



Subrentetan dalam String
Kita semua tahu bahawa String tidak boleh diubah dalam Java Jika anda menukar kandungannya, ia akan menghasilkan rentetan baharu. Jika kita ingin menggunakan sebahagian daripada data dalam rentetan, kita boleh menggunakan kaedah subrentetan.
Berikut ialah kod sumber String dalam Java11.
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
if (beginIndex == 0) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
public static String newString(byte[] val, int index, int len) {
if (String.COMPACT_STRINGS) {
byte[] buf = compress(val, index, len);
if (buf != null) {
return new String(buf, LATIN1);
}
}
int last = index + len;
return new String(Arrays.copyOfRange(val, index << 1, last << 1), UTF16);
}Seperti yang ditunjukkan dalam kod di atas, apabila kita memerlukan subrentetan, subrentetan menjana rentetan baharu, yang dibina melalui fungsi Arrays.copyOfRange bagi pembina.
Fungsi ini tiada masalah selepas Java7, tetapi dalam Java6, ia mempunyai risiko kebocoran memori Kita boleh mengkaji kes ini untuk melihat masalah yang mungkin timbul daripada penggunaan semula objek besar. Berikut ialah kod dalam Java6:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ?
this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}Seperti yang anda lihat, apabila mencipta subrentetan, ia bukan sahaja menyalin objek yang diperlukan, tetapi merujuk keseluruhan nilai. Jika rentetan asal agak besar, memori tidak akan dikeluarkan walaupun ia tidak lagi digunakan.
Sebagai contoh, kandungan artikel mungkin beberapa megabait Kami hanya memerlukan maklumat ringkasan dan perlu mengekalkan keseluruhan objek besar.
Sesetengah penemuduga dengan pengalaman kerja yang agak lama mempunyai tanggapan bahawa subrentetan masih dalam JDK6, tetapi sebenarnya, Java telah mengubah suai pepijat ini. Jika anda menghadapi soalan ini semasa temu duga, hanya untuk berada di pihak yang selamat, anda boleh menjawab soalan tentang proses penambahbaikan.
Maksudnya bagi kami ialah: jika anda mencipta objek yang agak besar dan menjana beberapa maklumat lain berdasarkan objek ini, pada masa ini, anda mesti ingat untuk mengalih keluar hubungan rujukan dengan objek besar ini.
Peluasan objek koleksi besar
Peluasan objek ialah fenomena biasa di Jawa, seperti StringBuilder, StringBuffer, HashMap, ArrayList, dsb. Ringkasnya, data dalam koleksi Java, termasuk Senarai, Set, Baris Gilir, Peta, dsb., tidak boleh dikawal. Apabila kapasiti tidak mencukupi, akan ada operasi pengembangan. Operasi pengembangan memerlukan data untuk disusun semula, jadi ia tidak selamat untuk benang.
Mari kita lihat dahulu kod pengembangan StringBuilder:
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}Apabila kapasiti tidak mencukupi, memori akan digandakan dan data sumber akan disalin menggunakan Arrays.copyOf.
Berikut ialah kod pengembangan HashMap Selepas pengembangan, saiznya juga digandakan. Tindakan pengembangannya jauh lebih rumit Selain daripada kesan faktor beban, ia juga perlu mencincang semula data asal Memandangkan kaedah Arrays.copy asli tidak boleh digunakan, kelajuannya akan menjadi sangat perlahan.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}Anda boleh menyemak kod Senarai sendiri Ia juga menyekat Strategi pengembangan adalah 1.5 kali panjang asal.
Memandangkan koleksi digunakan dengan sangat kerap dalam kod, jika anda mengetahui had atas item data tertentu, anda mungkin ingin menetapkan saiz permulaan yang munasabah. Sebagai contoh, HashMap memerlukan 1024 elemen dan memerlukan 7 pengembangan, yang akan menjejaskan prestasi aplikasi. Soalan ini akan kerap timbul dalam temu bual, dan anda perlu memahami kesan operasi pengembangan ini terhadap prestasi.
Tetapi sila ambil perhatian bahawa untuk koleksi seperti HashMap yang mempunyai faktor beban (0.75), saiz awal = nombor yang diperlukan/faktor beban + 1. Jika anda tidak begitu jelas tentang struktur asas, anda mungkin serta mengekalkan lalai.
Seterusnya, saya akan menerangkan pengoptimuman pada peringkat aplikasi bermula dari dimensi struktur dan dimensi masa data.
Kekalkan kebutiran objek yang sesuai
Izinkan saya berkongsi dengan anda satu kes praktikal: Kami mempunyai sistem perniagaan dengan keselarasan yang sangat tinggi, yang memerlukan penggunaan data asas pengguna yang kerap.
Seperti yang ditunjukkan dalam rajah di bawah, memandangkan maklumat asas pengguna disimpan dalam perkhidmatan lain, setiap kali maklumat asas pengguna digunakan, interaksi rangkaian diperlukan. Apa yang lebih tidak boleh diterima ialah walaupun hanya atribut jantina pengguna diperlukan, semua maklumat pengguna perlu disoal dan ditarik.
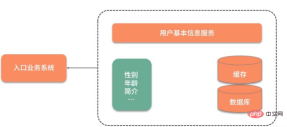
Untuk mempercepatkan pertanyaan data, data pada mulanya dicache dan dimasukkan ke dalam Redis Prestasi pertanyaan telah dipertingkatkan dengan baik, tetapi ia masih perlu disoal setiap masa. Banyak data yang berlebihan.
Kunci redis asal direka bentuk seperti ini:
type: string
key: user_${userid}
value: jsonTerdapat dua masalah dengan reka bentuk ini:
Untuk menanyakan nilai medan tertentu, anda perlu letak semua json Data ditanya dan dihuraikan dengan sendirinya;
Mengemas kini nilai salah satu medan memerlukan pengemaskinian keseluruhan rentetan json, yang mahal.
Untuk jenis maklumat json berbutir besar ini, ia boleh dioptimumkan dalam cara yang berselerak, supaya setiap kemas kini dan pertanyaan mempunyai sasaran yang difokuskan.
Seterusnya, data dalam Redis direka seperti berikut, menggunakan struktur hash dan bukannya struktur json:
type: hash
key: user_${userid}
value: {sex:f, id:1223, age:23}Dengan cara ini, kita boleh menggunakan arahan hget atau arahan hmget untuk mendapatkan Want data untuk mempercepatkan penyaluran maklumat.
Bitmap menjadikan objek lebih kecil
Selain daripada operasi di atas, bolehkah ia dioptimumkan lagi? Sebagai contoh, data jantina pengguna kerap digunakan dalam sistem kami untuk mengedarkan beberapa hadiah, mengesyorkan beberapa rakan berlainan jantina, kerap berbasikal pengguna untuk melakukan beberapa tindakan pembersihan, dsb. atau, menyimpan beberapa maklumat status pengguna, seperti sama ada mereka berada dalam talian dan sama ada mereka telah mendaftar masuk. , sama ada maklumat telah dihantar baru-baru ini, dsb., untuk mengira pengguna aktif, dsb. Kemudian operasi dua nilai ya dan tidak boleh dimampatkan menggunakan struktur Bitmap.
这里还有个高频面试问题,那就是 Java 的 Boolean 占用的是多少位?
在 Java 虚拟机规范里,描述是:将 Boolean 类型映射成的是 1 和 0 两个数字,它占用的空间是和 int 相同的 32 位。即使有的虚拟机实现把 Boolean 映射到了 byte 类型上,它所占用的空间,对于大量的、有规律的 Boolean 值来说,也是太大了。
如代码所示,通过判断 int 中的每一位,它可以保存 32 个 Boolean 值!
int a= 0b0001_0001_1111_1101_1001_0001_1111_1101;
Bitmap 就是使用 Bit 进行记录的数据结构,里面存放的数据不是 0 就是 1。还记得我们在之前 《分布式缓存系统必须要解决的四大问题》中提到的缓存穿透吗?就可以使用 Bitmap 避免,Java 中的相关结构类,就是 java.util.BitSet,BitSet 底层是使用 long 数组实现的,所以它的最小容量是 64。
10 亿的 Boolean 值,只需要 128MB 的内存,下面既是一个占用了 256MB 的用户性别的判断逻辑,可以涵盖长度为 10 亿的 ID。
static BitSet missSet = new BitSet(010_000_000_000);
static BitSet sexSet = new BitSet(010_000_000_000);
String getSex(int userId) {
boolean notMiss = missSet.get(userId);
if (!notMiss) {
//lazy fetch
String lazySex = dao.getSex(userId);
missSet.set(userId, true);
sexSet.set(userId, "female".equals(lazySex));
}
return sexSet.get(userId) ? "female" : "male";
}这些数据,放在堆内内存中,还是过大了。幸运的是,Redis 也支持 Bitmap 结构,如果内存有压力,我们可以把这个结构放到 Redis 中,判断逻辑也是类似的。
再插一道面试算法题:给出一个 1GB 内存的机器,提供 60亿 int 数据,如何快速判断有哪些数据是重复的?
大家可以类比思考一下。Bitmap 是一个比较底层的结构,在它之上还有一个叫作布隆过滤器的结构(Bloom Filter),布隆过滤器可以判断一个值不存在,或者可能存在。
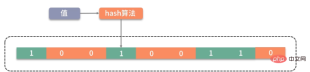
如图,它相比较 Bitmap,它多了一层 hash 算法。既然是 hash 算法,就会有冲突,所以有可能有多个值落在同一个 bit 上。它不像 HashMap一样,使用链表或者红黑树来处理冲突,而是直接将这个hash槽重复使用。从这个特性我们能够看出,布隆过滤器能够明确表示一个值不在集合中,但无法判断一个值确切的在集合中。
Guava 中有一个 BloomFilter 的类,可以方便地实现相关功能。
上面这种优化方式,本质上也是把大对象变成小对象的方式,在软件设计中有很多类似的思路。比如像一篇新发布的文章,频繁用到的是摘要数据,就不需要把整个文章内容都查询出来;用户的 feed 信息,也只需要保证可见信息的速度,而把完整信息存放在速度较慢的大型存储里。
数据的冷热分离
数据除了横向的结构纬度,还有一个纵向的时间维度,对时间维度的优化,最有效的方式就是冷热分离。
所谓热数据,就是靠近用户的,被频繁使用的数据;而冷数据是那些访问频率非常低,年代非常久远的数据。
同一句复杂的 SQL,运行在几千万的数据表上,和运行在几百万的数据表上,前者的效果肯定是很差的。所以,虽然你的系统刚开始上线时速度很快,但随着时间的推移,数据量的增加,就会渐渐变得很慢。
冷热分离是把数据分成两份,如下图,一般都会保持一份全量数据,用来做一些耗时的统计操作。

由于冷热分离在工作中经常遇到,所以面试官会频繁问到数据冷热分离的方案。下面简单介绍三种:
数据双写
把对冷热库的插入、更新、删除操作,全部放在一个统一的事务里面。由于热库(比如 MySQL)和冷库(比如 Hbase)的类型不同,这个事务大概率会是分布式事务。在项目初期,这种方式是可行的,但如果是改造一些遗留系统,分布式事务基本上是改不动的,我通常会把这种方案直接废弃掉。
写入 MQ 分发
通过 MQ 的发布订阅功能,在进行数据操作的时候,先不落库,而是发送到 MQ 中。单独启动消费进程,将 MQ 中的数据分别落到冷库、热库中。使用这种方式改造的业务,逻辑非常清晰,结构也比较优雅。像订单这种结构比较清晰、对顺序性要求较低的系统,就可以采用 MQ 分发的方式。但如果你的数据库实体量非常大,用这种方式就要考虑程序的复杂性了。
使用 Binlog 同步
针对 MySQL,就可以采用 Binlog 的方式进行同步,使用 Canal 组件,可持续获取最新的 Binlog 数据,结合 MQ,可以将数据同步到其他的数据源中。
思维发散
对于结果集的操作,我们可以再发散一下思维。可以将一个简单冗余的结果集,改造成复杂高效的数据结构。这个复杂的数据结构可以代理我们的请求,有效地转移耗时操作。
Sebagai contoh, indeks pangkalan data kami yang biasa digunakan ialah sejenis penyusunan semula dan pecutan data. Pokok B+ boleh mengurangkan bilangan interaksi antara pangkalan data dan cakera dengan berkesan Ia mengindeks data yang paling biasa digunakan melalui struktur data yang serupa dengan pokok B+ dan menyimpannya dalam ruang storan yang terhad.
Terdapat juga siri yang biasa digunakan dalam RPC. Sesetengah perkhidmatan menggunakan protokol SOAP WebService, yang merupakan protokol berdasarkan XML Penghantaran kandungan besar adalah perlahan dan tidak cekap. Kebanyakan perkhidmatan web hari ini menggunakan data json untuk interaksi, dan json lebih cekap daripada SOAP.
Selain itu, semua orang sepatutnya pernah mendengar tentang protobuf Google Kerana ia adalah protokol binari dan memampatkan data, prestasinya sangat unggul. Selepas protobuf memampatkan data, saiznya hanya 1/10 daripada json dan 1/20 daripada xml, tetapi prestasinya dipertingkatkan sebanyak 5-100 kali.
Reka bentuk protobuf patut dipelajari. Ia memproses data dengan sangat padat melalui tiga bahagian nilai tag|leng|, dan kelajuan penghuraian dan penghantaran sangat pantas.
Atas ialah kandungan terperinci Bagaimana untuk menangani objek besar di Jawa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimanakah saya menggunakan Maven atau Gradle untuk Pengurusan Projek Java Lanjutan, Membina Automasi, dan Resolusi Ketergantungan?Mar 17, 2025 pm 05:46 PM
Bagaimanakah saya menggunakan Maven atau Gradle untuk Pengurusan Projek Java Lanjutan, Membina Automasi, dan Resolusi Ketergantungan?Mar 17, 2025 pm 05:46 PMArtikel ini membincangkan menggunakan Maven dan Gradle untuk Pengurusan Projek Java, membina automasi, dan resolusi pergantungan, membandingkan pendekatan dan strategi pengoptimuman mereka.
 Bagaimanakah saya membuat dan menggunakan perpustakaan Java Custom (fail JAR) dengan pengurusan versi dan pergantungan yang betul?Mar 17, 2025 pm 05:45 PM
Bagaimanakah saya membuat dan menggunakan perpustakaan Java Custom (fail JAR) dengan pengurusan versi dan pergantungan yang betul?Mar 17, 2025 pm 05:45 PMArtikel ini membincangkan membuat dan menggunakan perpustakaan Java tersuai (fail balang) dengan pengurusan versi dan pergantungan yang betul, menggunakan alat seperti Maven dan Gradle.
 Bagaimanakah saya melaksanakan caching pelbagai peringkat dalam aplikasi java menggunakan perpustakaan seperti kafein atau cache jambu?Mar 17, 2025 pm 05:44 PM
Bagaimanakah saya melaksanakan caching pelbagai peringkat dalam aplikasi java menggunakan perpustakaan seperti kafein atau cache jambu?Mar 17, 2025 pm 05:44 PMArtikel ini membincangkan pelaksanaan caching pelbagai peringkat di Java menggunakan kafein dan cache jambu untuk meningkatkan prestasi aplikasi. Ia meliputi persediaan, integrasi, dan faedah prestasi, bersama -sama dengan Pengurusan Dasar Konfigurasi dan Pengusiran PRA Terbaik
 Bagaimanakah saya boleh menggunakan JPA (Java Constence API) untuk pemetaan objek-objek dengan ciri-ciri canggih seperti caching dan malas malas?Mar 17, 2025 pm 05:43 PM
Bagaimanakah saya boleh menggunakan JPA (Java Constence API) untuk pemetaan objek-objek dengan ciri-ciri canggih seperti caching dan malas malas?Mar 17, 2025 pm 05:43 PMArtikel ini membincangkan menggunakan JPA untuk pemetaan objek-relasi dengan ciri-ciri canggih seperti caching dan pemuatan malas. Ia meliputi persediaan, pemetaan entiti, dan amalan terbaik untuk mengoptimumkan prestasi sambil menonjolkan potensi perangkap. [159 aksara]
 Bagaimanakah mekanisme kelas muatan Java berfungsi, termasuk kelas yang berbeza dan model delegasi mereka?Mar 17, 2025 pm 05:35 PM
Bagaimanakah mekanisme kelas muatan Java berfungsi, termasuk kelas yang berbeza dan model delegasi mereka?Mar 17, 2025 pm 05:35 PMKelas kelas Java melibatkan pemuatan, menghubungkan, dan memulakan kelas menggunakan sistem hierarki dengan bootstrap, lanjutan, dan pemuat kelas aplikasi. Model delegasi induk memastikan kelas teras dimuatkan dahulu, yang mempengaruhi LOA kelas tersuai


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

