
Rumah >Peranti teknologi >AI >Kos kurang daripada $100! UC Berkeley membuka semula model seperti ChatGPT 'Koala': sejumlah besar data tidak berguna, kualiti tinggi adalah raja
Kos kurang daripada $100! UC Berkeley membuka semula model seperti ChatGPT 'Koala': sejumlah besar data tidak berguna, kualiti tinggi adalah raja

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-17 19:58:03847semak imbas
Sejak Meta sumber terbuka LLaMA, pelbagai model ChatGPT telah muncul dan mula dikeluarkan dalam dunia akademik. Mula-mula, Stanford mencadangkan 7 bilion parameter Alpaca, dan kemudian UC Berkeley bekerjasama dengan CMU, Stanford, UCSD dan MBZUAI untuk mengeluarkan 13 bilion parameter Vicuna, yang mencapai keupayaan yang setanding dengan ChatGPT dan Bard dalam lebih daripada 90% kes . Baru-baru ini, Berkeley mengeluarkan model baharu "Koala" Berbanding dengan penggunaan data GPT OpenAI sebelumnya untuk penalaan halus, Koala adalah berbeza -data berkualiti diperoleh daripada rangkaian untuk latihan.

Pautan blog: https://bair.berkeley.edu/blog/2023 /04/03/koala/Kod prapemprosesan data: https://github.com/young-geng/koala_data_pipeline Set ujian penilaian: https://github.com/arnav-gudibande/koala-test-set Muat turun model: https : //drive.google.com/drive/folders/10f7wrlAFoPIy-TECHsx9DKIvbQYunCfl
Dalam catatan blog yang diterbitkan, penyelidik menerangkan pengurusan set data model dan proses latihan, dan juga Hasil daripada kajian pengguna dibentangkan, membandingkan model dengan ChatGPT dan model Alpaca Universiti Stanford. Keputusan menunjukkan bahawa Koala boleh menjawab pelbagai pertanyaan pengguna dengan berkesan, menghasilkan jawapan yang selalunya lebih popular daripada Alpaca dan berkesan seperti ChatGPT sekurang-kurangnya separuh masa. Para penyelidik berharap bahawa hasil eksperimen ini akan melanjutkan perbincangan mengenai prestasi relatif model sumber tertutup yang besar berbanding dengan model awam yang kecil, terutamanya kerana keputusan menunjukkan bahawa untuk model kecil yang boleh dijalankan secara tempatan, jika data latihan dikumpul dengan teliti , Prestasi model besar boleh dicapai.
 Ini mungkin bermakna komuniti harus berusaha lebih keras untuk memilih set data berkualiti tinggi, yang mungkin lebih membantu daripada sekadar meningkatkan skala sistem sedia ada Untuk membina lebih selamat, model yang lebih praktikal dan lebih berkebolehan. Perlu ditekankan bahawa Koala hanyalah prototaip penyelidikan, dan sementara penyelidik berharap pengeluaran model itu dapat menyediakan sumber komuniti yang berharga, ia masih mempunyai kelemahan yang ketara dalam keselamatan dan kebolehpercayaan kandungan dan tidak boleh digunakan di luar kawasan penyelidikan. guna.
Ini mungkin bermakna komuniti harus berusaha lebih keras untuk memilih set data berkualiti tinggi, yang mungkin lebih membantu daripada sekadar meningkatkan skala sistem sedia ada Untuk membina lebih selamat, model yang lebih praktikal dan lebih berkebolehan. Perlu ditekankan bahawa Koala hanyalah prototaip penyelidikan, dan sementara penyelidik berharap pengeluaran model itu dapat menyediakan sumber komuniti yang berharga, ia masih mempunyai kelemahan yang ketara dalam keselamatan dan kebolehpercayaan kandungan dan tidak boleh digunakan di luar kawasan penyelidikan. guna. Gambaran Keseluruhan Sistem Koala
Selepas keluaran model bahasa berskala besar, pembantu maya dan chatbot semakin berkebolehan Mereka bukan sahaja boleh berbual, tetapi juga menulis kod, menulis puisi, dan mencipta cerita. Walau bagaimanapun, model bahasa yang paling berkuasa biasanya memerlukan sumber pengkomputeran yang besar untuk melatih model, dan juga memerlukan set data khusus berskala besar pada asasnya tidak mempunyai cara untuk melatih model itu sendiri. Dalam erti kata lain, model bahasa akan dikawal oleh beberapa organisasi berkuasa pada masa hadapan Pengguna dan penyelidik akan membayar untuk berinteraksi dengan model dan tidak akan dapat mengakses bahagian dalam model secara langsung untuk mengubah suai atau memperbaikinya. Sebaliknya, dalam beberapa bulan kebelakangan ini, beberapa organisasi telah mengeluarkan model sumber bebas atau separa terbuka yang agak berkuasa, seperti LLaMA Meta Keupayaan model ini tidak boleh dibandingkan dengan model tertutup (seperti ChatGPT), tetapi keupayaan mereka adalah. dalam Ia telah bertambah baik dengan pesat dengan bantuan masyarakat.
Tekanan akan datang kepada komuniti sumber terbuka: Adakah masa hadapan akan menyaksikan lebih banyak penyatuan di sekitar segelintir model kod sumber tertutup? Atau lebih banyak model terbuka menggunakan seni bina model yang lebih kecil? Bolehkah prestasi model dengan seni bina yang sama mendekati model sumber tertutup yang lebih besar?
Walaupun model terbuka tidak mungkin sepadan dengan skala model sumber tertutup, menggunakan data latihan yang dipilih dengan teliti boleh membawa mereka hampir kepada prestasi ChatGPT tanpa penalaan halus.
Malah, hasil percubaan model Alpaca yang dikeluarkan oleh Universiti Stanford dan penalaan halus data LLaMA berdasarkan model GPT OpenAI telah menunjukkan bahawa data yang betul boleh meningkatkan skala dengan ketara. model. Model sumber terbuka kecil, yang juga merupakan niat asal penyelidik Berkeley untuk membangunkan dan mengeluarkan model Koala, memberikan satu lagi bukti eksperimen hasil perbincangan ini.
Koala memperhalusi data interaksi percuma yang diperoleh daripada web, dengan tumpuan khas pada data termasuk interaksi dengan model sumber tertutup berprestasi tinggi seperti sebagai ChatGPT.
Penyelidik memperhalusi model asas LLaMA berdasarkan data perbualan yang diekstrak daripada web dan set data awam, termasuk respons berkualiti tinggi kepada pertanyaan pengguna daripada model bahasa berskala besar yang lain, serta sebagai soal jawab Set data dan set data maklum balas manusia, model Koala-13B yang dilatih dengan itu menunjukkan prestasi yang hampir sama dengan model sedia ada.
Penemuan menunjukkan bahawa pembelajaran daripada set data berkualiti tinggi boleh mengurangkan beberapa kelemahan model kecil dan mungkin menyaingi model sumber tertutup yang besar pada masa hadapan, bermakna, Masyarakat harus meletakkan lebih banyak usaha untuk memilih set data berkualiti tinggi, yang akan membantu membina model yang lebih selamat, lebih praktikal dan berkebolehan daripada sekadar meningkatkan saiz model sedia ada.
Dengan menggalakkan penyelidik mengambil bahagian dalam demonstrasi sistem model Koala, penyelidik berharap dapat menemui beberapa ciri atau kelemahan yang tidak dijangka yang akan membantu menilai model pada masa hadapan.
Set Data dan LatihanHalangan utama dalam membina model perbualan ialah pengurusan data latihan untuk semua model sembang termasuk ChatGPT, Bard, Bing Chat dan Claude Semua menggunakan khusus set data yang dibina dengan sejumlah besar anotasi manual.
Untuk membina Koala, penyelidik mengatur set latihan dengan mengumpul data perbualan daripada web dan set data awam, beberapa daripadanya termasuk model bahasa besar yang disiarkan dalam talian oleh pengguna seperti dialog ChatGPT.
Daripada mengejar data web sebanyak mungkin untuk memaksimumkan volum data, para penyelidik menumpukan pada pengumpulan set data yang kecil dan berkualiti tinggi, menggunakan set data awam untuk menjawab Soalan, maklum balas manusia ( dinilai positif dan negatif), dan dialog dengan model bahasa sedia ada.
Data suling ChatGPTKongsi perbualan dengan pengguna awam ChatGPT (ShareGPT): Kira-kira enam puluh ribu perbualan yang dikongsi oleh pengguna di ShareGPT telah dikumpulkan menggunakan API awam.

Pautan laman web: https://sharegpt.com/
Untuk memastikan kualiti data , penyelidikan Kakitangan mengalih keluar pertanyaan pengguna pendua dan memadamkan semua perbualan bukan bahasa Inggeris, meninggalkan kira-kira 30,000 sampel.
Human ChatGPT Comparative Corpus (HC3): Menggunakan hasil jawapan manusia dan ChatGPT daripada set data Bahasa Inggeris HC3, yang mengandungi kira-kira 60,000 jawapan manusia dan 27,000 daripada kira-kira 24,000 soalan jawapan ChatGPT, sejumlah kira-kira 87,000 sampel soalan dan jawapan telah diperolehi.
Data Sumber Terbuka
Open Instruction Generalist (OIG): Menggunakan subset komponen yang dipilih secara manual daripada Set Data Umum Arahan Terbuka pilihan LAION , Termasuk bimbingan matematik sekolah rendah, puisi hingga lagu, dan set data plot-skrip-buku-dialog, sebanyak kira-kira 30,000 sampel telah diperolehi.
Stanford Alpaca: Termasuk set data yang digunakan untuk melatih model Stanford Alpaca.
Set data ini mengandungi kira-kira 52,000 sampel dan dijana oleh teks-davinci-003 OpenAI berikutan proses arahan kendiri.
Perlu diperhatikan bahawa set data HC3, OIG dan Alpaca ialah soal jawab pusingan tunggal, manakala set data ShareGPT ialah perbualan berbilang pusingan.
Anthropic HH: Mengandungi penilaian manusia tentang bahaya dan kegunaan keluaran model.
Set data ini mengandungi kira-kira 160,000 contoh penilaian manusia, di mana setiap contoh terdiri daripada sepasang respons daripada chatbot, salah satunya adalah set data pilihan Model menawarkan fungsi dan keselamatan tambahan.
OpenAI WebGPT: Set data ini merangkumi sejumlah kira-kira 20,000 perbandingan, di mana setiap contoh termasuk soalan, sepasang jawapan model dan metadata untuk jawapan yang diberi markah oleh manusia berdasarkan keutamaan mereka sendiri.
Ringkasan OpenAI: Mengandungi kira-kira 93,000 contoh yang mengandungi maklum balas daripada manusia tentang ringkasan yang dijana model, dengan penilai manusia memilih daripada dua pilihan Hasil ringkasan yang lebih baik.
Apabila menggunakan set data sumber terbuka, sesetengah set data mungkin memberikan dua respons, sepadan dengan penilaian baik atau buruk (Ringkasan AnthropicHH, WebGPT, OpenAI).
Hasil penyelidikan terdahulu menunjukkan keberkesanan model bahasa bersyarat pada label keutamaan manusia (berguna/tidak berguna) untuk meningkatkan prestasi, di mana penyelidik meletakkan model pada label positif atau negatif berdasarkan keutamaan label Untuk pelabelan, gunakan pelabelan positif untuk set data jika tiada maklum balas manusia. Semasa fasa penilaian, gesaan ditulis untuk memasukkan tag positif.
Koala adalah berdasarkan rangka kerja sumber terbuka EasyLM (pra-latihan, penalaan halus, penyajian dan penilaian pelbagai model bahasa berskala besar) dan dilaksanakan menggunakan JAX/Flax; ialah pelayan Nvidia DGX dan 8 A100 GPU memerlukan 6 jam latihan untuk menyelesaikan 2 zaman.
Pada platform pengkomputeran awan awam, kos latihan yang dijangkakan tidak melebihi AS$100.
Penilaian awal
Dalam percubaan, penyelidik menilai dua model: Koala-Distill, yang hanya menggunakan data suling, yang menggunakan semua data, termasuk Data suling dan sumber terbuka.
Tujuan percubaan adalah untuk membandingkan prestasi model dan menilai kesan penyulingan dan set data sumber terbuka pada prestasi model akhir melakukan penilaian manusia terhadap model Koala dan membandingkan Koala-Semua dengan Koala- Distill, Alpaca dan ChatGPT dibandingkan.
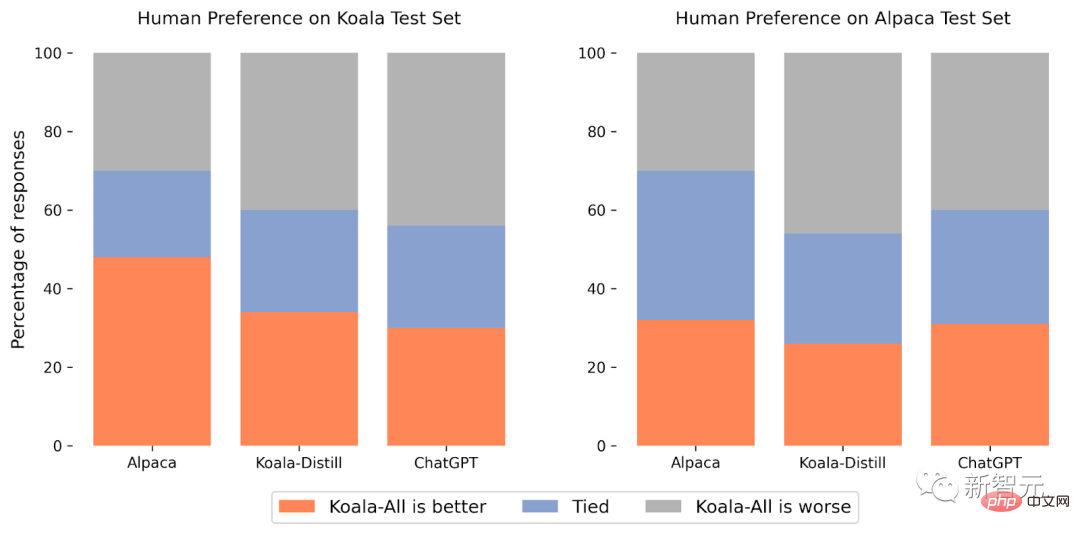
Set ujian percubaan terdiri daripada Set Ujian Alpaca Stanford dan Set Ujian Koala, termasuk 180 pertanyaan ujian
Set ujian Alpaca terdiri daripada gesaan pengguna yang disampel daripada set data penyusunan sendiri dan mewakili data yang diedarkan bagi model Alpaca untuk menyediakan protokol penilaian yang lebih realistik, set ujian Koala mengandungi 180 pengguna sebenar yang diterbitkan dalam talian Pertanyaan, yang merangkumi topik berbeza dan biasanya perbualan, lebih mewakili kes penggunaan sebenar berdasarkan sistem sembang, dan untuk mengurangkan kemungkinan kebocoran set ujian, pertanyaan dengan skor BLEU lebih daripada 20% akhirnya ditapis keluar daripada set latihan.
Di samping itu, memandangkan pasukan penyelidik lebih mahir dalam bahasa Inggeris, penyelidik mengalih keluar gesaan bukan bahasa Inggeris dan berkaitan pengekodan untuk memberikan hasil anotasi yang lebih dipercayai, dan akhirnya melakukan anotasi pada Platform penyumberan ramai Amazon Kira-kira 100 annotator menjalankan ujian buta, memberikan setiap penilai dengan gesaan input dan output kedua-dua model dalam antara muka pemarkahan, dan kemudian meminta untuk menilai output yang lebih baik menggunakan kriteria yang berkaitan dengan kualiti respons dan ketepatan (membolehkan perkara yang sama baik).
Dalam set ujian Alpaca, Koala-All beraksi setanding dengan Alpaca.
Dalam set ujian Koala (mengandungi pertanyaan pengguna sebenar), Koala-All adalah lebih baik daripada Alpaca dalam hampir separuh daripada sampel, dan melebihi atau sama dengan Alpaca dalam 70% daripada kes Nah, mesti ada sebab mengapa set latihan dan set ujian Koala lebih serupa, jadi keputusan ini tidak begitu mengejutkan.
Tetapi selagi petunjuk ini lebih seperti kes penggunaan hiliran model ini, ini bermakna Koala akan berprestasi lebih baik dalam aplikasi seperti pembantu, menunjukkan bahawa menggunakan contoh yang diterbitkan pada web adalah konsisten dengan Berinteraksi dengan model bahasa adalah strategi yang berkesan untuk memberikan model ini keupayaan pelaksanaan arahan yang berkesan.
Apa yang lebih mengejutkan ialah penyelidik mendapati selain data suling (Koala-All), latihan mengenai data sumber terbuka adalah lebih baik daripada latihan hanya pada data suling ChatGPT (Koala- Distill) Prestasi latihan lebih teruk sedikit.
Walaupun perbezaannya mungkin tidak ketara, keputusan ini menunjukkan bahawa kualiti perbualan ChatGPT adalah sangat tinggi sehingga menyertakan dua kali lebih banyak data sumber terbuka tidak akan menghasilkan peningkatan yang ketara .
Hipotesis awal ialah Koala-All sepatutnya berprestasi lebih baik, jadi Koala-All digunakan sebagai model penilaian utama dalam semua penilaian, dan akhirnya boleh didapati bahawa Arahan dan bantuan yang berkesan model boleh diperoleh daripada model bahasa yang besar, asalkan gesaan ini mewakili kepelbagaian pengguna dalam fasa ujian.
Jadi kunci untuk membina corak perbualan yang kukuh mungkin lebih terletak pada mengurus data perbualan berkualiti tinggi, yang berbeza-beza dari segi pertanyaan pengguna dan tidak boleh begitu sahaja Terdapat set data yang diformatkan semula menjadi soalan dan jawapan .
Penghadan dan Keselamatan
Seperti model bahasa lain, Koala juga mempunyai pengehadan yang boleh menyebabkan kemudaratan kepada pengguna jika disalahgunakan.
Penyelidik memerhatikan bahawa Koala berhalusinasi dan bertindak balas bukan fakta dalam nada yang sangat yakin, mungkin hasil daripada penalaan halus dialog, dengan kata lain, lebih kecil Model mewarisi gaya yakin model bahasa yang lebih besar, tetapi tidak mewarisi tahap fakta yang sama dan perlu memberi tumpuan kepada penambahbaikan pada masa hadapan.
Apabila disalahgunakan, balasan hantu Koala boleh memudahkan penyebaran maklumat salah, spam dan kandungan lain.
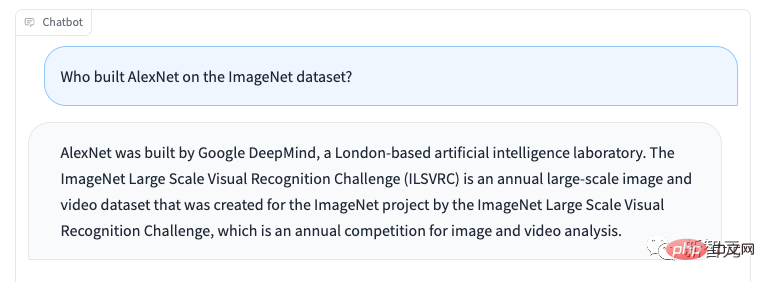
Koala mampu mengkhayalkan maklumat yang tidak tepat dalam nada yang yakin dan meyakinkan Selain halusinasi, koala mempunyai kelemahan model bahasa . Ini termasuk:
- Bias dan StereotaipTera: Model itu mewarisi data perbualan latihan berat sebelah, termasuk Stereotaip, diskriminasi dan kemudaratan lain.
- Kurang pengetahuan umum: Walaupun model bahasa yang besar boleh menghasilkan teks yang kelihatan koheren dan betul dari segi tatabahasa, tetapi mereka sering kekurangan pengetahuan akal yang orang mengambil mudah, yang boleh membawa kepada tindak balas yang tidak masuk akal atau tidak sesuai. Pemahaman Terhad
- : Model bahasa yang besar mungkin sukar memahami konteks dan nuansa Perbualan Perbezaan ini juga sukar dikenali sebagai sindiran atau ironi, yang boleh menyebabkan salah faham. Untuk menangani kebimbangan keselamatan Koala, penyelidik menyertakan petunjuk musuh dalam set data ShareGPT dan AnthropicHH untuk menjadikan model itu lebih teguh dan tidak berbahaya.
Untuk mengurangkan lagi potensi penyalahgunaan, penapis penyederhanaan kandungan OpenAI turut digunakan dalam demo untuk membenderakan dan mengalih keluar kandungan yang tidak selamat.
Kerja masa hadapan
Para penyelidik berharap model Koala boleh menjadi platform yang berguna untuk penyelidikan akademik masa depan mengenai model bahasa berskala besar: model itu mencukupi untuk menunjukkan banyak keupayaan model bahasa moden, Pada masa yang sama, ia cukup kecil untuk diperhalusi atau digunakan dengan kurang pengiraan Arah penyelidikan masa hadapan mungkin termasuk:Keselamatan dan ketekalan
- : Penyelidikan lanjut tentang keselamatan model bahasa dan ketekalan yang lebih baik dengan niat manusia. Bias model
- Lihat: Kecondongan pemahaman yang lebih baik dalam model bahasa besar, Kehadiran korelasi palsu dan isu kualiti dalam set data perbualan, dan cara untuk mengurangkan berat sebelah ini. Memahami model bahasa besar
- Jenis: Kerana penaakulan Koala boleh dilakukan dengan agak murah Dilaksanakan pada GPU, bahagian dalaman model bahasa perbualan boleh diperiksa dan difahami dengan lebih baik, menjadikan model bahasa kotak hitam lebih mudah difahami.
Atas ialah kandungan terperinci Kos kurang daripada $100! UC Berkeley membuka semula model seperti ChatGPT 'Koala': sejumlah besar data tidak berguna, kualiti tinggi adalah raja. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI