
Rumah >Peranti teknologi >AI >Richard Sutton secara terang-terangan menyatakan bahawa perambatan balik konvolusi telah ketinggalan, dan penemuan AI memerlukan idea baharu: perambatan balik berterusan
Richard Sutton secara terang-terangan menyatakan bahawa perambatan balik konvolusi telah ketinggalan, dan penemuan AI memerlukan idea baharu: perambatan balik berterusan

- 王林ke hadapan
- 2023-04-19 15:37:591328semak imbas
"Kehilangan Keplastikan" ialah salah satu kelemahan rangkaian saraf dalam yang paling kerap dikritik, yang juga merupakan salah satu sebab mengapa sistem AI berdasarkan pembelajaran mendalam dianggap tidak dapat meneruskan pembelajaran.
Bagi otak manusia, "plastisitas" merujuk kepada keupayaan untuk menjana neuron baru dan hubungan baru antara neuron, yang merupakan asas penting untuk pembelajaran berterusan. Apabila kita meningkat usia, keplastikan otak secara beransur-ansur berkurangan dengan mengorbankan penyatuan apa yang telah kita pelajari. Rangkaian saraf adalah serupa.
Contoh yang jelas ialah latihan permulaan hangat pada tahun 2020 telah terbukti: hanya dengan membuang kandungan yang dipelajari pada mulanya dan mempelajari keseluruhan data dalam satu masa Hanya melalui latihan intensif kita boleh mencapai pembelajaran yang lebih baik keputusan.
Dalam pembelajaran pengukuhan mendalam (DRL), sistem AI selalunya terpaksa "melupakan" semua kandungan yang dipelajari sebelum ini oleh rangkaian saraf, dan hanya menyimpan sebahagian daripada kandungan ke penimbal main balik, dan kemudian dari Mencapai pembelajaran berterusan dari awal. Cara menetapkan semula rangkaian ini juga dianggap membuktikan bahawa pembelajaran mendalam tidak boleh terus belajar.
Jadi, bagaimanakah kita boleh memastikan sistem pembelajaran mudah dibentuk?
Baru-baru ini, Richard Sutton, bapa pembelajaran pengukuhan, memberikan ucapan bertajuk "Mengekalkan Keplastikan dalam Pembelajaran Berterusan Dalam" pada persidangan CoLLAs 2022, dan mencadangkan perkara yang difikirkannya boleh menyelesaikan masalah ini . Jawapan: Algoritma Backprop Berterusan (Continual Backprop).
Richard Sutton mula-mula membuktikan kewujudan kehilangan keplastikan dari perspektif set data, kemudian menganalisis punca kehilangan keplastikan dari dalam rangkaian saraf, dan akhirnya mencadangkan perambatan balik berterusan algoritma sebagai Cara untuk menangani kehilangan keplastikan: Memulakan semula subset kecil neuron dengan utiliti yang rendah Penyerapan kepelbagaian berterusan ini boleh mengekalkan keplastikan rangkaian dalam selama-lamanya.
Berikut ialah teks penuh ucapan, dan semakan teknologi AI telah disusun tanpa mengubah maksud asal.
1 Kewujudan sebenar kehilangan keplastikan
Bolehkah pembelajaran mendalam benar-benar menyelesaikan masalah pembelajaran berterusan?
Jawapannya tidak, terutamanya untuk tiga perkara berikut:
- "Tidak boleh diselesaikan" bermaksud seperti Rangkaian linear tidak mendalam, kelajuan pembelajaran akhirnya akan menjadi sangat perlahan; Caching main semula itu sendiri adalah cara yang melampau untuk mengakui bahawa pembelajaran mendalam tidak boleh dilaksanakan.
- Oleh itu, kita mesti mencari algoritma yang lebih baik yang sesuai untuk model pembelajaran baharu ini dan menyingkirkan batasan pembelajaran sekali sahaja.
Pertama, kami menggunakan set data ImageNet dan MNIST untuk tugasan pengelasan, mencapai ramalan regresi dan secara langsung menguji kesan pembelajaran berterusan, membuktikan kewujudan kehilangan keplastikan dalam pembelajaran diselia. Ujian Set Data ImageNet
ImageNet ialah set data yang mengandungi berjuta-juta imej yang ditandai dengan kata nama. Ia mempunyai 1000 kategori dengan 700 atau lebih imej bagi setiap kategori dan digunakan secara meluas untuk pembelajaran kategori dan ramalan kategori.
Di bawah ialah foto jerung, dikurangkan sampel kepada saiz 32*32. Tujuan eksperimen ini adalah untuk mencari perubahan minimum daripada amalan pembelajaran mendalam. Kami membahagikan 700 imej setiap kategori kepada 600 sampel latihan dan 100 sampel ujian, dan kemudian membahagikan 1000 kategori kepada dua kumpulan untuk menjana urutan tugas klasifikasi binari dengan panjang 500. Semua set data secara rawak Kocok pesanan. Selepas latihan untuk setiap tugasan, kami menilai ketepatan model pada sampel ujian, menjalankannya secara bebas 30 kali dan mengambil purata sebelum memasuki tugas klasifikasi binari seterusnya.
500 tugas klasifikasi akan berkongsi rangkaian yang sama Untuk menghapuskan kesan kerumitan, rangkaian kepala akan ditetapkan semula selepas penukaran tugas. Kami menggunakan rangkaian standard, iaitu, 3 lapisan lilitan + 3 lapisan bersambung sepenuhnya, tetapi lapisan output mungkin agak kecil untuk dataset ImageNet kerana hanya dua kategori digunakan dalam satu tugas. Untuk setiap tugas, setiap 100 contoh diambil sebagai satu kelompok, dengan jumlah 12 kelompok dan 250 zaman latihan. Hanya satu permulaan dilakukan sebelum memulakan tugas pertama, menggunakan taburan Kaiming untuk memulakan pemberat. Kaedah penurunan kecerunan stokastik berasaskan momentum digunakan untuk kehilangan entropi silang, dan fungsi pengaktifan ReLU digunakan.
Ini membawa kepada dua soalan:
1. Bagaimanakah prestasi akan berkembang dalam urutan tugasan?
2. Adakah misi pertama awal lebih baik? Atau adakah tugasan seterusnya mendapat manfaat daripada pengalaman tugasan sebelumnya?
Jawapan diberikan dalam rajah di bawah Prestasi pembelajaran berterusan ditentukan secara menyeluruh oleh saiz langkah latihan dan perambatan belakang.
Oleh kerana ia adalah masalah pengelasan binari, kebarangkalian peluang ialah 50%, kawasan berlorek mewakili sisihan piawai, dan perbezaan ini tidak ketara. Penanda aras linear menggunakan lapisan linear untuk memproses secara langsung nilai piksel, yang tidak berkesan seperti kaedah pembelajaran mendalam Perbezaan ini adalah ketara.
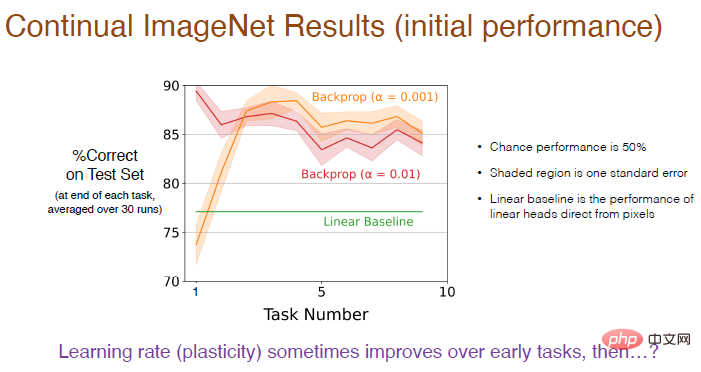
Ilustrasi: Menggunakan kadar pembelajaran yang lebih kecil (α=0.001) ketepatan akan lebih tinggi, dalam 5 tugasan pertama Prestasi bertambah baik secara beransur-ansur tetapi kemudian cenderung merosot dalam jangka masa panjang.
Kami kemudiannya menambah bilangan tugasan kepada 2000 dan seterusnya menganalisis kesan kadar pembelajaran terhadap kesan pembelajaran berterusan Ketepatan dikira secara purata setiap 50 tugasan. Hasilnya ditunjukkan di bawah.
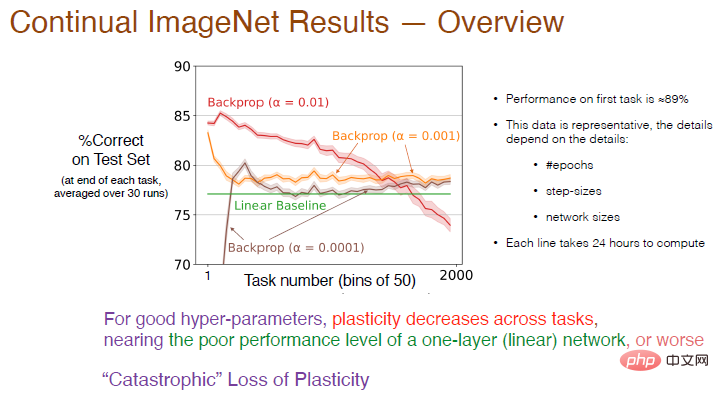
Legenda: Lengkung merah dengan α=0.01 mempunyai ketepatan kira-kira 89% pada tugasan pertama sekali adalah Melebihi 50, ketepatan berkurangan Apabila bilangan tugasan semakin meningkat, keplastikan secara beransur-ansur hilang, dan ketepatan akhir adalah lebih rendah daripada garis dasar linear. Apabila α=0.001, kelajuan pembelajaran menjadi perlahan, keplastikan juga berkurangan dengan mendadak, dan ketepatan hanya lebih tinggi sedikit daripada rangkaian linear.
Oleh itu, untuk hiperparameter yang baik, keplastikan antara tugas akan mereput dan ketepatan akan lebih rendah daripada menggunakan hanya satu lapisan rangkaian saraf Lengkung merah menunjukkan hampir Ia adalah “. kehilangan keplastikan yang dahsyat."
Hasil latihan juga bergantung pada parameter seperti bilangan lelaran, bilangan langkah dan saiz rangkaian Masa latihan untuk setiap lengkung dalam rajah ialah 24 jam pada berbilang pemproses. Apabila melakukan sistem Ia mungkin tidak praktikal dalam eksperimen seksual, jadi kami seterusnya memilih set data MNIST untuk ujian.
Ujian set data MNIST
Set data MNIST mengandungi sejumlah 60,000 imej digit tulisan tangan, dengan 10 kategori dari 0 hingga 9, dan merupakan skala kelabu 28*28 gambar .
Goodfellow et al pernah mencipta tugasan ujian baharu dengan mengocok susunan atau menyusun piksel secara rawak. Imej di sudut kanan bawah ialah contoh imej tersusun kaedah Untuk menjana keseluruhan urutan tugasan, 6000 imej dipersembahkan secara rawak dalam setiap tugasan. Tiada kandungan tugasan ditambahkan di sini dan pemberat rangkaian hanya dimulakan sekali sebelum tugasan pertama. Kami boleh menggunakan kehilangan silang entropi dalam talian untuk latihan, dan terus menggunakan indeks ketepatan untuk mengukur kesan pembelajaran berterusan.

Struktur rangkaian saraf ialah 4 lapisan bersambung sepenuhnya, bilangan neuron dalam 3 lapisan pertama ialah 2000, dan bilangan neuron dalam lapisan terakhir ialah 10. Memandangkan imej set data MNIST dipusatkan dan berskala, tiada operasi lilitan dilakukan. Semua tugas klasifikasi berkongsi rangkaian yang sama, menggunakan keturunan kecerunan stokastik tanpa momentum dan tetapan lain adalah sama seperti yang diuji pada dataset ImageNet.
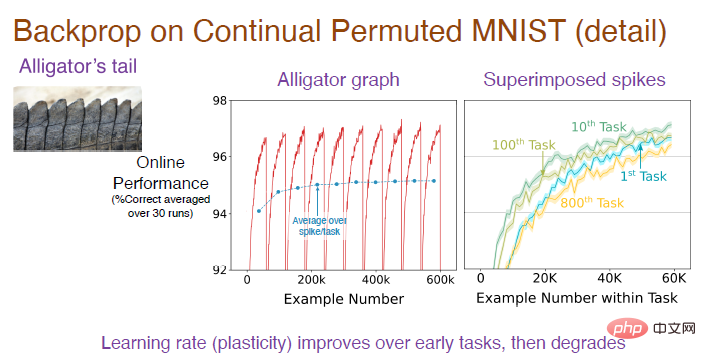
Nota Gambar: Gambar tengah adalah hasil daripada menjalankan urutan tugasan 30 kali secara bebas dan mengambil purata Setiap tugasan mempunyai 6000 sampel Memandangkan ia adalah tugasan pengelasan, tekaan rawak pada permulaan adalah tepat. Kadarnya ialah 10%. Selepas model mempelajari peraturan penyusunan imej, ketepatan ramalan akan meningkat secara beransur-ansur. Gambar di sebelah kanan menunjukkan kesan pembelajaran model pada setiap tugasan Ketepatan awal ialah 0. Dari masa ke masa, kesannya beransur-ansur menjadi lebih baik. Ketepatan pada tugasan ke-10 adalah lebih baik daripada tugasan pertama, tetapi ketepatan menurun pada tugasan ke-100, dan ketepatan pada tugasan ke-800 adalah lebih rendah daripada tugasan pertama.
Untuk memahami keseluruhan proses, kita perlu menumpukan pada menganalisis ketepatan bahagian cembung, dan kemudian puratanya untuk mendapatkan lengkung biru imej perantaraan. Ia dapat dilihat dengan jelas bahawa ketepatan akan meningkat secara beransur-ansur pada permulaan dan kemudian mendatar sehingga tugas ke-100. Jadi mengapa ketepatan jatuh mendadak pada tugasan ke-800?
Seterusnya, kami mencuba nilai langkah yang berbeza pada lebih banyak urutan tugasan untuk memerhatikan lagi kesan pembelajarannya. Keputusan adalah seperti yang ditunjukkan di bawah:
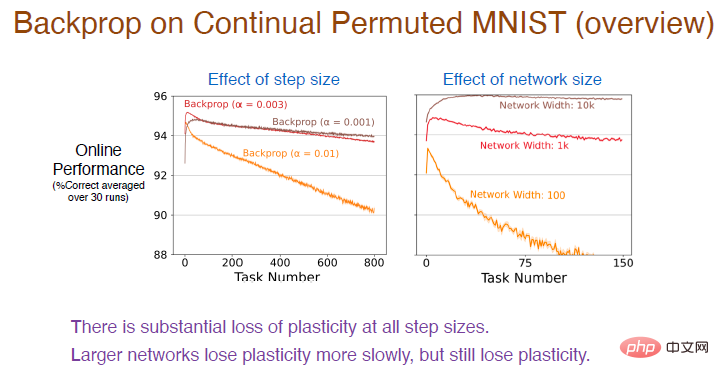
Legenda: Lengkung merah menggunakan nilai langkah yang sama seperti percubaan sebelumnya dan ketepatannya ialah memang menurun secara berterusan Kerugian keplastikan adalah agak besar.
Pada masa yang sama, semakin tinggi kadar pembelajaran, semakin cepat keplastikan berkurangan. Terdapat kehilangan keplastikan yang besar untuk semua nilai saiz langkah. Di samping itu, bilangan neuron dalam lapisan tersembunyi juga akan mempengaruhi ketepatan Bilangan neuron dalam lengkung coklat ialah 10,000 Oleh kerana keupayaan pemasangan rangkaian saraf yang dipertingkatkan, ketepatan akan menurun dengan sangat perlahan pada masa ini masih akan ada kehilangan keplastikan, tetapi lebih besar saiz rangkaian, lebih banyak ketepatan akan berkurangan.
Jadi dari dalam rangkaian saraf, kenapa ada kehilangan keplastikan?
Gambar di bawah menerangkan sebabnya. Boleh didapati bahawa bahagian neuron "mati" yang terlalu tinggi, berat neuron yang berlebihan, dan kehilangan kepelbagaian neuron adalah semua punca kehilangan keplastikan.
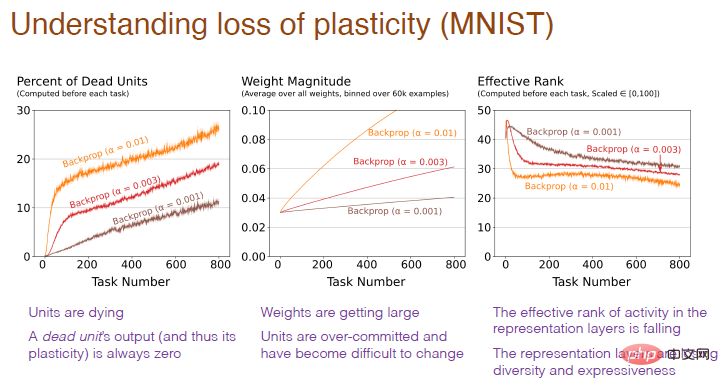
Nota ilustrasi: Paksi mendatar masih mewakili nombor tugas, dan paksi menegak gambar pertama mewakili " saraf kematian" Peratusan neuron, neuron "mati" ialah neuron yang output dan kecerunannya sentiasa 0 dan tidak lagi meramalkan keplastikan rangkaian. Paksi menegak graf kedua mewakili berat. Paksi menegak graf ketiga mewakili tahap berkesan bilangan neuron tersembunyi yang tinggal.
2 Keterbatasan kaedah sedia ada
Kami menganalisis sama ada kaedah pembelajaran mendalam sedia ada selain perambatan balik Akan membantu mengekalkan keplastikan.
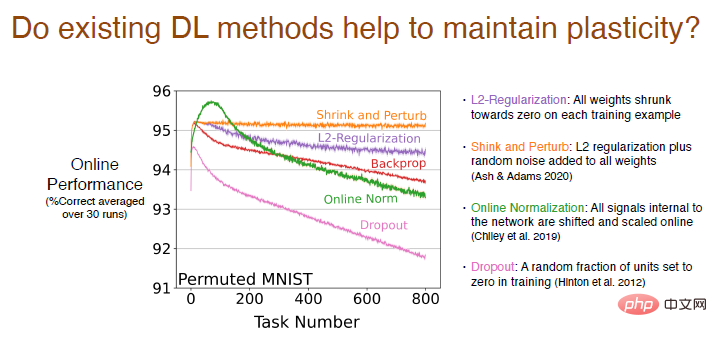
Keputusan menunjukkan bahawa kaedah regularisasi L2 akan mengurangkan kehilangan keplastikan, mengurangkan berat kepada 0 dalam proses, supaya ia boleh secara dinamik dilaraskan dan Kekal mudah dibentuk.
Kaedah pengecutan dan gangguan adalah serupa dengan penetapan L2, dan hingar rawak akan ditambah pada semua pemberat untuk meningkatkan kepelbagaian, tanpa kehilangan keplastikan.
Kami juga mencuba kaedah standardisasi dalam talian yang lain, yang berfungsi agak baik pada mulanya, tetapi kehilangan keplastikan adalah serius apabila pembelajaran diteruskan. Prestasi kaedah Keciciran adalah lebih teruk Kami secara rawak menetapkan sebahagian daripada neuron kepada 0 untuk latihan semula dan mendapati bahawa kehilangan keplastikan meningkat dengan mendadak.
Pelbagai kaedah juga akan memberi kesan kepada struktur dalaman rangkaian saraf. Menggunakan kaedah regularization akan meningkatkan peratusan neuron "mati", kerana dalam proses mengecilkan pemberat kepada 0, jika ia kekal pada 0, ia akan menyebabkan output menjadi 0 dan neuron akan "mati". Dan pengecutan dan gangguan menambah bunyi rawak pada pemberat, jadi tidak terdapat terlalu banyak neuron "mati". Kaedah normalisasi juga mempunyai banyak neuron "mati" dan nampaknya menuju ke arah yang salah, dan Dropout adalah serupa.
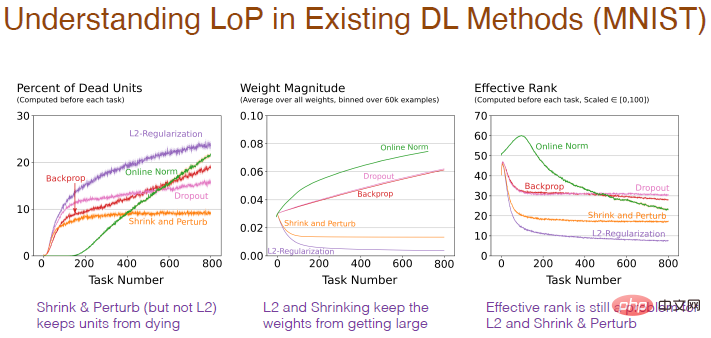
Hasil perubahan berat dengan bilangan tugas adalah lebih munasabah Menggunakan regularization akan memperoleh berat yang sangat kecil dan gangguan menambah bunyi berdasarkan regularization, dan penurunan berat badan agak lemah. Penyeragaman akan meningkatkan berat badan. Walau bagaimanapun, untuk regularisasi, penguncupan dan gangguan L2, tahap berkesan bilangan neuron tersembunyi adalah agak rendah, menunjukkan bahawa prestasinya dalam mengekalkan kepelbagaian adalah lemah, yang juga menjadi masalah.
Masalah Regresi Berubah Perlahan (SCR)
Semua idea dan algoritma kami diperolehi daripada eksperimen Masalah Regresi Berubah Perlahan, yang merupakan satu ideal baru soalan tertumpu kepada pembelajaran berterusan.
Dalam percubaan ini, matlamat kami adalah untuk mencapai fungsi objektif yang dibentuk oleh rangkaian neural satu lapisan dengan pemberat rawak dan 100 neuron ambang linear dalam lapisan tersembunyi.
Kami tidak melakukan pengelasan, kami hanya menjana nombor, jadi ini adalah masalah regresi. Setiap 10,000 langkah latihan, kami memilih 1 bit daripada 15 bit terakhir input untuk diselak, jadi ini adalah fungsi objektif yang berubah perlahan-lahan.
Penyelesaian kami ialah menggunakan struktur rangkaian yang sama, termasuk hanya satu lapisan tersembunyi neuron, sambil memastikan fungsi pengaktifan boleh dibezakan, tetapi kami akan mempunyai 5 lapisan neuron tersembunyi . Ini serupa dengan dalam RL Julat penerokaan oleh ejen jauh lebih kecil daripada persekitaran interaktif, jadi ia hanya boleh melakukan pemprosesan anggaran Apabila fungsi objektif berubah, cuba ubah nilai anggaran, yang akan menjadikannya lebih mudah untuk melakukan beberapa eksperimen sistematik.
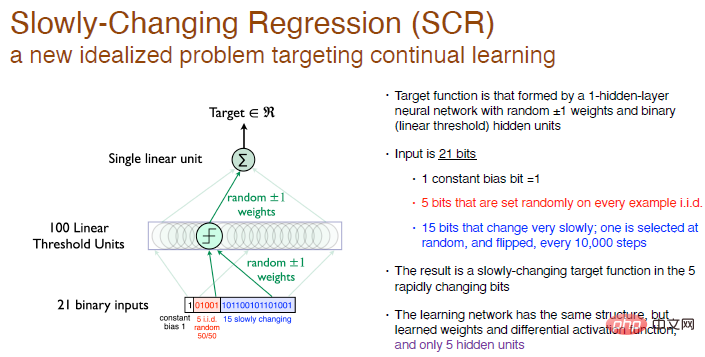
Legenda: Input ialah nombor binari rawak 21-bit, bit pertama ialah sisihan pemalar input dengan nilai 1 , dan 5 bit tengah adalah nombor rawak bebas dan teragih sama, 15 bit yang lain perlahan-lahan menukar pemalar, dan output adalah nombor nyata. Pemberat adalah rawak kepada 0, dan boleh dipilih secara rawak untuk menjadi +1 atau -1.
Kami terus mengkaji kesan perubahan nilai langkah dan fungsi pengaktifan pada kesan pembelajaran Contohnya, fungsi pengaktifan tanh, sigmoid dan relu digunakan di sini:
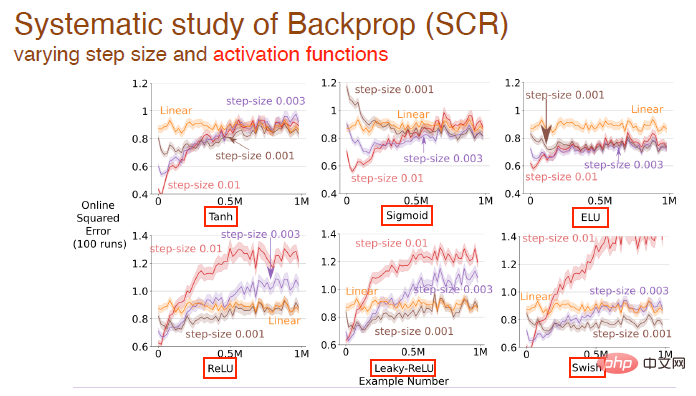
dan kesan bentuk fungsi pengaktifan pada kesan pembelajaran semua algoritma:
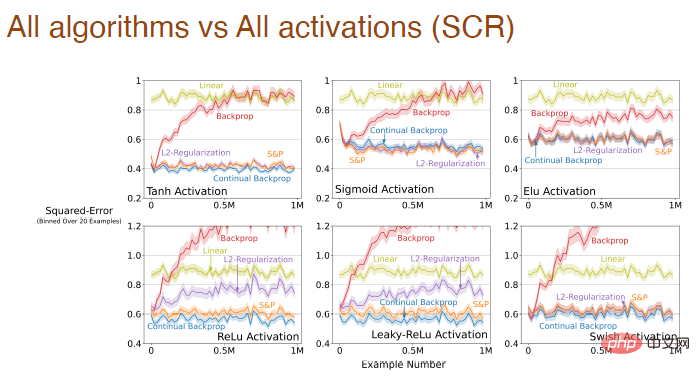
Apabila saiz langkah dan fungsi pengaktifan berubah secara serentak, kami juga membuat analisis sistematik tentang kesan perambatan balik Adam:
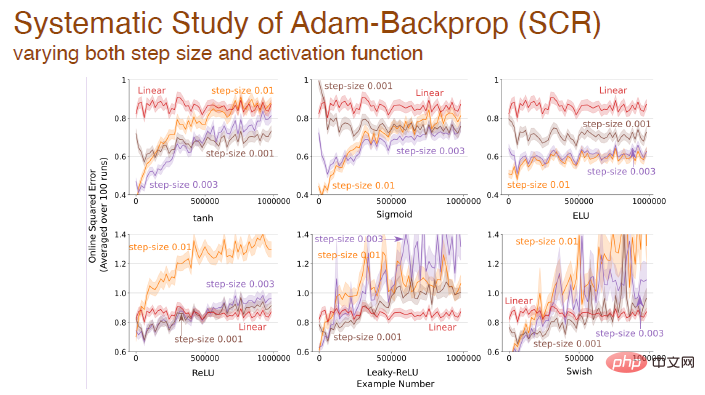
Akhir sekali : Selepas menggunakan fungsi pengaktifan yang berbeza, ralat berubah antara algoritma berbeza berdasarkan mekanisme Adam:
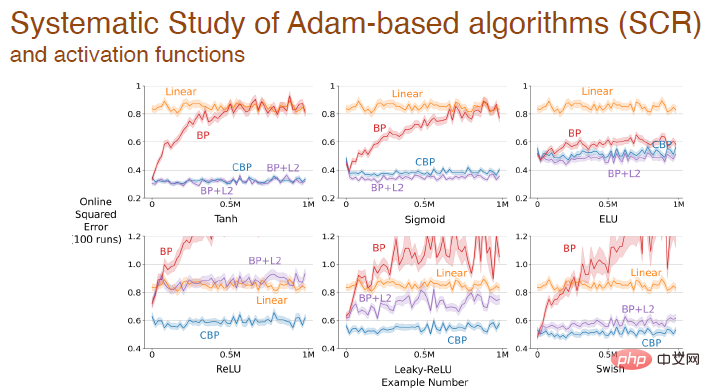
Keputusan percubaan di atas semuanya menunjukkan bahawa pembelajaran mendalam Kaedah ini tidak lagi sesuai untuk pembelajaran berterusan Apabila menghadapi masalah baru, proses pembelajaran akan menjadi sangat perlahan dan kelebihan kedalaman tidak akan dapat dilihat. Kaedah standard dalam pembelajaran mendalam hanya sesuai untuk pembelajaran sekali sahaja Kita perlu menambah baik kaedah pembelajaran mendalam untuk membolehkannya menggunakannya untuk pembelajaran berterusan.
3 Rambatan balik berterusan
Adakah algoritma perambatan balik konvolusi itu sendiri menjadi algoritma pembelajaran berterusan yang baik?
Kami fikir tidak.
Algoritma perambatan balik konvolusi terutamanya mengandungi dua aspek: pemulaan dengan pemberat rawak kecil dan keturunan kecerunan pada setiap langkah masa. Walaupun ia menjana nombor rawak kecil pada permulaan untuk memulakan pemberat, ia tidak berulang lagi. Sebaik-baiknya, kami mungkin mahukan beberapa algoritma pembelajaran yang boleh melakukan pengiraan yang serupa pada bila-bila masa.
Jadi bagaimana kita membuat algoritma perambatan balik konvolusi belajar secara berterusan?
Cara paling mudah ialah secara terpilih memulakan semula, contohnya selepas melakukan beberapa tugasan. Tetapi pada masa yang sama, memulakan semula keseluruhan rangkaian mungkin tidak munasabah dalam pembelajaran berterusan, kerana ini bermakna rangkaian saraf melupakan semua yang telah dipelajarinya. Oleh itu, lebih baik kita secara terpilih memulakan sebahagian daripada rangkaian saraf, seperti memulakan semula beberapa neuron "mati", atau menyusun rangkaian saraf mengikut utiliti dan memulakan semula neuron dengan utiliti yang lebih rendah.
Idea permulaan pemilihan rawak berkaitan dengan kaedah penjanaan dan ujian yang dicadangkan oleh Mahmood dan Sutton pada tahun 2012. Ia hanya perlu menjana beberapa neuron dan menguji kepraktisannya, dan algoritma perambatan balik berterusan dibina sebagai jambatan antara kedua-dua konsep ini. Kaedah penjanaan dan ujian mempunyai beberapa batasan, menggunakan hanya satu lapisan tersembunyi dan hanya satu neuron output, kami memanjangkannya kepada rangkaian berbilang lapisan yang boleh dioptimumkan dengan beberapa kaedah pembelajaran mendalam.
Kami mula-mula mempertimbangkan menyediakan rangkaian kepada berbilang lapisan dan bukannya satu output. Kerja sebelum ini menyebut konsep utiliti Memandangkan hanya terdapat satu pemberat, utiliti ini hanyalah konsep peringkat berat Walau bagaimanapun, kami mempunyai beberapa pemberat.
Idea lain ialah mempertimbangkan aktiviti ciri dan bukannya berat keluaran sahaja, supaya kita boleh mendarabkan jumlah pemberat dengan fungsi pengaktifan ciri purata , dengan itu Peruntukkan perkadaran yang berbeza. Kami berharap untuk mereka bentuk algoritma yang boleh terus belajar dan terus berjalan dengan pantas. Kami juga mempertimbangkan keplastikan ciri semasa mengira utiliti. Akhir sekali, purata sumbangan ciri dipindahkan ke bias keluaran, mengurangkan kesan pemadaman ciri.
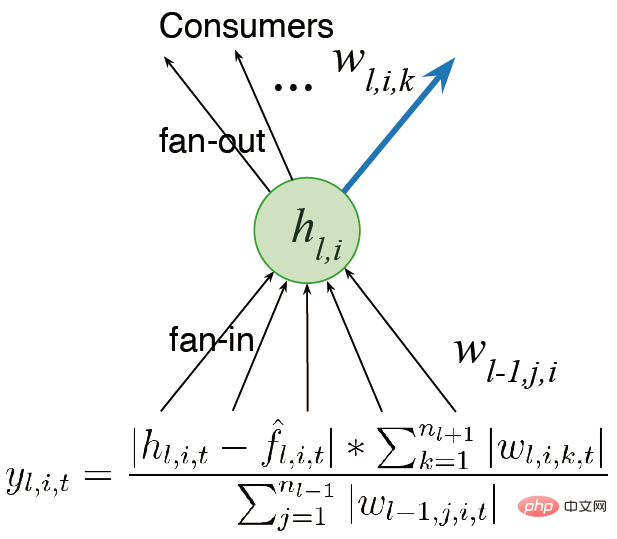
Terdapat dua hala tuju utama untuk penambahbaikan masa hadapan: (1) Kita perlu menjalankan pengukuran global utiliti dan mengukur neural Pengaruh elemen pada keseluruhan fungsi yang diwakili tidak terhad kepada ukuran tempatan seperti berat input, berat output dan fungsi pengaktifan; Pensampelan dilakukan untuk pemulaan, dan kaedah pemula yang boleh meningkatkan prestasi turut diterokai.
Jadi, sejauh manakah prestasi perambatan balik berterusan dalam mengekalkan keplastikan?Hasil eksperimen menunjukkan bahawa perambatan balik berterusan, dilatih menggunakan set data MNIST sejajar dalam talian,
mengekalkan keplastikan sepenuhnya. Lengkung biru dalam rajah di bawah menunjukkan hasil ini.
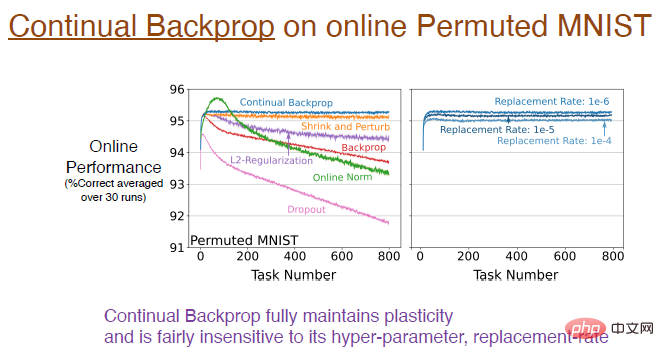
Nota ilustrasi: Gambar di sebelah kanan menunjukkan kesan kadar penggantian yang berbeza pada pembelajaran berterusan Contohnya, kadar penggantian 1e-6 bermakna setiap kali langkah untuk menggantikan 1/1000000 perwakilan. Iaitu, dengan mengandaikan terdapat 2000 ciri, satu neuron akan diganti dalam setiap lapisan setiap 500 langkah. Kelajuan kemas kini ini sangat perlahan, jadi kadar penggantian tidak begitu sensitif kepada hiperparameter dan tidak akan menjejaskan kesan pembelajaran dengan ketara.
Seterusnya, kita perlu mengkaji kesan perambatan balik berterusan ke atas struktur dalaman rangkaian saraf.Hampir tiada neuron "mati" dalam perambatan balik berterusan, Oleh kerana utiliti menganggap pengaktifan ciri purata, jika neuron "mati", ia akan diganti serta-merta. Dan kerana kami terus menggantikan neuron, kami mendapat neuron baharu dengan magnitud berat yang lebih kecil. Oleh kerana neuron dimulakan secara rawak, mereka mengekalkan perwakilan dan kepelbagaian yang lebih kaya dengan sewajarnya.
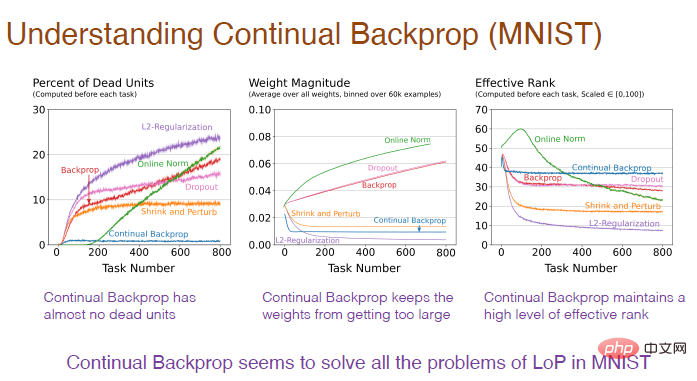
Jadi, bolehkah perambatan balik berterusan dilanjutkan ke rangkaian neural konvolusi yang lebih mendalam?
Jawapannya ya! Pada dataset ImageNet, perambatan balik berterusan mengekalkan keplastikan sepenuhnya, dan ketepatan akhir model adalah sekitar 89%. Malah, dalam peringkat latihan awal, prestasi algoritma ini adalah setara Seperti yang dinyatakan sebelum ini, kadar penggantian berubah dengan sangat perlahan, dan anggaran lebih baik hanya apabila bilangan tugasan cukup besar.
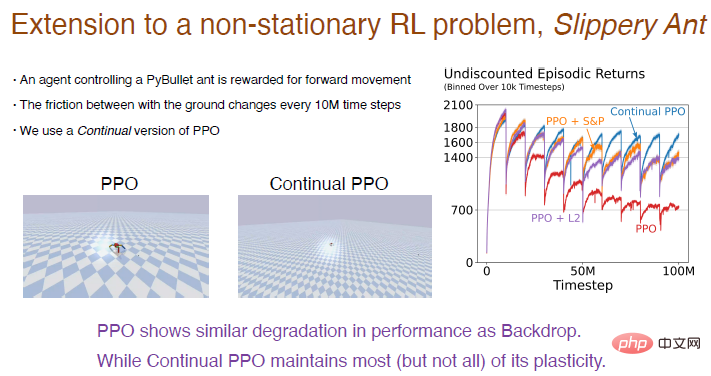
Di sini kita ambil masalah "Semut Licin" sebagai contoh untuk menunjukkan hasil eksperimen pembelajaran pengukuhan. Masalah "Semut Licin" adalah lanjutan daripada masalah tetulang tidak pegun dan pada asasnya serupa dengan persekitaran PyBullet Satu-satunya perbezaan ialah geseran antara tanah dan agen akan meningkat setiap 10 juta langkah perubahan berlaku. Kami melaksanakan versi pembelajaran berterusan algoritma PPO berdasarkan perambatan balik berterusan, yang boleh dimulakan secara terpilih. Hasil perbandingan antara algoritma PPO dan algoritma PPO berterusan adalah seperti berikut. Nota imej: Algoritma PPO menunjukkan prestasi yang baik pada mulanya, tetapi apabila latihan berlangsung, prestasi terus menurun, L2 algoritma dan pengecutan diperkenalkan dan algoritma gangguan akan dikurangkan. Algoritma PPO berterusan menunjukkan prestasi yang agak baik, mengekalkan kebanyakan keplastikan. Apa yang menarik ialah ejen yang dilatih oleh algoritma PPO hanya boleh bergelut untuk berjalan, tetapi ejen yang dilatih oleh algoritma PPO secara berterusan boleh berlari sangat jauh. Rangkaian pembelajaran mendalam terutamanya dioptimumkan untuk pembelajaran sekali sahaja, mungkin tidak berguna sepenuhnya untuk pembelajaran berterusan gagal. Kaedah pembelajaran mendalam seperti normalisasi dan DropOut mungkin tidak membantu untuk pembelajaran berterusan, tetapi membuat beberapa penambahbaikan kecil selain daripada ini, seperti perambatan balik berterusan, boleh menjadi sangat berkesan. Rambatan belakang berterusan menyusun ciri-ciri rangkaian mengikut utiliti neuron Terutamanya untuk rangkaian saraf berulang, mungkin terdapat lebih banyak peningkatan dalam kaedah pengisihan. Algoritma pembelajaran pengukuhan menggunakan idea lelaran dasar Walaupun masalah pembelajaran berterusan wujud, mengekalkan keplastikan rangkaian pembelajaran mendalam membuka kemungkinan baharu yang besar untuk RL dan RL berasaskan model. 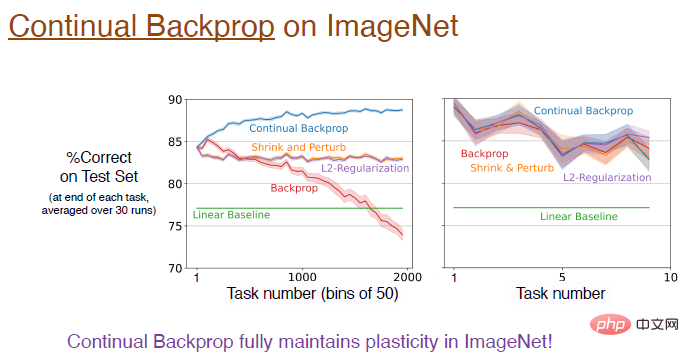
4 Kesimpulan
Atas ialah kandungan terperinci Richard Sutton secara terang-terangan menyatakan bahawa perambatan balik konvolusi telah ketinggalan, dan penemuan AI memerlukan idea baharu: perambatan balik berterusan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI