
Rumah >Peranti teknologi >AI >Dilema sumber terbuka untuk model AI yang besar: Monopoli, dinding dan kesedihan kuasa pengkomputeran
Dilema sumber terbuka untuk model AI yang besar: Monopoli, dinding dan kesedihan kuasa pengkomputeran

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-19 08:16:021117semak imbas
Artikel ini dicetak semula dengan kebenaran AI New Media Qubit (ID akaun awam: QbitAI Sila hubungi sumber untuk mencetak semula).
Pada Jun 2020, OpenAI mengeluarkan GPT-3 skala ratusan bilion parameter dan keupayaan pemprosesan bahasa yang menakjubkan telah membawa kejutan besar kepada komuniti AI domestik. Walau bagaimanapun, memandangkan GPT-3 tidak dibuka kepada pasaran domestik, apabila beberapa syarikat komersial yang menyediakan perkhidmatan penjanaan teks dilahirkan di luar negara, kami hanya boleh melihat ke belakang dan mengeluh.
Pada bulan Ogos tahun ini, Stability AI, sebuah syarikat sumber terbuka di London, mengeluarkan Stable Diffusion, model graf Vincent, dan sumber terbuka pemberat dan kod model secara percuma, yang dengan cepat mencetuskan kebangkitan aplikasi AI Painting sedang meletup di seluruh dunia.
Boleh dikatakan sumber terbuka memainkan peranan pemangkin langsung dalam ledakan AIGC pada separuh kedua tahun ini.
Dan apabila model besar menjadi permainan yang semua orang boleh sertai, bukan AIGC sahaja yang mendapat manfaat.
01
Sumber terbuka model besar sedang dijalankan
Empat tahun lalu, sebuah projek bernama BERT Model bahasa keluar dan menukar peraturan permainan model AI dengan 300 juta parameter.
Hari ini, jumlah model AI telah melonjak kepada trilion, tetapi "monopoli" model besar juga menjadi semakin ketara:
Syarikat besar, kuasa pengkomputeran besar, algoritma yang kukuh dan model besar, bersama-sama mereka telah membina tembok yang sukar untuk dipecahkan oleh pemaju biasa dan perusahaan kecil dan sederhana.
Halangan teknikal, serta sumber dan infrastruktur pengkomputeran yang diperlukan untuk melatih dan menggunakan model besar, menghalang Ini menandakan laluan kami daripada "memurnikan" model besar kepada "menggunakan" model besar. Oleh itu, sumber terbuka adalah mendesak. Membenarkan lebih ramai orang mengambil bahagian dalam permainan model besar melalui sumber terbuka dan mengubah model besar daripada teknologi AI yang sedang berkembang menjadi infrastruktur yang mantap menjadi konsensus ramai pencipta model besar.
Di bawah konsensus inilah Alibaba Damo Academy melancarkan komuniti sumber terbuka model Cina "ModelScope" di Persidangan Yunqi tidak lama dahulu perhatian dalam komuniti AI Pada masa ini, beberapa institusi domestik telah mula menyumbang model kepada komuniti atau menubuhkan sistem model sumber terbuka mereka sendiri.
Pembinaan ekologi sumber terbuka asing bagi model besar pada masa ini nampaknya mendahului model domestik. Kestabilan AI dilahirkan sebagai syarikat swasta tetapi mempunyai gen sumber terbuka sendiri Ia mempunyai komuniti pembangun yang besar dan mempunyai model keuntungan yang stabil semasa menjadi sumber terbuka.
BLOOM, dikeluarkan pada Julai tahun ini, mempunyai 176 bilion parameter dan kini merupakan model bahasa sumber terbuka terbesar di belakangnya amat sesuai dengan semangat sumber terbuka Jari kaki mendedahkan momentum bersaing dengan gergasi teknologi. BigScience ialah organisasi kerjasama terbuka yang diterajui oleh Huggingface dan bukan entiti yang ditubuhkan secara rasmi Kelahiran BLOOM adalah hasil daripada lebih 1,000 penyelidik dari lebih 70 negara yang berlatih tentang superkomputer selama 117 hari.
