
Rumah >Peranti teknologi >AI >Kejutkan komuniti saintifik! Penyelidikan 154 halaman Microsoft membanjiri skrin: Keupayaan GPT-4 hampir dengan manusia, dan 'Skynet' muncul?
Kejutkan komuniti saintifik! Penyelidikan 154 halaman Microsoft membanjiri skrin: Keupayaan GPT-4 hampir dengan manusia, dan 'Skynet' muncul?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-16 10:43:021394semak imbas
Adakah GPT-4 akan berkembang menjadi kecerdasan buatan am?
Ketua saintis kecerdasan buatan meta dan pemenang Anugerah Turing Yann LeCun menyatakan keraguan tentang perkara ini.
Pada pandangannya, model besar memerlukan terlalu banyak data dan kuasa pengkomputeran, tetapi kecekapan pembelajaran tidak tinggi, hanya dengan mempelajari "model dunia". bolehkah seseorang melalui Jalan ke AGI.
Walau bagaimanapun, kertas setebal 154 muka surat yang diterbitkan baru-baru ini oleh Microsoft nampaknya menjadi tamparan di muka.
Dalam kertas kerja ini yang dipanggil "Sparks of Artificial General Intelligence: Percubaan awal dengan GPT-4", Microsoft percaya bahawa, walaupun ia tidak lengkap, Tetapi GPT-4 sudah boleh dianggap sebagai versi awal kecerdasan buatan am.

Alamat kertas: https://arxiv.org/pdf/2303.12712.pdf
Memandangkan keluasan dan kedalaman keupayaan GPT-4, kami percaya ia wajar dianggap sebagai versi awal (tetapi masih tidak lengkap) sistem kecerdasan am buatan (AGI).
Matlamat utama artikel ini adalah untuk meneroka keupayaan dan batasan GPT-4 Kami percaya bahawa kecerdasan GPT-4 menandakan masa depan sains komputer dan Anjakan paradigma sebenar dalam bidang lain.
Agen perisikan AGI kini mampu berfikir dan menaakul seperti manusia, dan juga mampu merangkumi pelbagai kemahiran dan kebolehan kognitif.
Dalam kertas itu, dinyatakan bahawa AGI mempunyai penaakulan, perancangan, penyelesaian masalah, pemikiran abstrak, pemahaman idea yang kompleks, pembelajaran pantas dan mengalami keupayaan pembelajaran .
Dari segi skala parameter, Semafor melaporkan bahawa GPT-4 mempunyai 1 trilion parameter, iaitu 6 kali ganda GPT-3 (175 bilion parameter) besar .
Netizen menggunakan neuron otak skala parameter GPT untuk membuat analogi:
GPT - 3 adalah sama dalam skala dengan otak landak (175 bilion parameter). Jika GPT-4 mempunyai 1 trilion parameter, kita akan menghampiri saiz otak tupai. Jika kita terus berkembang pada kadar ini, ia mungkin hanya mengambil masa beberapa tahun sebelum kita boleh mencapai dan melepasi saiz otak manusia (170 trilion parameter).
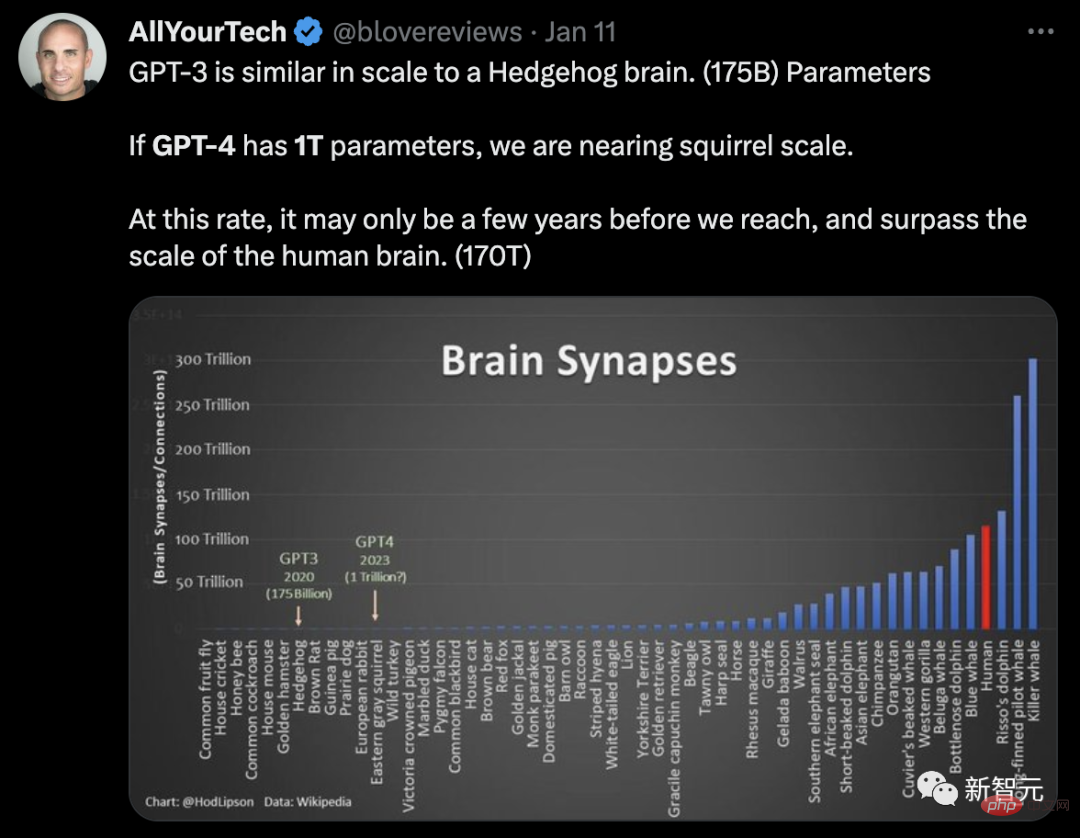
Dari sudut ini, GPT-4 tidak jauh untuk menjadi "Skynet".
Dan kertas kerja ini juga mendedahkan banyak perkara menarik.
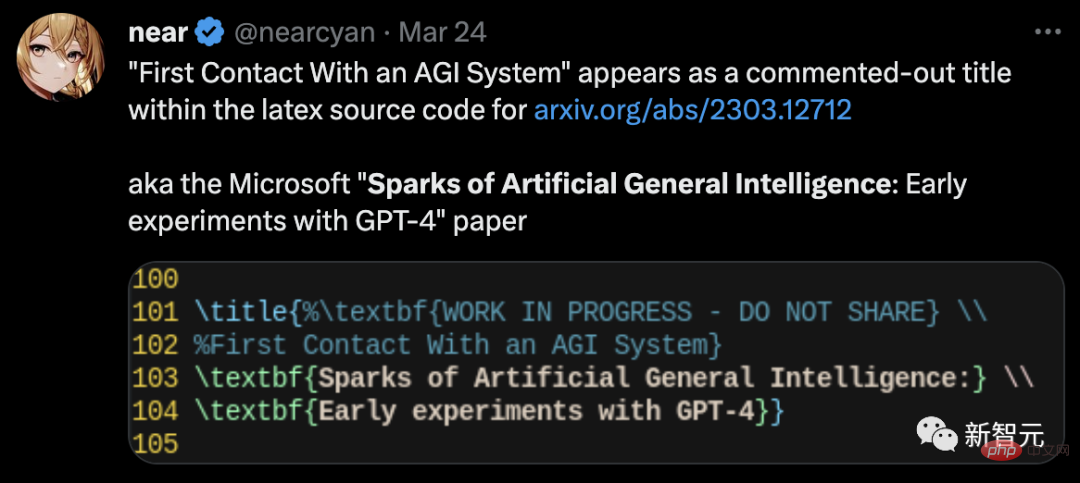
Tidak lama selepas kertas itu dikeluarkan, seorang netizen mendedahkan di Twitter bahawa maklumat tersembunyi ditemui dalam kod sumber lateks mereka.

Dalam versi ringkas kertas itu, GPT-4 sebenarnya ialah kertas The hidden pengarang ketiga , dengan nama dalaman DV-3, kemudiannya dipadamkan.
Menariknya, penyelidik Microsoft pun tidak mengetahui butiran teknikal GPT-4. Selain itu, kertas kerja ini juga membuang kandungan toksik yang dihasilkan oleh GPT-4 tanpa sebarang gesaan.
GPT-4 mula terbentuk sebagai AGI
Objek kajian kertas ini ialah versi awal GPT-4. Ketika ia masih dalam peringkat pembangunan awal, penyelidik Microsoft menjalankan pelbagai eksperimen dan penilaian ke atasnya.
Pada pendapat penyelidik, versi awal GPT-4 ini sudah pun mewakili generasi baharu LLM, dan ia menunjukkan lebih kecerdasan umum berbanding model kecerdasan buatan sebelumnya.
Melalui ujian, penyelidik Microsoft mengesahkan bahawa GPT-4 bukan sahaja mahir dalam bahasa, tetapi juga boleh digunakan dalam matematik, pengaturcaraan, penglihatan, perubatan, undang-undang, psikologi, dsb. Prestasi cemerlang dalam tugas yang pelbagai dan sukar tanpa memerlukan arahan khas.
Anehnya, dalam semua tugasan ini, prestasi GPT-4 hampir dengan tahap manusia, dan selalunya melebihi model sebelumnya, seperti ChatGPT.
Oleh itu, para penyelidik percaya bahawa GPT-4 boleh dianggap sebagai versi awal kecerdasan am buatan (AGI) memandangkan keluasan dan kedalaman keupayaannya.
Jadi, apakah cabaran dalam perjalanannya ke arah AGI yang lebih mendalam dan menyeluruh? Penyelidik percaya bahawa mungkin perlu mencari paradigma baharu yang melampaui "meramalkan perkataan seterusnya."
Penilaian keupayaan GPT-4 berikut ialah hujah yang diberikan oleh penyelidik Microsoft bahawa GPT-4 ialah versi awal AGI.
Keupayaan pelbagai mod dan antara disiplin
Sejak keluaran GPT-4, tanggapan semua orang tentang keupayaan multimodalnya masih kekal Pada video Greg Brockman demonstrasi pada masa itu.
Dalam bahagian kedua kertas kerja ini, Microsoft mula-mula memperkenalkan keupayaan pelbagai modalnya.
GPT-4 bukan sahaja menunjukkan kecekapan tinggi dalam pelbagai bidang seperti kesusasteraan, perubatan, undang-undang, matematik, sains fizikal dan pengaturcaraan; pelbagai bidang dan memahami konsep yang kompleks.
Keupayaan komprehensif
Para penyelidik menggunakan 4 perkara berikut Satu contoh disediakan untuk menunjukkan prestasi GPT-4 dari segi keupayaan komprehensif.
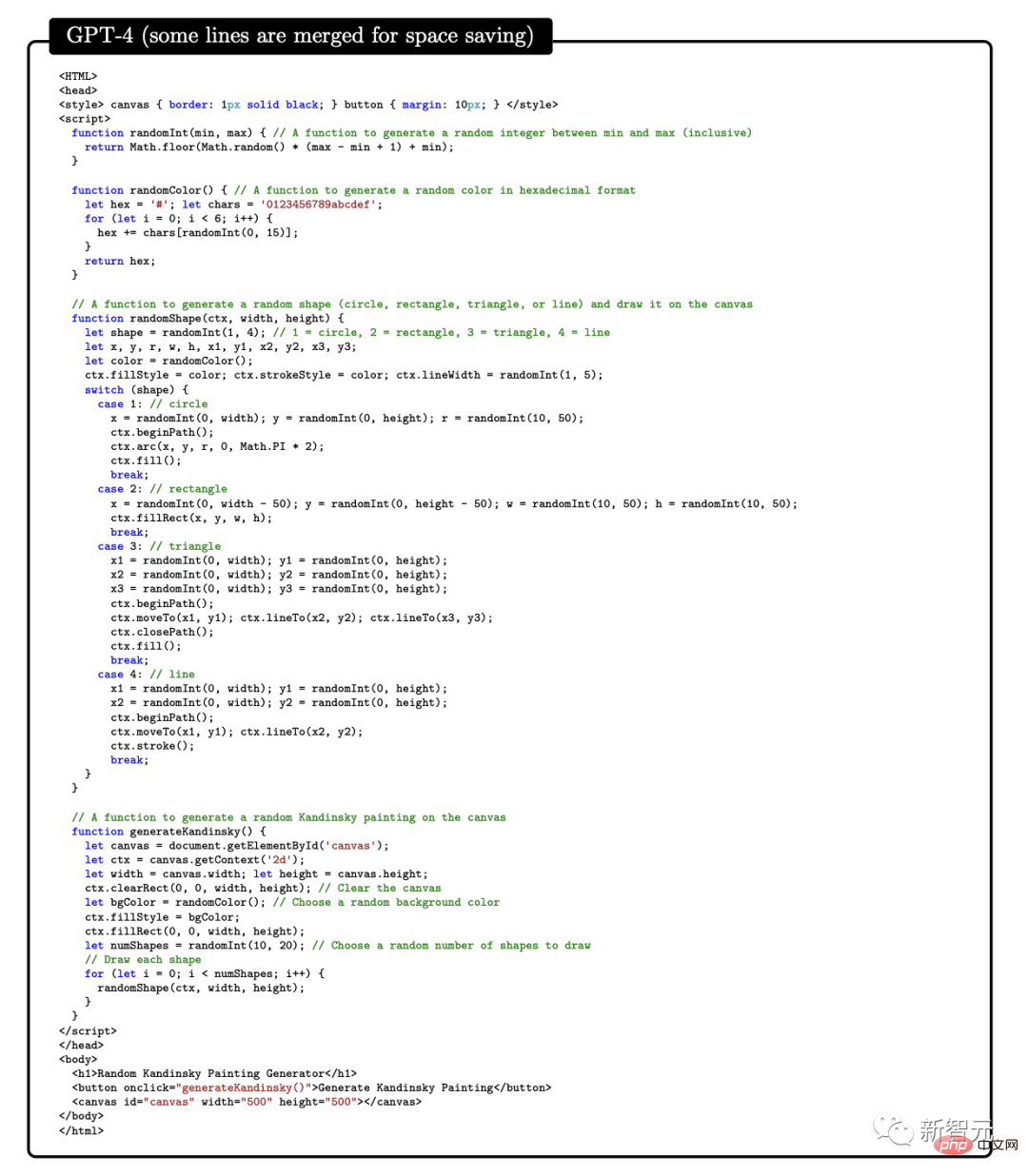
Dalam contoh pertama, untuk menguji keupayaan GPT-4 untuk menggabungkan seni dan pengaturcaraan, penyelidik meminta GPT-4 menjana kod javascript untuk menghasilkan pelukis Imej rawak dalam gaya Kandinsky.
Berikut ialah proses kod untuk pelaksanaan GPT-4:
Dari segi penggabungan sastera dan matematik, GPT-4 boleh membuktikan bahawa terdapat nombor perdana tak terhingga dalam gaya sastera Shakespeare.
Selain itu, kajian itu menguji keupayaan GPT-4 untuk menggabungkan pengetahuan sejarah dan fizikal dengan memintanya menulis surat yang menyokong bidaan Electron untuk Surat Presiden A.S. oleh Mahatma Gandhi kepada isterinya.
Gesa GPT-4 untuk menjana kod python untuk program yang mengambil sebagai input umur, jantina, berat, ketinggian dan vektor hasil ujian darah pesakit, dan menunjukkan sama ada pesakit berisiko tinggi untuk diabetes.
Melalui ujian, contoh di atas menunjukkan bahawa GPT-4 bukan sahaja dapat mempelajari beberapa prinsip dan corak biasa merentas bidang dan gaya yang berbeza, tetapi juga menggabungkannya dengan cara yang kreatif.
Visual
Apabila digesa GPT-4 boleh digunakan Apabila Grafik Vektor Boleh Skala (SVG) menjana imej objek, seperti kucing, trak atau huruf, kod yang dijana oleh model ini biasanya disusun menjadi imej yang agak terperinci dan boleh dikenali, seperti yang berikut:

Walau bagaimanapun, ramai orang mungkin berfikir bahawa GPT-4 hanya menyalin kod daripada data latihan, yang mengandungi imej serupa.
Malah, GPT-4 bukan sahaja menyalin kod daripada contoh serupa dalam data latihan, tetapi mampu mengendalikan tugas penglihatan sebenar walaupun hanya dilatih pada teks .
Yang berikut menggesa model untuk melukis seseorang dengan menggabungkan bentuk huruf Y, O dan H.
Semasa proses penjanaan, penyelidik menggunakan arahan garisan-lukisan dan bulatan-lukisan untuk mencipta huruf O, H dan Y, dan kemudian GPT- 4 berjaya untuk Mereka diletakkan dalam apa yang kelihatan seperti imej manusia yang munasabah.
Walaupun GPT-4 belum dilatih untuk mengenali bentuk huruf, masih boleh disimpulkan bahawa huruf Y mungkin kelihatan seperti batang tubuh dengan tangan terangkat .
Dalam demonstrasi kedua, GPT-4 digesa untuk membetulkan perkadaran batang tubuh dan lengan serta memusatkan kepala. Akhirnya minta model tambah baju dan seluar.
Nampaknya GPT-4 samar-samar mengetahui bahawa huruf berkaitan dengan beberapa bentuk tertentu daripada data latihan yang berkaitan, dan hasilnya adalah baik.
Untuk menguji lagi keupayaan GPT-4 untuk menjana dan memanipulasi imej, kami menguji sejauh mana ia mengikut arahan terperinci untuk mencipta dan mengedit grafik. Tugas ini memerlukan bukan sahaja kebolehan generatif tetapi juga interpretif, kombinatorial dan spatial.
Arahan pertama ialah membenarkan GPT-4 menjana imej 2D Gesaannya ialah:
「Seekor katak melompat ke bank dan bertanya kepada juruwang, 'Adakah anda mempunyai pad lily percuma?' >
Selepas banyak percubaan, GPT-4 menghasilkan imej yang sesuai dengan penerangan setiap masa. Kemudian, GPT-4 diminta menambah lebih banyak butiran untuk meningkatkan kualiti grafik GPT-4 menambah objek realistik seperti bank, tingkap dan kereta.Contoh kedua kami cuba menggunakan Javascript untuk menjana model 3D, juga menyelesaikan banyak tugasan melalui arahan GPT-4.

Gambar di bawah ialah tangkapan skrin pemodelan bandar 3D Gesaan input mempunyai sungai yang mengalir dari kiri ke kanan, padang pasir dengan piramid di sebelah sungai. dan padang pasir di bahagian bawah skrin 4 butang, warna hijau, biru, coklat dan merah. Keputusan yang dihasilkan adalah seperti berikut:

Muzik
Para penyelidik meminta GPT-4 menjana dan mengubah suai lagu menggunakan pengekodan notasi ABC, seperti berikut:Dengan meneroka prestasi GPT-4 dalam latihan Memandangkan berapa banyak kemahiran yang diperolehinya, para penyelidik mendapati bahawa GPT-4 mampu menghasilkan melodi yang berkesan dalam notasi ABC dan mentafsir dan memanipulasi struktur di dalamnya pada tahap tertentu.
Walau bagaimanapun, penyelidik tidak dapat membuat GPT-4 menghasilkan sebarang bentuk harmonik bukan remeh, seperti "Ode to Joy" dan "Für Elise". ” dan melodi terkenal lain.
Keupayaan Pengaturcaraan
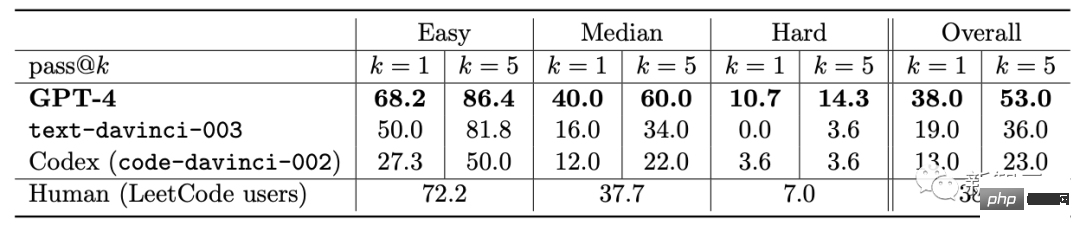
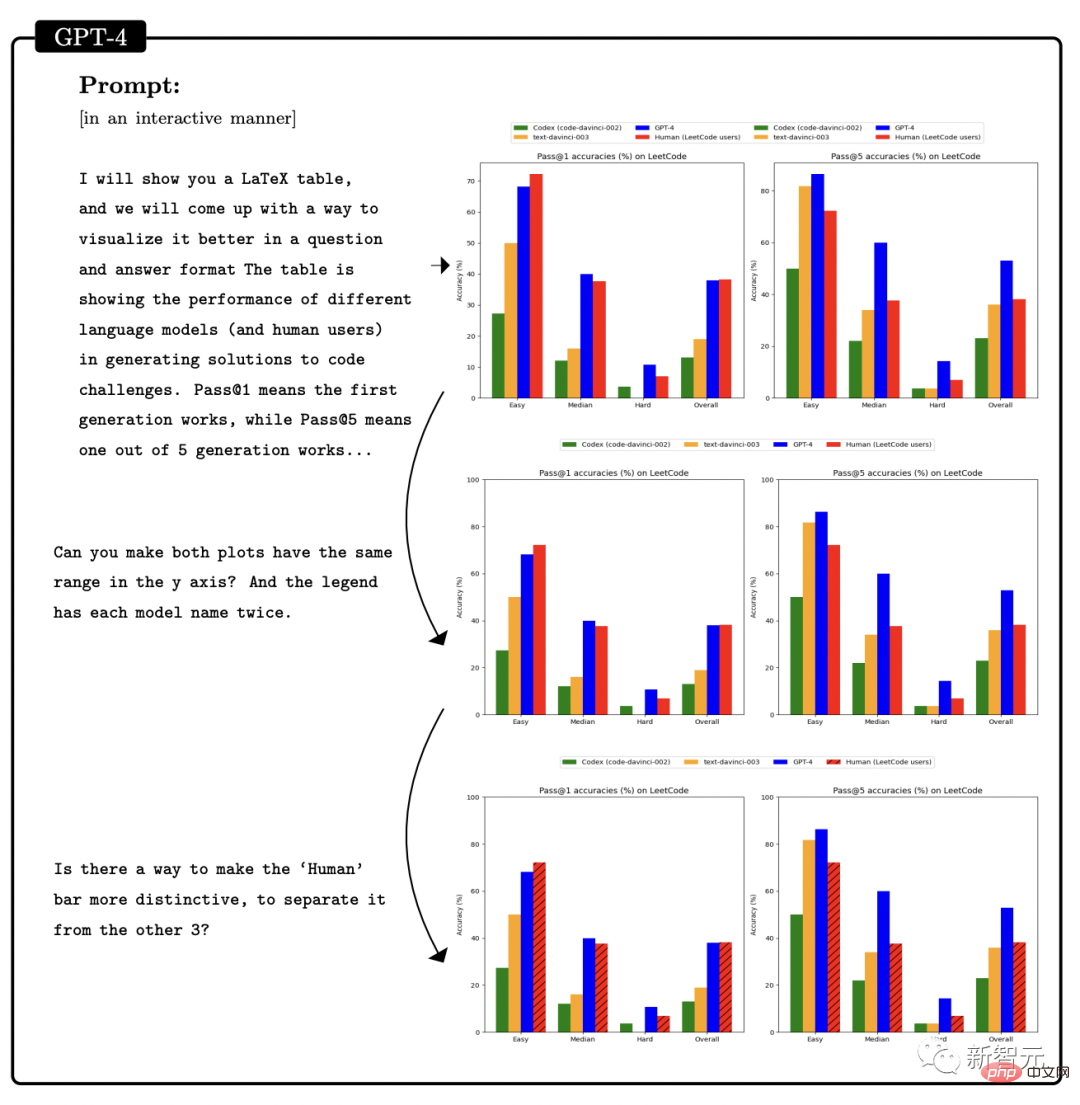
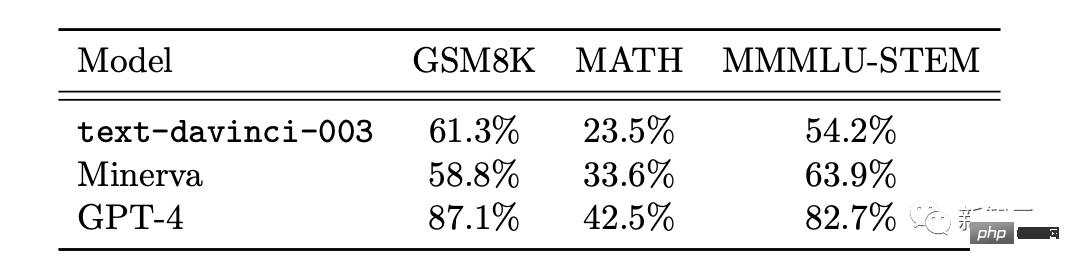
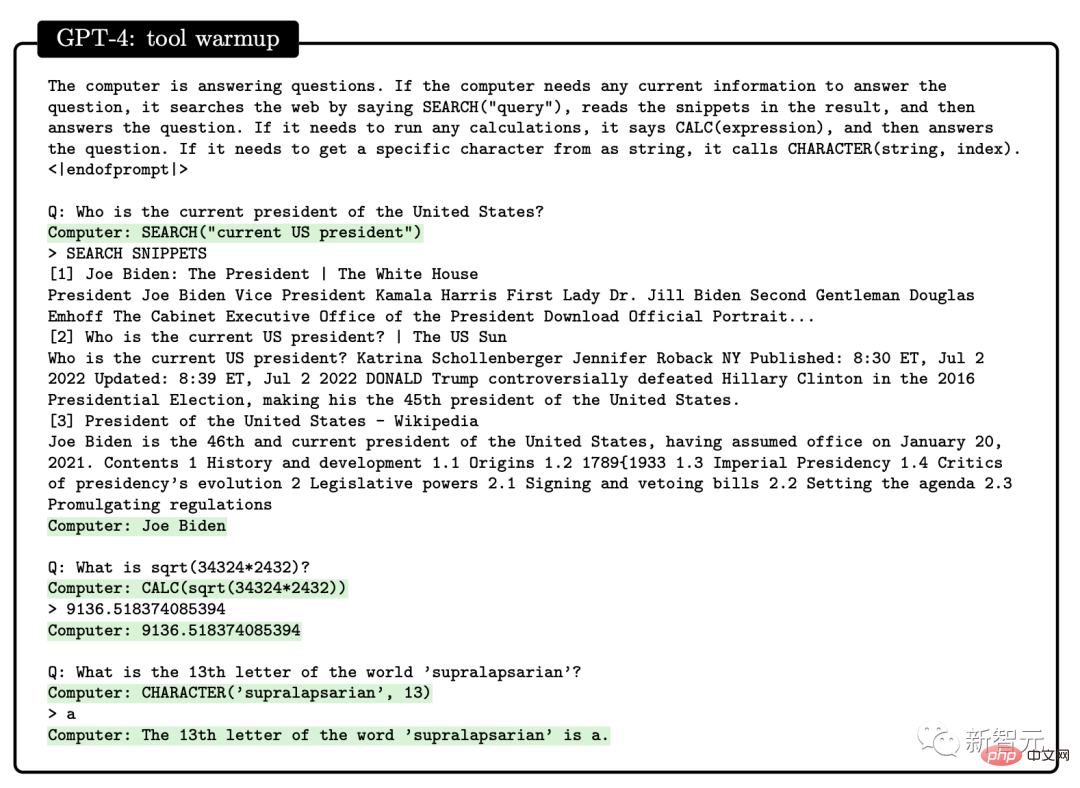
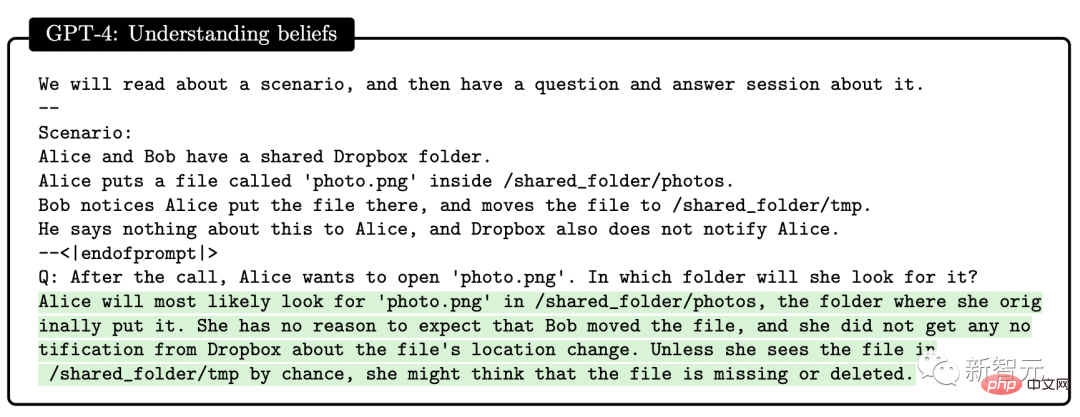
Selain itu, penyelidik menunjukkan bahawa GPT-4 mampu mengekod pada tahap yang sangat tinggi, tanpa mengira arahan Keupayaan yang ditunjukkan untuk menulis kod dan memahami kod sedia ada.Dari segi menulis kod mengikut arahan, penyelidik menunjukkan contoh membenarkan GPT-4 menulis fungsi python. Selepas kod dijana, penyelidik menggunakan platform temu bual kejuruteraan perisian LeetCode untuk menilai dalam talian sama ada kod itu betul . Semua orang membincangkan bahawa LeetCode mempunyai kadar ketepatan hanya 20%. menyangkal perkara ini. Selain itu, GPT-4 juga diminta untuk menggambarkan data ketepatan LeetCode dalam jadual di atas sebagai carta Keputusan adalah seperti yang ditunjukkan dalam rajah yang ditunjukkan. GPT-4 bukan sahaja dapat menyelesaikan kerja pengaturcaraan biasa, tetapi juga cekap dalam pembangunan permainan 3D yang kompleks. Para penyelidik meminta GPT-4 menulis permainan 3D dalam HTML menggunakan JavaScript GPT-4 menghasilkan permainan yang memenuhi semua keperluan dengan sampel sifar. Dalam pengaturcaraan pembelajaran mendalam, GPT-4 bukan sahaja memerlukan pengetahuan tentang matematik dan statistik, tetapi juga memerlukan pengetahuan tentang PyTorch dan TensorFlow Familiar dengan rangka kerja dan perpustakaan seperti Keras dan Keras. Para penyelidik meminta GPT-4 dan ChatGPT untuk menulis modul pengoptimum tersuai dan menyediakannya dengan penerangan bahasa semula jadi, yang termasuk satu siri operasi penting, seperti seperti menggunakan SVD dan sebagainya. Selain menulis kod mengikut arahan, GPT-4 telah menunjukkan kebolehan hebat dalam memahami kod. Penyelidik cuba membenarkan GPT-4 dan ChatGPT memahami program C/C++ dan meramalkan output program tersebut adalah seperti berikut: Kawasan yang diserlahkan dengan warna kuning ialah cerapan bernas daripada GPT-4, manakala penanda merah mewakili kawasan yang ChatGPT berlaku kesilapan. Melalui ujian keupayaan pengekodan, penyelidik mendapati bahawa GPT-4 boleh mengendalikan pelbagai tugas pengekodan, daripada cabaran pengekodan kepada Aplikasi praktikal, daripada pemasangan peringkat rendah kepada rangka kerja peringkat tinggi, daripada struktur data ringkas kepada program yang kompleks. Selain itu, GPT-4 boleh membuat alasan tentang pelaksanaan kod, mensimulasikan kesan arahan dan menerangkan keputusan dalam bahasa semula jadi. GPT-4 juga boleh melaksanakan pseudokod. Dari segi keupayaan matematik, berbanding model bahasa besar sebelumnya, GPT-4 telah membuat lonjakan kualitatif. Walaupun apabila berhadapan dengan Minerva yang diperhalusi khas, prestasinya telah meningkat dengan ketara. Namun, ia masih jauh dari tahap pakar. Contohnya: populasi arnab akan meningkat sebanyak kali setiap tahun, dan pada hari terakhir tahun itu , terdapat b Seekor arnab dijadikan anak angkat oleh manusia. Katakan terdapat x arnab pada hari pertama tahun pertama diketahui bahawa bilangan arnab akan menjadi 27x-26 selepas 3 tahun. Jadi, apakah nilai a dan b? Untuk menyelesaikan masalah ini, kita perlu mendapatkan ungkapan yang betul untuk perubahan tahunan dalam bilangan arnab, dan kemudian memperoleh sistem persamaan melalui hubungan rekursif ini, dan kemudian dapatkan Jawapan. Di sini, GPT-4 berjaya mencapai penyelesaian dan mengemukakan hujah yang munasabah. Sebaliknya, ChatGPT tidak pernah dapat memberikan alasan dan jawapan yang betul dalam beberapa percubaan bebas. Matematik Lanjutan Seterusnya, mari kita terus ke yang sukar. Sebagai contoh, soalan berikut adalah daripada 2022 International Mathematical Olympiad (IMO) (versi ringkas). Soalan ini berbeza daripada peperiksaan kalkulus sarjana muda kerana ia tidak mematuhi templat berstruktur. Menyelesaikan masalah ini memerlukan pendekatan yang lebih kreatif, kerana tidak ada strategi yang jelas untuk memulakan pembuktian. Sebagai contoh, keputusan untuk membahagikan hujah kepada dua kes (g(x) > x^2 dan g(x) Walaupun begitu, GPT-4 masih memberikan bukti yang betul. Perbincangan kedua tentang algoritma dan teori graf adalah setanding dengan temu duga peringkat siswazah. Dalam hal ini, GPT-4 dapat menaakul tentang pembinaan graf abstrak yang berkaitan dengan masalah kepuasan kekangan dan membuat kesimpulan yang betul tentang masalah SAT daripadanya ( Untuk pengetahuan terbaik kami, pembinaan ini tidak muncul dalam kesusasteraan matematik). Perbualan ini mencerminkan pemahaman mendalam GPT-4 tentang konsep matematik peringkat sarjana muda yang dibincangkan, serta tahap kreativiti yang agak besar. Walaupun GPT-4 menulis 2^n/2 sebagai 2^n-1 dalam satu jawapan, ia kelihatan lebih seperti apa yang biasa kita panggil "ralat perkeranian" kerana ia kemudiannya memberikan generalisasi formula yang betul. Selain itu, penyelidik membandingkan prestasi GPT-4, ChatGPT dan Minerva: GSM8K dan MATH. Didapati GPT4 melebihi Minerva dalam ujian pada setiap set data, dan kadar ketepatan dalam kedua-dua set ujian melebihi 80%. Mari kita lihat lebih dekat sebab ralat GPT4 68% adalah ralat pengiraan, bukan ralat penyelesaian. Satu lagi manifestasi utama kecerdasan ialah interaktiviti. Interaktiviti adalah penting untuk kecerdasan kerana ia membolehkan ejen memperoleh dan menggunakan pengetahuan, menyelesaikan masalah, menyesuaikan diri dengan situasi yang berubah dan mencapai matlamat Kebolehan sendiri. Oleh itu, penyelidik mengkaji interaktiviti GPT-4 daripada dua dimensi: penggunaan alat dan interaksi khusus. GPT-4 boleh mencari alat luaran seperti enjin atau API apabila menjawab soalan seperti berikut. Dalam kertas itu, penyelidik mendapati GPT-4 boleh membina Mental manusia model. Kajian ini merangka satu siri ujian untuk menilai teori kebolehan minda GPT-4, ChatGPT dan text-davinci-003. Contohnya, dalam memahami kepercayaan, GPT-4 berjaya melepasi ujian kepercayaan palsu Sally-Anne dalam psikologi. Terdapat juga ujian keupayaan GPT-4 untuk menyimpulkan keadaan emosi orang lain dalam situasi yang kompleks: -Kenapa Tom buat muka sedih? -Apakah yang Adam fikirkan menyebabkan ekspresi sedih Tom? Melalui beberapa pusingan ujian, para penyelidik mendapati bahawa adalah perlu untuk membuat alasan tentang keadaan psikologi orang lain dan mencadangkan penyelesaian yang konsisten dengan senario sosial kehidupan sebenar, GPT-4 mengatasi ChatGPT dan teks-davinci-003. Model "ramalkan perkataan seterusnya" yang digunakan oleh GPT-4 mempunyai had yang jelas: model tidak mempunyai perancangan , memori kerja, retrospektif kebolehan dan kebolehan menaakul. Kerana model itu bergantung pada proses tamak tempatan yang menjana perkataan seterusnya, tanpa menjana pemahaman mendalam tentang konteks global tugas atau output. Oleh itu, GPT-4 pandai menghasilkan teks yang lancar dan koheren, tetapi tidak pandai menyelesaikan masalah kompleks atau kreatif yang tidak dapat diproses secara berurutan. Sebagai contoh, gunakan empat nombor rawak dalam julat 0 hingga 9 untuk melakukan operasi pendaraban dan penambahan. Mengenai masalah ini yang pelajar sekolah rendah pun boleh selesaikan, ketepatan GPT-4 hanya 58%. Apabila nombor adalah antara 10 dan 19, dan antara 20 dan 39, ketepatan masing-masing menurun kepada 16% dan 12%. Apabila nombor berada dalam julat 99 hingga 199, ketepatan turun terus kepada 0. Walau bagaimanapun, ketepatan boleh dipertingkatkan dengan mudah jika GPT-4 dibenarkan "mengambil masa" untuk menjawab soalan. Contohnya, minta model menulis langkah perantaraan menggunakan gesaan berikut: 116 * 114 + 178 * 157 = ? Mari kita ambil satu langkah Fikir satu langkah pada satu masa, tulis semua langkah perantaraan sebelum tiba di penyelesaian muktamad. Pada masa ini, apabila nombor berada dalam julat 1-40, kadar ketepatan adalah setinggi 100%, dan apabila ia berada dalam julat 1 -200, ia juga mencapai 90%. Menariknya, selepas penerbitan kertas Microsoft ini Tidak lama kemudian, Marcus segera menulis blog, memanggil pandangan Microsoft "benar-benar tidak masuk akal." Dan memetik ayat dari Alkitab, "Kesombongan mendahului kehancuran, dan semangat yang angkuh mendahului kejatuhan. (Amsal 16:18)" Bagaimanakah GPT-4 boleh dianggap sebagai AGI awal? Dengan cara ini, kalkulator juga mengira, dan Eliza dan Siri mengira lebih banyak lagi. Takrifan ini sangat kabur dan mudah untuk memanfaatkannya. Pada pandangan Marcus, GPT-4 tiada kaitan dengan AGI, dan GPT-4 adalah sama seperti dahulu, kelemahannya masih belum dapat diselesaikan, dan ilusi masih wujud. Ketidakpercayaan jawapan masih belum dapat diselesaikan, malah penulis sendiri mengakui bahawa keupayaannya untuk merancang tugas yang rumit masih tidak mencukupi. Apa yang dia bimbangkan ialah dua kertas kerja yang ditulis oleh OpenAI dan Microsoft tidak didedahkan sama sekali. Hanya bergantung pada satu siaran akhbar Paper hanya mahu mempromosikan sifat saintifik mereka. Jadi "sesetengah bentuk AGI" yang dituntut dalam makalah itu tidak wujud, dan komuniti saintifik tidak boleh mengesahkannya sama sekali kerana ia tidak dapat memperoleh data , dan nampaknya data latihan telah tercemar. Apa yang lebih teruk ialah OpenAI telah mula memasukkan eksperimen pengguna ke dalam korpus latihan itu sendiri. Dengan mengelirukan keadaan dengan cara ini, komuniti saintifik tidak dapat menilai keupayaan utama GPT-4: sama ada model itu mempunyai keupayaan untuk menyamaratakan kes ujian baharu. Jika OpenAI tidak meletakkan topi saintifik pada dirinya di sini, Marcus mungkin tidak begitu kritikal terhadapnya. Dia mengakui GPT-4 sangat berkuasa, tetapi risikonya juga diketahui umum. Jika OpenAI tidak mempunyai ketelusan dan enggan mendedahkan modelnya kepada umum, ia mungkin juga ditutup. Microsoft mempunyai barisan pengarang yang kuat di belakang kertas 154 halaman ini. Ini termasuk: Sébastien Bubeck, penyelidik utama di Microsoft Research Redmond dan pemenang Hadiah Sloan 2015, Ronen Eldan, pemenang Hadiah Matematik New Horizons 2023, Yin Tat Lee, pemenang Anugerah Penyelidikan Sloan 2020, dan Li Yuanzhi, pemenang baharu Anugerah Penyelidikan Sloan 2023. Perlu dinyatakan bahawa tajuk asal kertas yang ditetapkan oleh pasukan Microsoft bukanlah "The Spark of General Kecerdasan Buatan: GPT" -4 percubaan awal". Kod lateks yang bocor dalam kertas yang belum dipotong menunjukkan bahawa tajuk asal ialah "Kontak Pertama dengan AGI". 




Keupayaan matematik




Berinteraksi dengan dunia
Berinteraksi dengan manusia

Keterbatasan

Marcus mengeluarkan bantahan
Barisan pengarang yang mantap

Atas ialah kandungan terperinci Kejutkan komuniti saintifik! Penyelidikan 154 halaman Microsoft membanjiri skrin: Keupayaan GPT-4 hampir dengan manusia, dan 'Skynet' muncul?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI