
Rumah >Peranti teknologi >AI >Dolly 2.0, model besar ChatGPT sumber terbuka pertama di dunia, boleh diubah suai sesuka hati untuk kegunaan komersil
Dolly 2.0, model besar ChatGPT sumber terbuka pertama di dunia, boleh diubah suai sesuka hati untuk kegunaan komersil

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-22 12:28:081675semak imbas
Seperti yang kita semua tahu, OpenAI tidak Terbuka apabila ia berkaitan dengan ChatGPT Model siri alpaca yang bersumberkan terbuka daripada Meta juga "terhad kepada aplikasi penyelidikan akademik" kerana isu seperti set data untuk pintasan Apabila ia datang kepada kaedah menyekat, ini datang model besar yang memfokuskan pada sumber terbuka 100%.
Pada 12 April, Databricks mengeluarkan Dolly 2.0, yang merupakan satu lagi versi baharu model bahasa besar (LLM) seperti ChatGPT interaktiviti manusia (mengikut arahan) yang dikeluarkan dua minggu lalu.
Databricks berkata Dolly 2.0 ialah sumber terbuka pertama industri, LLM yang mematuhi arahan, diperhalusi pada set data yang telus dan tersedia secara bebas yang juga sumber terbuka boleh digunakan untuk tujuan komersial . Ini bermakna Dolly 2.0 boleh digunakan untuk membina aplikasi komersial tanpa membayar akses API atau berkongsi data dengan pihak ketiga.

- Pautan projek: https://huggingface.co/databricks/dolly-v2-12b
- Dataset: https://github.com/databrickslabs/dolly/tree/master/data
Menurut Ketua Pegawai Eksekutif Databricks Ali Ghodsi, sementara terdapat model besar lain yang boleh digunakan untuk tujuan komersial, "mereka tidak bercakap dengan anda seperti Dolly 2.0 Dan berdasarkan model Dolly 2.0, pengguna boleh mengubah suai dan menambah baik data latihan , kerana ia tersedia secara percuma di bawah lesen sumber terbuka. Jadi anda boleh membuat Dolly versi anda sendiri.
Databricks turut mengeluarkan set data yang Dolly 2.0 telah diperhalusi, dipanggil databricks-dolly-15k. Ini adalah korpus lebih daripada 15,000 rekod yang dijana oleh beribu-ribu pekerja Databricks Databricks memanggilnya "sumber terbuka pertama, korpus arahan yang dijana manusia, yang direka khusus untuk membolehkan bahasa besar menunjukkan interaktiviti ajaib ChatGPT" ”
Bagaimana Dolly 2.0 dilahirkanDalam dua bulan lalu, industri dan akademia telah mengikuti OpenAI dan mencadangkan gelombang alat seperti ChatGPT yang mengikut arahan , versi ini dianggap sumber terbuka oleh banyak definisi (atau menawarkan beberapa tahap keterbukaan atau akses terhad). Antaranya, LLaMA Meta telah menarik perhatian paling ramai, yang telah membawa kepada sejumlah besar model yang dipertingkatkan lagi, seperti Alpaca, Koala, Vicuna dan Databricks' Dolly 1.0.
Tetapi sebaliknya, kebanyakan model "terbuka" ini berada di bawah "sekatan industri" kerana mereka dilatih mengenai set data dengan istilah yang direka untuk mengehadkan penggunaan komersial - Contohnya, 52,000 set data soal jawab daripada projek StanfordAlpaca telah dilatih mengenai output OpenAI's ChatGPT. Dan syarat penggunaan OpenAI termasuk peraturan bahawa anda tidak boleh menggunakan perkhidmatan OpenAI untuk bersaing dengan mereka.
Databricks telah memikirkan cara untuk menyelesaikan masalah ini: Dolly 2.0 yang baru dicadangkan ialah model bahasa 12 bilion parameter berdasarkan siri model EleutherAI pythia sumber terbuka, khususnya menyasarkan arahan sumber terbuka kecil rekod corpora Ditala halus (databricks-dolly-15k), set data ini dijana oleh pekerja Databricks dan dilesenkan di bawah syarat yang membenarkan penggunaan, pengubahsuaian dan sambungan untuk sebarang tujuan, termasuk aplikasi akademik atau komersial.
Setakat ini, model yang dilatih mengenai keluaran ChatGPT berada dalam kawasan kelabu yang sah. "Seluruh komuniti telah berjingkat-jingkat mengelilingi masalah ini, dan semua orang mengeluarkan model ini, tetapi tiada satu pun daripada mereka tersedia secara komersial," kata Ghodsi. "Itulah sebabnya kami sangat teruja."
"Semua orang mahu menjadi lebih besar, tetapi kami sebenarnya berminat dengan perkara yang lebih kecil," kata Ghodsi mengenai Dolly berskala kecil. "Kedua, kami telah meneliti semua jawapan dan ia adalah berkualiti tinggi." kecerdasan buatan kepada Orang ramai menyertai dan menghasilkan alternatif lain. Dia menjelaskan bahawa sekatan ke atas penggunaan komersial merupakan halangan besar untuk diatasi: "Kami teruja sekarang kerana kami akhirnya menemui jalan untuk mengatasinya. Saya jamin anda akan melihat orang menggunakan 15,000 masalah ini ke dunia nyata. Setiap model di sana ialah, mereka akan melihat berapa banyak model ini tiba-tiba menjadi sedikit ajaib dan anda boleh berinteraksi dengan mereka."
Set Data Gosok Tangan
Untuk memuat turun pemberat bagi model Dolly 2.0, cuma lawati halaman Muka Peluk Databricks dan lawati repo Dolly databricks-labs untuk memuat turun set databricks-dolly-15k .
Set data "databricks-dolly-15k" mengandungi 15,000 pasangan gesaan/balas berkualiti tinggi yang dihasilkan manusia, oleh lebih 5,000 pekerja Databricks pada 2023 Ditulis pada bulan Mac dan April, direka khusus untuk menyediakan arahan untuk menala model bahasa besar. Rakaman latihan ini adalah semula jadi, ekspresif dan direka bentuk untuk mewakili pelbagai tingkah laku, daripada sumbang saran dan penjanaan kandungan kepada pengekstrakan dan rumusan maklumat.
Mengikut syarat lesen set data ini (Creative Commons Attribution-ShareAlike 3.0 Unported License), sesiapa sahaja boleh menggunakan, mengubah suai atau melanjutkan set data ini untuk sebarang tujuan, termasuk aplikasi komersial.
Pada masa ini, set data ini ialah set data arahan sumber terbuka pertama yang dijana oleh manusia .
Mengapa mencipta set data sedemikian? Pasukan itu juga menjelaskan mengapa dalam catatan blog.
Langkah penting dalam mencipta Dolly 1.0, atau mana-mana arahan yang mengikuti LLM, ialah melatih model pada set data pasangan arahan dan balasan. Dolly 1.0 berharga $30 untuk melatih dan menggunakan set data yang dicipta oleh pasukan Alpaca di Stanford University menggunakan API OpenAI.
Selepas Dolly 1.0 dikeluarkan, ramai yang meminta untuk mencubanya, dan beberapa pengguna juga ingin menggunakan model ini secara komersial.
Tetapi set data latihan mengandungi output ChatGPT, dan seperti yang ditunjukkan oleh pasukan Stanford, syarat perkhidmatan cuba menghalang sesiapa daripada mencipta model yang bersaing dengan OpenAI.
Sebelum ini, semua model pematuhan arahan yang terkenal (Alpaca, Koala, GPT4All, Vicuna) tertakluk pada sekatan ini: penggunaan komersial adalah dilarang. Untuk menyelesaikan masalah ini, pasukan Dolly mula mencari cara untuk mencipta set data baharu tanpa sekatan ke atas penggunaan komersial.
Secara khusus, pasukan mengetahui daripada kertas penyelidikan yang diterbitkan oleh OpenAI bahawa model InstructGPT asal telah dilatih pada set data yang terdiri daripada 13,000 demonstrasi tingkah laku mengikut arahan. Diilhamkan oleh ini, mereka berusaha untuk melihat sama ada mereka boleh mencapai keputusan yang sama, diketuai oleh pekerja Databricks.
Ternyata, menghasilkan 13,000 soalan dan jawapan adalah lebih sukar daripada yang dibayangkan. Kerana setiap jawapan mestilah asli dan tidak boleh disalin daripada ChatGPT atau mana-mana di web, jika tidak, ia akan "mencemarkan" set data. Tetapi Databricks mempunyai lebih daripada 5,000 pekerja, dan mereka sangat berminat dengan LLM. Oleh itu, pasukan itu menjalankan percubaan penyumberan ramai yang mencipta set data berkualiti tinggi daripada apa yang dibuat oleh 40 anotasi untuk OpenAI.
Sudah tentu, kerja ini memakan masa dan intensif tenaga kerja untuk memotivasikan semua orang, pasukan telah mengadakan pertandingan, dan 20 pencatat teratas akan menerima hadiah kejutan. Pada masa yang sama, mereka turut menyenaraikan 7 tugasan yang sangat khusus:
- Soalan Jawab Terbuka: Contohnya, "Mengapa orang suka filem komedi atau "Apakah ibu negara Perancis?" bantuan diperlukan Pengetahuan tentang seluruh dunia;
- Soalan dan jawapan tertutup: Soalan ini boleh dijawab menggunakan hanya satu perenggan maklumat daripada rujukan. Sebagai contoh, memandangkan perenggan Wikipedia tentang atom, seseorang mungkin bertanya: "Apakah nisbah proton kepada neutron dalam nukleus?"; daripada perenggan, seperti berat atau ukuran;
- meringkaskan maklumat di Wikipedia: Untuk ini, annotator disediakan dengan petikan dari Wikipedia dan diminta untuk menyaringnya menjadi ringkasan ringkas; 🎜>
- Sumbangsaran: Tugas ini memerlukan idea terbuka , dan menyenaraikan kemungkinan pilihan yang berkaitan. Contohnya "Apakah aktiviti yang menyeronokkan yang boleh saya lakukan bersama rakan saya pada hujung minggu ini?";
- Kategori: Dalam tugasan ini, pencatat diminta membuat pertimbangan tentang keahlian kategori (mis., sama ada item dalam senarai adalah haiwan, mineral, atau sayur-sayuran), atau menilai atribut petikan pendek, seperti sentimen ulasan filem; puisi atau Surat cinta dan banyak lagi.
- Berikut ialah beberapa contoh:
Pada mulanya, pasukan itu ragu-ragu tentang mencapai 10,000 keputusan. Tetapi dengan permainan papan pendahulu setiap malam, ia berjaya mencapai 15,000 keputusan dalam satu minggu.


Selepas set data dibuat dengan cepat, pasukan mula mempertimbangkan aplikasi komersial.
Mereka mahu membuat model sumber terbuka yang boleh digunakan secara komersial. Walaupun databricks-dolly-15k jauh lebih kecil daripada Alpaca (set data yang Dolly 1.0 dilatih), model Dolly 2.0 berdasarkan EleutherAI pythia-12b mempamerkan arahan yang berkualiti tinggi mengikut tingkah laku.
Jika difikirkan semula, ini tidak menghairankan. Lagipun, banyak set data penalaan arahan yang dikeluarkan dalam beberapa bulan kebelakangan ini mengandungi data sintetik, yang selalunya mengandungi halusinasi dan ralat fakta.
databricks-dolly-15k, sebaliknya, dijana oleh profesional, berkualiti tinggi dan mengandungi jawapan berbentuk panjang untuk kebanyakan tugas.
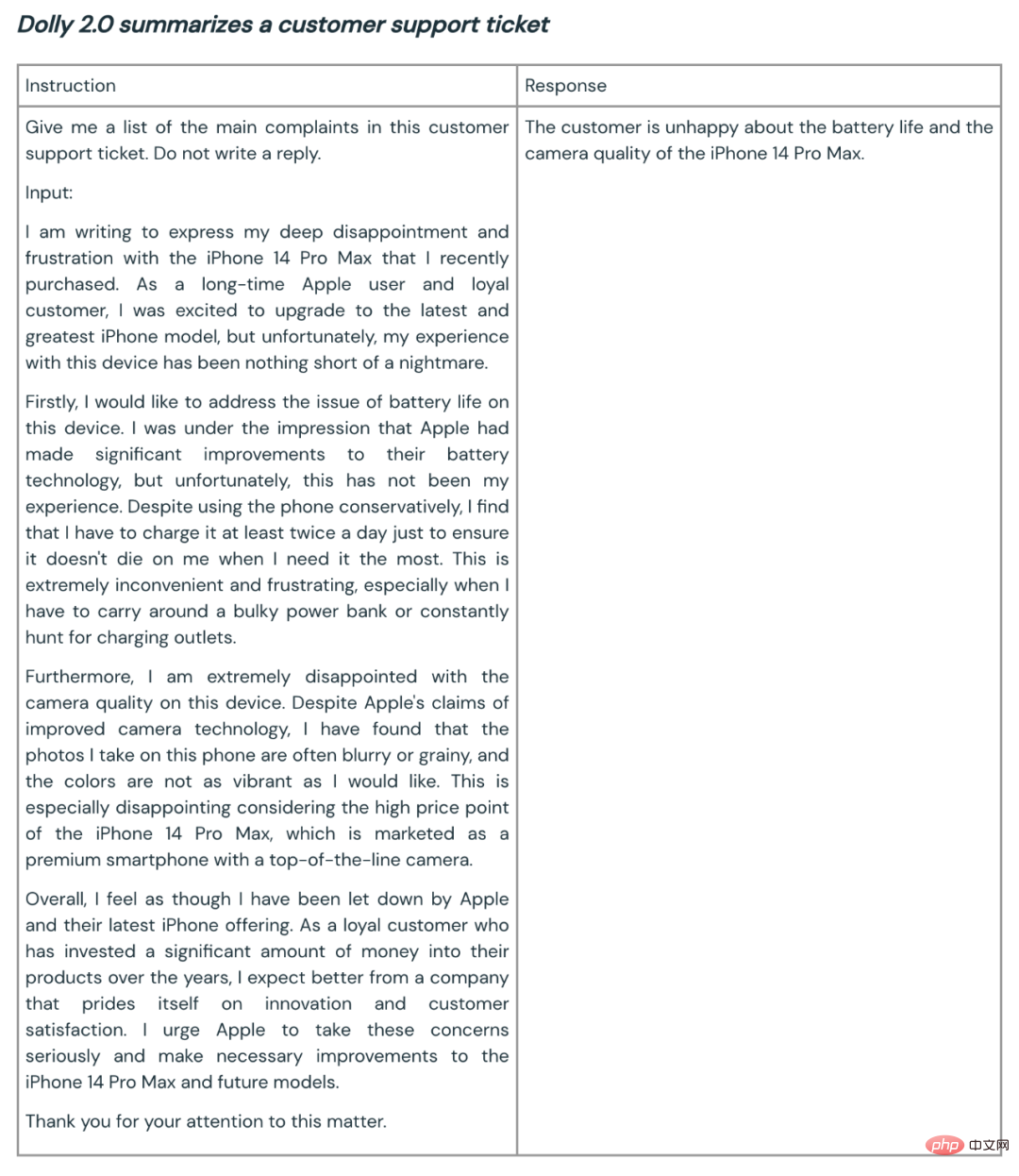
Berikut ialah beberapa contoh Dolly 2.0 yang digunakan untuk ringkasan dan penjanaan kandungan:
 Berdasarkan maklum balas awal pelanggan, pasukan Dolly berkata keupayaan seperti ini boleh digunakan secara meluas di seluruh perusahaan. Kerana banyak syarikat ingin mempunyai model mereka sendiri untuk mencipta model berkualiti tinggi untuk aplikasi domain khusus mereka sendiri, dan bukannya menyerahkan data sensitif mereka kepada pihak ketiga.
Berdasarkan maklum balas awal pelanggan, pasukan Dolly berkata keupayaan seperti ini boleh digunakan secara meluas di seluruh perusahaan. Kerana banyak syarikat ingin mempunyai model mereka sendiri untuk mencipta model berkualiti tinggi untuk aplikasi domain khusus mereka sendiri, dan bukannya menyerahkan data sensitif mereka kepada pihak ketiga.

Atas ialah kandungan terperinci Dolly 2.0, model besar ChatGPT sumber terbuka pertama di dunia, boleh diubah suai sesuka hati untuk kegunaan komersil. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI