
Rumah >Peranti teknologi >AI >Gambaran keseluruhan status semasa teknologi pembelajaran bersekutu dan aplikasinya dalam pemprosesan imej
Gambaran keseluruhan status semasa teknologi pembelajaran bersekutu dan aplikasinya dalam pemprosesan imej

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-23 12:55:111675semak imbas
Dalam beberapa tahun kebelakangan ini, graf telah digunakan secara meluas untuk mewakili dan memproses data yang kompleks dalam banyak bidang, seperti penjagaan perubatan, pengangkutan, bioinformatik dan sistem pengesyoran. Teknologi pembelajaran mesin graf ialah alat yang berkuasa untuk mendapatkan maklumat kaya yang tersembunyi dalam data yang kompleks, dan telah menunjukkan prestasi yang kukuh dalam tugas seperti pengelasan nod dan ramalan pautan.
Walaupun teknologi pembelajaran mesin graf telah mencapai kemajuan yang ketara, kebanyakannya memerlukan data graf untuk disimpan secara berpusat pada satu mesin. Walau bagaimanapun, dengan penekanan pada keselamatan data dan privasi pengguna, penyimpanan data berpusat telah menjadi tidak selamat dan tidak boleh dilaksanakan. Data graf sering diedarkan merentasi berbilang sumber data (silo data), dan atas sebab privasi dan keselamatan, ia menjadi tidak mungkin untuk mengumpul data graf yang diperlukan dari tempat yang berbeza.
Sebagai contoh, syarikat pihak ketiga ingin melatih model pembelajaran mesin graf untuk sesetengah institusi kewangan untuk membantu mereka mengesan potensi jenayah kewangan dan pelanggan penipuan. Setiap institusi kewangan memegang data pelanggan peribadi, seperti data demografi dan rekod transaksi. Pelanggan setiap institusi kewangan membentuk graf pelanggan, di mana tepi mewakili rekod transaksi. Disebabkan dasar privasi dan persaingan perniagaan yang ketat, setiap data pelanggan peribadi organisasi tidak boleh dikongsi secara langsung dengan syarikat pihak ketiga atau organisasi lain. Pada masa yang sama, mungkin juga terdapat hubungan antara institusi, yang boleh dianggap sebagai maklumat struktur antara institusi. Oleh itu, cabaran utama adalah untuk melatih model pembelajaran mesin graf untuk pengesanan jenayah kewangan berdasarkan graf pelanggan persendirian dan maklumat struktur antara agensi tanpa akses terus kepada data pelanggan persendirian setiap institusi.
Pembelajaran bersekutu (FL) ialah penyelesaian pembelajaran mesin teragih yang menyelesaikan masalah pulau data melalui latihan kolaboratif. Ia membolehkan peserta (iaitu pelanggan) untuk bersama-sama melatih model pembelajaran mesin tanpa berkongsi data peribadi mereka. Oleh itu, menggabungkan FL dengan pembelajaran mesin graf menjadi penyelesaian yang menjanjikan kepada masalah di atas.
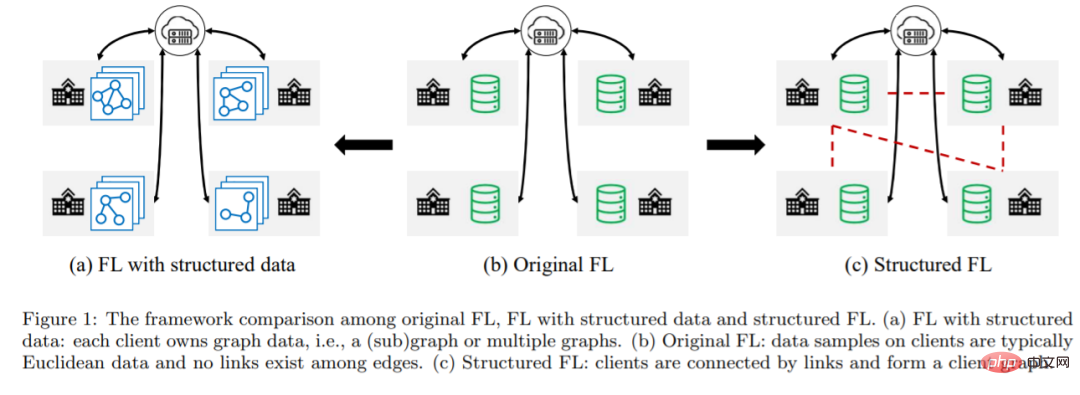
Dalam artikel ini, penyelidik dari Universiti Virginia mencadangkan Pembelajaran Mesin Graf Bersekutu (FGML). Secara umumnya, FGML boleh dibahagikan kepada dua tetapan berdasarkan tahap maklumat struktur: yang pertama ialah FL dengan data berstruktur Dalam FL dengan data berstruktur, pelanggan secara kolaboratif melatih model pembelajaran mesin graf berdasarkan data graf mereka, manakala Simpan data graf secara tempatan. . Jenis kedua ialah FL berstruktur Dalam FL berstruktur, terdapat maklumat struktur antara pelanggan, membentuk graf pelanggan. Kaedah pengoptimuman bersama yang lebih cekap boleh direka bentuk menggunakan graf klien.

Alamat kertas: https://arxiv.org/pdf/2207.11812.pdf
Walaupun FGML menyediakan pelan tindakan yang menjanjikan, masih terdapat beberapa cabaran:
1. Dalam FL dengan data berstruktur, senario biasa ialah setiap mesin pelanggan mempunyai subgraf graf global, dan sesetengah nod mungkin mempunyai jiran rapat kepunyaan pelanggan lain. Atas sebab privasi, nod hanya boleh mengagregatkan ciri jiran terdekat mereka dalam klien, tetapi tidak boleh mengakses ciri yang terletak pada klien lain, yang membawa kepada kurang perwakilan nod.
2. Kebocoran privasi struktur graf. Dalam FL tradisional, pelanggan tidak dibenarkan mendedahkan ciri dan label sampel data mereka. Dalam FL dengan data berstruktur, privasi maklumat struktur juga harus dipertimbangkan. Maklumat struktur boleh didedahkan secara langsung melalui matriks bersebelahan yang dikongsi atau secara tidak langsung melalui pembenaman nod penghantaran.
3. Tidak seperti FL tradisional yang heterogeniti data berasal daripada sampel data bukan IID, data graf dalam FGML mengandungi maklumat struktur yang kaya. Pada masa yang sama, struktur graf pelanggan yang berbeza juga akan mempengaruhi prestasi model pembelajaran mesin graf.
4. Strategi untuk menggunakan parameter. Dalam FL berstruktur, graf pelanggan membolehkan pelanggan mendapatkan maklumat daripada pelanggan jiran mereka. Dalam FL berstruktur, strategi berkesan perlu direka bentuk untuk mengeksploitasi sepenuhnya maklumat jiran yang diselaraskan oleh pelayan pusat atau terdesentralisasi sepenuhnya.
Untuk menangani cabaran di atas, penyelidik telah membangunkan sejumlah besar algoritma. Pelbagai algoritma kini tertumpu terutamanya pada cabaran dan kaedah dalam FL standard, dengan hanya beberapa percubaan untuk menangani masalah dan teknik khusus dalam FGML. Seseorang menerbitkan kertas ulasan yang mengklasifikasikan FGML, tetapi tidak meringkaskan teknik utama dalam FGML. Sesetengah artikel ulasan hanya meliputi bilangan kertas yang berkaitan yang terhad di FL dan secara ringkas memperkenalkan teknologi sedia ada semasa.
Dalam kertas kerja yang diperkenalkan hari ini, penulis mula-mula memperkenalkan konsep dua reka bentuk masalah dalam FGML. Kemudian, kemajuan teknologi terkini di bawah setiap shezhi disemak, dan aplikasi praktikal FGML turut diperkenalkan. dan meringkaskan set data graf yang boleh diakses dan platform yang tersedia untuk aplikasi FGML. Akhirnya, penulis memberikan beberapa arahan penyelidikan yang menjanjikan. Sumbangan utama artikel termasuk:
Taksonomi teknologi FGML: Artikel ini memberikan taksonomi FGML berdasarkan masalah yang berbeza dan meringkaskan cabaran utama dalam setiap tetapan.
Semakan Teknologi Komprehensif: Artikel ini memberikan gambaran menyeluruh tentang teknologi sedia ada dalam FGML. Berbanding dengan kertas semakan sedia ada yang lain, penulis bukan sahaja mengkaji rangkaian kerja berkaitan yang lebih luas, tetapi juga menyediakan analisis teknikal yang lebih terperinci dan bukannya hanya menyenaraikan langkah-langkah setiap kaedah.
Aplikasi praktikal: Artikel ini meringkaskan aplikasi praktikal FGML buat kali pertama. Penulis mengelaskannya mengikut bidang aplikasi dan memperkenalkan karya berkaitan dalam setiap bidang.
Set Data dan Platform: Artikel ini memperkenalkan set data dan platform sedia ada dalam FGML, yang sangat membantu jurutera dan penyelidik yang ingin membangunkan algoritma dan menggunakan aplikasi dalam FGML.
Arahan masa hadapan: Artikel ini bukan sahaja menunjukkan had kaedah sedia ada, tetapi juga memberikan hala tuju pembangunan masa depan FGML.
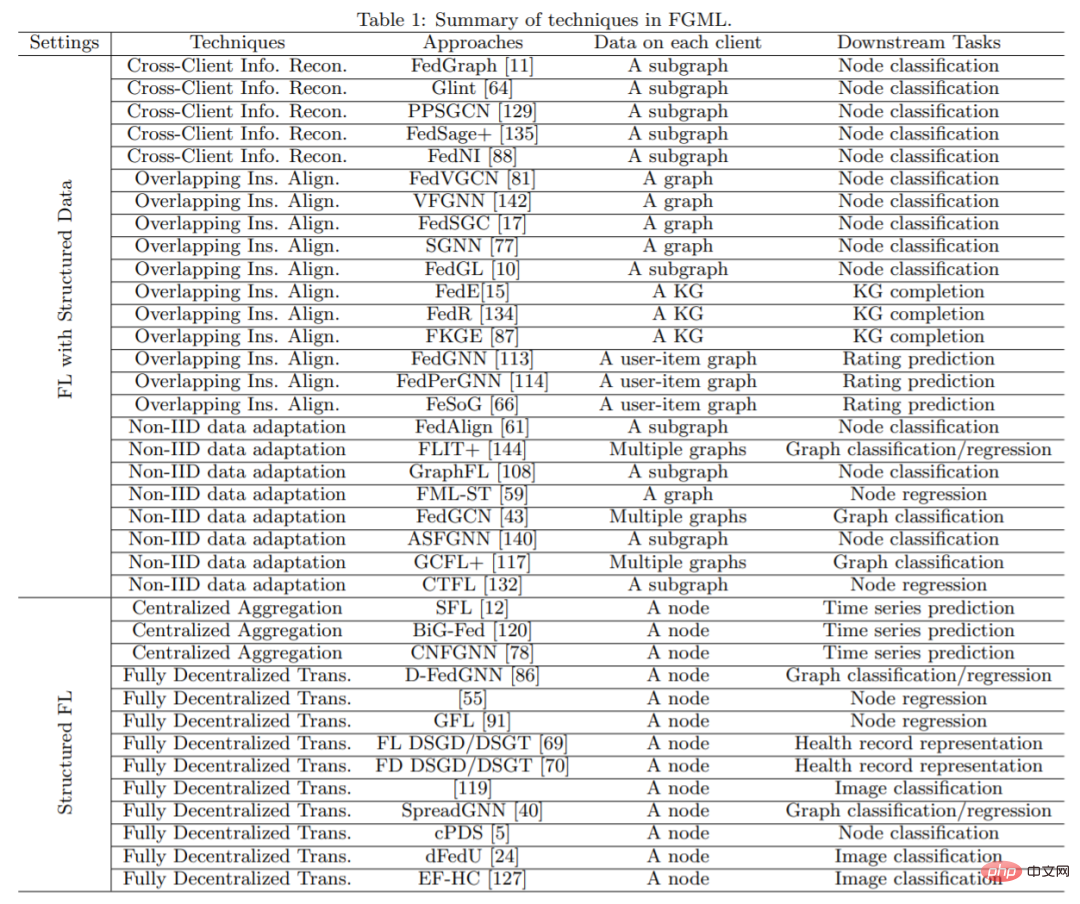
Gambaran Keseluruhan Teknologi FGML Berikut ialah struktur utama artikel pengenalan.
Bahagian 2 memperkenalkan secara ringkas definisi dalam pembelajaran mesin graf serta konsep serta cabaran dalam kedua-dua tetapan dalam FGML.
Bahagian 3 dan 4 menyemak teknologi dominan dalam kedua-dua tetapan. Bahagian 5 meneroka lebih lanjut aplikasi dunia sebenar FGML. Bahagian 6 memperkenalkan Set Data Graf Terbuka dan dua platform untuk FGML yang digunakan dalam kertas FGML yang berkaitan. Arah masa hadapan yang mungkin disediakan dalam Bahagian 7 .
Akhirnya Bahagian 8 meringkaskan teks penuh. Sila rujuk kertas asal untuk butiran lanjut.
Atas ialah kandungan terperinci Gambaran keseluruhan status semasa teknologi pembelajaran bersekutu dan aplikasinya dalam pemprosesan imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI