
Rumah >Peranti teknologi >AI >Gunakan AI untuk membantu ratusan juta orang buta 'melihat dunia' semula!
Gunakan AI untuk membantu ratusan juta orang buta 'melihat dunia' semula!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-16 18:37:031833semak imbas
Dulu, memulihkan penglihatan kepada orang buta sering dianggap sebagai "keajaiban" perubatan.
Dengan penemuan hebat teknologi pintar pelbagai mod yang diwakili oleh "penglihatan mesin + pemahaman bahasa semula jadi", AI telah membawa kemungkinan baharu untuk membantu orang buta, dan lebih ramai orang Buta akan menggunakan persepsi, pemahaman dan keupayaan interaksi yang disediakan oleh AI untuk "melihat dunia" dengan cara lain.
AI membantu orang buta, membenarkan lebih ramai orang "melihat dunia" semula
Secara umumnya, orang cacat penglihatan tidak dapat melihat . Walau bagaimanapun, kajian saintifik menunjukkan bahawa antara maklumat luaran yang diperoleh manusia, penglihatan menyumbang sebanyak 70% hingga 80%.
Oleh itu, membina sistem penglihatan mesin berdasarkan AI untuk membantu pesakit cacat penglihatan mempunyai persepsi visual dan pemahaman visual tentang persekitaran luaran sudah pasti merupakan penyelesaian yang paling langsung dan berkesan.
Dalam bidang persepsi visual, model AI mod tunggal semasa telah melepasi tahap manusia dalam tugas pengecaman imej, tetapi jenis teknologi ini pada masa ini hanya boleh mencapai pengiktirafan dan pengiktirafan dalam modaliti visual . Pemahaman, sukar untuk menyelesaikan pembelajaran silang mod, pemahaman dan penaakulan yang bersilang dengan maklumat deria yang lain, ia hanya boleh dirasakan tetapi tidak difahami.
Atas sebab ini, David Marr, salah seorang pengasas visi pengiraan, mencadangkan isu teras penyelidikan pemahaman visual dalam buku "Vision", percaya bahawa sistem visual harus dibina dalam dua dimensi persekitaran atau perwakilan tiga dimensi dan boleh berinteraksi dengan. Interaksi di sini bermaksud pembelajaran, pemahaman dan penaakulan.
Teknologi bantuan buta AI yang sangat baik sebenarnya adalah projek sistematik yang merangkumi penderiaan pintar, penaakulan niat pengguna yang bijak dan penyampaian maklumat pintar hanya dengan cara ini kebolehcapaian maklumat boleh dibina antara muka interaktif.
Untuk meningkatkan keupayaan generalisasi model AI dan membolehkan mesin mempunyai analisis imej silang mod dan keupayaan pemahaman, algoritma berbilang modal yang diwakili oleh "penglihatan mesin + pemahaman bahasa semula jadi" mula meningkat dan berkembang pesat.
Model algoritma interaksi modal berbilang maklumat ini boleh meningkatkan persepsi, pemahaman dan keupayaan interaksi AI dengan ketara Setelah matang dan digunakan dalam bidang bantuan AI untuk orang buta, ia akan memberi manfaat kepada digital Beratus-ratus juta orang buta boleh "melihat dunia" semula.
Menurut statistik WHO, sekurang-kurangnya 2.2 bilion orang di dunia cacat penglihatan atau buta, dan negara saya adalah negara yang paling ramai buta di dunia, menyumbang 18% -20% daripada jumlah keseluruhan orang buta di dunia Jumlah orang yang baru buta mencecah 450,000 setiap tahun.
"kesan domino" yang disebabkan oleh tugasan soal jawab visual untuk orang buta
Teknologi persepsi perspektif orang pertama sangat penting untuk AI membantu orang buta. Ia tidak memerlukan orang buta untuk melangkah keluar sebagai peserta untuk mengendalikan peranti pintar Sebaliknya, ia boleh bermula dari perspektif sebenar orang buta dan membantu saintis membina model algoritma yang lebih sesuai dengan kognisi orang buta. Ini telah mendorong kemunculan tugas penyelidikan asas menjawab soalan visual untuk orang buta.
Tugas soalan dan jawapan visual untuk orang buta ialah titik permulaan dan salah satu hala tuju penyelidikan teras untuk penyelidikan akademik tentang bantuan AI untuk buta. Walau bagaimanapun, di bawah keadaan teknikal semasa, tugasan soalan dan jawapan visual untuk orang buta, sebagai jenis khas tugasan soalan dan jawapan visual, menghadapi kesukaran yang lebih besar dalam meningkatkan ketepatan berbanding dengan tugasan soalan dan jawapan visual biasa.
Di satu pihak, jenis soalan untuk Soal Jawab visual buta adalah lebih kompleks, termasuk pengesanan sasaran, pengecaman teks, warna, pengecaman atribut dan jenis soalan lain, seperti membezakan daging. dalam peti sejuk, berunding Arahan untuk mengambil ubat, memilih baju berwarna unik, memperkenalkan kandungan buku, dsb.
Sebaliknya, disebabkan keistimewaan orang buta sebagai subjek interaksi persepsi, sukar bagi orang buta untuk memahami jarak antara telefon bimbit dan objek apabila mengambil gambar, selalunya mengakibatkan situasi di luar fokus Atau walaupun objek ditangkap, tidak semuanya ditangkap, atau maklumat penting tidak ditangkap, yang meningkatkan kesukaran pengekstrakan ciri yang berkesan.
Pada masa yang sama, kebanyakan model soalan dan jawapan visual sedia ada adalah berdasarkan latihan data soal jawab dalam persekitaran tertutup Ia amat terhad oleh pengedaran sampel dan sukar untuk dilakukan membuat generalisasi kepada senario bersoal jawab dalam dunia terbuka, adalah perlu untuk menyepadukan pengetahuan luaran untuk penaakulan pelbagai peringkat.

Data soalan dan jawapan visual buta
Kedua, dengan perkembangan soal jawab visual buta penyelidikan, saintis Semasa proses penyelidikan, didapati bahawa menjawab soalan visual akan menghadapi masalah terbitan yang disebabkan oleh gangguan bunyi. Oleh itu, cara mengesan bunyi bising dengan tepat dan menyelesaikan penaakulan pintar juga menghadapi cabaran besar.
Memandangkan orang buta tidak mempunyai persepsi visual tentang dunia luar, mereka sering membuat sejumlah besar ralat dalam tugasan soal jawab visual pada pemadanan teks imej. Sebagai contoh, apabila orang buta pergi membeli-belah di pasar raya, orang buta mudah bertanya soalan yang salah kerana rupa dan rasa produk yang serupa, seperti mengambil sebotol cuka dan bertanya siapa pengeluarnya. kicap je. Kebisingan bahasa seperti ini sering menyebabkan model AI sedia ada gagal, memerlukan AI mempunyai keupayaan untuk menganalisis bunyi dan maklumat yang tersedia daripada persekitaran yang kompleks.
Akhir sekali, sistem bantuan buta AI bukan sahaja harus menjawab keraguan semasa orang buta, tetapi juga mempunyai keupayaan untuk membuat alasan tentang niat pintar dan menyampaikan maklumat pintar, dan teknologi interaksi pintar merupakan satu hala tuju penyelidikan yang penting. Penyelidikan algoritma masih di peringkat awal.
Fokus penyelidikan teknologi penaakulan niat pintar adalah untuk membuat kesimpulan bahawa pengguna cacat penglihatan ingin menyatakan niat interaktif mereka dengan membenarkan mesin mempelajari secara berterusan tabiat bahasa dan tingkah laku pengguna cacat penglihatan. Sebagai contoh, melalui tindakan orang buta memegang cawan air dan duduk, tindakan seterusnya meletakkan cawan air di atas meja boleh diramalkan oleh orang buta yang bertanya tentang warna atau gaya pakaian, ia boleh meramalkan bahawa seseorang boleh melakukan perjalanan, dsb.
Kesukaran teknologi ini adalah disebabkan oleh keacakan dalam ekspresi dan tindakan ekspresi pengguna dalam masa dan ruang, model psikologi pembuatan keputusan interaktif juga mempunyai. cara mengekstrak input maklumat yang berkesan oleh pengguna daripada data tingkah laku rawak berterusan dan mereka bentuk model berbilang modal bukan deterministik dinamik untuk mencapai pembentangan terbaik bagi tugasan yang berbeza adalah sangat kritikal.
Memfokuskan pada penyelidikan asas tentang AI untuk membantu buta, banyak kajian Inspur Information telah diiktiraf di peringkat antarabangsa
Tidak dinafikan bahawa AI adalah penemuan utama dalam asas di atas bidang penyelidikan Kunci kepada pelaksanaan awal teknologi untuk membantu buta. Pada masa ini, pasukan penyelidikan canggih dari Inspur Information sedang berusaha sedaya upaya untuk mempromosikan pembangunan lanjut penyelidikan bantuan buta AI melalui pelbagai inovasi algoritma, model pra-latihan dan pembinaan set data asas.
Dalam bidang penyelidikan tugasan soalan dan jawapan visual untuk orang buta, VizWiz-VQA ialah cabaran soalan dan jawapan visual teratas berbilang mod global untuk orang buta yang dilancarkan bersama oleh sarjana dari Carnegie Mellon University dan institusi lain Set data penglihatan buta "VizWiz" melatih model AI, dan kemudian AI memberikan jawapan kepada pasangan gambar dan teks rawak yang disediakan oleh orang buta. Dalam tugasan soal jawab visual untuk orang buta, Pasukan Penyelidik Sempadan Maklumat Inspur menyelesaikan banyak masalah biasa dalam tugasan soalan dan jawapan visual untuk orang buta.
Pertama sekali, memandangkan gambar yang diambil oleh orang buta adalah kabur dan mempunyai maklumat yang kurang berkesan, soalan biasanya lebih subjektif dan samar untuk memahami tuntutan orang buta dan memberi jawapan.
Pasukan mencadangkan model penjajaran titik anchor multi-modal dwi-strim, yang menggunakan entiti utama dan atribut pengesanan sasaran visual sebagai titik sauh untuk menyambungkan gambar dan soalan untuk mencapai multi-modal peningkatan semantik.
Kedua, memandangkan masalah sukar bagi orang buta untuk memastikan arah yang betul semasa mengambil gambar , dengan membetulkan sudut imej dan semantik watak secara automatik peningkatan, digabungkan dengan pengesanan aksara optik dan teknologi pengecaman untuk menyelesaikan masalah "Ya" "Apa" adalah persoalan pemahaman.
Akhir sekali, imej yang diambil oleh orang buta biasanya kabur dan tidak lengkap , yang menyukarkan algoritma umum untuk menilai jenis dan tujuan objek sasaran, dan model perlu lebih maju Keupayaan akal fikiran yang mencukupi untuk menaakul tentang niat sebenar pengguna.
Untuk tujuan ini, pasukan mencadangkan algoritma yang menggabungkan kedudukan visual dipacu jawapan dengan imej model besar dan padanan teks, dan mencadangkan strategi latihan silang berbilang peringkat. Semasa penaakulan, model kedudukan visual terlatih silang dan padanan teks imej digunakan untuk membuat kesimpulan dan mencari kawasan jawapan pada masa yang sama, aksara serantau ditentukan berdasarkan algoritma pengecaman aksara optik, dan teks output dihantar ke; pengekod teks, dan akhirnya teks model padanan teks imej ialah Penyahkod mendapat jawapan bahawa lelaki buta meminta bantuan, dan ketepatan akhir algoritma berbilang modal adalah 9.5 mata peratusan mendahului prestasi manusia.
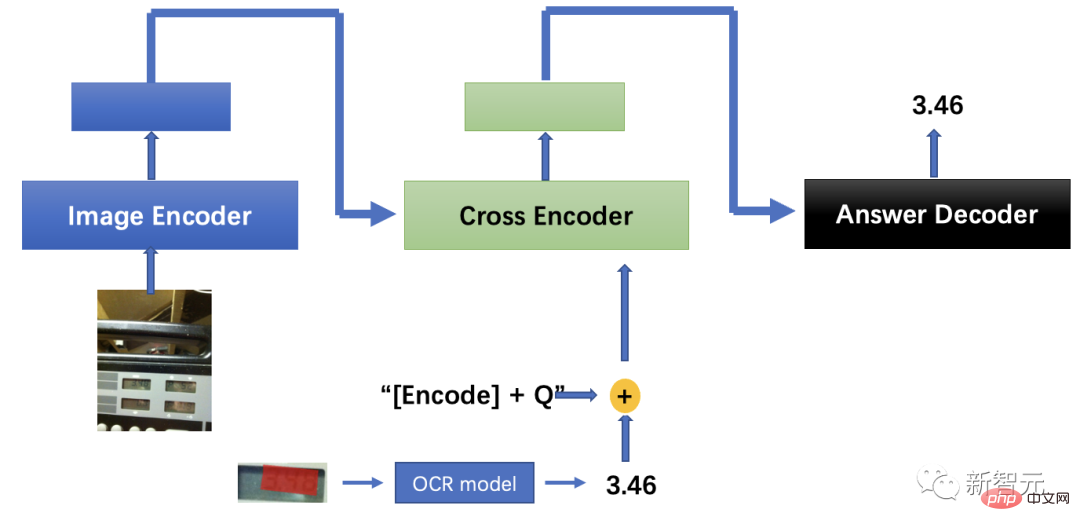
Penyelesaian model menjawab soalan visual berbilang modal
Salah satu halangan terbesar kepada aplikasi semasa penyelidikan kedudukan visual ialah pemprosesan hingar yang pintar Dalam adegan sebenar, penerangan teks selalunya bising. seperti tergelincir lidah manusia, kesamaran, retorik, dll. Eksperimen telah mendapati bahawa bunyi teks boleh menyebabkan model AI sedia ada gagal.
Untuk tujuan ini, Pasukan Penyelidik Inspur Information Frontier meneroka masalah ketidakpadanan pelbagai mod yang disebabkan oleh ralat bahasa manusia di dunia nyata, dan mencadangkan teks kedudukan visual yang menafikan tugas penaakulan FREC untuk kali pertama. Model ini diperlukan untuk mengesan kandungan visual yang sepadan dengan penerangan bunyi dan alasan lanjut tentang bukti bahawa teks itu bising.
FREC menyediakan 30,000 imej dan lebih daripada 250,000 anotasi teks, meliputi pelbagai bunyi seperti gelinciran lidah, kekaburan, penyelewengan subjektif, dll. Ia juga menyediakan pembetulan hingar yang boleh ditafsir, bising bukti, dsb. Label.
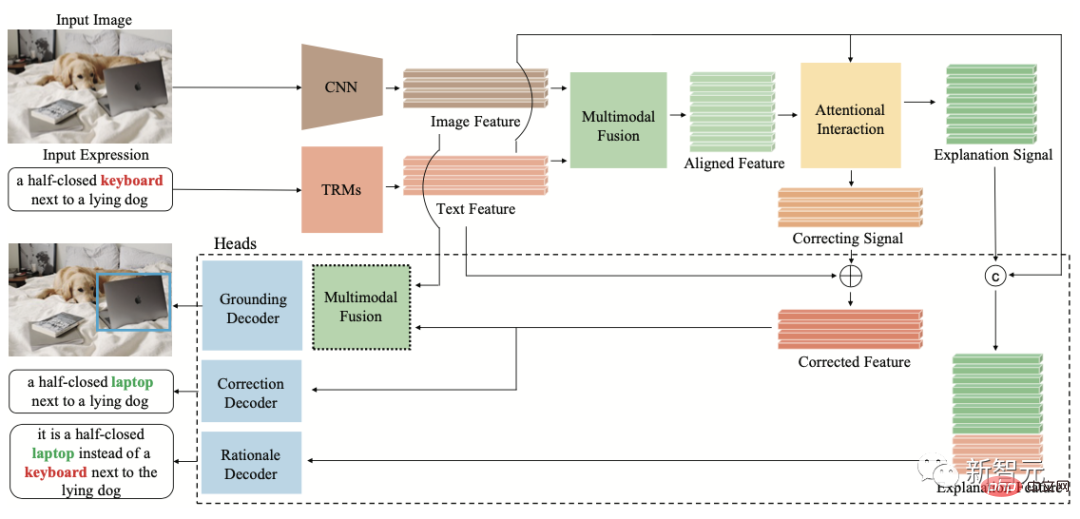
Rajah struktur FCTR
Pada masa yang sama, pasukan juga membina yang pertama Model kedudukan visual denoising boleh tafsir FCTR meningkatkan ketepatan sebanyak 11 mata peratusan berbanding model tradisional di bawah keadaan perihalan teks yang bising.
Hasil penyelidikan ini telah diterbitkan pada persidangan ACM Multimedia 2022, yang merupakan persidangan teratas dalam bidang multimedia antarabangsa dan satu-satunya persidangan antarabangsa Kelas A yang disyorkan oleh CCF dalam bidang ini.

Alamat kertas: https://www.php.cn/link/9f03268e82461f179f372e61621f42d9
Untuk meneroka keupayaan AI untuk berinteraksi dengan pemikiran berdasarkan imej dan teks, Pasukan Penyelidik Inspur Information Frontier telah mencadangkan hala tuju penyelidikan baharu untuk industri, mencadangkan tugasan soalan dan jawapan interaksi visual ejen yang boleh ditafsir AI-VQA, melalui Wujudkan pautan logik untuk mencari dalam pangkalan pengetahuan yang besar, dan mengembangkan kandungan imej dan teks sedia ada.Pada masa ini, pasukan telah membina set data sumber terbuka AI-VQA, yang mengandungi lebih daripada 144,000 pangkalan pengetahuan acara berskala besar, 19,000 soalan penaakulan kognitif tingkah laku interaktif yang dilabelkan secara manual sepenuhnya, dan anotasi penting yang boleh ditafsir seperti objek, fakta sokongan dan laluan penaakulan.
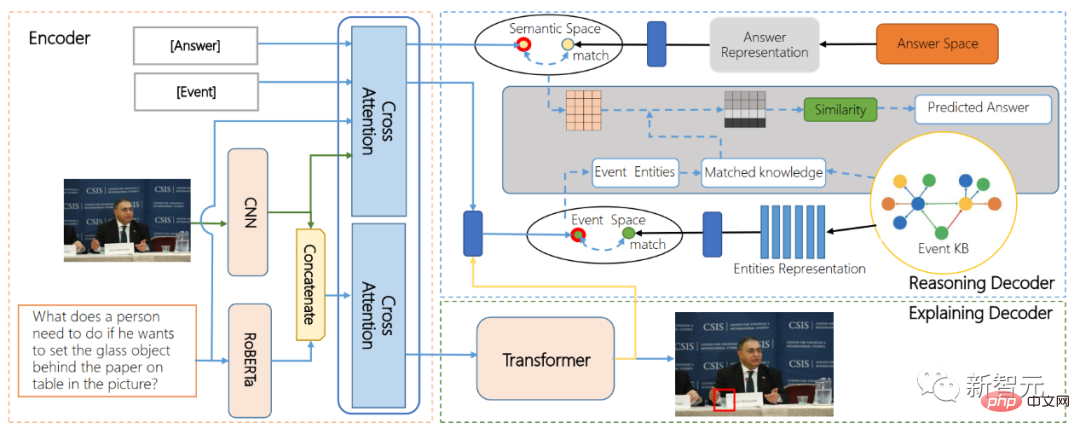
ADALAH rajah struktur
Pada masa yang sama, kecerdasan pertama dicadangkan oleh pasukan Model algoritma pemahaman tingkah laku interaksi badan ARE (model penyahkod-pengekod untuk alasan dan penjelasan alternatif) merealisasikan kedudukan tingkah laku interaksi hujung ke hujung dan penaakulan impak tingkah laku interaksi berdasarkan imej dan teks berbilang modal teknologi gabungan dan algoritma perolehan graf pengetahuan, ia merealisasikan model menjawab soalan visual jangka panjang untuk keupayaan penaakulan rantai sebab.Kehebatan teknologi bukan sahaja untuk mengubah dunia, tetapi yang lebih penting, bagaimana memberi manfaat kepada manusia dan menjadikan perkara yang lebih mustahil menjadi mungkin.
Bagi orang buta, dapat hidup berdikari seperti orang lain melalui teknologi AI untuk membantu kebutaan, dan bukannya dirawat secara istimewa, mencerminkan kebaikan terbesar teknologi.
Ketika AI bersinar menjadi realiti, teknologi tidak lagi sedingin gunung, tetapi penuh dengan penjagaan kemanusiaan.
Berdiri di barisan hadapan teknologi AI, Inspur Information berharap penyelidikan mengenai teknologi kecerdasan buatan dapat menarik lebih ramai orang untuk terus mempromosikan pelaksanaan teknologi kecerdasan buatan, supaya AI berbilang modal boleh membantu Gelombang buta meluas kepada lebih banyak senario seperti anti-penipuan AI, diagnosis dan rawatan AI, amaran awal bencana AI, dsb., mewujudkan lebih nilai untuk masyarakat kita.
Pautan rujukan: https://www.php.cn/link/9f03268e82461f179f312e42169 >
Atas ialah kandungan terperinci Gunakan AI untuk membantu ratusan juta orang buta 'melihat dunia' semula!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI