
Rumah >Peranti teknologi >AI >Masalah dengan kebolehtafsiran rangkaian saraf: menyemak semula kritikan NN dari tiga puluh tahun yang lalu
Masalah dengan kebolehtafsiran rangkaian saraf: menyemak semula kritikan NN dari tiga puluh tahun yang lalu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-21 14:19:091382semak imbas
1 AI Boleh Dijelaskan (XAI)
Dengan rangkaian neural dalam (DNN) digunakan untuk memutuskan kelulusan pinjaman, permohonan kerja, kelulusan jaminan mahkamah, dsb., yang rapat berkaitan dengan kepentingan orang Atau beberapa keputusan hidup atau mati (seperti berhenti mengejut di lebuh raya), adalah penting untuk menjelaskan keputusan ini, dan bukannya hanya menghasilkan skor ramalan.
Penyelidikan dalam kecerdasan buatan yang boleh dijelaskan (XAI) baru-baru ini memfokuskan pada konsep contoh kontrafaktual. Ideanya mudah: mula-mula buat beberapa contoh kontrafaktual dengan output yang dijangkakan dan masukkannya ke dalam rangkaian asal kemudian, baca unit lapisan tersembunyi untuk menerangkan mengapa rangkaian menghasilkan beberapa output lain. Secara lebih formal:
"Pecahan p dikembalikan kerana pembolehubah V mempunyai nilai (v1, v2, ...) yang dikaitkan dengannya. Jika V mempunyai nilai (v′1 , v ′2, ...), dan semua pembolehubah lain kekal tidak berubah, pecahan p' akan dikembalikan ”
Berikut ialah contoh yang lebih khusus: <.>
"Anda telah ditolak pinjaman kerana pendapatan tahunan anda ialah £30,000. Jika pendapatan anda ialah £45,000, anda akan mendapat pinjaman." kertas kerja oleh Browne dan Swift [1] (selepas ini B&W) baru-baru ini menunjukkan bahawa contoh kontrafaktual hanyalah contoh lawan yang lebih bermakna yang dihasilkan dengan melakukan gangguan kecil dan tidak dapat diperhatikan pada input , mengakibatkan rangkaian salah mengklasifikasikannya dengan keyakinan yang tinggi.
Selain itu, contoh kontrafaktual "menerangkan" ciri-ciri yang sepatutnya untuk mendapatkan ramalan yang betul, tetapi "jangan buka kotak hitam" iaitu, ia tidak menerangkan cara algoritma berfungsi daripada. Artikel itu seterusnya berhujah bahawa contoh kontrafaktual tidak memberikan penyelesaian untuk kebolehtafsiran dan bahawa "tanpa semantik tidak ada penjelasan".
Malah, artikel itu malah membuat cadangan yang lebih kuat:
1) Kita sama ada mencari jalan untuk mengekstrak apa yang diandaikan wujud dalam Semantik dalam lapisan tersembunyi rangkaian, sama ada
2) Akui kami gagal.
Walid S. Saba sendiri pesimis terhadap (1).
2 Fodor dan "Hantu" Pylyshyn
Walaupun orang ramai bersetuju sepenuhnya dengan pandangan B&W bahawa "tanpa semantik, tiada penjelasan", tetapi Harapan untuk mentafsir semantik perwakilan lapisan tersembunyi dalam rangkaian saraf dalam untuk menghasilkan penjelasan yang memuaskan untuk sistem pembelajaran mendalam tidak dapat direalisasikan, penulis percaya, atas sebab-sebab yang digariskan lebih daripada tiga puluh tahun yang lalu oleh Fodor dan Pylyshyn [2] .
Walid S. Saba kemudian berhujah: Sebelum menjelaskan di mana masalahnya, kita perlu ambil perhatian bahawa model sambungan semata-mata (seperti rangkaian saraf) tidak boleh mengambil kira kesisteman dan Kekomposisian dimodelkan kerana ia tidak mengenali struktur simbolik dengan sintaks terbitan dan semantik yang sepadan.
Oleh itu, perwakilan dalam rangkaian saraf bukanlah benar-benar "simbol" yang sepadan dengan apa-apa yang boleh ditafsir - tetapi nilai berangka teragih, berkorelasi dan berterusan, itu sendiri tidak bermakna apa-apa yang boleh dijelaskan secara konsep. .
Dalam istilah yang lebih mudah, perwakilan sub-simbolik dalam rangkaian saraf tidak sendiri merujuk kepada apa-apa yang boleh difahami oleh manusia secara konsep (unit tersembunyi itu sendiri tidak boleh mewakili sebarang objek makna metafizik). Sebaliknya, ia adalah satu set unit tersembunyi yang bersama-sama biasanya mewakili beberapa ciri yang menonjol (cth., misai kucing).
Tetapi inilah sebabnya rangkaian saraf tidak dapat mencapai kebolehtafsiran, iaitu kerana gabungan beberapa ciri tersembunyi tidak dapat ditentukan - setelah gabungan selesai (oleh beberapa fungsi gabungan linear), satu unit hilang (kami akan tunjukkan di bawah).
3 Kebolehtafsiran ialah "penaakulan terbalik", DNN tidak boleh melakukan penaakulan terbalik
Penulis membincangkan mengapa Fodor dan Pylyshyn mencapai kesimpulan bahawa NN tidak boleh memodelkan inferens sistematik (dan oleh itu boleh ditafsir) [2].
Dalam sistem simbolik, terdapat fungsi semantik gubahan yang ditakrifkan dengan baik yang mengira makna kata majmuk berdasarkan makna konstituennya. Tetapi gabungan ini boleh diterbalikkan -
Iaitu, seseorang sentiasa boleh mendapatkan komponen (input) yang menghasilkan output itu, dan tepat kerana dalam sistem simbolik seseorang boleh Mengakses "struktur sintaksis" yang mengandungi peta cara komponen dipasang. Semua ini tidak benar dalam NN. Sebaik sahaja vektor (tensor) digabungkan dalam NN, penguraian mereka tidak dapat ditentukan (bilangan cara vektor (termasuk skalar) boleh diuraikan adalah tidak terhingga!)
Untuk menggambarkan mengapa ini berlaku. masalah Pada intinya, mari kita pertimbangkan cadangan B&W untuk mengekstrak semantik dalam DNN untuk mencapai kebolehtafsiran. Syor B&W adalah untuk mengikuti garis panduan berikut:
Imej input dilabelkan "Seni Bina" kerana neuron tersembunyi 41435 yang biasanya mengaktifkan hubcap mempunyai nilai pengaktifan 0.32. Jika nilai pengaktifan neuron tersembunyi 41435 ialah 0.87, imej input akan dilabelkan "kereta".
Untuk memahami mengapa ini tidak membawa kepada kebolehtafsiran, cuma ambil perhatian bahawa memerlukan pengaktifan 0.87 untuk neuron 41435 tidak mencukupi. Untuk kesederhanaan, anggap bahawa neuron 41435 hanya mempunyai dua input, x1 dan x2. Apa yang kita ada sekarang ditunjukkan dalam Rajah 1 di bawah:
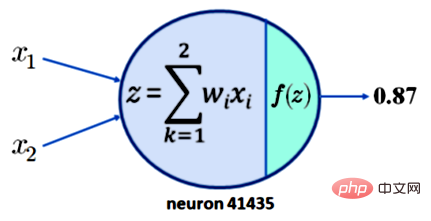
Kapsyen: Satu neuron dengan dua input mempunyai output 0.87
Sekarang dengan mengandaikan bahawa fungsi pengaktifan kami f ialah fungsi ReLU yang popular, ia boleh menghasilkan output z = 0.87. Ini bermakna untuk nilai x1, x2, w1 dan w2 yang ditunjukkan dalam jadual di bawah, output sebanyak 0.87 diperolehi.
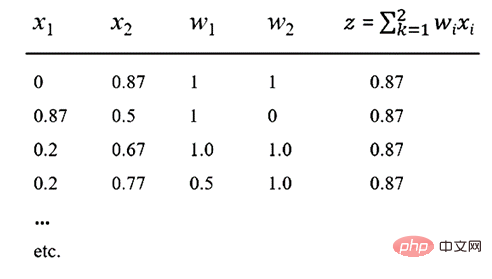
Nota Jadual: Pelbagai kaedah input boleh menghasilkan nilai 0.87
Melihat jadual di atas, adalah mudah untuk melihat bahawa terdapat bilangan kombinasi linear yang tidak terhingga bagi x1, x2, w1 dan w2 yang akan menghasilkan output 0.87. Perkara penting di sini ialah komposisi dalam NN tidak dapat dipulihkan, jadi semantik yang bermakna tidak boleh ditangkap daripada mana-mana neuron atau mana-mana koleksi neuron.
Selaras dengan slogan B&W "Tiada semantik, tiada penjelasan", kami menyatakan bahawa tiada penjelasan boleh diperolehi daripada NN. Ringkasnya, tidak ada semantik tanpa komposisi, tidak ada penjelasan tanpa semantik, dan DNN tidak boleh memodelkan komposisi. Ini boleh diformalkan seperti berikut:
1 Tanpa semantik, tiada penjelasan[1] 2. Tanpa komposisi boleh balik, tiada semantik[2]
3. Gabungan dalam DNN tidak boleh diterbalikkan[2]
=> DNN tidak boleh dijelaskan (tanpa XAI)
Tamat .
Dengan cara ini, fakta bahawa komposisi dalam DNN tidak dapat dipulihkan mempunyai akibat selain tidak dapat menghasilkan ramalan yang boleh ditafsir, terutamanya apabila penaakulan peringkat lebih tinggi diperlukan Medan seperti pemahaman bahasa semula jadi ( NLU).
Khususnya, sistem sedemikian benar-benar tidak dapat menjelaskan cara kanak-kanak boleh belajar cara mentafsir ayat yang tidak terhingga hanya daripada templat seperti (
Oleh kerana sistem sedemikian tidak mempunyai "memori" dan komposisinya tidak boleh diterbalikkan, secara teorinya mereka memerlukan banyak contoh untuk mempelajari struktur mudah ini. [Nota editor: Perkara ini adalah tepatnya soalan Chomsky tentang linguistik struktur, dan dengan itu memulakan tatabahasa generatif transformasi yang telah mempengaruhi linguistik selama lebih daripada setengah abad. 】
Akhirnya, penulis menekankan bahawa lebih daripada tiga puluh tahun yang lalu, Fodor dan Pylyshyn [2] menimbulkan kritikan terhadap NN sebagai seni bina kognitif - mereka menunjukkan mengapa NN tidak boleh membina model yang sistematik, produktiviti dan komposisi yang perlu untuk bercakap tentang apa-apa "semantik" - dan kritikan yang menarik ini tidak pernah dijawab dengan sempurna.
Memandangkan keperluan untuk menyelesaikan masalah kebolehjelasan dalam AI menjadi kritikal, kita mesti menyemak semula kertas klasik itu kerana ia menunjukkan keperluan untuk menyamakan pengecaman corak statistik dengan kecerdasan buatan Had kemajuan.
Atas ialah kandungan terperinci Masalah dengan kebolehtafsiran rangkaian saraf: menyemak semula kritikan NN dari tiga puluh tahun yang lalu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI