
Rumah >pembangunan bahagian belakang >Tutorial Python >Sembilan perpustakaan Python yang sangat berguna untuk sains data
Sembilan perpustakaan Python yang sangat berguna untuk sains data

- PHPzke hadapan
- 2023-04-17 09:25:081048semak imbas
Dalam artikel ini, kita akan melihat beberapa pustaka Python untuk tugas sains data selain daripada tugasan yang lebih biasa seperti panda, scikit-learn dan matplotlib. Walaupun perpustakaan seperti panda dan scikit-learn biasanya digunakan dalam tugasan pembelajaran mesin, ia sentiasa berfaedah untuk memahami produk Python lain dalam bidang ini.
1. Wget
Mengekstrak data daripada Internet ialah salah satu tugas penting seorang saintis data. Wget ialah utiliti percuma yang boleh digunakan untuk memuat turun fail bukan interaktif dari Internet. Ia menyokong protokol HTTP, HTTPS dan FTP, serta mendapatkan semula fail melalui proksi HTTP. Oleh kerana ia tidak interaktif, ia boleh berfungsi di latar belakang walaupun pengguna tidak log masuk. Jadi lain kali anda ingin memuat turun semua imej pada tapak web atau halaman, wget boleh membantu anda.
Pemasangan:
$ pip install wget
Contoh:
import wget url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3' filename = wget.download(url) 100% [................................................] 3841532 / 3841532 filename 'razorback.mp3'
2. Pendulum
Bagi mereka yang kecewa apabila berurusan dengan tarikh dan masa dalam ular sawa. Orang ramai, Pendulum adalah untuk anda. Ia adalah pakej Python yang memudahkan operasi datetime. Ia adalah pengganti mudah untuk kelas asli Python. Lihat dokumentasi untuk pembelajaran lebih mendalam.
Pemasangan:
$ pip install pendulum
Contoh:
import pendulum dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto') dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver') print(dt_vancouver.diff(dt_toronto).in_hours()) 3
3 tidak seimbang-belajar
Ia boleh dilihat apabila bilangan sampel dalam. setiap kelas Kebanyakan algoritma klasifikasi berfungsi paling baik apabila ia pada asasnya sama, iaitu, keseimbangan data perlu dikekalkan. Walau bagaimanapun, kebanyakan kes dunia sebenar adalah set data yang tidak seimbang, yang mempunyai kesan yang besar pada fasa pembelajaran dan ramalan seterusnya bagi algoritma pembelajaran mesin. Nasib baik, perpustakaan ini direka untuk menyelesaikan masalah ini. Ia serasi dengan scikit-learn dan merupakan sebahagian daripada projek scikit-lear-contrib. Cuba gunakan ini apabila anda menghadapi set data yang tidak seimbang.
Pemasangan:
$ pip install -U imbalanced-learn # 或者 $ conda install -c conda-forge imbalanced-learn
Contoh:
Sila rujuk dokumentasi untuk penggunaan dan contoh.
4. FlashText
Dalam tugasan NLP, membersihkan data teks selalunya memerlukan penggantian kata kunci dalam ayat atau mengekstrak kata kunci daripada ayat. Biasanya ini boleh dilakukan menggunakan ungkapan biasa, tetapi ini boleh menjadi menyusahkan jika bilangan istilah yang dicari mencecah ribuan. Modul FlashText Python adalah berdasarkan algoritma FlashText dan menyediakan alternatif yang sesuai untuk situasi ini. Perkara yang menarik tentang FlashText ialah masa larian adalah sama tanpa mengira bilangan istilah carian. Anda boleh mengetahui lebih lanjut di sini.
Pemasangan:
$ pip install flashtext
Contoh:
Ekstrak kata kunci
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
['New York', 'Bay Area']Ganti kata kunci
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
'I love New York and NCR region.'
FuzzywuzzyLima , fuzzywuzzy
Nama pustaka ini kedengaran pelik, tetapi fuzzywuzzy ialah perpustakaan yang sangat berguna apabila ia berkaitan dengan pemadanan rentetan. Operasi seperti mengira tahap padanan rentetan dan darjah padanan token boleh dilaksanakan dengan mudah, dan rekod yang disimpan dalam pangkalan data yang berbeza juga boleh dipadankan dengan mudah.
Pemasangan:
$ pip install fuzzywuzzy
Contoh:
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# 简单匹配度
fuzz.ratio("this is a test", "this is a test!")
97
# 模糊匹配度
fuzz.partial_ratio("this is a test", "this is a test!")
100Contoh yang lebih menarik boleh didapati dalam repositori GitHub.
6. PyFlux
Analisis siri masa ialah salah satu masalah yang paling biasa dalam bidang pembelajaran mesin. PyFlux ialah perpustakaan sumber terbuka dalam Python yang dibina untuk menangani masalah siri masa. Perpustakaan ini mempunyai koleksi model siri masa moden yang sangat baik, termasuk tetapi tidak terhad kepada model ARIMA, GARCH dan VAR. Ringkasnya, PyFlux menyediakan pendekatan kebarangkalian kepada pemodelan siri masa. Berbaloi mencuba.
Pemasangan
pip install pyflux
Contoh
Sila rujuk dokumentasi rasmi untuk penggunaan dan contoh terperinci.
7. Ipyvolume
Paparan hasil juga merupakan aspek penting dalam sains data. Mampu memvisualisasikan hasilnya akan menjadi kelebihan yang besar. IPyvolume ialah perpustakaan Python yang boleh menggambarkan volum dan grafik 3D (seperti plot serakan 3D, dsb.) dalam buku nota Jupyter dan hanya memerlukan sedikit konfigurasi. Tetapi ia masih dalam peringkat versi pra-1.0. Metafora yang lebih sesuai untuk dijelaskan ialah: Volshow IPyvolume berguna untuk tatasusunan tiga dimensi sebagaimana tayangan matplotlib adalah untuk tatasusunan dua dimensi. Lebih banyak terdapat di sini.
Menggunakan pip
$ pip install ipyvolume
Menggunakan Conda/Anaconda
$ conda install -c conda-forge ipyvolume
Contoh
Animasi
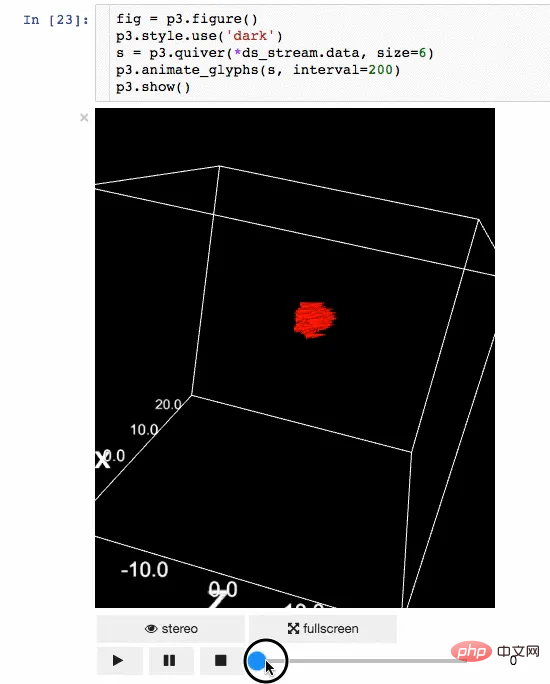
Rendering Volume
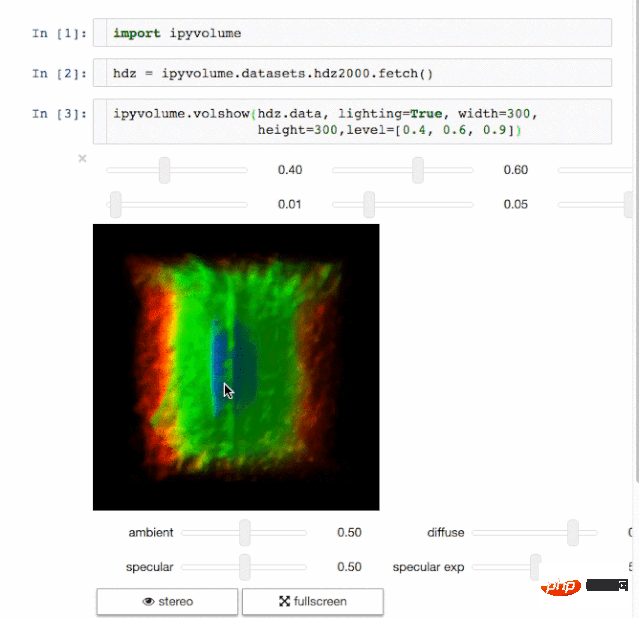
8 Dash
Dash ialah rangka kerja Python yang cekap untuk membina aplikasi web. Ia direka berdasarkan Flask, Plotly.js dan React.js, dan terikat kepada banyak elemen UI moden seperti kotak drop-down, slider dan carta Anda boleh terus menggunakan kod Python untuk menulis analisis yang berkaitan tanpa perlu Menggunakan javascript. Dash bagus untuk membina aplikasi visualisasi data. Aplikasi ini kemudiannya boleh dipaparkan dalam pelayar web. Panduan pengguna boleh didapati di sini.
Pemasangan
pip install dash==0.29.0# 核心 dash 后端 pip install dash-html-components==0.13.2# HTML 组件 pip install dash-core-components==0.36.0# 增强组件 pip install dash-table==3.1.3# 交互式 DataTable 组件(最新!)
Contoh Contoh berikut menunjukkan carta yang sangat interaktif dengan fungsi lungsur turun. Apabila pengguna memilih nilai dalam menu lungsur, kod aplikasi mengeksport data secara dinamik daripada Google Finance ke DataFrame panda.
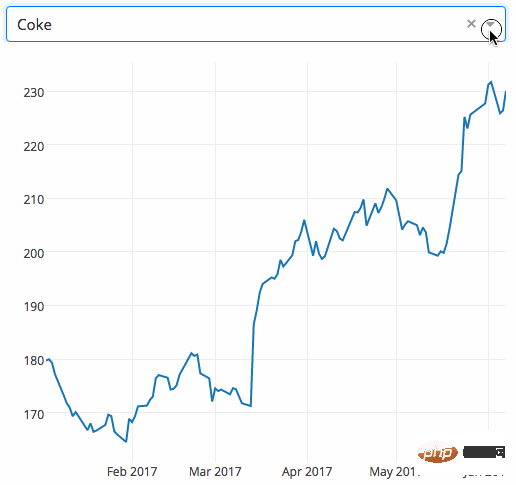
九、Gym
OpenAI 的 Gym 是一款用于增强学习算法的开发和比较工具包。它兼容任何数值计算库,如 TensorFlow 或 Theano。Gym 库是测试问题集合的必备工具,这个集合也称为环境 —— 你可以用它来开发你的强化学习算法。这些环境有一个共享接口,允许你进行通用算法的编写。
安装
pip install gym
例子这个例子会运行CartPole-v0环境中的一个实例,它的时间步数为 1000,每一步都会渲染整个场景。
总结
以上这些有用的数据科学 Python 库都是我精心挑选出来的,不是常见的如 numpy 和 pandas 等库。如果你知道其它库,可以添加到列表中来,请在下面的评论中提一下。另外别忘了先尝试运行一下它们。
Atas ialah kandungan terperinci Sembilan perpustakaan Python yang sangat berguna untuk sains data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!