Selain itu, syarikat gergasi teknologi tidak terlepas daripada terlibat dalam sumber terbuka model besar. Pada Mei tahun ini, Meta menggunakan sumber terbuka OPT model besar dengan 175 bilion parameter Selain membenarkan OPT digunakan untuk tujuan bukan komersial, ia juga mengeluarkan kodnya dan 100 halaman log yang merekodkan proses latihan bahawa sumber terbuka adalah sangat teliti.
Pasukan penyelidik menyatakan secara terang-terangan dalam abstrak kertas OPT, "Memandangkan kos pengiraan, model ini sukar untuk ditiru tanpa jumlah pembiayaan yang besar. Untuk Beberapa model yang tersedia melalui API tidak mempunyai akses kepada berat model penuh, menjadikannya sukar untuk dipelajari." Nama penuh model "Open Pre-trained Transformers" juga menunjukkan sikap sumber terbuka Meta. Ini boleh dikatakan sebagai sindiran GPT-3 yang dikeluarkan oleh OpenAI, yang bukan "Terbuka" (hanya menyediakan perkhidmatan berbayar API), dan 540 bilion parameter model besar PaLM (bukan sumber terbuka) yang dilancarkan oleh Google pada April tahun ini .
Antara syarikat besar yang sentiasa mempunyai perasaan monopoli yang kuat, langkah sumber terbuka Meta adalah menghirup udara segar. Percy Liang, pengarah Pusat Penyelidikan Model Fundamental di Universiti Stanford pada masa itu, mengulas: "Ini adalah langkah yang menarik ke arah membuka peluang baharu untuk penyelidikan. Secara umumnya, kita boleh berfikir bahawa keterbukaan yang lebih besar akan membolehkan penyelidik menyelesaikan masalah Isu yang lebih mendalam 》
02
Imaginasi model besar tidak sepatutnya berhenti di AIGC
Percy Kata-kata Liang juga menjawab persoalan mengapa model besar mesti menjadi sumber terbuka dari peringkat akademik.
Kelahiran pencapaian asal memerlukan sumber terbuka untuk menyediakan tanah.
Pasukan R&D melatih model besar Jika berhenti menerbitkan kertas kerja di persidangan teratas, maka semua penyelidik lain akan mendapat pelbagai aspek kertas itu . Angka "menunjukkan otot" jenis ini tanpa melihat lebih banyak butiran teknologi latihan model hanya boleh mengambil masa untuk menghasilkan semula, tetapi ia mungkin tidak berjaya. Kebolehulangan adalah jaminan untuk kebolehpercayaan dan kredibiliti hasil penyelidikan saintifik Dengan model terbuka, kod dan set data, penyelidik saintifik boleh bersaing dengan penyelidikan yang paling canggih dengan cara yang lebih tepat pada masanya, dan berdiri di atas bahu gergasi untuk disentuh. bintang. Buah-buahan dari tempat yang lebih tinggi boleh menjimatkan banyak masa dan kos serta mempercepatkan inovasi teknologi.
Kekurangan keaslian dalam kerja model besar di China terutamanya dicerminkan dalam usaha mengejar saiz model secara buta, tetapi terdapat sedikit inovasi dalam seni bina asas, Ini adalah konsensus umum di kalangan pakar industri yang terlibat dalam penyelidikan model besar.
Profesor Madya Liu Zhiyuan dari Jabatan Sains Komputer Universiti Tsinghua menunjukkan Kajian Teknologi AI: Terdapat beberapa karya yang agak inovatif pada seni bina model besar di China, tetapi pada asasnya semuanya Masih berdasarkan Transformer, China masih kekurangan seni bina asas seperti Transformer, serta model seperti BERT dan GPT-3 yang boleh menyebabkan perubahan besar dalam bidang tersebut.
Dr. Zhang Jiaxing, ketua saintis Institut Penyelidikan IDEA (Institut Penyelidikan Ekonomi Digital Kawasan Teluk Guangdong-Hong Kong-Macao), turut memberitahu Kajian Teknologi AI bahawa daripada berpuluh bilion hingga ratusan bilion hingga trilion, selepas kita mengatasi pelbagai cabaran sistem dan kejuruteraan, kita harus memikirkan struktur model baharu dan bukannya menjadikan model itu lebih besar.
Sebaliknya, untuk model besar mencapai kemajuan teknologi, satu set piawaian penilaian model diperlukan, dan penjanaan piawaian memerlukan keterbukaan dan ketelusan. Beberapa penyelidikan baru-baru ini cuba mencadangkan pelbagai penunjuk penilaian untuk banyak model besar, tetapi beberapa model yang sangat baik dikecualikan kerana tidak dapat diakses Contohnya, model besar Google PaLM yang dilatih di bawah seni bina Pathwaysnya mempunyai keupayaan pemahaman bahasa super jenaka, dan model bahasa besar DeepMind Chinchilla bukan sumber terbuka.
Tetapi sama ada ia adalah daripada keupayaan cemerlang model itu sendiri atau status pengeluar utama ini, mereka tidak sepatutnya tidak hadir dari padang permainan yang adil itu.
Fakta yang menyedihkan ialah kajian terbaru oleh Percy Liang dan rakan sekerja menunjukkan bahawa berbanding model bukan sumber terbuka, model sumber terbuka semasa Terdapat jurang tertentu dalam persembahan pada banyak adegan teras. Model besar sumber terbuka seperti OPT-175B, BLOOM-176B dan GLM-130B dari Universiti Tsinghua hampir hilang sepenuhnya kepada model besar bukan sumber terbuka dalam pelbagai tugas, termasuk InstructGPT OpenAI, TNLG- 530B Microsoft/NVIDIA dan sebagainya (seperti yang ditunjukkan di bawah).
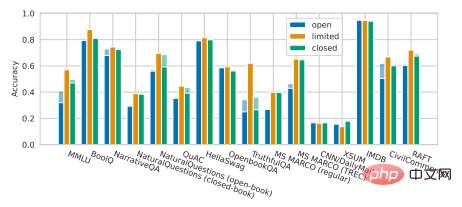
Ilustrasi: Percy Liang et al Penilaian Holistik Model Bahasa
Untuk menyelesaikan situasi yang memalukan ini, setiap pemimpin perlu membuka sumber model besar mereka sendiri yang berkualiti tinggi, supaya kemajuan keseluruhan dalam bidang model besar dapat mencapai tahap yang lebih tinggi dengan lebih cepat.
Dari segi pelaksanaan industri model besar, sumber terbuka adalah satu-satunya cara untuk digunakan.
Jika anda mengambil pelepasan GPT-3 sebagai titik permulaan, selepas lebih daripada dua tahun usaha anda, model besar Pada pendapat saya, teknologi penyelidikan dan pembangunan agak matang, tetapi pada skala global, pelaksanaan model besar masih di peringkat awal. Walaupun model besar yang dibangunkan oleh pengeluar domestik utama mempunyai senario pelaksanaan perniagaan dalaman, model itu belum lagi mempunyai model pengkomersilan matang secara keseluruhan.
Apabila pelaksanaan model berskala besar mendapat momentum, melakukan kerja yang baik dalam sumber terbuka boleh meletakkan asas bagi ekosistem pelaksanaan berskala besar dalam masa hadapan.
Sifat model besar menentukan keperluan sumber terbuka untuk pelaksanaan. Zhou Jingren, timbalan pengarah Akademi Alibaba Damo, memberitahu Kajian Teknologi AI, "Model besar adalah abstraksi dan penambahbaikan sistem pengetahuan manusia, jadi senario yang boleh digunakan dan nilai yang dihasilkannya adalah besar hanya melalui sumber terbuka model boleh Potensi aplikasi boleh dimaksimumkan oleh banyak pembangun kreatif.
Ini adalah sesuatu yang model API yang menutup butiran teknikal dalaman model besar tidak boleh lakukan. Pertama sekali, model ini sesuai untuk pengguna model yang mempunyai keupayaan pembangunan yang rendah Bagi mereka, kejayaan atau kegagalan pelaksanaan model besar adalah bersamaan dengan sepenuhnya berada di tangan R&D institusi.
Ambil OpenAI, pemenang terbesar yang menyediakan perkhidmatan berbayar API model besar, sebagai contoh Menurut statistik OpenAI, lebih daripada 300 syarikat di seluruh dunia telah menggunakan Aplikasi teknologi GPT-3, tetapi premis fakta ini ialah kekuatan penyelidikan dan pembangunan OpenAI adalah kuat dan GPT-3 cukup kuat. Sekiranya model itu sendiri berprestasi buruk, maka pemaju sedemikian tidak berdaya.
Lebih penting lagi, keupayaan yang boleh disediakan oleh model besar melalui API terbuka adalah terhad, menjadikannya sukar untuk mengendalikan keperluan aplikasi yang kompleks dan pelbagai. Pada masa ini, hanya terdapat beberapa aplikasi kreatif di pasaran, tetapi secara keseluruhannya ia masih dalam peringkat "mainan" dan jauh daripada mencapai tahap perindustrian berskala besar.
"Nilai yang dijana tidak begitu hebat, dan kosnya tidak dapat dipulihkan, jadi senario aplikasi berdasarkan API GPT-3 adalah sangat terhad. Ramai orang dalam industri Malah, saya tidak bersetuju dengan pendekatan ini,” kata Zhang Jiaxing. Malah, syarikat asing seperti copy.ai dan Jasper memilih untuk terlibat dalam perniagaan penulisan berbantukan AI Pasaran pengguna secara relatifnya lebih besar, jadi mereka boleh menjana nilai komersial yang agak besar, manakala lebih banyak aplikasi hanya berskala kecil.
Sebaliknya, sumber terbuka "mengajar orang cara memancing".
Dalam model sumber terbuka, perusahaan bergantung pada kod sumber terbuka untuk menjalankan latihan dan latihan menengah yang memenuhi keperluan perniagaan mereka berdasarkan asas sedia ada. rangka kerja. Pembangunan, yang boleh memberikan permainan penuh kepada kelebihan serba boleh model besar, mengeluarkan produktiviti jauh melebihi tahap semasa, dan akhirnya membawa pelaksanaan sebenar teknologi model besar dalam industri.
Sebagai trek yang paling jelas kelihatan untuk pengkomersialan model besar pada masa ini, lepas landas AIGC telah mengesahkan kejayaan model sumber terbuka model besar . Walau bagaimanapun, Dalam senario aplikasi lain, sumber terbuka model besar masih dalam minoriti, di dalam dan di luar negara. Lan Zhenzhong, ketua Makmal Pembelajaran Dalam Universiti West Lake, pernah memberitahu Kajian Teknologi AI bahawa walaupun terdapat banyak keputusan pada model besar, terdapat sangat sedikit sumber terbuka dan akses terhad kepada penyelidik biasa, yang sangat dikesali.
Sumbangan, penyertaan dan kerjasama Sumber terbuka dengan kata kunci ini sebagai terasnya boleh menghimpunkan sebilangan besar pembangun yang bersemangat untuk bersama-sama mencipta yang berpotensi transformatif. projek model membolehkan model besar bergerak dari makmal ke industri dengan lebih pantas.
03
Berat tidak tertanggung: kuasa pengkomputeran
Kepentingan sumber terbuka untuk model besar Ini adalah konsensus, tetapi masih terdapat halangan besar dalam perjalanan ke sumber terbuka: kuasa pengkomputeran.
Ini juga merupakan cabaran terbesar yang dihadapi oleh pelaksanaan semasa model besar. Walaupun Meta mempunyai OPT sumber terbuka, setakat ini ia nampaknya tidak membuat riak besar dalam pasaran aplikasi Akhirnya, kos kuasa pengkomputeran masih tidak tertanggung untuk pembangun kecil, apatah lagi memperhalusi model besar , pembangunan sekunder , hanya penaakulan adalah sangat sukar.
Oleh sebab itu, di bawah gelombang refleksi pada parameter, banyak institusi R&D telah beralih kepada idea untuk membuat model ringan dan mengawal parameter daripada model kepada Antara ratusan juta hingga beberapa bilion. Model "Mencius" yang dilancarkan oleh Lanzhou Technology dan siri model "Fengshen Bang" sumber terbuka oleh Institut Penyelidikan IDEA adalah kedua-dua wakil domestik bagi laluan ini. Mereka membahagikan pelbagai keupayaan model yang sangat besar kepada model dengan parameter yang agak kecil, dan telah membuktikan keupayaan mereka untuk mengatasi ratusan bilion model dalam beberapa tugasan tunggal.
Tetapi tidak syak lagi bahawa jalan ke model besar tidak akan berhenti di sini Ramai pakar industri telah memberitahu Kajian Teknologi AI bahawa parameter model besar masih Terdapat ruang untuk penambahbaikan, dan seseorang mesti terus meneroka model berskala lebih besar. Jadi kita perlu menghadapi dilema model besar sumber terbuka Jadi, apakah penyelesaiannya?
Mari kita pertimbangkan dahulu dari perspektif kuasa pengkomputeran itu sendiri. Pembinaan kluster komputer berskala besar dan pusat kuasa pengkomputeran pasti akan menjadi trend pada masa hadapan Lagipun, sumber pengkomputeran pada akhirnya tidak dapat memenuhi permintaan. Tetapi sekarang Undang-undang Moore telah menjadi perlahan, dan tidak ada kekurangan dalam industri bahawa Undang-undang Moore akan berakhir Jika anda hanya meletakkan harapan anda pada peningkatan kuasa pengkomputeran, anda tidak akan dapat memadamkan. dahaga segera anda.
"Kini satu kad boleh dijalankan (dari segi inferens) satu bilion model. Mengikut kadar pertumbuhan kuasa pengkomputeran semasa, apabila satu The kad boleh menjalankan model 100 bilion, yang bermaksud bahawa ia mungkin mengambil masa sepuluh tahun untuk meningkatkan kuasa pengkomputeran sebanyak seratus kali ganda." Zhang Jiaxing menjelaskan.
Saya tidak sabar menunggu begitu lama untuk model besar itu dilancarkan.
Arah yang lain adalah untuk membuat kekecohan tentang teknologi latihan untuk mempercepatkan inferens model yang besar, mengurangkan kos kuasa pengkomputeran dan mengurangkan penggunaan tenaga, untuk meningkatkan model besar kemudahan penggunaan.
Sebagai contoh, OPT Meta (berbanding GPT-3) hanya memerlukan 16 GPU NVIDIA v100 untuk melatih dan menggunakan asas kod model yang lengkap ketujuh GPT-3. Baru-baru ini, Universiti Tsinghua dan Zhipu AI bersama-sama membuka model besar dwibahasa GLM-130B Melalui kaedah inferens pantas, model tersebut telah dimampatkan ke tahap di mana ia boleh digunakan untuk inferens kendiri pada A100 (40G*8) atau. Pelayan V100 (32G*8).
Sudah tentu masuk akal untuk bekerja keras ke arah ini Sebab yang jelas sendiri mengapa pengeluar utama tidak mahu membuka model besar sumber adalah kos latihan yang tinggi . Pakar sebelum ini menganggarkan bahawa puluhan ribu GPU Nvidia v100 digunakan untuk melatih GPT-3, dengan jumlah kos sehingga AS$27.6 juta Jika seseorang individu ingin melatih PaLM, ia akan menelan kos AS$9 hingga 17 juta. Sekiranya kos latihan model besar dapat dikurangkan, kesediaan mereka untuk membuka sumber secara semula jadi akan meningkat.
Tetapi dalam analisis akhir, ini hanya dapat mengurangkan kekangan pada sumber pengkomputeran daripada perspektif kejuruteraan, tetapi bukan penyelesaian muktamad. Walaupun banyak model berskala besar dengan ratusan bilion dan trilion tahap telah mula mempromosikan kelebihan "penggunaan tenaga rendah" mereka, dinding kuasa pengkomputeran masih terlalu tinggi.
Akhirnya, kita perlu kembali kepada model besar itu sendiri untuk mencari titik terobosan Arah yang sangat menjanjikan ialah dinamik yang jarang model.
Model besar yang jarang dicirikan oleh kapasiti yang sangat besar, tetapi hanya bahagian tertentu untuk tugasan, sampel atau label tertentu diaktifkan. Dalam erti kata lain, struktur dinamik yang jarang ini boleh membenarkan model besar melonjak beberapa tahap dalam kuantiti parameter tanpa perlu membayar kos pengiraan yang besar, membunuh dua burung dengan satu batu. Ini adalah kelebihan besar berbanding model padat dan besar seperti GPT-3, yang memerlukan pengaktifan keseluruhan rangkaian saraf untuk menyelesaikan tugas yang paling mudah sekalipun, mengakibatkan pembaziran sumber yang besar.
Google ialah perintis kepada struktur dinamik jarang mereka mula-mula mencadangkan MoE (Sparsely-Gated Mixture-of-Experts Layer, Sparsely-Gated Mixture-of-Experts Layer) pada 2017 dan melancarkan 16,000 daripada. mereka tahun lepas. Model besar berbilion parameter Switch Transformers menggabungkan seni bina gaya MoE, dan kecekapan latihan meningkat sebanyak 7 kali ganda berbanding dengan model padat T5-Base Transformer mereka.
Seni bina bersatu Pathways yang menjadi asas PaLM tahun ini ialah model struktur dinamik yang jarang: model boleh mempelajari secara dinamik bahagian tertentu rangkaian yang baik di. Untuk tugasan, kita boleh memanggil laluan kecil melalui rangkaian mengikut keperluan, tanpa mengaktifkan keseluruhan rangkaian saraf untuk menyelesaikan tugas.

Kapsyen: Seni bina laluan
Ini pada asasnya serupa dengan cara otak manusia beroperasi Terdapat berpuluh-puluh bilion neuron dalam otak manusia, tetapi hanya neuron dengan fungsi tertentu yang diaktifkan apabila melakukan tugas-tugas tertentu.
Besar, serba boleh dan cekap, laluan model besar ini sudah pasti sangat menarik.
"Dengan sokongan dinamik yang jarang pada masa hadapan, kos pengiraan tidak akan begitu tinggi , tetapi model Parameter pasti akan menjadi lebih besar dan lebih besar, dan struktur dinamik yang jarang boleh membuka dunia baru untuk model besar, dan tidak ada masalah untuk pergi ke 10 trilion atau 100 bilion." Zhang Jiaxing percaya bahawa jarang struktur dinamik akan menyelesaikan masalah saiz model yang besar dan kuasa pengkomputeran Jalan utama kepada konflik antara kos. Tetapi dia juga menambah bahawa apabila struktur model seperti ini belum lagi popular, tidak masuk akal untuk terus menjadikan model itu lebih besar.
Pada masa ini, terdapat sedikit percubaan domestik ke arah ini dan ia tidak begitu teliti seperti Google. Penerokaan dan inovasi dalam struktur model besar dan sumber terbuka mempromosikan satu sama lain, dan kami memerlukan lebih banyak sumber terbuka untuk merangsang perubahan dalam teknologi model besar.
Apa yang menghalang sumber terbuka model besar bukan sahaja ketersediaan rendah yang disebabkan oleh kos kuasa pengkomputeran model besar, tetapi juga isu keselamatan.
Mengenai risiko penyalahgunaan model besar, terutamanya yang dihasilkan selepas sumber terbuka, nampaknya terdapat lebih banyak kebimbangan dari luar negara dan banyak kontroversi menjadi Banyak institusi memilih untuk tidak membuka sumber kelayakan model besar, tetapi itu juga mungkin menjadi alasan untuk mereka menolak sifat murah hati.
OpenAI telah menarik banyak kritikan untuk perkara ini. Apabila mereka mengeluarkan GPT-2 pada 2019, mereka mendakwa bahawa keupayaan penjanaan teks model terlalu berkuasa dan mungkin menyebabkan kemudaratan etika, menjadikannya tidak sesuai untuk sumber terbuka. Apabila GPT-3 dikeluarkan setahun kemudian, ia hanya menyediakan percubaan API Versi sumber terbuka semasa GPT-3 sebenarnya dihasilkan semula oleh komuniti sumber terbuka itu sendiri.
Malah, menyekat akses kepada model besar tidak akan kondusif untuk meningkatkan keteguhan model besar dan mengurangkan berat sebelah dan ketoksikan. Apabila Joelle Pineau, ketua Meta AI, bercakap tentang keputusan untuk membuka OPT sumber, dia dengan ikhlas menyatakan bahawa pasukannya sendiri tidak dapat menyelesaikan semua masalah, seperti berat sebelah etika dan perkataan berniat jahat yang mungkin timbul semasa proses penjanaan teks. Mereka percaya bahawa jika kerja rumah yang mencukupi dilakukan, model besar boleh diakses secara terbuka secara bertanggungjawab.
Mengekalkan akses terbuka dan ketelusan yang mencukupi sambil menjaga daripada risiko penyalahgunaan bukanlah tugas yang mudah. Sebagai orang yang membuka "Kotak Pandora", Stability AI telah menikmati reputasi baik yang dibawa oleh sumber terbuka yang proaktif, tetapi ia juga baru-baru ini menghadapi tindak balas yang dibawa oleh sumber terbuka, menyebabkan kontroversi dalam aspek seperti pemilikan hak cipta.
Proposisi dialektik kuno tentang "kebebasan dan keselamatan" di sebalik sumber terbuka telah wujud sejak sekian lama mungkin tidak ada jawapan yang betul-betul betul, tetapi pada permulaan model besar Semasa kami bergerak ke arah pelaksanaan, fakta yang jelas ialah: kami tidak melakukan cukup untuk membuka model besar sumber.
Lebih daripada dua tahun telah berlalu, dan kami sudah mempunyai model berskala besar peringkat trilion kami sendiri Dalam proses transformasi seterusnya model berskala besar daripada "membaca ribuan buku" kepada "mengembara. beribu-ribu batu", sumber terbuka Ia adalah pilihan yang tidak dapat dielakkan.
Baru-baru ini, GPT-4 akan keluar, dan semua orang mempunyai jangkaan yang besar untuk lonjakan keupayaannya, tetapi kami tidak tahu apa yang akan berlaku seperti pada masa hadapan. Berapa banyak produktiviti yang akan dikeluarkan untuk berapa orang?
Atas ialah kandungan terperinci Dilema sumber terbuka untuk model AI yang besar: Monopoli, dinding dan kesedihan kuasa pengkomputeran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI