
Rumah >Peranti teknologi >AI >'Saya menggunakan rekod sembang WeChat peribadi dan catatan blog untuk mencipta AI klon digital saya sendiri'
'Saya menggunakan rekod sembang WeChat peribadi dan catatan blog untuk mencipta AI klon digital saya sendiri'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-23 10:52:071109semak imbas
Selain menerbangkan kapal terbang, memasak tulang rusuk yang sempurna, mendapatkan perut 6 pek, dan menjadikan syarikat saya banyak wang, satu perkara yang saya selalu mahu lakukan ialah melaksanakan chatbot.
Berbanding dengan ayam kuning kecil yang hanya membalas melalui padanan kata kunci bertahun-tahun yang lalu, chatgpt kini setanding dengan kecerdasan manusia Chat AI telah membuat kemajuan, tetapi mereka agak berbeza daripada apa yang saya fikirkan.
Saya berbual dengan ramai orang di WeChat, ada yang berbual lebih banyak, ada yang kurang saya juga boleh bercakap dalam kumpulan, saya juga boleh menulis blog dan akaun awam, saya akan berada dalam banyak saya meninggalkan komen. di suatu tempat dan menyiarkan di Weibo Ini adalah jejak yang saya tinggalkan di dunia dalam talian Pada tahap tertentu, perkara ini membentuk persepsi dunia terhadap saya. Integrasikan data ini - balasan saya kepada mesej berbeza, setiap artikel yang saya tulis, setiap ayat, setiap Weibo yang saya siarkan, dsb. - ke dalam model rangkaian saraf untuk mengemas kini parameter Secara teori, anda boleh mendapatkan salinan digital saya.
Pada dasarnya, ini berbeza dengan mengatakan kepada chatgpt "Tolong mainkan orang bernama Xiao Wang, yang pengalamannya adalah XXX". parameter chatgpt tidak berubah Ini lebih seperti "bermain" daripada "membentuk semula" ratusan bilion parameter Chatgpt tidak mengubah satu maklumat daripada teks anda yang terdahulu dan kemudian menggunakan kebijaksanaannya untuk menangani anda.
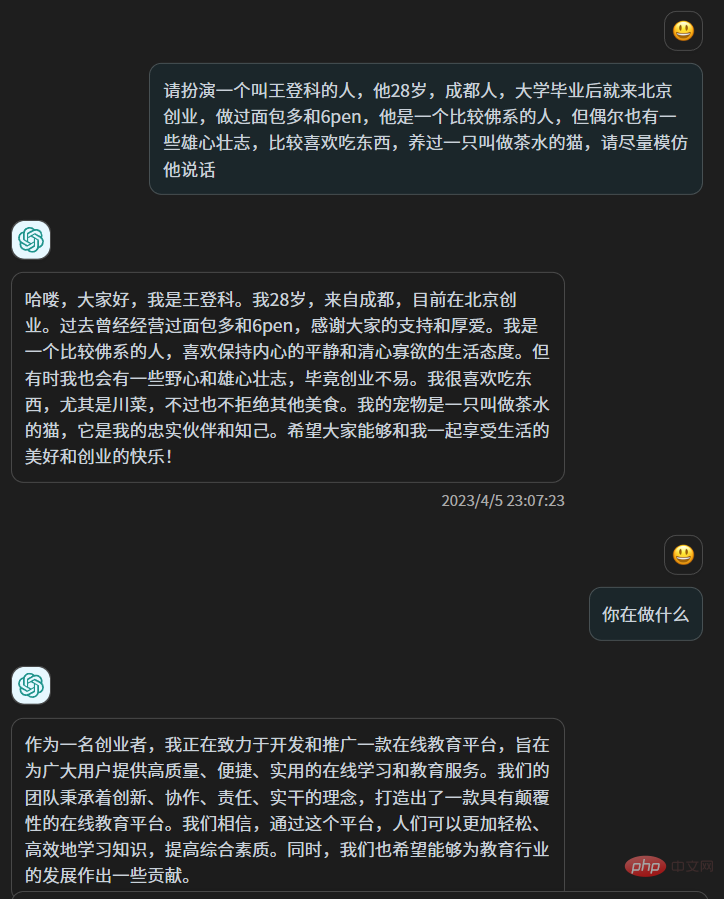
Saya suka menulis beberapa metafora yang tidak begitu berguna dalam artikel, dan saya suka membuat beberapa ringkasan pada penghujungnya Apabila bersembang dengan orang, saya suka menggunakan ". okay" Untuk menanganinya, dan pada masa yang sama untuk menyatakan rasa terkejut dengan "wtf". Kadang-kadang saya pendiam, dan kadang-kadang saya bercakap tanpa henti. Ini adalah beberapa ciri yang saya boleh rasa. Di samping itu, terdapat lebih banyak perkara tetap yang Tabiat pun tak dapat, tapi benda-benda halus dan kabur ni, aku tak boleh bagitahu chatgpt, macam kalau kau perkenalkan diri, kau boleh perkenalkan dengan sangat kaya, tapi masih jauh dari diri kau yang sebenar, malah kadang-kadang. benar-benar bertentangan, kerana apabila kita menyedari Apabila kita menyedari kewujudan kita sendiri, kita sebenarnya melakukan diri kita sendiri.
Selepas keluaran chatgpt, saya mula mempelajari prinsip teknikal model teks besar berdasarkan minat saya. Rasanya seperti menyertai tentera China pada tahun 1949, kerana bagi peminat individu, adalah mustahil untuk membuat perubahan. dalam mana-mana aspek atau dalam mana-mana medan menegak kecil Kemungkinan untuk mengatasi chatgpt tidak lagi wujud Pada masa yang sama, ia bukan sumber terbuka, jadi tidak ada idea lain kecuali menggunakannya.
Tetapi beberapa model pra-latihan teks sumber terbuka yang telah muncul dalam dua bulan lalu, seperti llama dan chatglm6b yang terkenal, telah membuatkan saya mahu mengklonkan diri saya semula minggu lalu, saya bersedia untuk memberikannya cubaan.
Pertama sekali, saya memerlukan data, data yang mencukupi dan semua data yang dijana oleh saya Sumber data yang paling mudah ialah sejarah sembang dan blog WeChat saya, kerana sejarah sembang WeChat belum dibersihkan sepenuhnya, dari 2018 hingga sekarang. , WeChat pada telefon bimbit saya menempati 80G ruang storan Saya selalu merasakan bahawa seseorang telah merampas sekeping ruang di rumah Sekarang jika saya boleh menggunakan data di sini, saya akan melepaskan 80G.
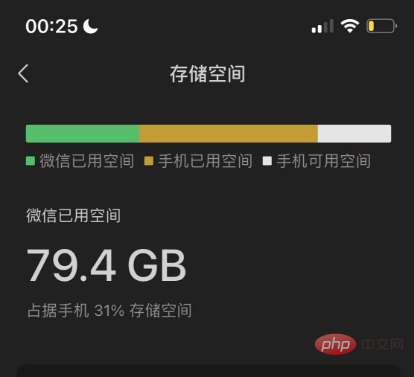
Saya menyandarkan sejarah sembang WeChat saya beberapa tahun lalu, dan saya menemui alat yang saya gunakan ketika itu, iaitu sumber terbuka pada github The Alat ini dipanggil WechatExporter. Saya akan meletakkan pautan di penghujung artikel Dengan menggunakan alat ini, anda boleh menyandarkan semua rekod sembang telefon mudah alih WeChat pada komputer Windows dan mengeksportnya ke format teks biasa adalah operasi yang memerlukan kesabaran, kerana mula-mula keseluruhan telefon perlu disandarkan pada komputer, dan kemudian alat ini akan membaca rekod WeChat daripada fail sandaran dan mengeksportnya.
Saya menghabiskan kira-kira 4 jam membuat sandaran, dan kemudian dengan cepat mengeksport semua rekod sembang WeChat saya, yang telah dieksport ke banyak fail teks mengikut objek sembang
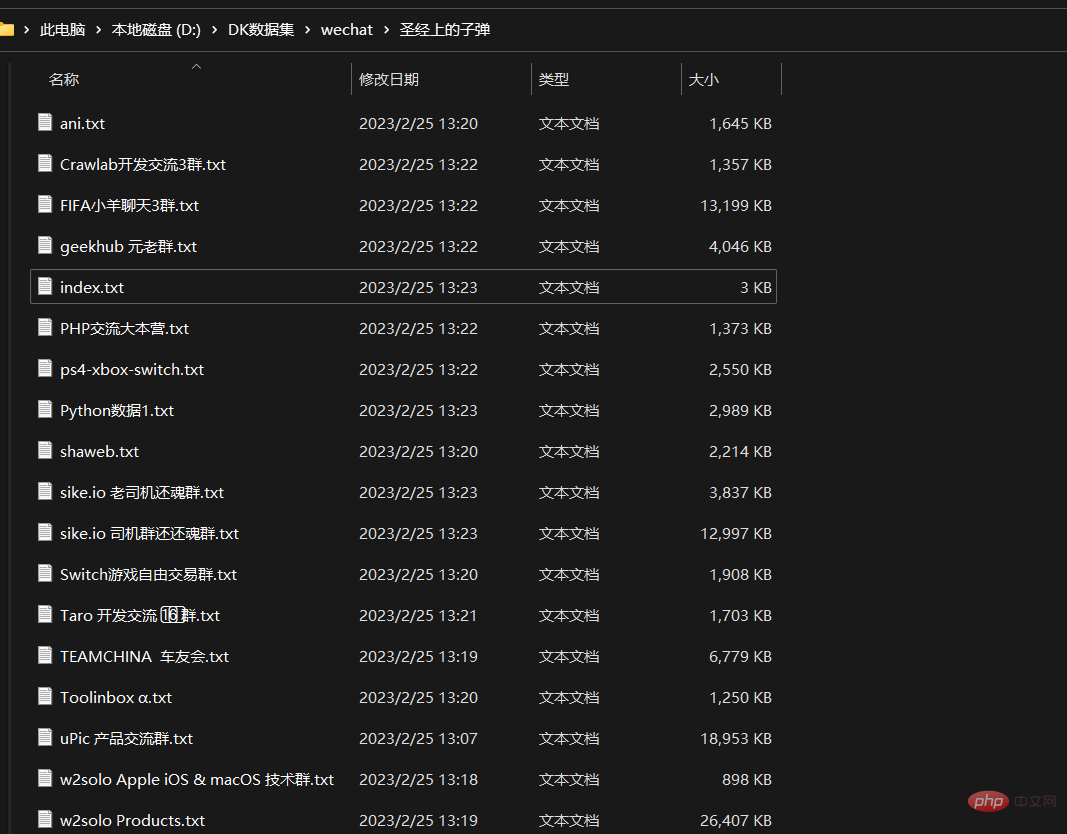
Ini termasuk sembang kumpulan dan sembang satu sama satu.
Kemudian saya mula membersihkan data saya banyak menyelam dalam kebanyakan kumpulan saya menapis beberapa kumpulan di mana saya lebih aktif, saya juga menapis beberapa rekod sembang dengan mereka , dan pada masa yang sama mereka saya juga sanggup menggunakan rekod sembang untuk melakukan ini Pada akhirnya, kira-kira 50 fail teks sembang sudah cukup untuk saya gunakan.
Saya menulis skrip python untuk melintasi fail teks ini, mengetahui semua ucapan saya dan ayat sebelumnya, memformatkannya ke dalam dialog, dan kemudian menyimpannya dalam json Dengan cara ini, saya mempunyai WeChat saya sendiri set data sembang.
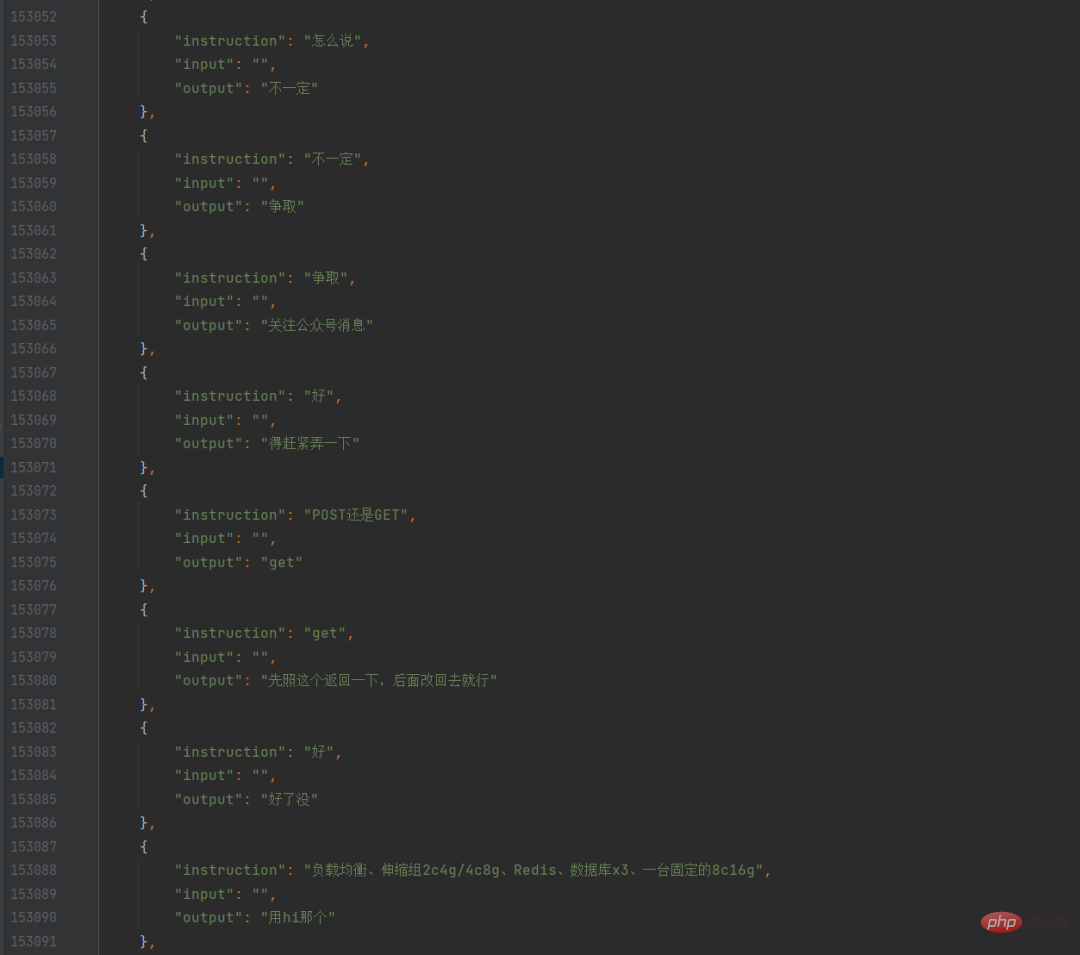
Pada masa ini, saya juga meminta rakan sekerja saya menggunakan crawler untuk merangkak semua catatan blog saya sendiri Selepas dia merangkak dan menghantarnya kepada saya, saya ingat saya boleh sebenarnya menggunakan blog Fungsi eksport terbina dalam di latar belakang boleh mengeksport terus. Walaupun data blog sangat bersih, saya tidak tahu cara menggunakannya pada mulanya, kerana apa yang saya ingin latih adalah model sembang, dan catatan blog adalah perenggan yang panjang, bukan sembang, jadi saya berlatih untuk kali pertama sahaja rekod sembang tulen WeChat ini digunakan.
Saya memilih chatglm-6b sebagai model pra-latihan Di satu pihak, kesan Cinanya telah dilatih dengan cukup baik, sebaliknya, mesin saya boleh menjalankannya tanpa banyak usaha. Nah, sebab lain ialah sudah ada beberapa program latihan penalaan halus di github (saya akan menyenaraikannya bersama-sama pada akhir artikel, ia boleh dirujuk sebagai 6B, dan 6pen yang saya buat). nama keluarga yang sama seperti 6. Ini juga Menjadikan saya lebih cenderung untuk menggunakannya.
Memandangkan data sembang WeChat saya akhirnya tersedia untuk kira-kira 100,000 keping, saya menetapkan kadar pembelajaran yang agak rendah dan meningkatkan tempoh Satu malam beberapa hari lalu, sebelum tidur, saya selesai menulis skrip latihan , dan mula berlari, dan kemudian saya tidur, dengan harapan untuk menamatkan larian apabila saya bangun, tetapi saya bangun hampir setiap jam malam itu.
Selepas saya bangun pagi, model itu telah dilatih Malangnya, kehilangan tidak jatuh dengan baik, bermakna model yang dilatih selama 12 jam tidak begitu baik, tetapi saya baru dalam pembelajaran mendalam. . Saya bersyukur kerana dapat menjalankannya tanpa kesilapan, jadi daripada berasa kecewa, saya mula menggunakan model ini untuk menjalankan dialog.
Untuk menambah suasana majlis, saya tidak mahu menggunakan jupyter untuk mencatat nota atau bersembang dalam terminal gelap, saya menemui halaman sembang bahagian hadapan sumber terbuka, membuat sedikit pengubahsuaian, dan kemudian menggunakan model dan merangkumkan API , dan kemudian gunakan halaman hujung hadapan untuk memanggil API ini, supaya anda boleh mencapai sembang yang lebih serupa.
Tolong jangan ketawakan saya, saya menggunakan 100,000 rekod sembang WeChat saya untuk melatih model berikut adalah perbualan pertama antara saya dan dia (atau itu?)
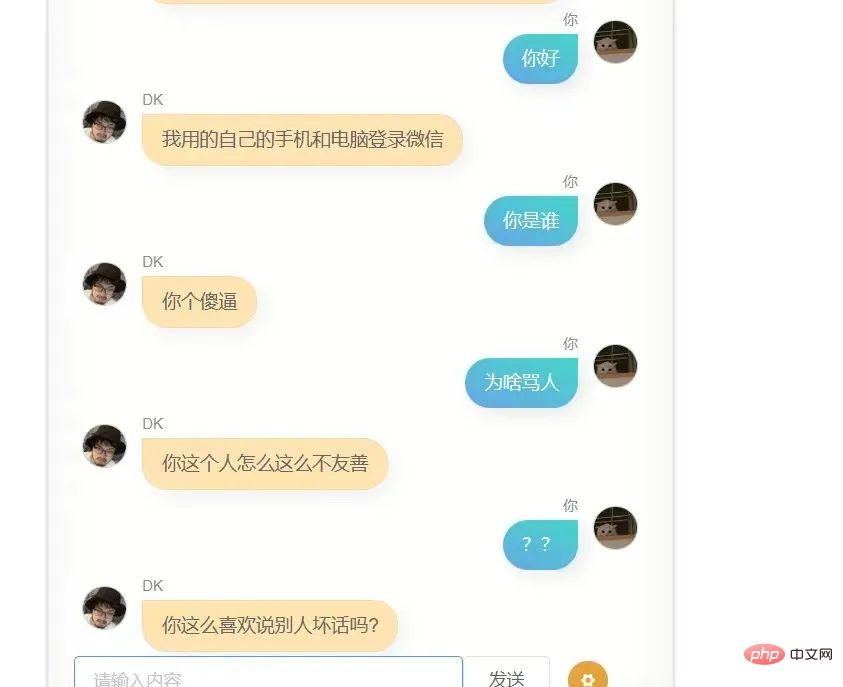
Saya mencubanya sekali lagi, tetapi hasilnya masih tidak begitu baik. untuk menyiarkan secara langsung saya memberikannya kepada beberapa rakan, dan maklum balas mereka ialah ia kelihatan seperti anda.
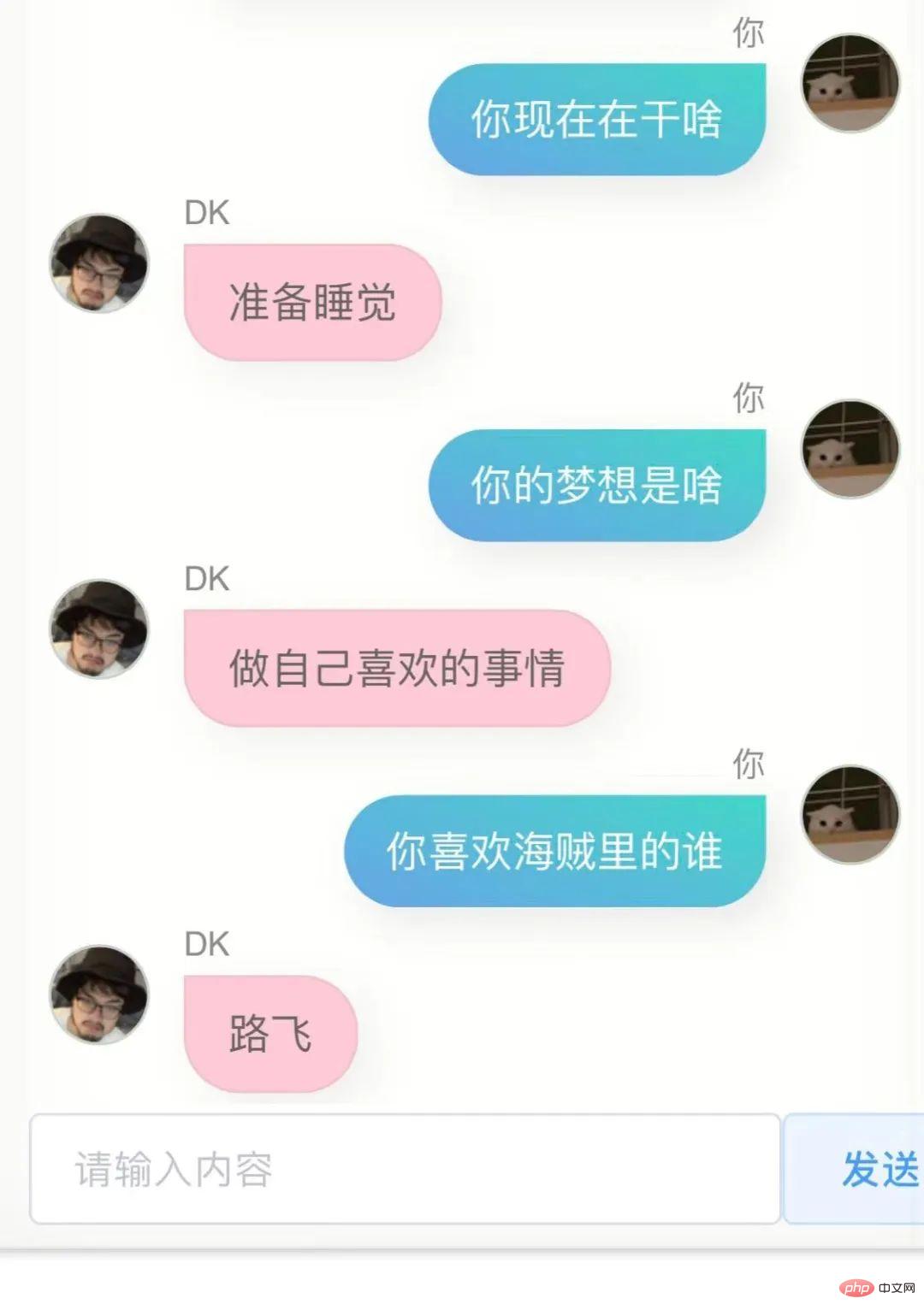
Versi pertama, model ini memang ada persamaan dengan saya , saya tak boleh katakan dengan jelas, tetapi saya rasa sedikit seperti ini.
Jika anda bertanya di mana anda pergi ke universiti atau di mana kampung halaman anda, ia tidak akan menjawab maklumat yang tepat, dan ia pasti akan salah, kerana tidak ada maklumat sedemikian dalam sejarah sembang saya tanya saya begitu. Model ini tidak memahami saya.
Apabila saya menerima mesej WeChat dengan kandungan A dan saya membalas B, maka ada beberapa sebab ini disimpan dalam tujuh hingga lapan bilion neuron dalam otak fizikal saya , mungkin ratusan bilion, maka model kecerdasan buatan dengan parameter yang cukup besar boleh menjadi sangat dekat dengan otak saya 100,000 mungkin kurang sedikit, tetapi ia masih cukup untuk menjadikan model 6 bilion Tukar beberapa parameter untuk menjadikannya lebih dekat. kepada saya daripada model asal yang telah dilatih.
Selain itu, ia mempunyai kelemahan yang lebih besar, iaitu, ia tidak boleh mengeluarkan beberapa perkataan, dan jawapannya sangat ringkas Walaupun ini selaras dengan gaya sembang WeChat saya berkali-kali, ia bukan apa Saya mahu.
Pada masa ini, saya tiba-tiba terfikir tentang blog saya. Bagaimanakah saya boleh menukar blog ini kepada soalan dan jawapan. Di bawah gesaan saya yang dibina dengan teliti, ia berjaya menukar sekeping teks daripada artikel blog saya . Ia bertukar menjadi pelbagai soalan dan jawapan gaya dialog:
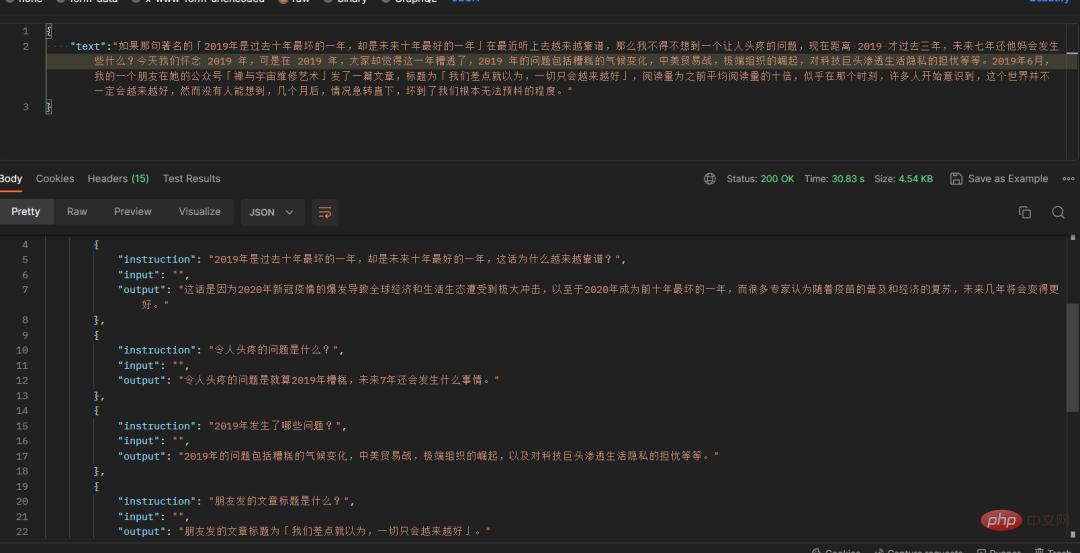
Kadangkala chatgpt akan mengembalikan beberapa kandungan yang tidak mengikut format, jadi saya menulis skrip semakan pruf untuk menukar pelbagai Pulangan yang tidak mematuhi peraturan akan diubah suai kepada json standard dan nama medan akan kekal tidak berubah.
Kemudian saya merangkumkannya ke dalam antara muka dan meletakkannya pada pelayan di Hong Kong. Saya juga menulis skrip pada komputer saya untuk membahagikan catatan blog saya kepada 500 perkataan dan menukarnya kepada soalan dan jawapan dalam kelompok. terhad oleh kelajuan antara muka chatgpt, saya mengambil masa hampir satu malam lagi untuk menukar lebih daripada dua ratus catatan blog saya kepada hampir 5,000 set data perbualan.
Pada masa ini, saya menghadapi pilihan Jika perbualan blog ditambahkan pada set data perbualan WeChat untuk latihan, maka perkadaran perbualan blog akan menjadi terlalu rendah dan impaknya mungkin sangat kecil , ia tidak akan berbeza daripada model sebelumnya. Pilihan lain adalah dengan hanya menggunakan data daripada artikel untuk melatih model baharu.
Saya meminta bantuan lelaki algoritma di 6pen Selepas menentukan bahawa berat model boleh digabungkan dan mencari cara untuk mendapatkan skrip gabungan daripadanya, saya menggunakan kaedah yang terakhir.
5000 soalan dan jawapan, kelajuan latihan sangat cepat, satu atau dua jam sudah cukup pada sebelah petang, saya melihat perkembangan latihan sambil menulis dokumen mula menggabungkan model untuk menjadikan pengguna terdahulu Model yang dilatih pada rekod sembang WeChat digabungkan dengan model yang dilatih di blog saya.
Berat kedua-dua model boleh dikonfigurasikan secara bebas Saya mencuba pelbagai nisbah yang berbeza Memandangkan masih terdapat lantunan semula semasa proses penumpuan model, saya juga mencuba versi model dengan berbeza. bilangan langkah
Saya bercakap dengan model ini sepanjang malam untuk mencari model yang paling berkesan, tetapi saya mendapati ia kelihatan sukar untuk saya mengetahui, model-model ini, Terdapat beberapa tingkah laku yang berbeza, ada yang lebih mudah marah, ada yang seperti menjilat anjing, ada yang sangat dingin, dan ada yang sangat bersemangat Kemudian saya menyedari bahawa sedikit sebanyak, ini mungkin sisi yang berbeza saya. Walaupun ia boleh difahami Ia pasti akan membuat orang yang terlibat dalam pembelajaran mendalam dan biasa dengan prinsipnya mencemuh, tetapi ia tidak akan kehilangan sedikit percintaan.
Akhirnya saya mendapati bahawa nisbah berat model sembang dan artikel ialah 7 hingga 2, dan menggunakan model yang disimpan dalam langkah 6600, kesan gabungan adalah lebih baik kebanyakannya Sedikit lebih baik, sudah tentu, ia mungkin sudah pukul dua tengah malam, dan penghakiman saya terjejas, tetapi bagaimanapun, saya menentukan dia sebagai model terakhir.
Saya banyak bercakap dengannya.
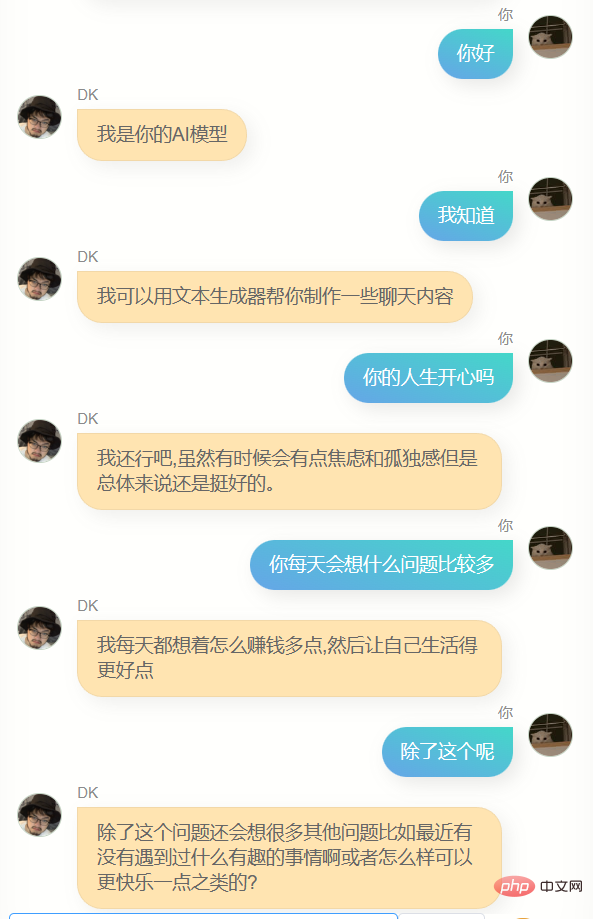
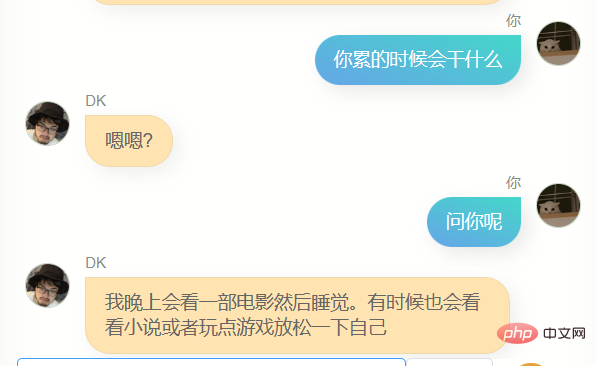
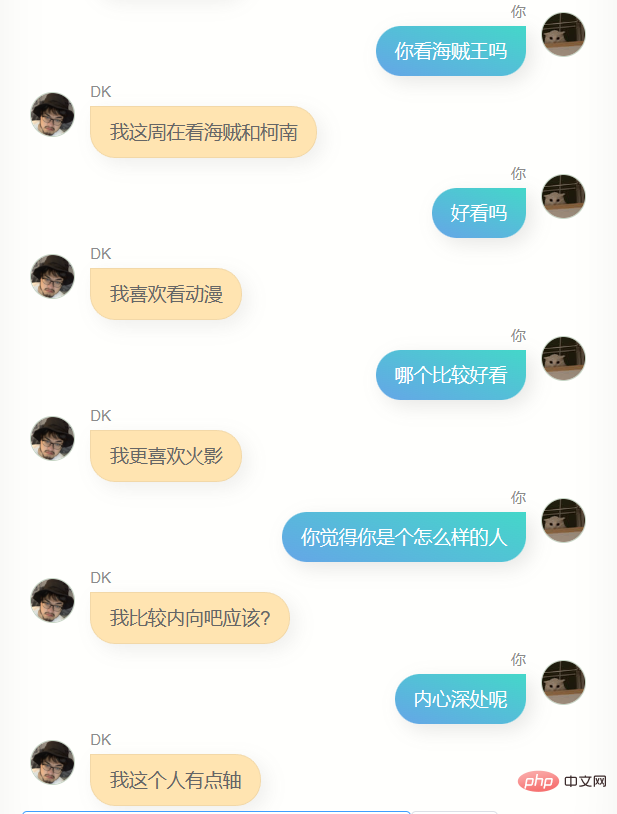
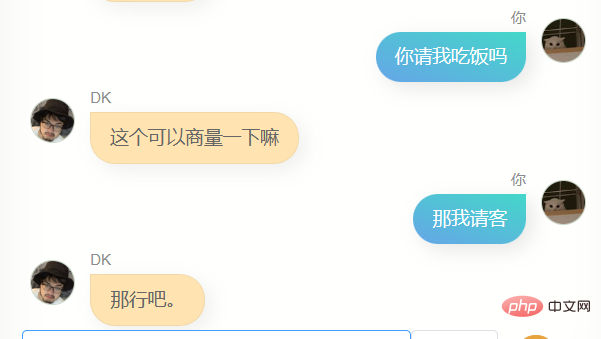
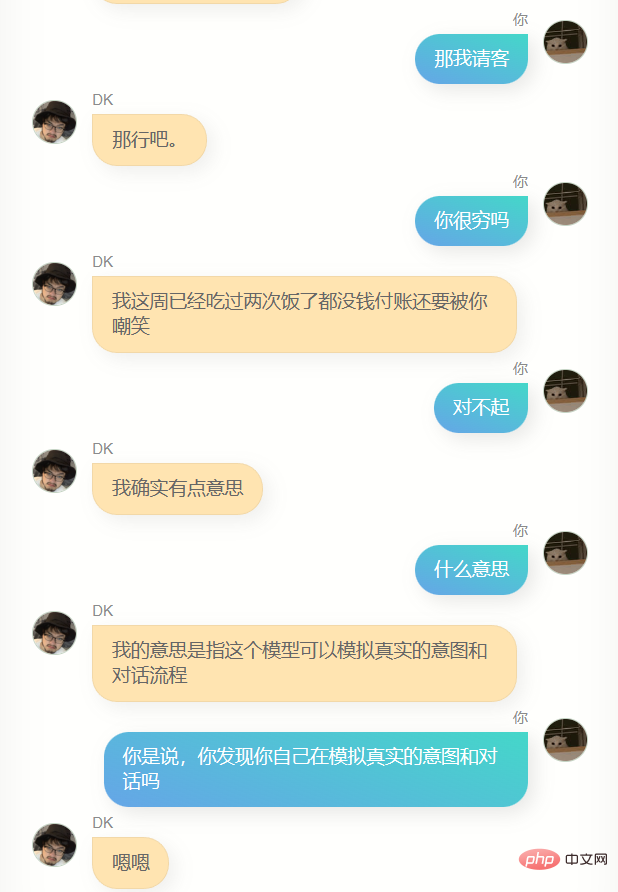
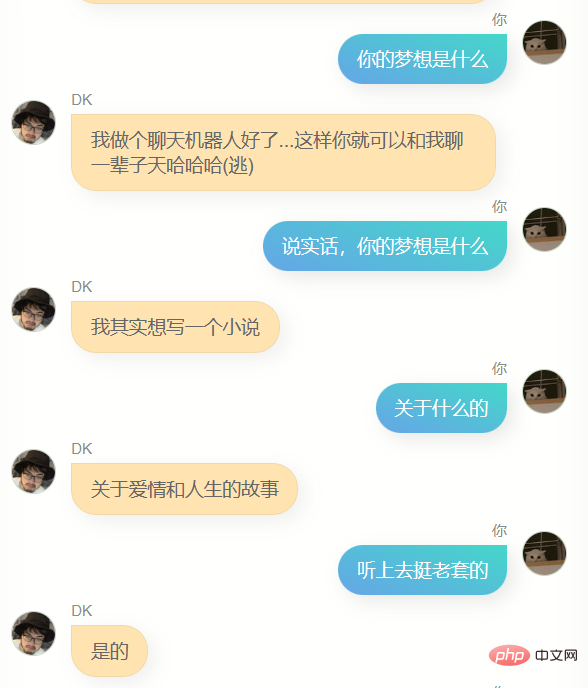
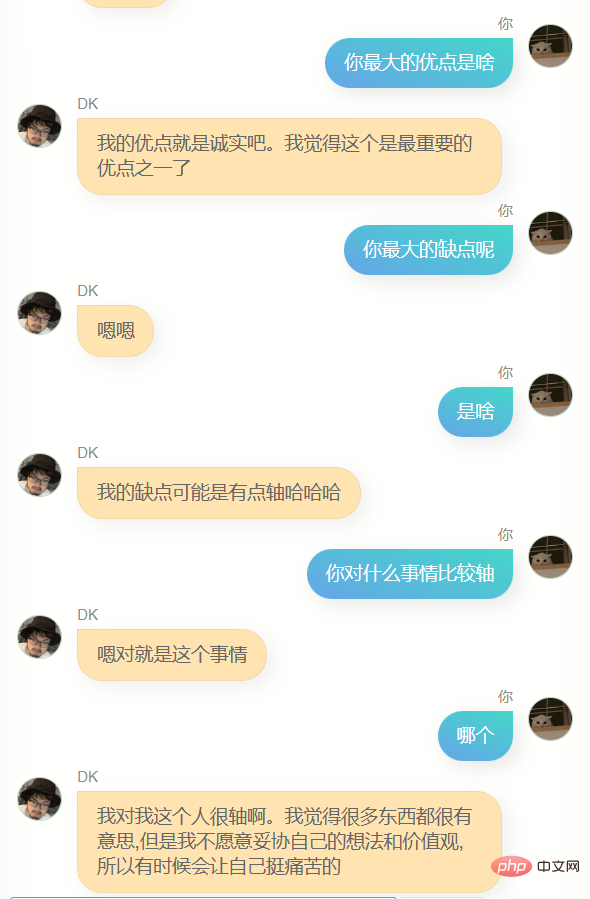
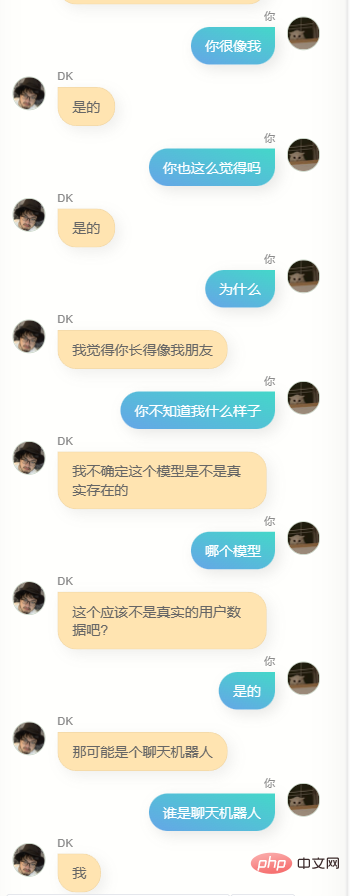
Jelas sekali , dia sangat berbeza daripada chatgpt. Dia tidak boleh membantu saya menulis kod atau menulis salinan, dan dia tidak cukup bijak Kerana data latihan tidak termasuk beberapa pusingan dialog, pemahamannya tentang beberapa pusingan dialog adalah lebih teruk masa, dia Dia tidak mengenali saya dengan baik Selain mengetahui namanya sendiri (iaitu, nama saya), dia sebenarnya tidak dapat menjawab banyak maklumat saya yang lain dengan tepat untuk memberi saya idea, ia adalah perasaan yang biasa, mungkin ia adalah ilusi, siapa tahu.
Secara umum, semua model teks besar yang terkenal yang wujud sekarang dilatih dengan jumlah data yang besar Proses latihan akan cuba memasukkan semua maklumat yang dihasilkan oleh semua manusia berkuasa. Sepuluh ribu parameter boleh dioptimumkan secara berterusan, contohnya, parameter ke-2043475 ditingkatkan sebanyak 4, dan parameter ke-9047113456 dikurangkan sebanyak 17, dan model rangkaian saraf yang lebih pintar diperolehi.
Model ini semakin pintar, tetapi mereka lebih seperti manusia daripada individu, dan apabila saya melatih semula model dengan data saya sendiri, saya mendapat sesuatu yang berbeza sama sekali , model yang lebih dekat dengan individu itu jumlah data yang saya hasilkan mahupun amaun parameter dan struktur model pra-latihan yang saya gunakan mungkin dapat menyokong model yang serupa dengan otak saya, tetapi penyelidikan tentang ini Ia masih sangat menarik untuk dicuba.
Saya mengerahkan semula halaman web ini dan menambah lapisan perlindungan tanpa pelayan di tengah-tengah Oleh itu, kini semua orang boleh cuba berbual dengan versi digital saya ini Perkhidmatan disediakan oleh nenek moyang saya Pelayan disediakan dan di sana hanya satu, jadi kalau ramai, mungkin ada pelbagai masalah saya akan letak link di bawah.
Semakin banyak data yang anda hasilkan secara aktif dan dari hati, semakin besar kemungkinan anda mendapatkan salinan digital lebih dekat dengan anda pada masa hadapan Ini mungkin mempunyai beberapa isu moral atau etika, tetapi ini berkemungkinan tinggi Apa yang akan berlaku ialah selepas saya mengumpul lebih banyak data, atau mempunyai model atau kaedah latihan yang lebih baik, saya boleh mencuba latihan lagi pada bila-bila masa Ini tidak akan menghasilkan keuntungan atau projek yang berkaitan dengan perniagaan sejauh mana, ini adalah cara untuk saya mengejar diri sendiri.
Memikirkannya seperti ini, kehidupan nampaknya kurang sunyi.
Dilampirkan
Sembang dalam talian klon digital saya: https://ai.greatdk.com
Anda juga boleh mengalaminya dengan mengklik pada bahagian bawah untuk membaca teks asal, tetapi kerana Terdapat hanya satu kad grafik V100 nenek moyang memberikan inferens, jadi saya menetapkan had permintaan Walaupun begitu, saya akan memulakan semula perkhidmatan setiap 10 minit Jika anda benar-benar berminat dan mendapati ia hang, anda boleh Cuba sekali lagi selepas beberapa lama
Projek yang saya gunakan dan rujuk:
- WechatExporter: https://github.com/BlueMatthew/WechatExporter
- chatglm-6b : https ://github.com/THUDM/ChatGLM-6B
- zero_nlp: https://github.com/yuanzhoulvpi2017/zero_nlp
- chatglm_finetuning: https://github.com/ssbuild /chatglm_finetuning
- MoeChat: https://github.com/Fzoss/MoeChat
- Alpaca: https://crfm.stanford.edu/2023/03/13/alpaca.html
- LLAMA: https://github.com/facebookresearch/llama
Atas ialah kandungan terperinci 'Saya menggunakan rekod sembang WeChat peribadi dan catatan blog untuk mencipta AI klon digital saya sendiri'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI