
Rumah >Peranti teknologi >AI >Manusia tidak mempunyai korpus berkualiti tinggi yang mencukupi untuk AI belajar, dan mereka akan keletihan pada tahun 2026. Netizen: Projek penjanaan teks manusia berskala besar telah dilancarkan!
Manusia tidak mempunyai korpus berkualiti tinggi yang mencukupi untuk AI belajar, dan mereka akan keletihan pada tahun 2026. Netizen: Projek penjanaan teks manusia berskala besar telah dilancarkan!

- PHPzke hadapan
- 2023-04-16 17:49:031385semak imbas
Selera AI terlalu besar, dan data korpus manusia tidak lagi mencukupi.
Sebuah kertas baharu daripada pasukan Epoch menunjukkan bahawa AI akan menggunakan semua korpus berkualiti tinggi dalam masa kurang daripada 5 tahun.

Anda mesti tahu bahawa ini adalah hasil yang diramalkan dengan mengambil kira kadar pertumbuhan data bahasa manusia Dalam erti kata lain, bilangan kertas yang baru ditulis dan yang baru disusun oleh manusia dalam beberapa tahun kebelakangan ini Walaupun semua kod diberikan kepada AI, ia tidak akan mencukupi.
Jika ini berterusan, model bahasa besar yang bergantung pada data berkualiti tinggi untuk meningkatkan prestasi mereka akan menghadapi kesesakan tidak lama lagi.
Sesetengah netizen tidak boleh duduk diam:
Ini mengarut. Manusia boleh melatih diri dengan berkesan tanpa membaca segala-galanya di Internet.
Kami memerlukan model yang lebih baik, bukan lebih banyak data.
Sesetengah netizen mengejek bahawa lebih baik membiarkan AI makan apa yang dimuntahkannya:
AI boleh menjananya dengan sendirinya Teks disalurkan kepada AI sebagai data berkualiti rendah.

Mari kita lihat, berapa banyak data yang ditinggalkan oleh manusia?
Bagaimanakah data teks dan imej "inventori"?
Kertas ini terutamanya meramalkan dua jenis data: teks dan imej.
Pertama ialah data teks.
Kualiti data biasanya terdiri daripada baik hingga buruk. Pengarang membahagikan data teks yang tersedia kepada bahagian berkualiti rendah dan berkualiti tinggi berdasarkan jenis data yang digunakan oleh model besar sedia ada dan data lain.
Korpus berkualiti tinggi merujuk kepada set data latihan yang digunakan oleh model bahasa besar seperti Pile, PaLM dan MassiveText, termasuk Wikipedia, berita, kod pada GitHub, buku yang diterbitkan, dsb.
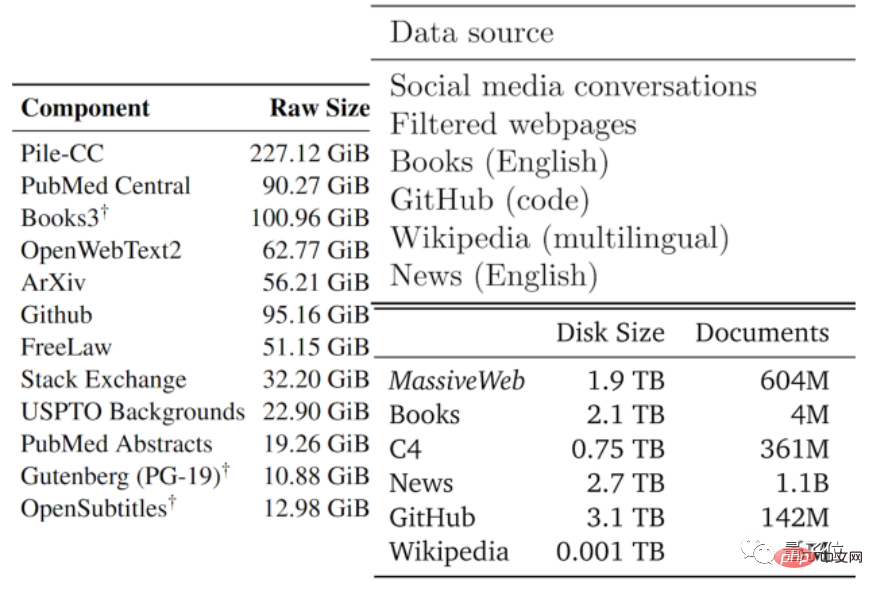
Korpus berkualiti rendah datang daripada tweet di media sosial seperti Reddit, serta fiksyen peminat tidak rasmi (fanfic).
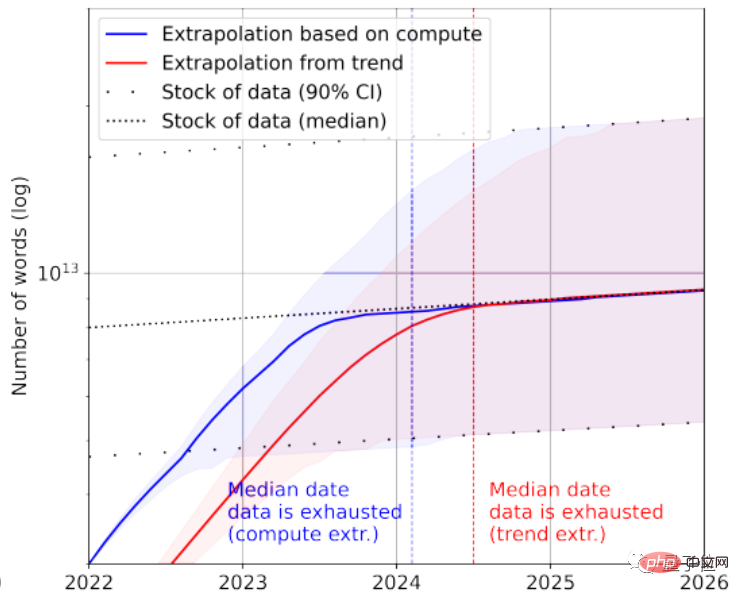
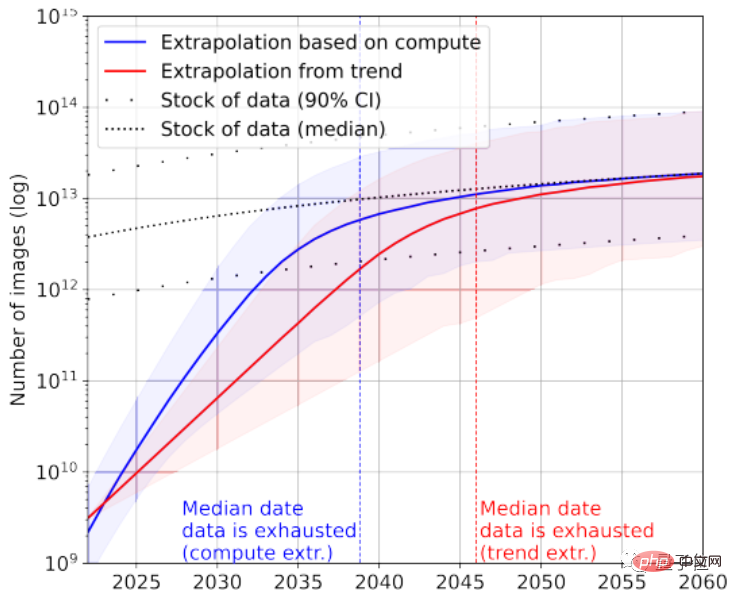
Menurut statistik, hanya tinggal kira-kira 4.6×10^12~1.7×10^13 perkataan dalam stok data bahasa berkualiti tinggi, iaitu kurang daripada susunan magnitud yang lebih besar daripada teks terbesar semasa set data.
Digabungkan dengan kadar pertumbuhan, makalah itu meramalkan bahawa data teks berkualiti tinggi akan dihabiskan oleh AI antara 2023 dan 2027, dengan anggaran nod sekitar 2026.
Nampaknya agak pantas...
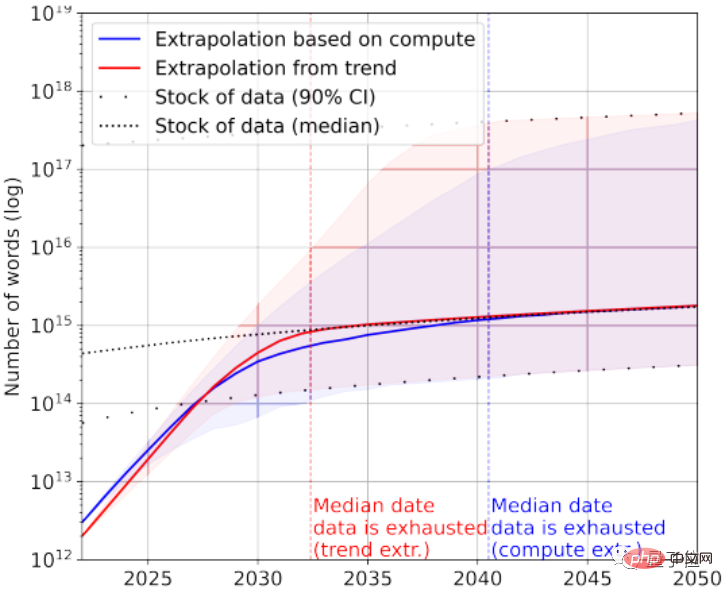
Sudah tentu, data teks berkualiti rendah boleh ditambah untuk menyelamatkan. Menurut statistik, pada masa ini terdapat 7×10^13~7×10^16 perkataan yang tinggal dalam keseluruhan stok data teks, iaitu 1.5~4.5 susunan magnitud lebih besar daripada set data terbesar.
Jika keperluan untuk kualiti data tidak tinggi, maka AI akan menggunakan semua data teks antara 2030 dan 2050.
Melihat data imej sekali lagi, kertas di sini tidak membezakan kualiti imej.
Set data imej terbesar pada masa ini mempunyai imej 3×10^9.
Menurut statistik, jumlah bilangan imej semasa adalah lebih kurang 8.11×10^12~2.3×10^13, iaitu 3~4 susunan magnitud lebih besar daripada set data imej terbesar.
Makalah itu meramalkan bahawa AI akan kehabisan imej ini antara 2030 dan 2070.
Jelas sekali, model bahasa besar menghadapi situasi "kekurangan data" yang lebih teruk berbanding model imej.
Jadi bagaimana kesimpulan ini dicapai?
Kira purata bilangan siaran harian yang disiarkan oleh netizen dan dapatkan hasilnya
Kertas tersebut menganalisis kecekapan penjanaan data imej teks dan pertumbuhan set data latihan daripada dua perspektif.
Perlu diambil perhatian bahawa statistik dalam kertas itu bukan semua data berlabel Memandangkan pembelajaran tanpa pengawasan agak popular, data tidak berlabel juga disertakan.
Ambil data teks sebagai contoh Kebanyakan data akan dijana daripada platform sosial, blog dan forum.
Untuk menganggarkan kelajuan penjanaan data teks, terdapat tiga faktor yang perlu dipertimbangkan, iaitu jumlah populasi, kadar penembusan Internet, dan jumlah purata data yang dijana oleh pengguna Internet.
Sebagai contoh, ini ialah anggaran populasi masa hadapan dan trend pertumbuhan pengguna Internet berdasarkan data populasi sejarah dan bilangan pengguna Internet:
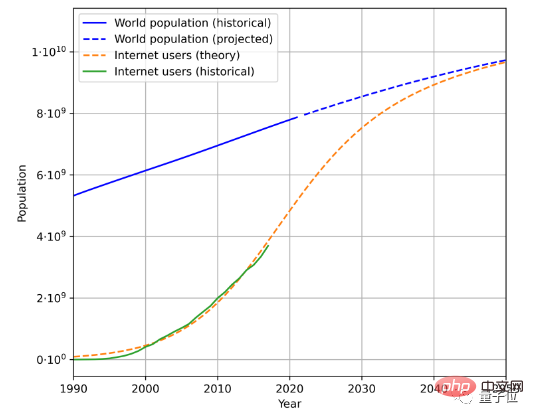
digabungkan dengan pengguna -dijana Dengan purata jumlah data, kadar di mana data dijana boleh dikira. (Disebabkan perubahan geografi dan masa yang kompleks, makalah ini memudahkan kaedah pengiraan jumlah purata data yang dijana oleh pengguna)
Mengikut kaedah ini, kadar pertumbuhan data bahasa dikira sekitar 7%. Walau bagaimanapun, kadar pertumbuhan ini akan meningkat dengan Berperingkat menurun dari semasa ke semasa.
Dianggarkan menjelang 2100, kadar pertumbuhan data bahasa kami akan menurun kepada 1%.
Kaedah yang sama digunakan untuk menganalisis data imej Kadar pertumbuhan semasa adalah kira-kira 8%.
Makalah ini percaya bahawa jika kadar pertumbuhan data tidak meningkat dengan ketara, atau sumber data baharu muncul, sama ada imej atau teks model besar yang dilatih dengan data berkualiti tinggi, ia mungkin membawa kepada tempoh kesesakan pada peringkat tertentu.
Sesetengah netizen bergurau tentang perkara ini, mengatakan bahawa sesuatu seperti jalan cerita fiksyen sains mungkin akan berlaku pada masa hadapan:
Untuk melatih AI, manusia telah melancarkan projek penjanaan teks berskala besar, dan semua orang sedang bekerja keras untuk menulis sesuatu untuk AI.
Dia menggelarnya sebagai sejenis "pendidikan untuk AI":
Kami memberi AI 140,000 hingga 2.6 juta perkataan setiap tahun Jumlah data teks, bunyi lebih sejuk daripada menggunakan manusia sebagai bateri?
Apa pendapat anda?
Alamat kertas: https://arxiv.org/abs/2211.04325
Pautan rujukan: https://twitter.com/emollick/status/1605756428941246466
Atas ialah kandungan terperinci Manusia tidak mempunyai korpus berkualiti tinggi yang mencukupi untuk AI belajar, dan mereka akan keletihan pada tahun 2026. Netizen: Projek penjanaan teks manusia berskala besar telah dilancarkan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI