
Rumah >pembangunan bahagian belakang >Tutorial Python >14 operasi biasa dalam Excel menggunakan Python
14 operasi biasa dalam Excel menggunakan Python

- WBOYke hadapan
- 2023-04-15 19:07:01923semak imbas

Helo semua, saya seorang pemula!
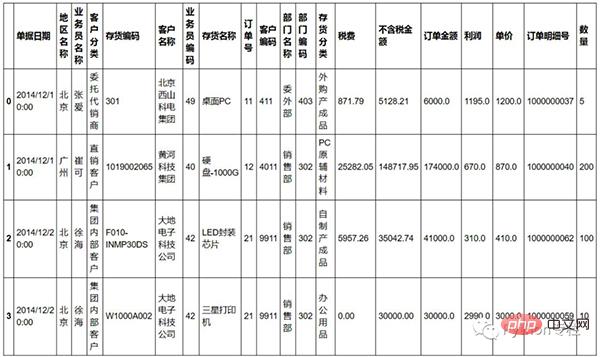
Data ialah data jualan yang ditemui dalam talian Ia kelihatan seperti ini:
1. Formula persatuan: Vlookup
<.> vlookup adalah hampir formula yang paling biasa digunakan dalam Excel, dan biasanya digunakan untuk pertanyaan berkaitan antara dua jadual. Jadi saya mula-mula membahagikan jadual ini kepada dua jadual. df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号', '客户编码', '部门名称', '部门编码']] df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]Permintaan: Saya ingin tahu keuntungan yang sepadan dengan setiap pesanan df1. Lajur keuntungan wujud dalam jadual df2, jadi saya ingin tahu keuntungan yang sepadan dengan setiap pesanan df1. Apabila menggunakan excel, mula-mula sahkan bahawa nombor butiran pesanan ialah nilai unik, kemudian tambah lajur baharu dalam df1 dan tulis: =vlookup(a2,df2!a:h,6,0), dan kemudian tariknya ke bawah dan ia akan baik-baik sahaja. (Saya tidak akan menulis excel untuk baki 13 lagi)
#查看订单明细号是否重复,结果是没。 df1["订单明细号"].duplicated().value_counts() df2["订单明细号"].duplicated().value_counts() df_c=pd.merge(df1,df2,on="订单明细号",how="left")2. Jadual pangsi
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])3 Bandingkan perbezaan antara dua lajur
sale["订单明细号2"]=sale["订单明细号"] #在订单明细号2里前10个都+1. sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1 #差异输出 result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]4. Alih keluar nilai pendua
sale.drop_duplicates("业务员编码",inplace=True)5 pemprosesan#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值 sale.info()

#用0填充缺失值 sale["客户名称"]=sale["客户名称"].fillna(0) #删除有客户编码缺失值的行 sale.dropna(subset=["客户编码"])6. Penapisan pelbagai keadaan
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]7. Penapisan kabur data
sale.loc[sale["存货名称"].str.contains("三星|索尼")]8. Ringkasan terperingkat sale.groupby(["地区名称","业务员名称"])["利润"].sum()9. Pengiraan bersyarat
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()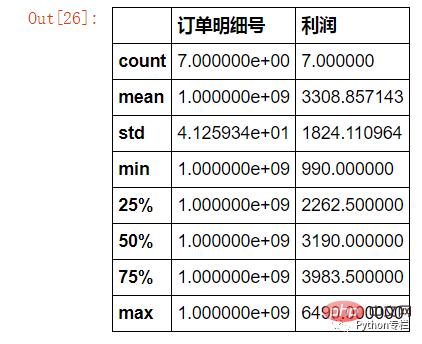
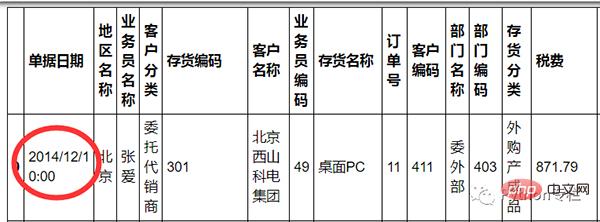
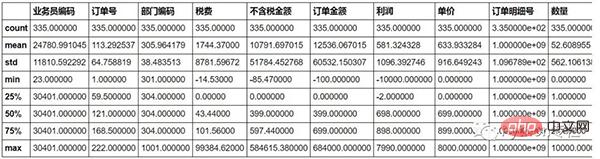
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)12 Penggantian outlier sale.describe()
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)13. Pengelompokan
sale.groupby("地区名称")["利润"].sum().describe()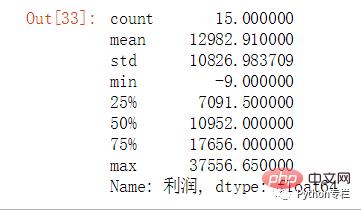
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups)14. Tentukan teg mengikut logik perniagaan sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品" sale.loc[(sale["利润"]/sale["订单金额"])<0.05,"label"]="一般商品"Sebenarnya, ia adalah operasi yang biasa digunakan dalam excel. Terdapat banyak lagi yang saya senaraikan. Jika anda ingin melaksanakan operasi lain, anda boleh mengulas dan membincangkannya bersama. Saya juga tahu bahawa penulisan Python saya tidak cukup diselaraskan, jadi saya menggunakan loc secara tidak aktif (sebenarnya, pertanyaan akan lebih diperkemas Jika anda mempunyai cara yang lebih baik untuk menulis operasi ini, sila beritahu saya dalam ulasan, terima kasih). !
Akhir sekali, saya ingin mengatakan bahawa saya fikir adalah lebih baik untuk tidak membandingkan excel dan python untuk mengkaji mana yang lebih mudah untuk digunakan. Malah, kedua-duanya adalah alat pemprosesan data yang paling meluas dimonopoli selama bertahun-tahun dan mesti agak mudah dalam pemprosesan data Cemerlang, sesetengah operasi memang lebih mudah dengan python, tetapi terdapat juga banyak operasi dalam excel yang lebih mudah daripada python.
Contohnya, operasi yang sangat mudah: jumlahkan setiap lajur dan paparkannya di baris bawah Excel hanya menambah fungsi sum() pada lajur, dan kemudian menariknya ke kiri untuk menyelesaikannya . Python Kemudian anda perlu mentakrifkan fungsi (kerana python perlu menentukan format, jika ia bukan data berangka, ia akan melaporkan ralat secara langsung.)
Atas ialah kandungan terperinci 14 operasi biasa dalam Excel menggunakan Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!