
Rumah >pangkalan data >tutorial mysql >Bagaimana untuk mencipta indeks berprestasi tinggi untuk MySQL
Bagaimana untuk mencipta indeks berprestasi tinggi untuk MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-17 18:13:06918semak imbas
1 Asas Indeks
1.1 Fungsi Indeks
Dalam MySQL, apabila mencari data, mula-mula cari nilai yang sepadan dalam indeks, dan kemudian Cari baris data yang sepadan mengikut rekod indeks yang sepadan Jika anda ingin menjalankan pernyataan pertanyaan berikut:
SELECT * FROM USER WHERE uid = 5;
Jika terdapat indeks yang dibina pada uid, MySQL akan menggunakan indeks untuk mencari dahulu. baris dengan uid 5, atau Maksudnya, MySQL mula-mula mencari mengikut nilai pada indeks, dan kemudian mengembalikan semua baris data yang mengandungi nilai tersebut.
1.2 Struktur data yang biasa digunakan untuk indeks MySQL
Indeks MySQL dilaksanakan pada peringkat enjin storan, bukan pada pelayan. Oleh itu, tiada standard pengindeksan bersatu: indeks dalam enjin storan berbeza berfungsi secara berbeza.
1.2.1 B-Tree
Kebanyakan enjin MySQL menyokong jenis indeks B-Tree Walaupun berbilang enjin storan menyokong jenis indeks yang sama, pelaksanaan asasnya mungkin berbeza. Sebagai contoh, InnoDB menggunakan B+Tree.
Enjin storan melaksanakan B-Tree dengan cara yang berbeza, dengan prestasi dan kelebihan yang berbeza. Contohnya, MyISAM menggunakan teknologi mampatan awalan untuk menjadikan indeks lebih kecil, manakala InnoDB menyimpan data mengikut format data asal Indeks MyISAM merujuk kepada baris yang diindeks mengikut lokasi fizikal data, manakala InnoDB menggunakan baris yang diindeks mengikut. komponen.
Semua nilai dalam B-Tree disimpan secara berurutan, dan jarak dari setiap halaman daun ke akar adalah sama. Rajah di bawah secara kasar menggambarkan cara indeks InnoDB berfungsi Struktur yang digunakan oleh MyISAM adalah berbeza. Tetapi pelaksanaan asas adalah serupa.
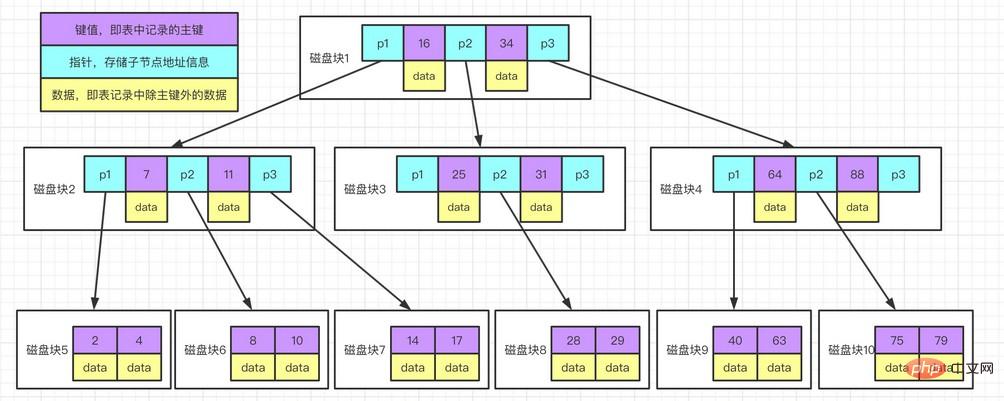
Contoh perihalan rajah:
Setiap nod menduduki satu blok cakera, dan terdapat dua kekunci tertib menaik dan tiga subpohon penunjuk pada satu nod daripada nod akar, yang menyimpan alamat blok cakera di mana nod anak berada. Tiga medan julat dibahagikan dengan dua kata kunci sepadan dengan medan julat data subpokok yang ditunjuk oleh tiga penunjuk. Mengambil nod akar sebagai contoh, kata kunci ialah 16 dan 34, julat data subpokok yang ditunjuk oleh penunjuk P1 adalah kurang daripada 16, julat data subpokok yang ditunjuk oleh penunjuk P2 ialah 16~34, dan data julat subpokok yang ditunjuk oleh penuding P3 adalah lebih besar daripada 34. Proses carian kata kunci:
Cari blok cakera 1 berdasarkan nod akar dan baca ke dalam ingatan. [Kendalian I/O Cakera kali pertama]
Bandingkan kata kunci 28 Dalam selang (16,34), cari penunjuk P2 bagi blok cakera 1.
Cari blok cakera 3 mengikut penuding P2 dan baca ke dalam ingatan. [Operasi I/O Cakera ke-2]
Bandingkan kata kunci 28 dalam selang (25,31), cari penunjuk P2 bagi blok cakera 3.
Cari blok cakera 8 mengikut penuding P2 dan baca ke dalam ingatan. [Operasi I/O Cakera ke-3]
Menjumpai kata kunci 28 dalam senarai kata kunci dalam blok cakera 8.
Kelemahan:
Setiap nod mempunyai kunci dan juga mengandungi data, dan setiap halaman mempunyai ruang storan Ia adalah terhad. Jika data agak besar, bilangan kunci yang disimpan dalam setiap nod akan menjadi lebih kecil; Bilangan masa IO cakera semasa membuat pertanyaan akan menjejaskan prestasi pertanyaan.
1.2.2 B+Tree index
B+ tree ialah varian B-tree. Perbezaan daripada B-tree: B+ tree hanya menyimpan data dalam nod daun, dan nod bukan daun hanya menyimpan nilai dan penunjuk utama.
Terdapat dua penunjuk pada pokok B+, satu menunjuk ke nod daun akar dan satu lagi menghala ke nod daun dengan kata kunci terkecil, dan terdapat struktur cincin rantai antara semua nod daun (iaitu nod data ). Oleh itu, dua operasi carian boleh dilakukan pada pokok B+: satu ialah carian julat untuk komponen, dan satu lagi ialah carian rawak bermula dari nod akar.
Pokok B* serupa dengan nombor B+, bezanya nombor B* juga mempunyai struktur cincin rantai antara nod bukan daun.
1.2.3 Indeks cincang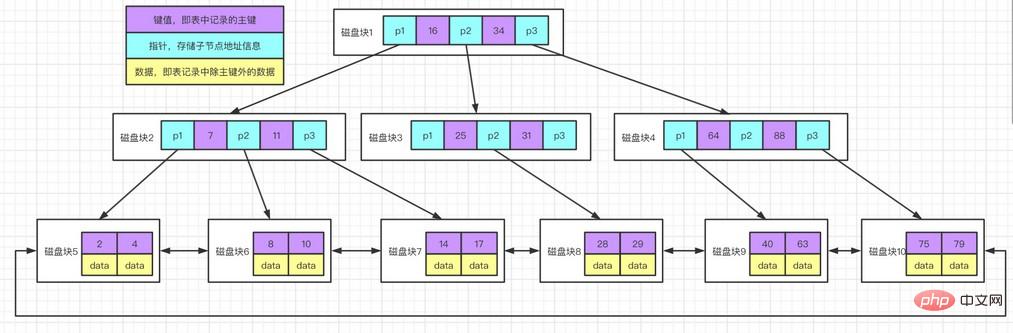 Indeks cincang dilaksanakan berdasarkan jadual cincang Hanya pertanyaan yang sepadan dengan tepat dengan semua lajur indeks yang sah. Untuk setiap baris data, enjin storan akan mengira kod cincang untuk semua lajur indeks Kod cincang adalah nilai yang lebih kecil, dan kod cincang yang dikira untuk baris dengan nilai kunci yang berbeza juga berbeza. Indeks cincang menyimpan semua kod cincang dalam indeks dan penunjuk kepada setiap baris data dalam jadual cincang.
Indeks cincang dilaksanakan berdasarkan jadual cincang Hanya pertanyaan yang sepadan dengan tepat dengan semua lajur indeks yang sah. Untuk setiap baris data, enjin storan akan mengira kod cincang untuk semua lajur indeks Kod cincang adalah nilai yang lebih kecil, dan kod cincang yang dikira untuk baris dengan nilai kunci yang berbeza juga berbeza. Indeks cincang menyimpan semua kod cincang dalam indeks dan penunjuk kepada setiap baris data dalam jadual cincang.
Dalam MySQL, hanya jenis indeks lalai Memory ialah indeks cincang yang digunakan, dan memori juga menyokong indeks B-Tree. Pada masa yang sama, enjin Memori menyokong indeks cincang bukan unik Jika nilai cincang berbilang lajur adalah sama, indeks akan menyimpan berbilang penunjuk dalam entri cincang yang sama dalam senarai terpaut. Sama seperti HashMap.
Kelebihan :
:
Kelemahan:
Jika anda menggunakan storan cincang, anda perlu menambah semua fail data pada memori, yang menggunakan lebih banyak ruang memori; 🎜>
- Data indeks cincang tidak disimpan mengikut susunan, jadi ia tidak boleh digunakan untuk mengisih;
Jika semua pertanyaan adalah pertanyaan setara, maka pencincangan adalah benar-benar pantas, tetapi dalam perusahaan atau persekitaran kerja sebenar, terdapat lebih banyak carian julat data, bukan pertanyaan setara, jadi pencincangan tidak Ia sangat sesuai;
Sekiranya terdapat banyak konflik cincang, kos operasi penyelenggaraan indeks juga akan menjadi sangat tinggi Ini juga merupakan masalah HashMap dengan menambah pokok merah-hitam pada peringkat kemudian untuk diselesaikan masalah konflik Hash;
2 Strategi indeks berprestasi tinggi
2.1 Indeks berkelompok dan indeks tidak berkelompok
Indeks berkelompok
bukan jenis indeks yang berasingan, tetapi kaedah penyimpanan data Dalam enjin storan InnoDB, indeks berkelompok sebenarnya menyimpan nilai utama dan baris data dalam struktur yang sama. Apabila jadual mempunyai indeks berkelompok, baris datanya sebenarnya disimpan dalam halaman daun indeks. Oleh kerana baris data tidak boleh disimpan di tempat yang berbeza pada masa yang sama, hanya boleh terdapat satu indeks berkelompok dalam jadual (liputan indeks boleh mensimulasikan situasi indeks berkelompok berbilang).
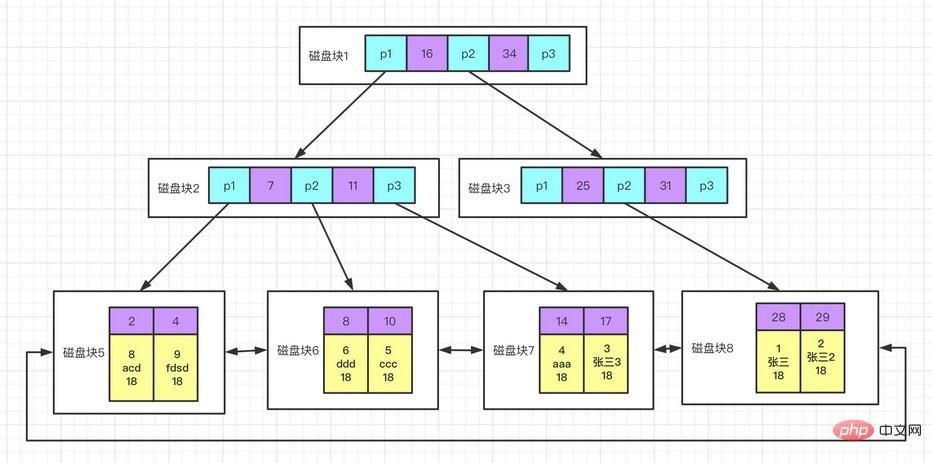
Kelebihan indeks berkelompok:
boleh menyimpan data berkaitan bersama-sama adalah lebih pantas kerana indeks dan data disimpan dalam pepohon yang sama menggunakan meliputi imbasan indeks boleh terus menggunakan nilai kunci utama dalam nod halaman;
Kelemahan:
Data berkelompok memaksimumkan prestasi aplikasi intensif IO jika data semuanya dalam ingatan, kemudian berkelompok indeks tidak mempunyai kelebihan; kelajuan sisipan banyak bergantung pada susunan sisipan, dan memasukkan mengikut urutan kunci utama adalah cara terpantas; lokasi baharu; jadual berdasarkan indeks berkelompok mungkin menghadapi pemisahan halaman apabila baris baharu dimasukkan atau kunci utama dikemas kini dan baris perlu dialihkan boleh menyebabkan imbasan jadual penuh menjadi perlahan, terutamanya perbandingan baris Jarang atau apabila storan data tidak berterusan kerana pemisahan halaman;
Indeks tidak berkelompok
Fail data dan fail indeks disimpan secara berasingan
2.2 Indeks awalan
Kadangkala ia adalah perlu untuk mengindeks rentetan yang sangat panjang, yang akan menjadikan indeks besar dan perlahan Biasanya, anda boleh menggunakan sebahagian daripada rentetan pada permulaan lajur, yang sangat menjimatkan ruang indeks dan meningkatkan kecekapan pengindeksan, tetapi ini akan Mengurangkan selektiviti indeks. Pemilihan indeks merujuk kepada nisbah nilai indeks unik (juga dipanggil kardinaliti) kepada jumlah bilangan rekod jadual data, antara 1/#T hingga 1. Semakin tinggi selektiviti indeks, semakin tinggi kecekapan pertanyaan, kerana indeks yang lebih selektif membolehkan MySQL menapis lebih banyak baris semasa mencari.
Secara amnya, selektiviti awalan lajur tertentu cukup tinggi untuk memenuhi prestasi pertanyaan Walau bagaimanapun, untuk lajur jenis BLOB, TEXT dan VARCHAR, indeks awalan mesti digunakan kerana MySQL tidak membenarkan pengindeksan. daripada ini. Panjang penuh lajur Caranya dengan kaedah ini ialah memilih awalan yang cukup panjang untuk memastikan selektiviti yang tinggi, tetapi tidak terlalu panjang.
Contoh
Struktur jadual dan muat turun data daripada tapak web rasmi MySQL atau GitHub.
Lajur Jadual bandar
| 字段名 | 含义 |
|---|---|
| city_id | 城市主键ID |
| city | 城市名 |
| country_id | 国家ID |
| last_update: | 创建或最近更新时间 |
--计算完整列的选择性
select count(distinct left(city,3))/count(*) as sel3,
count(distinct left(city,4))/count(*) as sel4,
count(distinct left(city,5))/count(*) as sel5,
count(distinct left(city,6))/count(*) as sel6,
count(distinct left(city,7))/count(*) as sel7,
count(distinct left(city,8))/count(*) as sel8
from citydemo;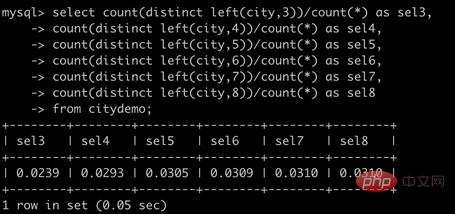
可以看到当前缀长度到达7之后,再增加前缀长度,选择性提升的幅度已经很小了。由此最佳创建前缀索引长度为7。
2.3 回表
要理解回表需要先了解聚族索引和普通索引。聚族索引即建表时设置的主键索引,如果没有设置MySQL自动将第一个非空唯一值作为索引,如果还是没有InnoDB会创建一个隐藏的row-id作为索引(oracle数据库row-id显式展示,可以用于分页);普通索引就是给普通列创建的索引。普通列索引在叶子节点中存储的并不是整行数据而是主键,当按普通索引查找时会先在B+树中查找该列的主键,然后根据主键所在的B+树中查找改行数据,这就是回表。
2.4 覆盖索引
覆盖索引在InnoDB中特别有用。MySQL中可以使用索引直接获取列的数据,如果索引的叶子节点中已经包含要查询的数据,那么就没必要再回表查询了,如果一个索引包含(覆盖)所有需要查询的字段的值,那么该索引就是覆盖索引。简单的说:不回表直接通过一次索引查找到列的数据就叫覆盖索引。
表信息
CREATE TABLE `t_user` ( `uid` int(11) NOT NULL AUTO_INCREMENT, `uname` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`uid`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
举例
--将uid设置成主键索引后通过下面的SQL查询 在explain的Extra列可以看到“Using index” explain select uid from t_user where uid = 1;

覆盖索引在组合索引中用的比较多,举例
explain select age,uname from t_user where age = 10 ;
当不建立组合索引时,会进行回表查询

设置组合索引后再次查询
create index index_user on t_user(age,uname);

2.5 索引匹配方式
2.5.1 最左匹配
在使用组合索引中,比如设置(age,name)为组合索引,单独使用组合索引中最左列是可以匹配索引的,如果不使用最左列则不走索引。例如下面SQL
--走索引 explain select * from t_user where age=10 and uname='zhang';

下面的SQL不走索引
explain select * from t_user where uname='zhang';

2.5.2 匹配列前缀
可以匹配某一列的值的开头部分,比如like 'abc%'。
2.5.3 匹配范围值
可以查找某一个范围的数据。
explain select * from t_user where age>18;

2.5.4 精确匹配某一列并范围匹配另外一列
可以查询第一列的全部和第二列的部分
explain select * from t_user where age=18 and uname like 'zhang%';

2.5.5 只访问索引的查询
查询的时候只需要访问索引,不需要访问数据行,本质上就是覆盖索引。
explain select age,uname,update_time from t_user
where age=18 and uname= 'zhang' and update_time='123';
3 索引优化最佳实践
1. 当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层。
--推荐 select uid,age,uname from t_user where uid=1; --不推荐 select uid,age,uname from t_user where uid+9=10;
2. 尽量使用主键查询,而不是其他索引,因为主键查询不会触发回表查询
3. 使用前缀索引参考2.2 前缀索引
4. 使用索引扫描排序mysql有两种方式可以生成有序的结果:通过排序操作或者按索引顺序扫描,如果explain出来的type列的值为index,则说明mysql使用了索引扫描来做排序。
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那么就不得不每扫描一条索引记录就得回表查询一次对应的行,这基本都是随机IO,因此按索引顺序读取数据的速度通常要比顺序地全表扫描慢。
mysql可以使用同一个索引即满足排序,又用于查找行,如果可能的话,设计索引时应该尽可能地同时满足这两种任务。
只有当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方式都一样时,mysql才能够使用索引来对结果进行排序,如果查询需要关联多张表,则只有当orderby子句引用的字段全部为第一张表时,才能使用索引做排序。order by子句和查找型查询的限制是一样的,需要满足索引的最左前缀的要求,否则,mysql都需要执行顺序操作,而无法利用索引排序。
举例表结构及数据MySQL官网或GItHub下载。
CREATE TABLE `rental` ( `rental_id` int(11) NOT NULL AUTO_INCREMENT, `rental_date` datetime NOT NULL, `inventory_id` mediumint(8) unsigned NOT NULL, `customer_id` smallint(5) unsigned NOT NULL, `return_date` datetime DEFAULT NULL, `staff_id` tinyint(3) unsigned NOT NULL, `last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`rental_id`), UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`), KEY `idx_fk_inventory_id` (`inventory_id`), KEY `idx_fk_customer_id` (`customer_id`), KEY `idx_fk_staff_id` (`staff_id`), CONSTRAINT `fk_rental_customer` FOREIGN KEY (`customer_id`) REFERENCES `customer` (`customer_id`) ON UPDATE CASCADE, CONSTRAINT `fk_rental_inventory` FOREIGN KEY (`inventory_id`) REFERENCES `inventory` (`inventory_id`) ON UPDATE CASCADE, CONSTRAINT `fk_rental_staff` FOREIGN KEY (`staff_id`) REFERENCES `staff` (`staff_id`) ON UPDATE CASCADE ) ENGINE=InnoDB AUTO_INCREMENT=16050 DEFAULT CHARSET=utf8mb4;
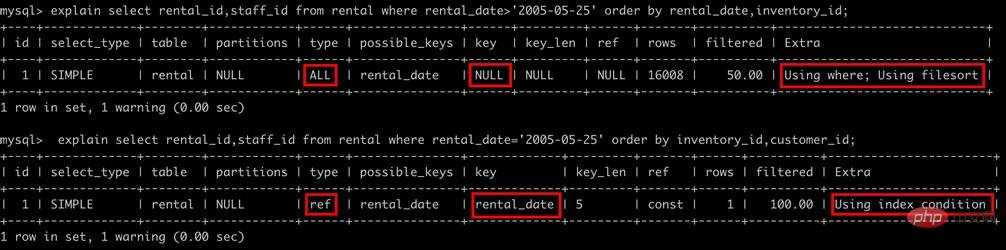
rental表在rental_date,inventory_id,customer_id上有rental_date的索引。使用rental_date索引为下面的查询做排序
--该查询为索引的第一列提供了常量条件,而使用第二列进行排序,将两个列组合在一起,就形成了索引的最左前缀 explain select rental_id,staff_id from rental where rental_date='2005-05-25' order by inventory_id desc --下面的查询不会利用索引 explain select rental_id,staff_id from rental where rental_date>'2005-05-25' order by rental_date,inventory_id
5. union all,in,or都能够使用索引,但是推荐使用in
explain select * from actor where actor_id = 1 union all select * from actor where actor_id = 2; explain select * from actor where actor_id in (1,2); explain select * from actor where actor_id = 1 or actor_id =2;
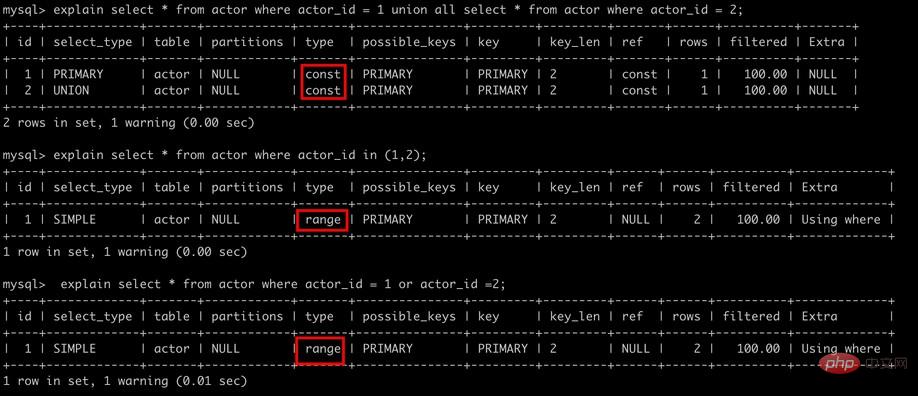
6. 范围列可以用到索引范围条件是:d2714fbb0e49a95306c2048bc19e4f2b、>=、between。范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列。
7. 更新十分频繁,数据区分度不高的字段上不宜建立索引
更新会变更B+树,更新频繁的字段建议索引会大大降低数据库性能;
类似于性别这类区分不大的属性,建立索引是没有意义的,不能有效的过滤数据;
一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算;
8. 创建索引的列,不允许为null,可能会得到不符合预期的结果
9.当需要进行表连接的时候,最好不要超过三张表,如果需要join的字段,数据类型必须一致
10. 能使用limit的时候尽量使用limit
11. 单表索引建议控制在5个以内
12. 单索引字段数不允许超过5个(组合索引)
13. 创建索引的时候应该避免以下错误概念
索引越多越好
过早优化,在不了解系统的情况下进行优化
4 索引监控
show status like 'Handler_read%';
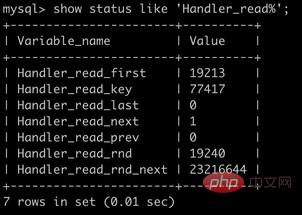
| 参数 | 说明 |
|---|---|
| Handler_read_first | 读取索引第一个条目的次数 |
| Handler_read_key | 通过index获取数据的次数 |
| Handler_read_last | 读取索引最后一个条目的次数 |
| Handler_read_next | 通过索引读取下一条数据的次数 |
| Handler_read_prev | 通过索引读取上一条数据的次数 |
| Handler_read_rnd | 从固定位置读取数据的次数 |
| Handler_read_rnd_next | 从数据节点读取下一条数据的次数 |
Atas ialah kandungan terperinci Bagaimana untuk mencipta indeks berprestasi tinggi untuk MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!