
Rumah >Peranti teknologi >AI >AI belajar bermain 'Minecraft' dari awal, generalisasi AI DeepMind membuat kejayaan
AI belajar bermain 'Minecraft' dari awal, generalisasi AI DeepMind membuat kejayaan

- PHPzke hadapan
- 2023-04-15 18:07:031740semak imbas
Kecerdasan am perlu menyelesaikan tugasan dalam pelbagai bidang. Algoritma pembelajaran pengukuhan dianggap mempunyai potensi ini, tetapi ia telah dihalang oleh sumber dan pengetahuan yang diperlukan untuk menyesuaikannya dengan tugasan baharu. Dalam kajian baharu daripada DeepMind, penyelidik menunjukkan DreamerV3, algoritma berasaskan model dunia am dan boleh skala yang mengatasi kaedah sebelumnya dalam pelbagai domain dengan hiperparameter tetap.
Domain yang dipatuhi oleh DreamerV3 untuk memasukkan tindakan berterusan dan diskret, input visual dan dimensi rendah, dunia 2D dan 3D, volum data yang berbeza-beza, kekerapan ganjaran dan tahap ganjaran. Perlu dinyatakan bahawa DreamerV3 ialah algoritma pertama untuk mengumpul berlian dalam Minecraft dari awal tanpa data manusia atau pendidikan aktif . Para penyelidik mengatakan algoritma umum sedemikian boleh membolehkan aplikasi pembelajaran pengukuhan yang meluas dan berpotensi diperluaskan kepada masalah membuat keputusan yang sukar.
Berlian ialah salah satu item paling popular dalam Minecraft. Ia adalah salah satu item yang paling jarang dalam permainan dan boleh digunakan untuk membuat kebanyakan item dalam permainan. senjata dan perisai. Oleh kerana berlian hanya terdapat di lapisan batu yang paling dalam, pengeluaran adalah rendah.
DreamerV3 ialah algoritma pertama untuk mengumpul berlian dalam Minecraft tanpa memerlukan tunjuk cara manusia atau pembuatan kursus manual. Video ini menunjukkan berlian pertama yang dikumpulnya, yang berlaku dalam lingkungan 30M langkah / 17 hari dari masa permainan.
Jika anda tidak tahu tentang AI bermain Minecraft, saintis AI NVIDIA Jim Fan berkata berbanding dengan AlphaGo bermain Go, bilangan tugas Minecraft adalah tidak terhad dan perubahan persekitaran adalah tidak terhad. Ya, ilmu juga mempunyai maklumat tersembunyi.
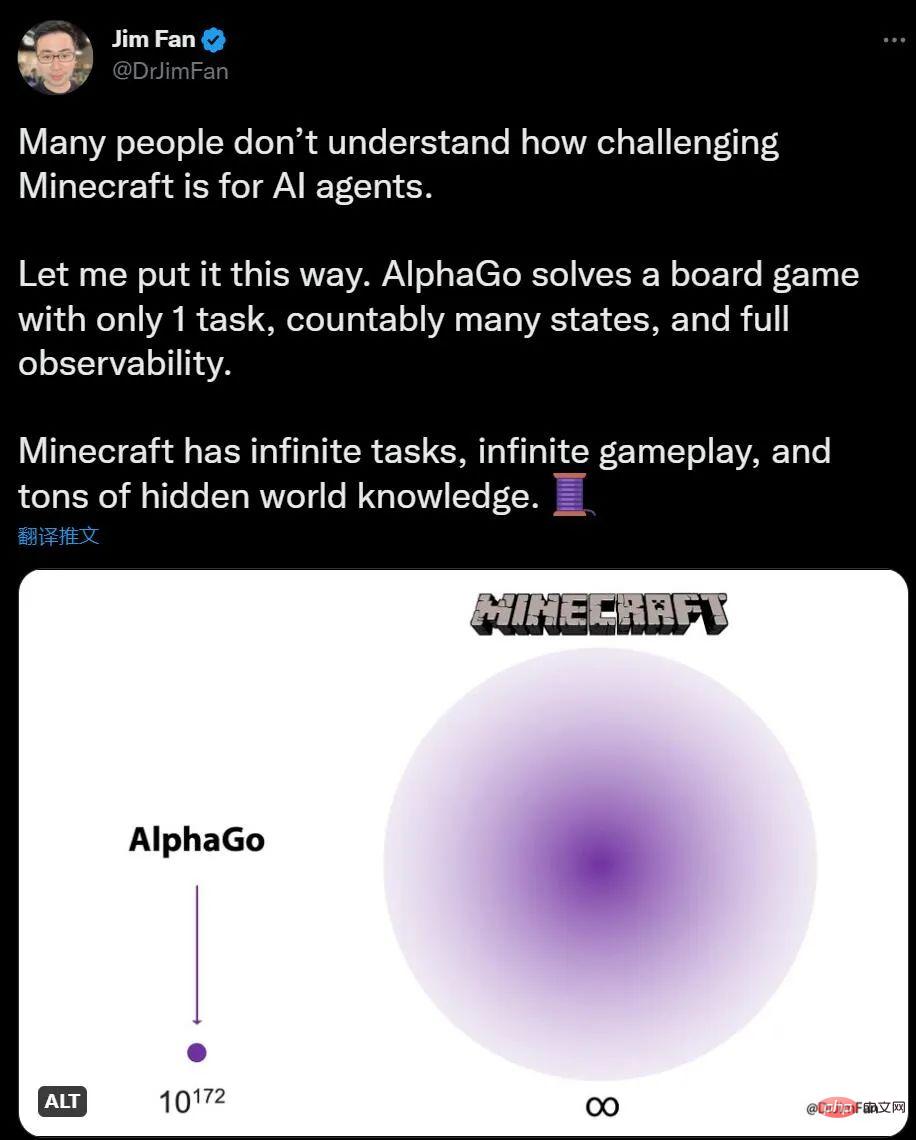
Bagi manusia, meneroka dan membina dalam Minecraft adalah menarik, manakala Go nampaknya agak rumit Untuk AI, Perkara sebaliknya adalah benar. AlphaGo mengalahkan juara manusia 6 tahun yang lalu, tetapi kini tiada algoritma yang boleh bersaing dengan pakar manusia Minecraft.
Seawal musim panas 2019, syarikat pembangunan Minecraft mencadangkan "Cabaran Berlian", menawarkan ganjaran untuk algoritma AI yang boleh mencari berlian dalam permainan sehingga NeurIPS 2019 , penyerahan Daripada lebih 660 penyertaan, tidak ada satu AI pun yang mampu melaksanakan tugas tersebut.
Tetapi kemunculan DreamerV3 telah mengubah keadaan ini adalah satu gabungan tugasan dan jangka panjang yang memerlukan penerokaan dan perancangan yang kompleks. Algoritma baharu boleh mencapai ini tanpa sebarang bantuan data buatan Kumpul berlian sekiranya berlaku. Mungkin terdapat banyak ruang untuk meningkatkan kecekapan, tetapi Hakikat bahawa ejen AI kini boleh belajar mengumpul berlian dari awal adalah satu peristiwa penting .
Gambaran keseluruhan kaedah DreamerV3
Kertas "Menguasai Pelbagai Domain melalui Model Dunia":

Pautan kertas: https://arxiv.org/abs/2301.04104v1
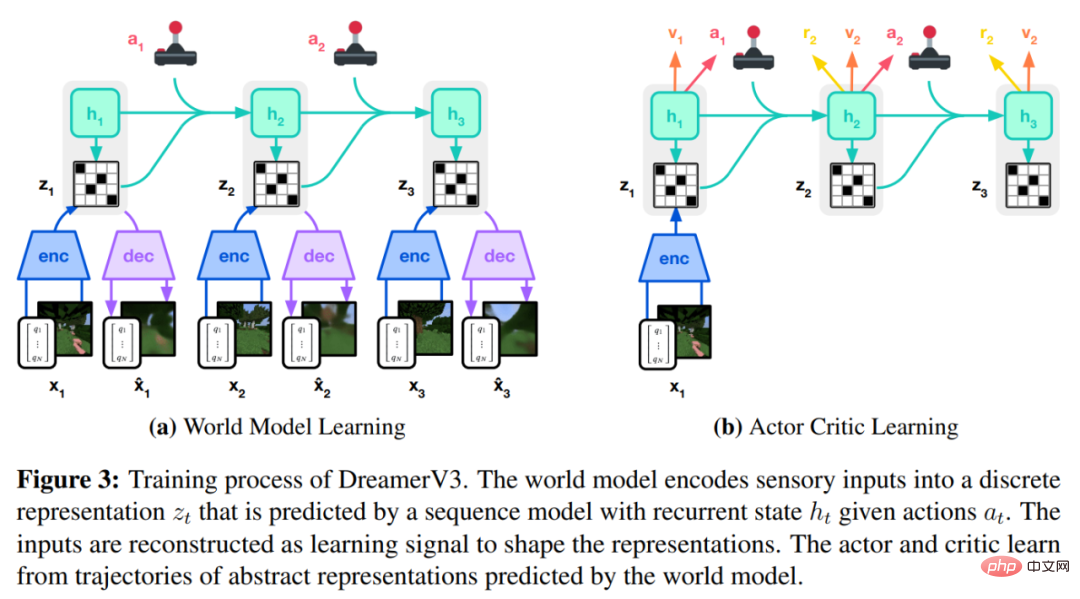
Algoritma DreamerV3 terdiri daripada tiga rangkaian neural iaitu model dunia (dunia) model), pengkritik dan pelakon. Tiga rangkaian saraf dilatih secara serentak berdasarkan pengalaman ulangan tanpa berkongsi kecerunan Rajah 3(a) di bawah menunjukkan pembelajaran model dunia dan rajah (b) menunjukkan pembelajaran pengkritik aktor.
Untuk mencapai kejayaan merentas domain, komponen ini perlu menyesuaikan diri dengan amplitud isyarat yang berbeza dan mengimbangi terma dengan mantap merentas sasarannya. Ini mencabar kerana kami bukan sahaja menyasarkan tugasan yang serupa dalam domain yang sama, tetapi kami juga belajar merentas domain yang berbeza menggunakan hiperparameter tetap.
DeepMind mula-mula menerangkan transformasi mudah untuk meramalkan susunan magnitud yang tidak diketahui, kemudian memperkenalkan model dunia, pengkritik, pelakon dan matlamat pembelajaran teguh mereka. Didapati bahawa menggabungkan keseimbangan KL dan bit bebas membolehkan model dunia dipelajari tanpa pelarasan, dan mencapai penyelaras entropi dasar tetap dengan mengecilkan pulangan besar tanpa membesar-besarkan pulangan kecil.
Ramalan Symlog
Membina semula input dan meramalkan ganjaran dan nilai adalah mencabar kerana skalanya boleh berbeza-beza merentas domain. Menggunakan kerugian kuasa dua untuk meramalkan sasaran yang besar membawa kepada perbezaan, manakala kerugian mutlak dan kehilangan Huber menghentikan pembelajaran. Sebaliknya, objektif penormalan berdasarkan statistik operasi memperkenalkan tidak pegun ke dalam pengoptimuman. Oleh itu, DeepMind mencadangkan ramalan symlog sebagai penyelesaian mudah untuk masalah ini.
Untuk melakukan ini, rangkaian saraf f (x, θ) dengan input x dan parameter θ belajar untuk meramalkan versi diubah sasarannya y. Untuk membaca ramalan rangkaian y^, DeepMind menggunakan penjelmaan songsang, seperti ditunjukkan dalam persamaan (1) di bawah.
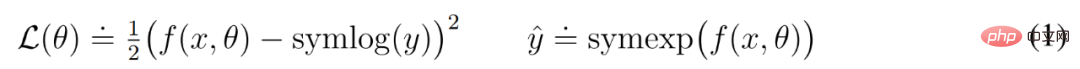
Seperti yang anda lihat dalam Rajah 4 di bawah, sasaran dengan nilai negatif tidak boleh diramal menggunakan logaritma sebagai penjelmaan.

Oleh itu, DeepMind memilih fungsi daripada keluarga logaritma bisymmetric, dinamakan symlog, sebagai penjelmaan, dan fungsi symexp sebagai fungsi songsang.
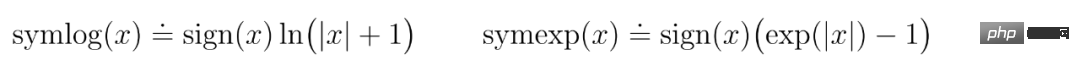
Fungsi symlog memampatkan saiz nilai positif dan negatif yang besar. DreamerV3 menggunakan ramalan symlog dalam penyahkod, peramal ganjaran dan pengkritik, dan juga menggunakan fungsi symlog untuk memampatkan input pengekod.
Pembelajaran model dunia
Model dunia mempelajari perwakilan padat input deria melalui pengekodan automatik dan meramalkan Ganjaran masa hadapan untuk perwakilan dan tingkah laku yang berpotensi untuk melaksanakan perancangan.
Seperti yang ditunjukkan dalam Rajah 3 di atas, DeepMind melaksanakan model dunia sebagai Model Angkasa Keadaan Berulang (RSSM). Pertama, pengekod memetakan input deria x_t kepada perwakilan rawak z_t, dan kemudian model jujukan dengan keadaan berulang h_t meramalkan jujukan perwakilan ini diberikan tindakan lepas a_t−1. Gabungan h_t dan z_t membentuk keadaan model dari mana ganjaran r_t dan bendera kesinambungan episod c_t ∈ {0, 1} diramalkan dan input dibina semula untuk memastikan perwakilan maklumat, seperti ditunjukkan dalam Persamaan (3) di bawah.
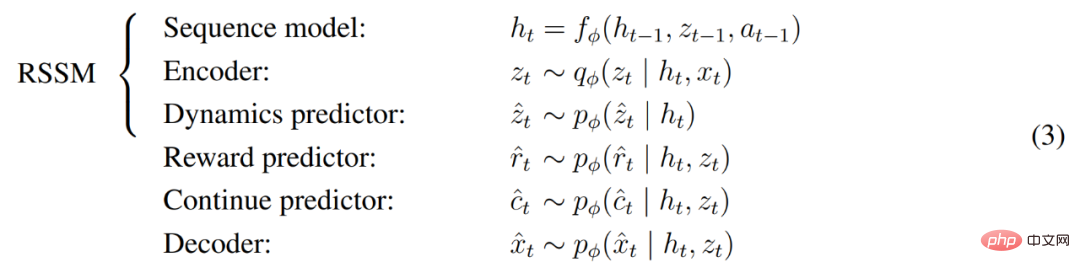
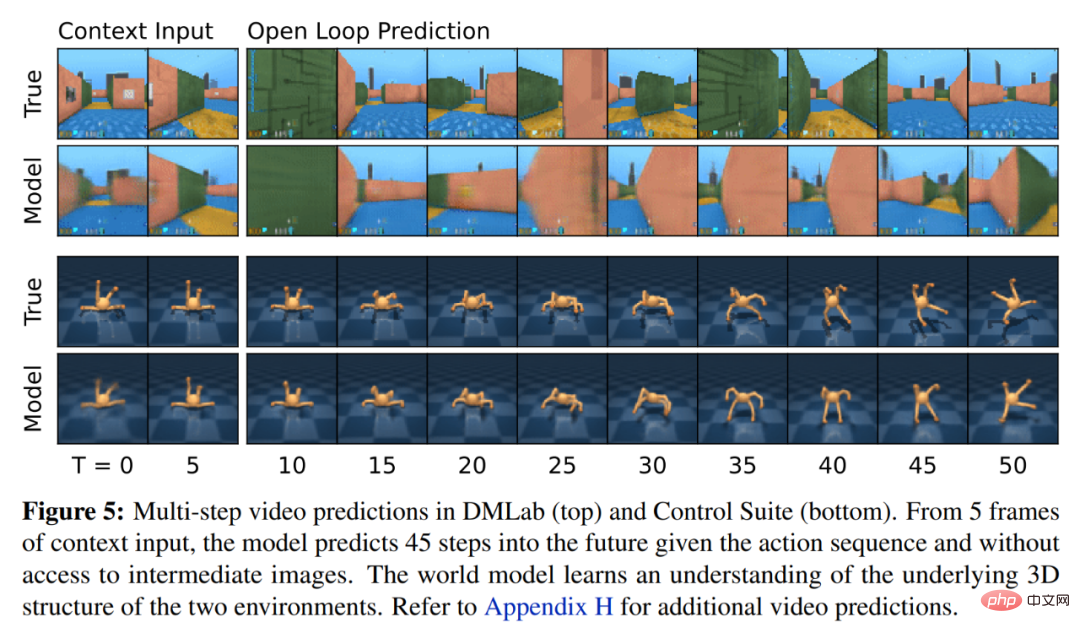
Rajah 5 di bawah menggambarkan ramalan video jangka panjang dunia dunia. Pengekod dan penyahkod menggunakan rangkaian neural konvolusi (CNN) untuk input visual dan perceptron berbilang lapisan (MLP) untuk input berdimensi rendah. Peramal dinamik, ganjaran dan kegigihan juga merupakan MLP, dan perwakilan ini diambil sampel daripada vektor taburan softmax. DeepMind menggunakan kecerunan lulus dalam langkah pensampelan.
Pengkritik Pelakon belajar
Rangkaian saraf Pengkritik Aktor sepenuhnya belajar daripada model dunia Meramal tingkah laku yang dipelajari dalam urutan abstrak. Semasa interaksi dengan persekitaran, DeepMind memilih tindakan dengan mengambil sampel daripada rangkaian aktor, tanpa memerlukan perancangan ke hadapan.
pelakon dan pengkritik beroperasi dalam keadaan model 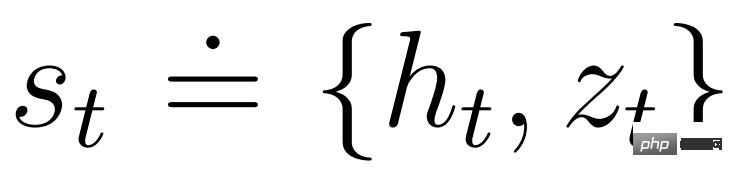 dan boleh mendapat manfaat daripada perwakilan Markov yang dipelajari oleh model dunia. Matlamat pelakon adalah untuk memaksimumkan pulangan yang dijangka
dan boleh mendapat manfaat daripada perwakilan Markov yang dipelajari oleh model dunia. Matlamat pelakon adalah untuk memaksimumkan pulangan yang dijangka 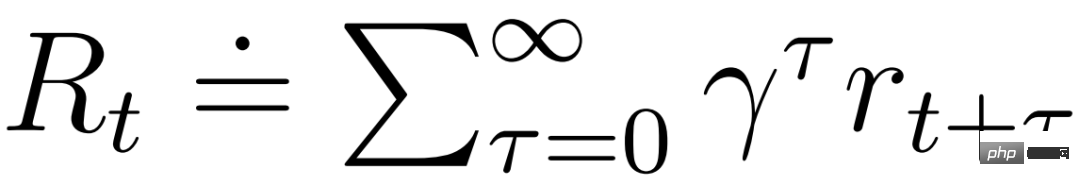 apabila faktor diskaun γ = 0.997 untuk setiap keadaan model. Untuk mengambil kira ganjaran di luar julat ramalan T = 16, pengkritik belajar untuk meramalkan ganjaran bagi setiap keadaan memandangkan tingkah laku aktor semasa.
apabila faktor diskaun γ = 0.997 untuk setiap keadaan model. Untuk mengambil kira ganjaran di luar julat ramalan T = 16, pengkritik belajar untuk meramalkan ganjaran bagi setiap keadaan memandangkan tingkah laku aktor semasa.
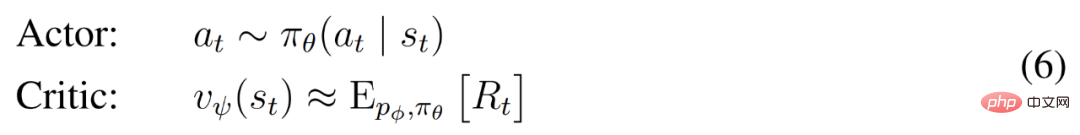
Bermula daripada perwakilan input yang dimainkan semula, peramal dinamik dan pelakon menghasilkan urutan keadaan model yang dijangkakan s_1 :T , tindakan a_1:T, ganjaran r_1:T dan bendera berterusan c_1:T. Untuk menganggarkan pulangan bagi ganjaran di luar ufuk yang diramalkan, DeepMind mengira pulangan λ yang terpasang, yang menyepadukan pulangan dan nilai yang dijangkakan.
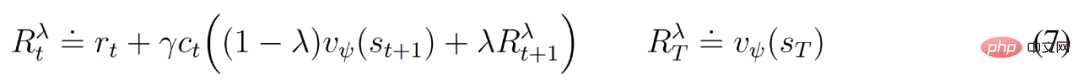
Keputusan Eksperimen
DeepMind menjalankan kajian empirikal yang meluas untuk menilai keluasan dan kebolehskalaan DreamerV3 merentas domain berbeza (lebih 150 tugas) di bawah hiperparameter tetap, dan membandingkannya dengan yang sedia ada Terdapat kaedah SOTA dalam kesusasteraan untuk perbandingan. DreamerV3 juga digunakan untuk permainan video yang mencabar Minecraft.
Untuk DreamerV3, DeepMind melaporkan secara langsung prestasi strategi latihan rawak dan mengelakkan penilaian berasingan berjalan dengan strategi penentu, memudahkan persediaan. Semua ejen DreamerV3 dilatih menggunakan GPU Nvidia V100. Jadual 1 di bawah memberikan gambaran keseluruhan penanda aras.
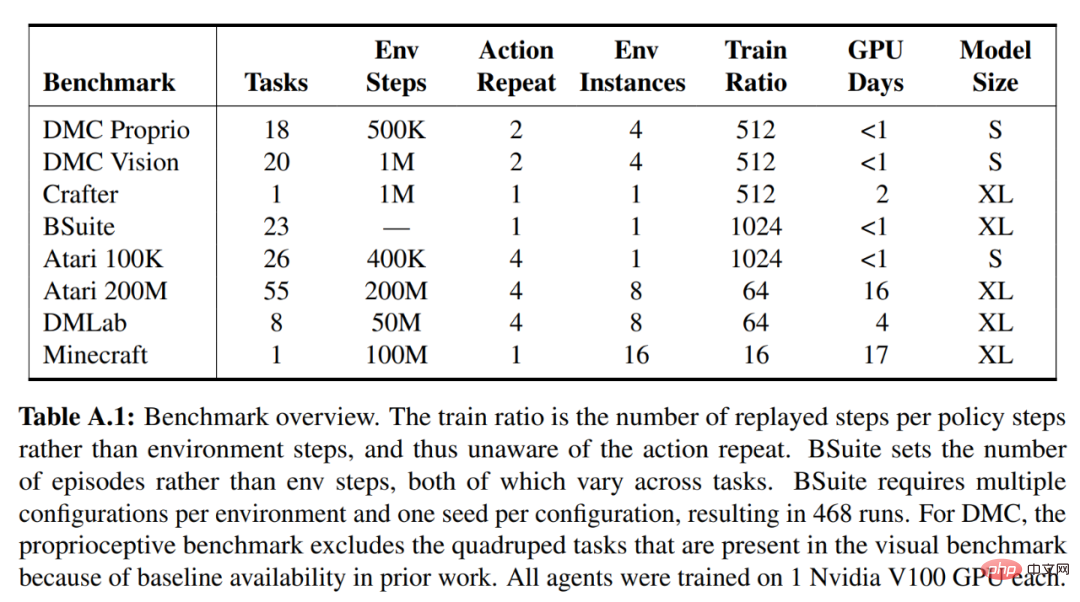
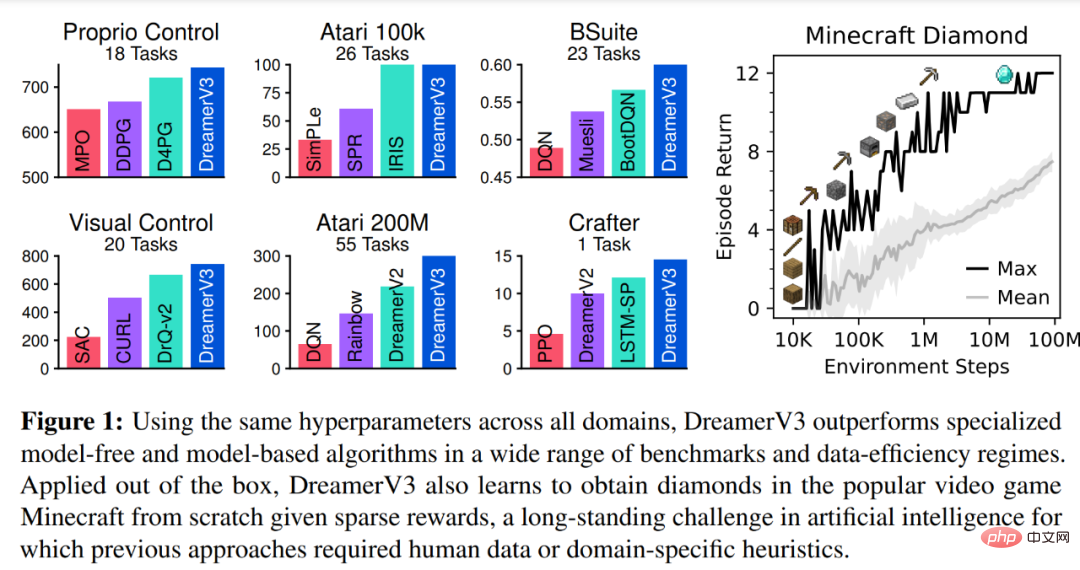
Untuk menilai keluasan DreamerV3, DeepMind menjalankan penilaian empirikal yang meluas dalam tujuh domain, termasuk tindakan berterusan dan diskret, penglihatan dan Input berdimensi rendah , ganjaran padat dan jarang, skala ganjaran yang berbeza, dunia 2D dan 3D, dan penjanaan prosedur. Keputusan dalam Rajah 1 di bawah mendapati bahawa DreamerV3 mencapai prestasi yang kukuh dalam semua domain dan mengatasi semua algoritma sebelumnya dalam 4 daripadanya, sambil menggunakan hiperparameter tetap merentas semua penanda aras.
Sila rujuk kertas asal untuk butiran lanjut teknikal dan keputusan percubaan.
Atas ialah kandungan terperinci AI belajar bermain 'Minecraft' dari awal, generalisasi AI DeepMind membuat kejayaan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI