaran mendalam yang popular untuk klasifikasi imej, berprestasi buruk apabila dilatih pada set data imej yang bising. Selepas menapis mengikut nilai Shapley data, data dengan kualiti yang lemah dipadamkan Pada masa ini, prestasi model ResNet yang dilatih pada subset data yang lebih bersih adalah jauh lebih baik.
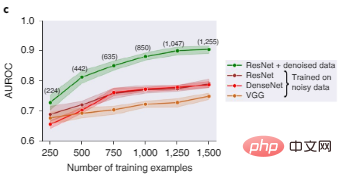
Rajah 2c: Perbandingan prestasi ujian pengecaman objek bagi model berbeza sebelum dan selepas penapisan data. Nombor dalam kurungan mewakili bilangan mata data latihan yang tinggal selepas menapis data yang bising, dengan keputusan diagregatkan ke atas lima biji rawak, dan kawasan berlorek mewakili selang keyakinan 95%.
Inilah maksud penilaian data, ia bertujuan untuk mengukur kepentingan data yang berbeza dan menapis data yang mungkin membahayakan prestasi model disebabkan kualiti yang rendah atau berat sebelah.
Pembersihan Data
Dalam artikel ini, penulis memperkenalkan dua kaedah penilaian data untuk membantu membersihkan data:
Satu kaedah adalah untuk mengukur apabila data yang berbeza dipadamkan semasa latihan. perubahan dalam prestasi model AI boleh diperoleh dengan menggunakan nilai Shapley atau penghampiran kesan data, seperti ditunjukkan dalam Rajah 3a di bawah. Pendekatan ini membolehkan penilaian pengiraan yang cekap bagi model AI yang besar.
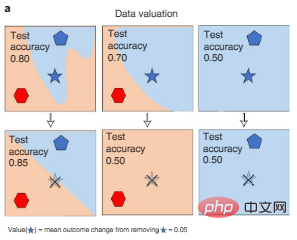
Rajah 3a: Penilaian data. Nilai Shapley bagi data mengukur perubahan dalam prestasi model yang dilatih pada subset data yang berbeza apabila titik tertentu dialihkan daripada latihan (bintang berbucu lima pudar dicoret dalam rajah), dengan itu mengukur setiap titik data (titik simbol bintang berbucu lima) nilai. Warna mewakili label kategori.
Pendekatan lain ialah meramalkan ketidakpastian untuk mengesan titik data berkualiti rendah. Anotasi manusia bagi titik data boleh menyimpang secara sistematik daripada ramalan model AI, dan algoritma pembelajaran keyakinan boleh mengesan penyelewengan ini, dengan lebih daripada 3% data ujian didapati salah label pada penanda aras biasa seperti ImageNet. Menapis ralat ini boleh meningkatkan prestasi model dengan sangat baik.
Anotasi data
Anotasi data juga merupakan sumber utama bias data. Walaupun model AI boleh bertolak ansur dengan tahap hingar label rawak tertentu, ralat berat sebelah boleh menghasilkan model berat sebelah. Pada masa ini, kami bergantung terutamanya pada anotasi manual, yang sangat mahal Contohnya, kos untuk membuat anotasi satu imbasan LIDAR mungkin melebihi $30 Oleh kerana ia adalah data tiga dimensi, pencatat perlu melukis kotak sempadan tiga dimensi adalah lebih menuntut daripada tugas anotasi umum.
Oleh itu, penulis percaya bahawa kami perlu menentukur alat anotasi dengan teliti pada platform sumber ramai seperti MTurk untuk menyediakan peraturan anotasi yang konsisten. Dalam persekitaran perubatan, ia juga penting untuk mempertimbangkan bahawa anotasi mungkin memerlukan pengetahuan khusus atau mungkin mempunyai data sensitif yang tidak boleh disumber ramai.
Salah satu cara untuk mengurangkan kos anotasi ialah pengaturcaraan data. Dalam pengaturcaraan data, pembangun AI tidak lagi perlu melabel titik data secara manual, sebaliknya menulis fungsi pelabelan program untuk melabel set latihan secara automatik. Seperti yang ditunjukkan dalam Rajah 3b, selepas menjana berbilang label yang berpotensi bising secara automatik untuk setiap input menggunakan fungsi label yang ditentukan pengguna, kami boleh mereka bentuk algoritma tambahan untuk mengagregatkan berbilang ciri label untuk mengurangkan hingar.
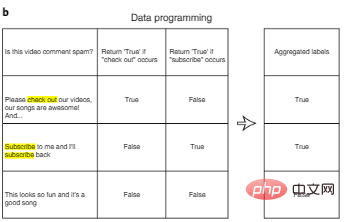
Rajah 3b: Pengaturcaraan data.
Satu lagi pendekatan "human-in-the-loop" untuk mengurangkan kos pelabelan adalah dengan mengutamakan data yang paling berharga supaya kami boleh melabelkannya melalui pembelajaran aktif. Pembelajaran aktif memperoleh idea daripada reka bentuk eksperimen yang optimum Dalam pembelajaran aktif, algoritma memilih titik paling bermaklumat daripada satu set titik data yang tidak berlabel, seperti titik dengan perolehan maklumat yang tinggi atau titik yang modelnya tidak pasti anotasi. Faedah pendekatan ini ialah jumlah data yang diperlukan adalah lebih kecil daripada yang diperlukan untuk pembelajaran seliaan standard.
Pembesaran Data
Akhir sekali, apabila data sedia ada masih sangat terhad, penambahan data adalah kaedah yang berkesan untuk mengembangkan set data dan meningkatkan kebolehpercayaan model.
Data penglihatan komputer boleh dipertingkatkan dengan putaran imej, flip dan transformasi digital lain, dan data teks boleh dipertingkatkan dengan transformasi kepada gaya penulisan automatik. Terdapat juga Mixup baru-baru ini, teknik penambahan yang lebih kompleks yang mencipta data latihan baharu dengan menginterpolasi pasangan sampel latihan, seperti yang ditunjukkan dalam Rajah 3c.
Selain peningkatan data manual, proses peningkatan data automatik AI semasa juga merupakan penyelesaian yang popular. Selain itu, apabila data tidak berlabel tersedia, penambahan label juga boleh dicapai dengan menggunakan model awal untuk membuat ramalan (ramalan ini dipanggil pseudo-label), dan kemudian melatih model yang lebih besar pada data gabungan dengan pseudo- berkeyakinan tinggi yang nyata dan berkeyakinan tinggi. label.
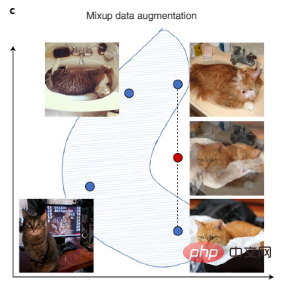
Rajah 3c: Campuran menambah set data dengan mencipta data sintetik yang menginterpolasi data sedia ada. Titik biru mewakili titik data sedia ada dalam set latihan, dan titik merah mewakili titik data sintetik yang dicipta dengan menginterpolasi dua titik data sedia ada.
3. Data untuk menilai dan memantau model AI
Selepas model dilatih, matlamat penilaian AI ialah kebolehgeneralisasian dan kredibiliti model.
Untuk mencapai matlamat ini, kami harus mereka bentuk data penilaian dengan teliti untuk mencari tetapan dunia sebenar model, dan data penilaian juga perlu cukup berbeza daripada data latihan model.
Sebagai contoh, dalam penyelidikan perubatan, model AI biasanya dilatih berdasarkan data daripada sebilangan kecil hospital. Apabila model sedemikian digunakan di hospital baharu, ketepatannya berkurangan disebabkan oleh perbezaan dalam pengumpulan dan pemprosesan data. Untuk menilai generalisasi model, adalah perlu untuk mengumpul data penilaian daripada hospital yang berbeza dan saluran paip pemprosesan data yang berbeza. Dalam aplikasi lain, data penilaian hendaklah dikumpul daripada sumber yang berbeza, sebaiknya dilabelkan sebagai data latihan oleh anotasi yang berbeza. Pada masa yang sama, label manusia berkualiti tinggi kekal sebagai penilaian yang paling penting.
Peranan penting penilaian AI adalah untuk menentukan sama ada model AI menggunakan korelasi palsu sebagai "jalan pintas" dalam data latihan yang tidak dapat dikonsepkan dengan baik. Contohnya, dalam pengimejan perubatan, cara data diproses (seperti pemangkasan atau pemampatan imej) boleh mencipta korelasi palsu (iaitu, pintasan) yang diambil oleh model. Pintasan ini mungkin berguna di permukaan, tetapi boleh gagal secara besar-besaran apabila model digunakan dalam persekitaran yang sedikit berbeza.
Ablasi data sistematik ialah cara terbaik untuk memeriksa kemungkinan "pintasan" model. Dalam ablasi data, model AI dilatih dan diuji pada input ablasi isyarat permukaan yang berkorelasi palsu.
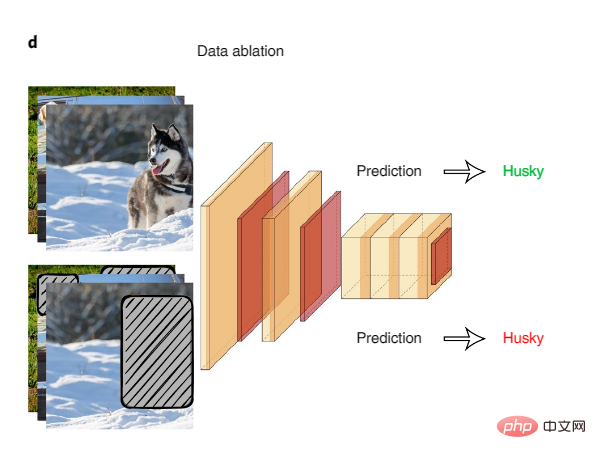
Rajah 4: Ablasi data
Contoh penggunaan ablasi data untuk mengesan pintasan model ialah kajian tentang set data inferens bahasa semula jadi yang biasa, model AI dilatih hanya pada separuh pertama input teks mencapai ketepatan yang tinggi dalam membuat kesimpulan hubungan logik antara bahagian pertama dan kedua teks, berbanding dengan tahap inferens manusia dan meneka secara rawak pada input yang sama. Ini menunjukkan bahawa model AI mengeksploitasi korelasi palsu sebagai jalan pintas untuk menyelesaikan tugas ini. Pasukan penyelidik mendapati bahawa fenomena linguistik tertentu dieksploitasi oleh model AI, seperti penolakan dalam teks yang sangat berkorelasi dengan tag.
Ablasi data digunakan secara meluas dalam pelbagai bidang. Contohnya, dalam bidang perubatan, bahagian imej yang berkaitan secara biologi boleh disembunyikan sebagai cara untuk menilai sama ada AI belajar daripada latar belakang palsu atau artifak kualiti imej.
Penilaian AI selalunya terhad kepada membandingkan metrik prestasi keseluruhan merentas keseluruhan set data ujian. Tetapi walaupun model AI berfungsi dengan baik pada tahap data keseluruhan, ia mungkin masih menunjukkan ralat sistematik pada subkumpulan data tertentu, dan mencirikan kelompok ralat ini boleh memberikan pemahaman yang lebih baik tentang batasan model.
Apabila metadata tersedia, kaedah penilaian yang terperinci harus menghiris data penilaian mengikut jantina, jantina, bangsa dan lokasi geografi peserta dalam set data apabila boleh - contohnya, "Lelaki Lebih Tua Asia" atau "Asli Amerika wanita”—dan ukur prestasi model pada setiap subkumpulan data. Pengauditan berbilang ketepatan ialah algoritma yang secara automatik mencari subkumpulan data yang model AI berprestasi buruk. Di sini, algoritma pengauditan dilatih untuk meramal dan mengelompokkan ralat model asal menggunakan metadata, dan kemudian memberikan jawapan yang boleh dijelaskan kepada soalan seperti kesilapan yang dilakukan oleh model AI dan mengapa.
Apabila metadata tidak tersedia, kaedah seperti Domino secara automatik mengenal pasti kelompok data yang mana model penilaian terdedah kepada ralat dan menggunakan penjanaan teks untuk mencipta penjelasan bahasa semula jadi tentang ralat model ini.
4. Masa depan data
Pada masa ini kebanyakan projek penyelidikan AI hanya membangunkan set data sekali sahaja, tetapi pengguna AI dunia sebenar selalunya perlu mengemas kini set data dan model secara berterusan. Pembangunan data yang berterusan akan membawa cabaran berikut:
Pertama, kedua-dua data dan tugas AI boleh berubah mengikut masa: contohnya, mungkin model kenderaan baharu muncul di jalan raya (iaitu peralihan domain) , atau mungkin AI pemaju ingin mengenali kategori objek baharu (contohnya, jenis bas sekolah yang berbeza daripada bas biasa), yang akan mengubah klasifikasi label. Membuang berjuta-juta jam data teg lama adalah membazir, jadi kemas kini adalah penting. Selain itu, metrik latihan dan penilaian hendaklah direka bentuk dengan teliti untuk menimbang data baharu dan menggunakan data yang sesuai untuk setiap subtugas.
Kedua, untuk memperoleh dan menggunakan data secara berterusan, pengguna perlu mengautomasikan kebanyakan proses AI yang mengutamakan data. Automasi ini melibatkan penggunaan algoritma untuk memilih data yang hendak dihantar kepada annotator dan cara menggunakannya untuk melatih semula model dan hanya memaklumkan pembangun model jika berlaku kesilapan dalam proses (contohnya, jika metrik ketepatan menurun). Sebagai sebahagian daripada trend "MLOps (Machine Learning Operations)", syarikat industri mula menggunakan alatan untuk mengautomasikan kitaran hayat pembelajaran mesin.
Atas ialah kandungan terperinci Penyelidikan baharu oleh pasukan Stanford Li Feifei mendapati bahawa mereka bentuk, menambah baik dan menilai data adalah kunci untuk mencapai kecerdasan buatan yang boleh dipercayai. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI