
Rumah >Peranti teknologi >AI >Lima fungsi kehilangan yang biasa digunakan untuk melatih rangkaian saraf pembelajaran mendalam
Lima fungsi kehilangan yang biasa digunakan untuk melatih rangkaian saraf pembelajaran mendalam

- 王林ke hadapan
- 2023-04-16 14:16:031451semak imbas
Pengoptimuman rangkaian saraf semasa latihan adalah untuk menganggarkan ralat keadaan semasa model dahulu, dan kemudian untuk mengurangkan ralat penilaian seterusnya, adalah perlu untuk mengemas kini pemberat menggunakan fungsi yang boleh mewakili ralat. Fungsi ini dipanggil fungsi kehilangan.

Pilihan fungsi kehilangan berkaitan dengan masalah pemodelan ramalan khusus (seperti pengelasan atau regresi) yang model rangkaian saraf belajar daripada contoh. Dalam artikel ini kami akan memperkenalkan beberapa fungsi kehilangan yang biasa digunakan, termasuk:
- Min kuadrat kehilangan ralat model regresi
- Entropi silang dan kehilangan engsel model klasifikasi binari
Fungsi kehilangan model regresi
Model ramalan regresi digunakan terutamanya untuk meramal nilai berterusan. Jadi kami akan menggunakan fungsi make_regression() scikit-learn untuk menjana beberapa data simulasi dan menggunakan data ini untuk membina model regresi.
Kami akan menjana 20 ciri input: 10 daripadanya akan bermakna, tetapi 10 akan tidak berkaitan dengan masalah itu.
Dan jana 1,000 contoh secara rawak. Dan tentukan benih rawak, jadi 1,000 contoh yang sama dijana setiap kali anda menjalankan kod.

Menskalakan pembolehubah input dan output bernilai sebenar kepada julat yang munasabah selalunya boleh meningkatkan prestasi rangkaian saraf. Jadi kita perlu menyeragamkan data.
StandardScaler juga boleh didapati dalam perpustakaan scikit-learn, untuk memudahkan masalah kami akan menskalakan semua data sebelum membahagikannya kepada set latihan dan ujian.

Kemudian bahagikan set latihan dan pengesahan sama rata
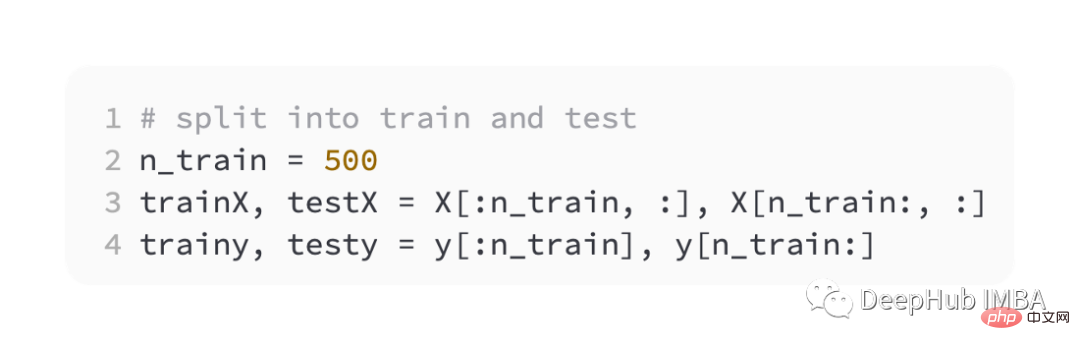
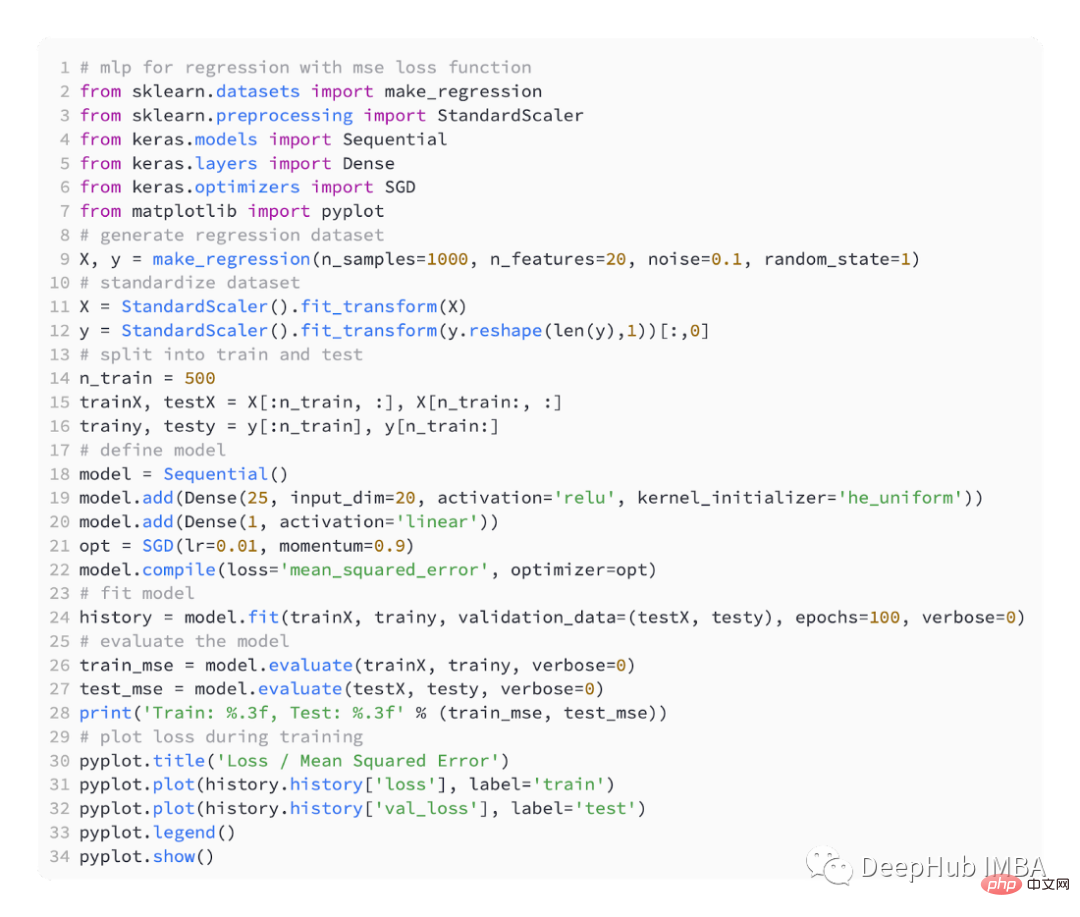
Untuk memperkenalkan fungsi kerugian yang berbeza, kami akan membangunkan berbilang kecil - Model Lapisan Perceptron (MLP).
Mengikut takrifan masalah, terdapat 20 ciri sebagai input, melalui model kami. Nilai sebenar diperlukan untuk meramalkan, jadi lapisan keluaran akan mempunyai nod.

Kami menggunakan SGD untuk pengoptimuman dan mempunyai kadar pembelajaran 0.01 dan momentum 0.9, kedua-duanya adalah nilai lalai yang munasabah. Latihan akan dijalankan selama 100 zaman, set ujian akan dinilai pada akhir setiap peringkat, dan keluk pembelajaran akan diplot.

Selepas model selesai, fungsi kehilangan boleh diperkenalkan:
MSE
Masalah regresi yang paling biasa digunakan ialah min kehilangan ralat kuasa dua (MSE). Ia adalah fungsi kehilangan pilihan di bawah inferens kemungkinan maksimum apabila taburan pembolehubah sasaran ialah Gaussian. Jadi anda hanya perlu menukar kepada fungsi kerugian lain jika anda mempunyai sebab yang lebih baik.
Jika "mse" atau "mean_squared_error" ditentukan sebagai fungsi kehilangan apabila menyusun model dalam Keras, fungsi kehilangan ralat kuasa dua min digunakan.

Kod di bawah ialah contoh lengkap masalah regresi di atas.
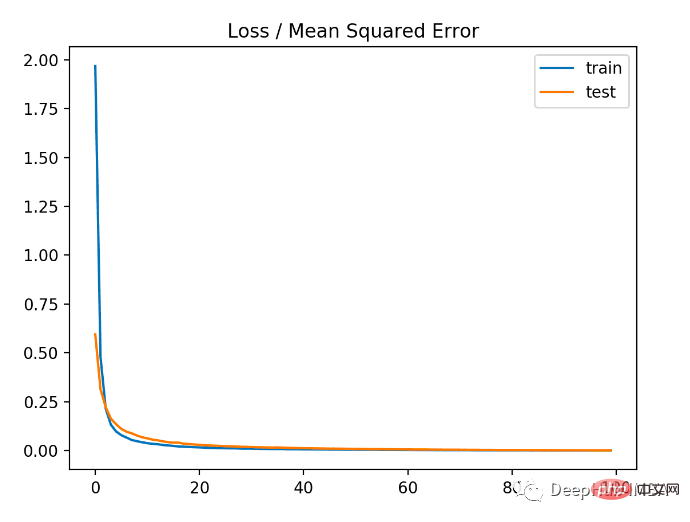
Dalam langkah pertama menjalankan contoh, ralat min kuasa dua bagi set data latihan dan ujian model dicetak Kerana 3 tempat perpuluhan dikekalkan dipaparkan sebagai 0.000

Seperti yang anda boleh lihat daripada rajah di bawah, model menumpu agak cepat dan prestasi latihan dan ujian kekal tidak berubah. Bergantung pada prestasi dan sifat penumpuan model, ralat min kuasa dua ialah pilihan yang baik untuk masalah regresi.
MSLE
Dalam masalah regresi dengan julat nilai yang luas, mungkin tidak diingini untuk menghukum model sebanyak ralat kuasa dua min apabila meramalkan besar nilai. Jadi min ralat kuasa dua boleh dikira dengan terlebih dahulu mengira logaritma asli setiap nilai yang diramalkan. Kehilangan ini dipanggil MSLE, atau min ralat log segi empat sama.
Ia mempunyai kesan melonggarkan kesan penalti apabila terdapat perbezaan besar dalam nilai yang diramalkan. Ia mungkin merupakan ukuran kerugian yang lebih sesuai apabila model secara langsung meramalkan kuantiti tidak berskala.
Menggunakan "mean_squared_logarithmic_error" sebagai fungsi kehilangan dalam keras

Contoh di bawah ialah kod lengkap menggunakan fungsi kehilangan MSLE.

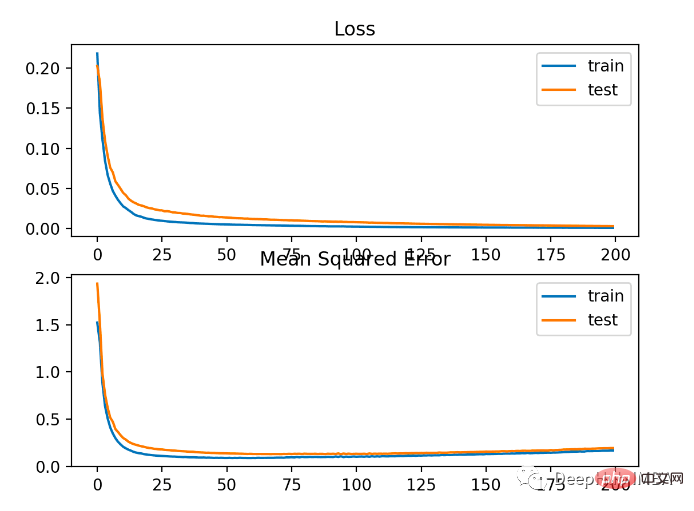
Model mempunyai MSE yang lebih teruk pada set data latihan dan ujian. Ini kerana taburan pembolehubah sasaran adalah taburan Gaussian standard, yang bermaksud bahawa fungsi kehilangan kami mungkin tidak begitu sesuai untuk masalah ini.

Rajah di bawah menunjukkan perbandingan setiap zaman latihan MSE menumpu dengan baik, tetapi MSE mungkin terlalu sesuai kerana ia berkurangan dari zaman 20 kepada berubah dan mula meningkat.
MAE
Bergantung kepada masalah regresi, taburan pembolehubah sasaran mungkin terutamanya Gaussian tetapi mungkin mengandungi outlier seperti nilai besar jauh daripada nilai min atau Kecil.
Dalam kes ini, min ralat mutlak atau kerugian MAE adalah fungsi kerugian yang sesuai kerana ia lebih teguh kepada outlier. Dikira sebagai purata, dengan mengambil kira perbezaan mutlak antara nilai sebenar dan ramalan.
Menggunakan fungsi kehilangan "min_absolute_error"

Berikut ialah kod lengkap menggunakan MAE

Hasilnya Seperti yang ditunjukkan di bawah

Seperti yang anda lihat dalam rajah di bawah, MAE memang bertumpu tetapi ia mempunyai proses yang bergelombang. MAE juga tidak begitu sesuai dalam kes ini kerana pembolehubah sasaran adalah fungsi Gaussian tanpa outlier besar.
Fungsi kehilangan untuk klasifikasi binari
Masalah klasifikasi binari ialah salah satu daripada dua label dalam masalah pemodelan ramalan. Masalah ini ditakrifkan sebagai meramalkan nilai kelas pertama atau kedua sebagai 0 atau 1, dan secara amnya dilaksanakan sebagai meramalkan kebarangkalian tergolong dalam nilai kelas 1.
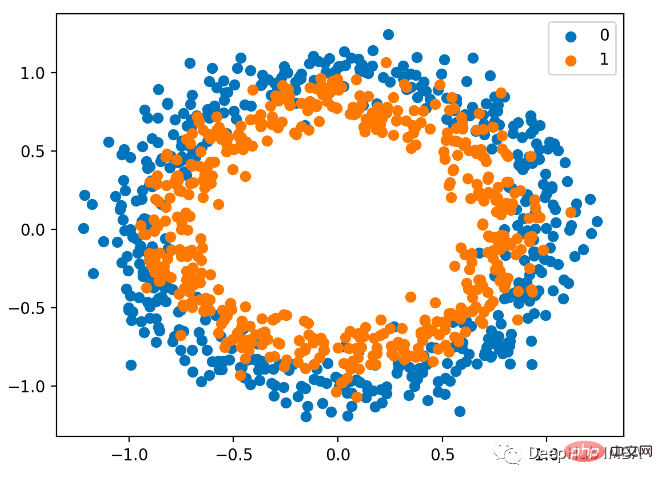
Kami juga menggunakan sklearn untuk menjana data Di sini kami menggunakan masalah bulatan Ia mempunyai satah dua dimensi dengan dua bulatan sepusat tergolong dalam kelas 1. Untuk menjadikan pembelajaran lebih mencabar, kami juga menambahkan bunyi statistik pada sampel. Saiz sampel ialah 1000, dan 10% bunyi statistik ditambah.

Petak sebaran set data boleh membantu kami memahami masalah yang kami modelkan. Disenaraikan di bawah adalah contoh lengkap.

Plot serakan adalah seperti berikut, di mana pembolehubah input menentukan lokasi titik dan warna ialah nilai kelas. 0 ialah biru dan 1 ialah oren.
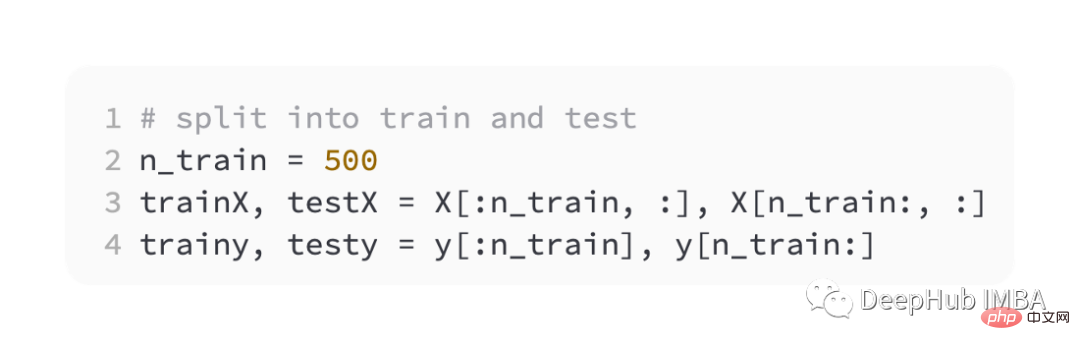
Ini masih separuh untuk latihan dan separuh lagi untuk ujian
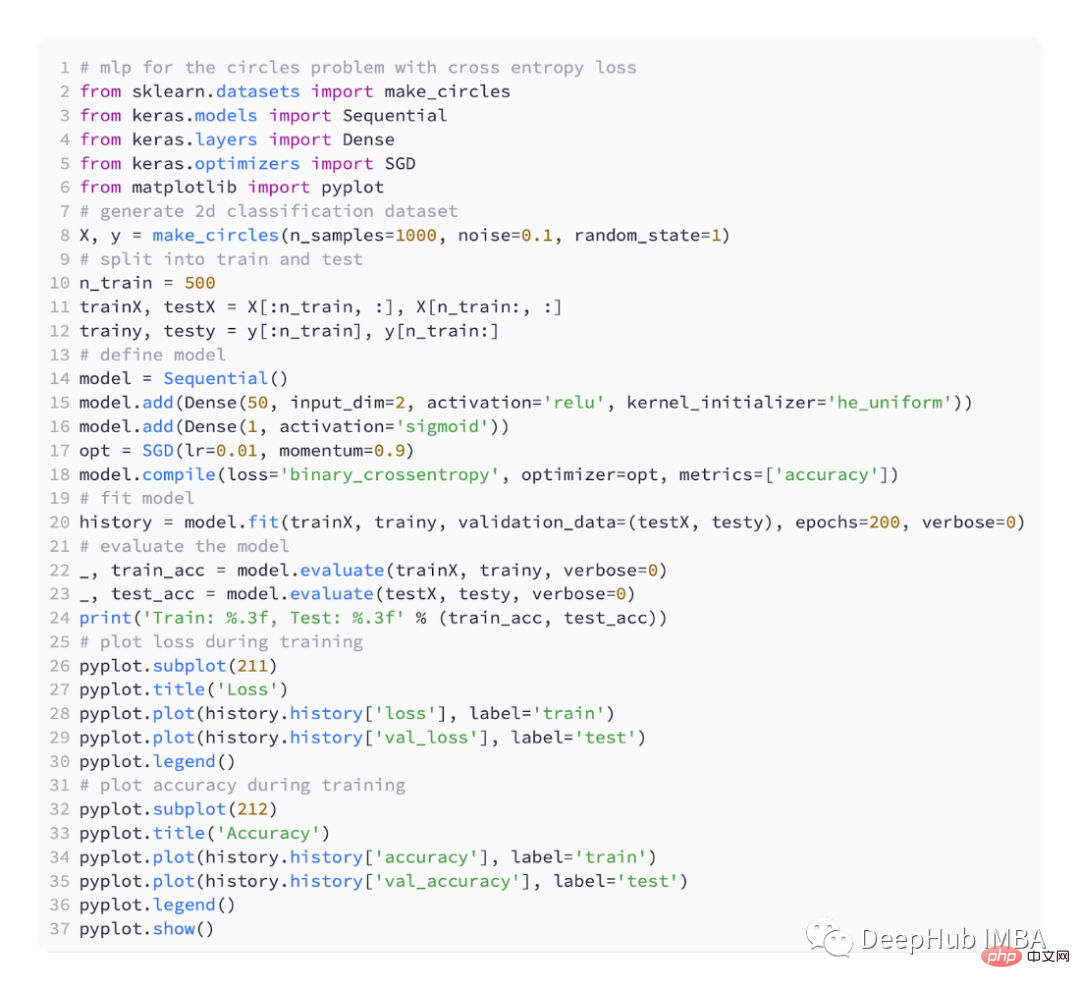
Kami masih mentakrifkan model MLP yang mudah, <.>





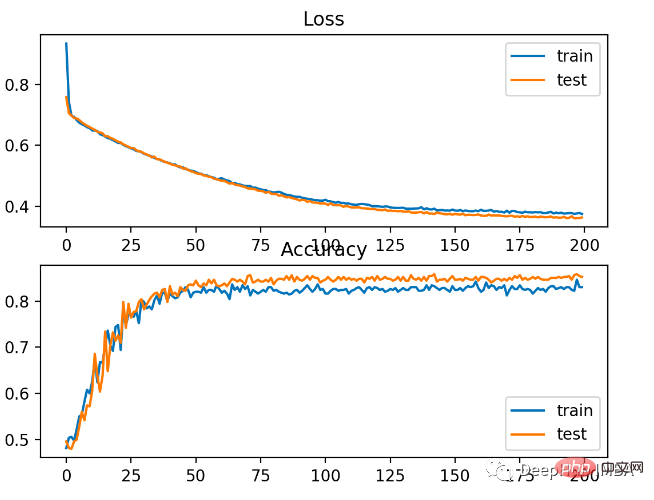
Sebagai langkah pertama, kita perlu mengubah suai nilai pembolehubah sasaran kepada set {-1, 1}.

Ia dipanggil ' engsel ' dalam keras.

Dalam lapisan keluaran rangkaian, satu nod fungsi pengaktifan tanh mesti digunakan untuk mengeluarkan satu nilai antara -1 dan 1.

Berikut ialah kod lengkap:

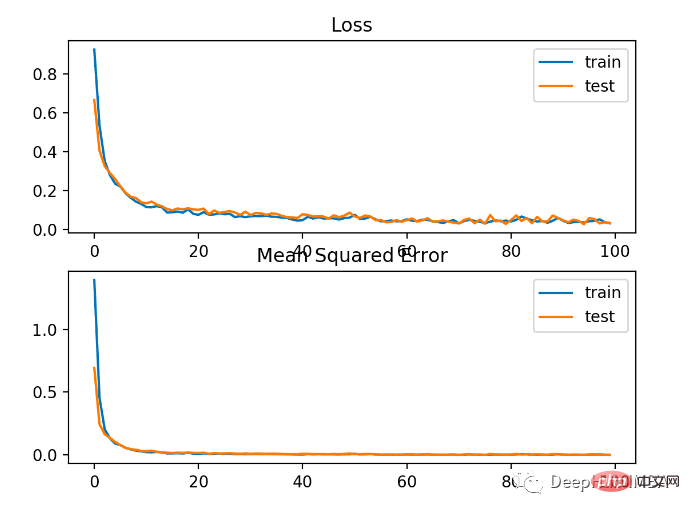
Prestasi yang lebih teruk daripada cross entropy, pada set latihan dan ujian. ketepatan kurang daripada 80%.
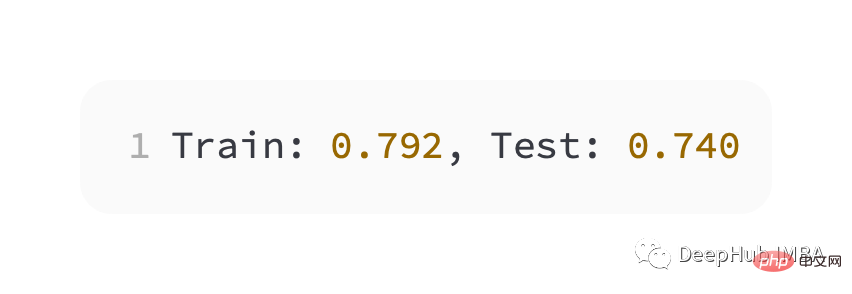
Seperti yang dapat dilihat daripada rajah di bawah, model telah menumpu, dan graf ketepatan pengelasan menunjukkan bahawa ia juga telah menumpu.
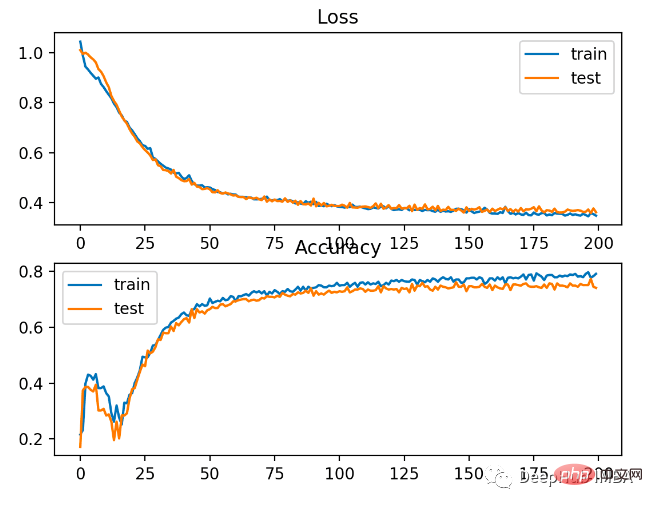
Anda dapat melihat bahawa BCE adalah lebih baik untuk masalah ini. Sebab yang mungkin di sini ialah kami mempunyai beberapa titik bunyi
Atas ialah kandungan terperinci Lima fungsi kehilangan yang biasa digunakan untuk melatih rangkaian saraf pembelajaran mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI