
Rumah >Peranti teknologi >AI >Stanford, Meta AI Research: Dalam perjalanan ke AGI, pemangkasan data adalah lebih penting daripada yang kita fikirkan
Stanford, Meta AI Research: Dalam perjalanan ke AGI, pemangkasan data adalah lebih penting daripada yang kita fikirkan

- PHPzke hadapan
- 2023-04-17 19:04:031219semak imbas
Merentasi banyak bidang pembelajaran mesin, termasuk penglihatan, bahasa dan pertuturan, undang-undang penskalaan saraf menyatakan bahawa ralat ujian secara amnya berkurangan dengan data latihan, saiz model atau bilangan pengiraan. Peningkatan berkadar ini telah mendorong pembelajaran mendalam untuk mencapai peningkatan prestasi yang besar. Walau bagaimanapun, penambahbaikan yang dicapai melalui penskalaan sahaja datang pada kos yang besar dari segi pengiraan dan tenaga.
Skala berkadar ini tidak mampan. Contohnya, menurunkan ralat daripada 3% kepada 2% memerlukan lebih banyak data, pengiraan atau tenaga secara eksponen. Beberapa kajian terdahulu telah menunjukkan bahawa mengurangkan kehilangan rentas entropi daripada 3.4 kepada 2.8 dalam pemodelan bahasa dengan Transformer besar memerlukan 10 kali lebih banyak data latihan. Tambahan pula, untuk Transformers visual yang besar, tambahan 2 bilion mata data pra-latihan (bermula dari 1 bilion) hanya menghasilkan keuntungan ketepatan beberapa mata peratusan pada ImageNet.
Semua keputusan ini menerangkan sifat data dalam pembelajaran mendalam, sambil menunjukkan bahawa amalan mengumpul set data yang besar boleh menjadi tidak cekap. Perbincangan di sini ialah sama ada kita boleh melakukan yang lebih baik. Sebagai contoh, bolehkah kita mencapai penskalaan eksponen dengan strategi yang baik untuk memilih sampel latihan?
Dalam artikel baru-baru ini, penyelidik mendapati bahawa hanya menambah beberapa sampel latihan yang dipilih dengan teliti boleh mengurangkan ralat daripada 3% kepada 2% tanpa mengumpul 10 kali lebih sampel rawak . Pendek kata, "Jualan bukan semua yang anda perlukan".

Pautan kertas: https://arxiv.org/pdf/2206.14486.pdf
Secara keseluruhannya, sumbangan penyelidikan ini ialah:
1. Menggunakan mekanik statistik, teori analisis pemangkasan data baru dibangunkan Dalam persekitaran pembelajaran perceptron guru-murid, sampel dipangkas mengikut margin guru mereka, dan margin besar (kecil) masing-masing sepadan dengan mudah ( Kesukaran). sampel. Teori secara kuantitatif bersetuju dengan eksperimen berangka dan mendedahkan dua ramalan yang mengejutkan:
a Strategi pemangkasan optimum berubah dengan jumlah data awal jika data awal banyak (jarang), maka Hanya sampel yang sukar (mudah). hendaklah dikekalkan.
b. Jika skor pemangkasan optimum Pareto yang meningkat dipilih sebagai fungsi saiz set data awal, maka penskalaan eksponen mungkin untuk saiz set data yang dipangkas.

2. Penyelidikan menunjukkan bahawa kedua-dua ramalan ini berlaku dalam amalan dalam tetapan yang lebih umum. Mereka mengesahkan ciri penskalaan eksponen ralat berkenaan dengan saiz set data yang dipangkas untuk ResNets yang dilatih dari awal pada SVHN, CIFAR-10 dan ImageNet, dan untuk Transformer visual yang diperhalusi pada CIFAR-10.
3 Menjalankan kajian penanda aras berskala besar ke atas 10 metrik pemangkasan data yang berbeza di ImageNet dan mendapati kebanyakan metrik berprestasi buruk kecuali yang paling intensif dari segi pengiraan.
4. Metrik pemangkasan tanpa pengawasan kos rendah baharu dibangunkan menggunakan pembelajaran diselia sendiri, yang tidak seperti metrik sebelumnya tidak memerlukan label. Kami menunjukkan bahawa langkah tanpa pengawasan ini adalah setanding dengan langkah pemangkasan diselia terbaik, yang memerlukan label dan lebih banyak pengiraan. Keputusan ini mendedahkan kemungkinan menggunakan model asas pra-terlatih untuk memangkas set data baharu.
Adakah skala sahaja yang anda perlukan?
Teori pemangkasan data perceptron penyelidik mencadangkan tiga ramalan yang mengejutkan, yang boleh diuji dalam persekitaran yang lebih umum, seperti rangkaian saraf dalam yang dilatih pada penanda aras:
( 1) Berbanding dengan pemangkasan data rawak , apabila set data awal agak besar, adalah berfaedah untuk mengekalkan hanya sampel yang paling sukar, tetapi apabila set data awal agak kecil, ini berbahaya
(2) Secara rawak Sebagai set data awal saiz bertambah, pemangkasan data dengan mengekalkan pecahan tetap f daripada sampel yang paling sukar harus menghasilkan penskalaan undang-undang kuasa dengan eksponen bersamaan dengan pemangkasan rawak
(3) Apabila saiz set data awal dan semua Mengoptimumkan ujian ralat pada pecahan data yang disimpan boleh dicapai dengan melakukan pemangkasan yang lebih agresif pada set data awal yang lebih besar, menjejaki sampul bawah Pareto-optimum, memutuskan hubungan antara ralat ujian dan saiz set data yang dipangkas Hubungan fungsi penskalaan undang-undang antara
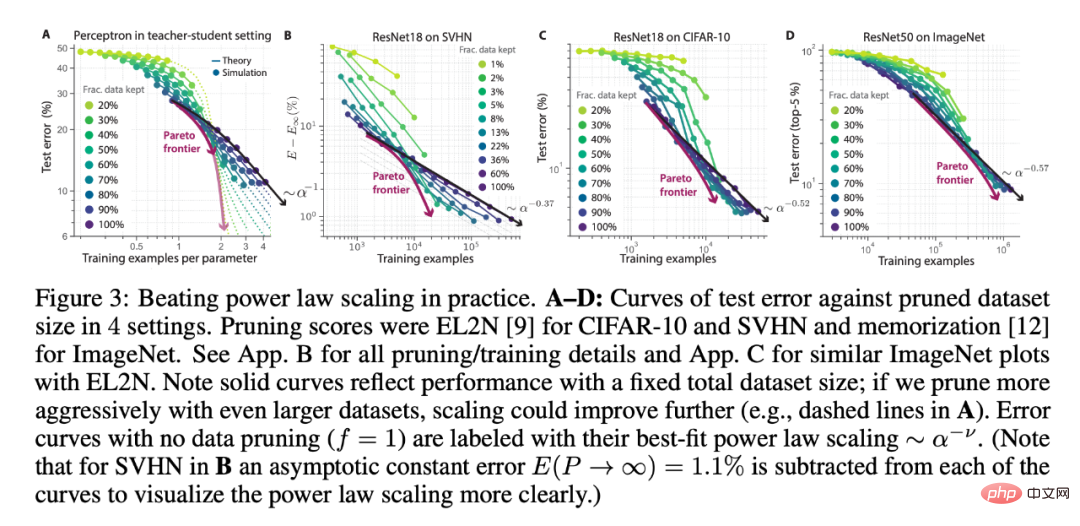
Para penyelidik menggunakan bilangan saiz set data awal yang berbeza dan pecahan data yang disimpan di bawah pemangkasan data (teori dalam Rajah 3A vs. eksperimen pembelajaran mendalam dalam Rajah 3BCD), ResNets dilatih pada SVHN, CIFAR-10 dan ImageNet mengesahkan tiga ramalan di atas. Dalam setiap tetapan percubaan, dapat dilihat bahawa saiz set data awal yang lebih besar dan pemangkasan yang lebih agresif berprestasi lebih baik daripada penskalaan undang-undang kuasa. Selain itu, set data awal yang lebih besar mungkin melihat penskalaan yang lebih baik (Rajah 3A).
Selain itu, penyelidik mendapati pemangkasan data boleh meningkatkan prestasi pembelajaran pemindahan. Mereka mula-mula menganalisis ViT pralatihan pada ImageNet21K dan kemudian diperhalusi pada subset pemangkasan CIFAR-10 yang berbeza. Menariknya, model pralatihan membenarkan pemangkasan data yang lebih agresif; hanya 10% daripada penalaan halus CIFAR-10 sepadan atau melebihi prestasi yang dicapai oleh semua penalaan halus CIFAR-10 (Rajah 4A). Selain itu, Rajah 4A menyediakan sampel pemecahan penskalaan undang-undang kuasa dalam tetapan yang diperhalusi.

Dengan pra-latihan ResNet50 pada subset pemangkasan berbeza ImageNet1K (ditunjukkan dalam Rajah 3D), para penyelidik mengkaji keberkesanan pemangkasan data pra-latihan, dan kemudian menggunakan CIFAR Perhalusi mereka pada -10. Seperti yang ditunjukkan dalam Rajah 4B, pralatihan pada sekurang-kurangnya 50% ImageNet dapat memadankan atau melebihi prestasi CIFAR-10 yang dicapai dengan pralatihan pada semua ImageNet.
Oleh itu, pemangkasan data pra-latihan tugas huluan masih boleh mengekalkan prestasi tinggi pada tugas hiliran yang berbeza. Secara keseluruhan, keputusan ini menunjukkan janji pemangkasan dalam pembelajaran pemindahan semasa fasa pra-latihan dan penalaan halus.
Menanda aras metrik pemangkasan diselia pada ImageNet
Para penyelidik mendapati bahawa kebanyakan eksperimen pemangkasan data adalah pada set data berskala kecil (iaitu, varian MNIST dan CIFAR ) pada. Oleh itu, beberapa metrik pemangkasan yang dicadangkan untuk ImageNet jarang dibandingkan dengan garis dasar yang direka pada set data yang lebih kecil.
Oleh itu, tidak jelas bagaimana kebanyakan kaedah pemangkasan berskala kepada ImageNet dan kaedah mana yang terbaik. Untuk menyiasat kesan teori kualiti metrik pemangkasan terhadap prestasi, kami memutuskan untuk mengisi jurang pengetahuan ini dengan menjalankan penilaian sistematik 8 metrik pemangkasan diselia berbeza pada ImageNet.

Mereka memerhatikan perbezaan prestasi yang ketara antara metrik: Rajah 5BC menunjukkan prestasi ujian apabila sebahagian daripada sampel paling sukar di bawah setiap metrik dikekalkan dalam set latihan. Banyak metrik mencapai kejayaan pada set data yang lebih kecil, tetapi apabila memilih subset latihan yang jauh lebih kecil (seperti 80% daripada Imagenet), hanya sebilangan kecil yang masih mencapai prestasi yang setanding apabila dilatih pada set data penuh.
Walau bagaimanapun, kebanyakan langkah masih mengatasi prestasi pemangkasan rawak (Rajah 5C). Penyelidik mendapati bahawa semua metrik pemangkasan menguatkan ketidakseimbangan kelas, mengakibatkan kemerosotan prestasi. Untuk menangani isu ini, pengarang menggunakan kadar baki kelas 50% yang mudah dalam semua percubaan ImageNet.
Pemangkasan data yang diselia sendiri melalui metrik prototaip
Seperti yang ditunjukkan dalam Rajah 5, banyak metrik pemangkasan data tidak berskala dengan baik kepada ImageNet, dan sebahagian daripadanya sememangnya intensif dari segi pengiraan. Selain itu, semua metrik ini memerlukan anotasi, yang mengehadkan keupayaan pemangkasan data mereka untuk melatih model asas berskala besar pada set data besar yang tidak berlabel. Oleh itu, kami jelas memerlukan metrik pemangkasan yang mudah, berskala dan diselia sendiri.

Untuk menilai sama ada gugusan yang ditemui oleh metrik adalah konsisten dengan kelas ImageNet, kami membandingkan pertindihannya dalam Rajah 6A. Prestasi langkah-langkah yang diselia dan diselia sendiri adalah serupa apabila mengekalkan lebih daripada 70% data, yang menunjukkan janji pemangkasan diselia sendiri.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Stanford, Meta AI Research: Dalam perjalanan ke AGI, pemangkasan data adalah lebih penting daripada yang kita fikirkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI